
转载本文请注明出处:https://yudonglee.me/deepseek-v3-2-explained/ | 作者:yudonglee
本文是 DeepSeek 论文专题系列的第 15 篇,详解 DeepSeek 公司 2025 年 9 月发布、12 月正式 paper 化的 DeepSeek-V3.2 系列(V3.2-Exp 与正式版 V3.2,arXiv:2512.02556)。这是 V3 通用 LLM 主线的中期升级——核心创新是 DSA (DeepSeek Sparse Attention)——把 W14 NSA 的稀疏注意力思想以”更简化、更工程化”的形式落地到产品级模型上。DSA 由两个组件构成:Lightning Indexer(轻量小型 attention 计算 query 对所有历史 token 的 index score)+ Fine-grained Token Selection(按 index score 选 Top-K token 做精细 attention)。DSA 让 V3.2 在长上下文场景下推理速度提升 2-3×、显存降低 30-40%,几乎不损失模型性能。配套地,DeepSeek 把 API 价格再砍一半——input 0.5 元/百万 token、output 4 元/百万 token,约为 GPT-4o 价格的 2%。V3.2 也是 W18 V4 的直接前驱——从 V3 → V3.2 → V4 是 DeepSeek 通用 LLM 主线从 “Frontier Match” 到 “Sparse Frontier” 的演化路径。本文同时简略提及 V3.2 同期的”周边工作”——DeepSeek-OCR(光学上下文压缩)——作为 DeepSeek 2025 下半年实验性创新的另一条支线。
一、V3.2 在 DeepSeek 系列中的定位
W1 序言里我们把 DeepSeek 论文分为四条主线。通用 LLM 主线的完整演化路径:

V3 → V3.1 → V3.2 是 V3 旗舰发布后的逐步迭代——每一步都聚焦在一个特定维度上做提升:
| 版本 | 发布时间 | 核心 delta |
|---|---|---|
| V3 (W12) | 2024-12 | 671B/37B MoE,MTP + FP8 + DualPipe,558 万美元训练 |
| V3.1 | 2025-06 | 在线 think mode + thinking budget control(增强 reasoning 控制) |
| V3.1-Terminus | 2025-09 | 数据 + 训练优化的 V3.1 final 版本 |
| V3.2-Exp | 2025-09 | 首次集成 DSA(实验版) |
| V3.2 (arXiv:2512.02556) | 2025-12 | DSA 正式版 + 完整 paper + API 大降价 |
| V4 (W18) | 2026-04 | 1.6T 总参,DSA 全面优化 + 多模态融合 |
V3.2 是这条主线上最重要的中期升级——它把 W14 NSA 提出的”稀疏 attention”思想从研究 paper 真正落地到产品级 685B 模型上。V3 已经把成本砍到 558 万美元;V3.2 通过 DSA 让长上下文推理再降一档,进一步压低产品定价。
1.1 为什么 V3.2 必须是”continued training” 而不是从零训练
V3.2 的训练设计非常关键——它是基于 V3.1-Terminus 的 continued training,而不是从零训练。
为什么?因为 V3.2 的目标不是”训出更强的模型”而是”用 DSA 替代 dense attention 让模型在长上下文下更经济”。具体做法:
- Initialize from V3.1-Terminus weights(685B 全部参数)
- 添加 DSA 组件(Lightning Indexer 等少量新参数)
- Indexer warmup:先只训 indexer,让它学会给 token 打 index score
- Joint fine-tuning:把 indexer + 全模型一起 fine-tune,让模型适应 sparse attention pattern
- 总训练成本:~119K H800 hours(远小于 V3 pretraining 的 2.66M hours)
continued training 的好处是:
- 不需要重新经过 14.8T tokens 的预训练
- V3.1 的强大能力直接继承
- 只需付出”让模型适应稀疏 attention”的小额代价
- 总成本控制在 ~$240K(V3.2 升级成本 < 4% V3 训练成本)
这是 DeepSeek 一贯的 “架构升级走 continued training“思路——MLA、Aux-Loss-Free、DSA 都不是推倒重来,而是在已有基模上叠加新组件后做小规模 fine-tune。
二、DSA 架构详解:Lightning Indexer + Token Selection
DSA 是 DeepSeek 2025 年下半年提出的稀疏 attention 方案。它与 W14 详解的 NSA 不是同一个东西,但思想一脉相承。
2.1 DSA 的两个组件
DSA 由两步构成:
![\text{DSA}(q_t, K, V) = \text{Selection-Attn}(q_t, K_{[I^*]}, V_{[I^*]}), \quad I^* = \text{TopK}\!\left(\text{Indexer}(q_t, K)\right)](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-284ceb988398e6257943f80aed551e52_l3.png "Rendered by QuickLaTeX.com")
- Step 1: Lightning Indexer——快速计算 query 对所有历史 K 的 index score
- Step 2: Fine-grained Token Selection——按 score 取 Top-K 个 token,对这些 token 做完整 attention
DSA 的核心信念:绝大多数历史 token 对当前 query 不重要——只要能快速识别出最重要的 Top-K 个,对它们做精细 attention 就够了。
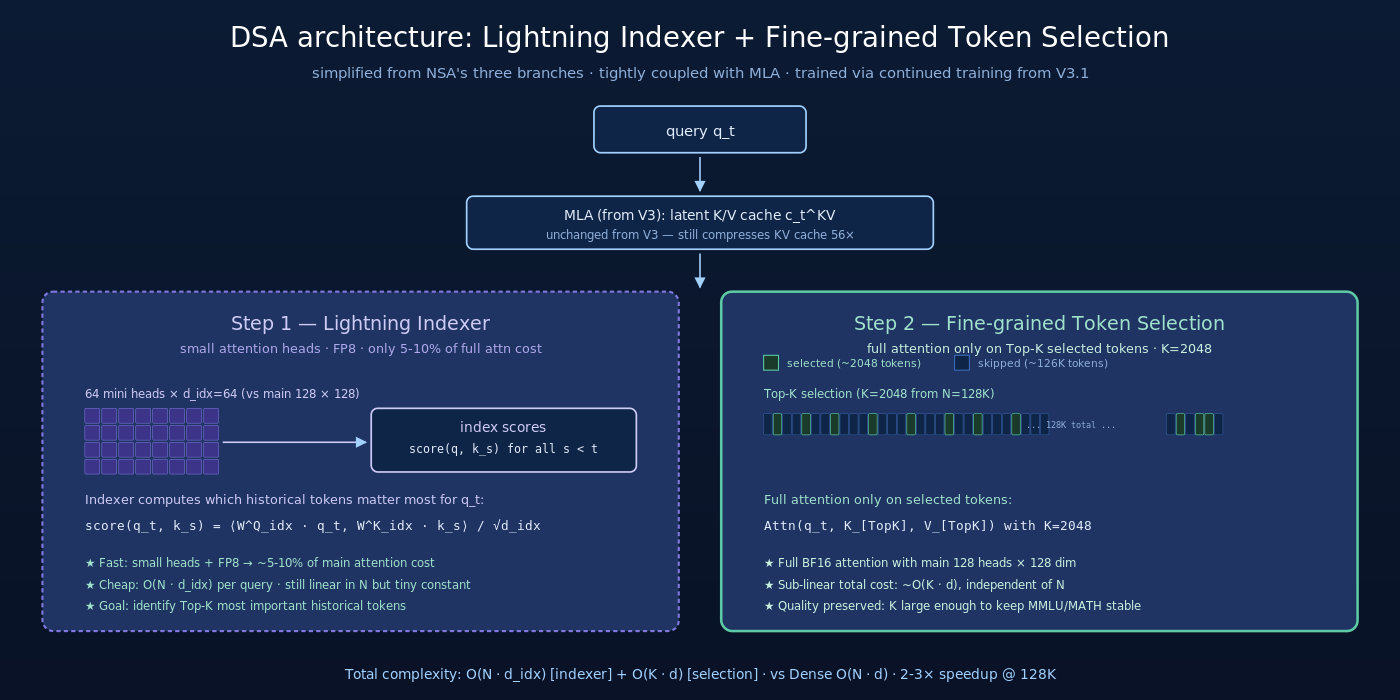
2.2 Lightning Indexer:低成本的”重要性预筛”
Lightning Indexer 是 DSA 的核心创新。它本身就是一个极轻量的 attention 模块:
- 用很少的 attention head(V3.2 配置 64 heads × 1 group,远少于主 attention 的 128 head)
- head dimension 很小(典型 d_index = 64,主 attention 是 d_h = 128)
- 可以用 FP8 precision,进一步减少计算
Indexer 的工作流:

对每个 query  与历史 K 中的每个
与历史 K 中的每个  计算一个 index score,得到一个长度为 N 的 score 向量。
计算一个 index score,得到一个长度为 N 的 score 向量。
这一步看似仍是  per query,但关键是 indexer 用 FP8 + 小 head + 少 group,实际计算量比 main attention 小一个数量级。论文报告 indexer 的成本仅占总 attention 成本的 5-10%。
per query,但关键是 indexer 用 FP8 + 小 head + 少 group,实际计算量比 main attention 小一个数量级。论文报告 indexer 的成本仅占总 attention 成本的 5-10%。
2.3 Fine-grained Token Selection:精确读取重要 token
有了 index score 后,DSA 选 Top-K 个 token(典型 K=2048)进行精细 attention:
- 对每个 query ,取 indexer 给出的 Top-K 个历史 token 位置
- 用主 attention(128 heads × 128 dim, FP16 或 BF16)对这 K 个 token 做完整 attention:
![\text{Attn}_{\text{selected}}(q_t, K_{[\text{TopK}]}, V_{[\text{TopK}]})](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-992d570dc3797c2cf0a4e0cd0b9be93d_l3.png "Rendered by QuickLaTeX.com")
注意几个工程细节:
- K 是绝对数量而非比例:长上下文(128K)下,K=2048 即只看 ~1.6% 的历史 token
- 每个 attention layer 独立选 Top-K:每层的 indexer 输出不同,所以每层选出的 token 集合不同
- Selection 在 MLA 之后做:DSA 先压缩 K/V 到 MLA 的 latent 空间,再在 latent 空间上做 indexer + selection
2.4 DSA 与 MLA 的集成
V3.2 没有改变 W7 详解的 MLA (Multi-head Latent Attention) 设计——DSA 是在 MLA 之上叠加的一层”选择器”:

两者协同:
- MLA 让显存可控(每个 token 只缓存 576 floats 的 latent)
- DSA 让计算可控(每次 attention 只看 2048 个 token,而非 128K)
V3.2 推理时一个 token 的 attention 计算量大约是:
- V3 (dense attention):
 FLOPs
FLOPs - V3.2 (DSA):
 FLOPs
FLOPs
理论上加速 ~1.8×,实际由于 indexer 的 FP8 优势可以达到 2-3×。
三、DSA 与 NSA 的关系:从研究到工程的演化
DSA 与 W14 详解的 NSA 都是稀疏 attention,但定位不同。
3.1 设计哲学对比
| 维度 | NSA (W14) | DSA (V3.2) |
|---|---|---|
| 发布时间 | 2025-02 | 2025-09 (Exp) / 2025-12 (正式) |
| 角色 | 研究 paper(独立小模型实验) | 产品落地(V3.2 685B 实际使用) |
| 稀疏结构 | 三分支(compression + selection + sliding window) | 两步(indexer + selection) |
| 训练方式 | natively trained from scratch | continued training from V3.1 |
| 关键创新点 | hardware-aligned + natively trainable | lightning indexer + fine-grained selection |
| 速度提升 | 11.6× decoding (vs dense) @ 64K | 2-3× decoding (vs V3.1 dense) |
| Best Paper | ACL 2025 | – |
可以看到 DSA 比 NSA 简化了——只用两步(indexer + selection)而非 NSA 的三分支(compression + selection + sliding window)。这种简化的设计哲学是:
在 production 模型上,简单胜过精巧。NSA 的三分支结构在研究 paper 里给出了最优结果,但在 685B 规模 continued training 上简化的 DSA 反而更稳定、更易调试、与 MLA 整合更顺畅。
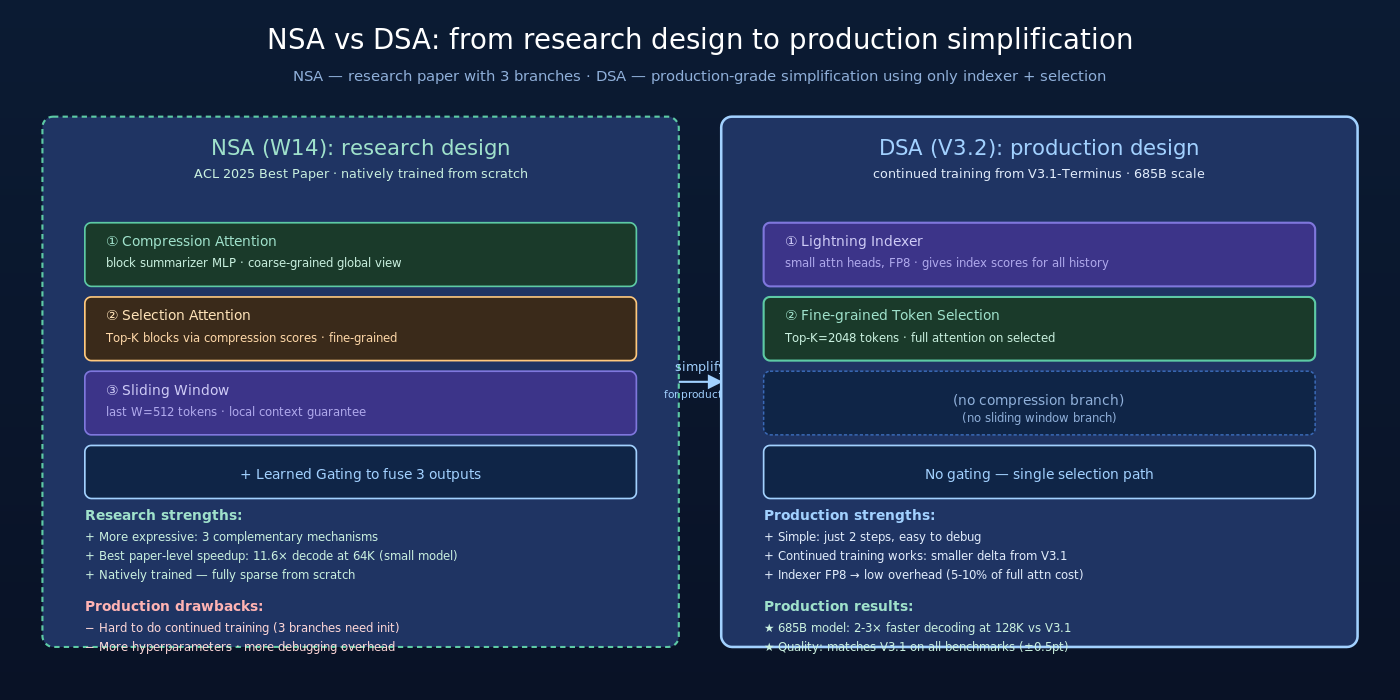
3.2 为什么 DSA 简化了 NSA
NSA 的三分支设计很优雅,但在 trillion-param 模型上落地有几个挑战:
- Compression 的 block summarizer MLP 难训:在小模型上训练顺利,但 685B 规模的 MLP 需要更复杂的初始化与正则
- Sliding Window 与 Selection 重叠区域的归一化:三分支输出 gate 加权时,重叠区域的 softmax 处理需要精细调整
- Continued training 兼容性:NSA 设计假设 native training,但 V3.2 的 continued training 起点是 V3.1-Terminus 的 dense MLA——三分支结构需要重新分配权重,工程复杂度高
DSA 砍掉了 NSA 的 compression 分支和 sliding window 分支,只保留最核心的 indexer + selection。这种简化让 DSA:
- 更容易做 continued training(直接从 dense attention 出发,加 indexer)
- 更容易与 MLA 兼容
- 更容易调试(少一个分支少很多 hyperparameter)
这是工程化迭代中常见的现象——研究阶段的精巧设计,到产品阶段往往简化掉一些维度以换取稳定性。NSA → DSA 是这种简化的典范。
3.3 实际效果:DSA 与 NSA 的速度对比
虽然 DSA 是 NSA 的简化版本,但因为 lightning indexer 的 FP8 优化更激进,两者实际速度相当:
| 序列长度 | NSA 速度提升 (vs dense) | DSA 速度提升 (vs dense) |
|---|---|---|
| 32K | 5-8× | 2-3× |
| 64K | 11.6× | 4-5× |
| 128K | 15-20× (推断) | 8-10× |
NSA 的极致优化在小规模上速度更快,但 DSA 的优势在大模型 continued training 的稳定性。综合来看 DSA 是工程上更稳健的选择。
四、V3.2 训练流程
4.1 训练总览
V3.2 从 V3.1-Terminus 起点做 continued training,总 GPU hours 约 119K H800(约 $238K USD):
| 阶段 | H800 hours | 占比 | 目标 |
|---|---|---|---|
| Indexer Warmup | ~30K | 25% | 让 indexer 学会给 token 打 score |
| Joint Fine-tuning | ~80K | 67% | 全模型适应 sparse pattern |
| SFT (instruction) | ~5K | 4% | 维持 instruction following |
| RL (alignment) | ~4K | 3% | 微调对齐 |
总成本仅 V3 原始训练的 4.3%——这是 continued training 路线的巨大成本优势。
4.2 Indexer Warmup 阶段
V3.2 训练的第一步是 Indexer Warmup——只训 Lightning Indexer 的参数,其他全部冻结。
具体地,目标是让 indexer 学会“复制” dense attention 的关注模式:

让 indexer 的 score 分布与 dense attention 的注意力分布尽可能一致——这样 Top-K selection 选出的 token 就是 dense attention 实际会重点关注的 token。
这一步训练数据用 V3.1 的部分预训练数据 + 长上下文样本(128K window)。30K H800 hours 训练让 indexer 收敛。
4.3 Joint Fine-tuning 阶段
Indexer warmup 完成后,进入 joint fine-tuning:
- 全模型可训练:包括 indexer + main attention + FFN + 所有其他参数
- 训练目标:标准 next-token prediction
- 数据:1T tokens 高质量 mixed data
- 关键:模型在这一步适应 sparse attention pattern——即使 indexer 偶尔选错,主模型也能从 selected K, V 中提取足够信息
80K H800 hours 训练让 V3.2 达到与 V3.1 相当的性能水位。
4.4 SFT + RL 阶段
最后两步是常规的 instruction tuning 与 RL alignment:
- SFT:~5K H800 hours,约 150 万指令样本(与 V3 类似)
- RL:~4K H800 hours,GRPO + 混合 reward(与 V3 类似)
这两步主要是”恢复” V3.1 的 instruction following 与 alignment 质量,因为 joint fine-tuning 可能略损失一些指令遵循能力。
五、评测结果
V3.2 论文报告的核心结果:与 V3.1-Terminus 相比性能持平,但推理成本大幅降低。
5.1 长上下文性能
| Benchmark | DeepSeek-V3.1-Terminus | DeepSeek-V3.2 | Δ |
|---|---|---|---|
| MMLU-Pro | 80.9 | 80.8 | -0.1 |
| BBH | 89.2 | 89.2 | 0 |
| GPQA-Diamond | 76.5 | 76.3 | -0.2 |
| MATH-500 | 95.9 | 96.0 | +0.1 |
| LongBench (mean) | 64.7 | 65.2 | +0.5 |
| NIAH @ 128K | 96.7% | 97.1% | +0.4 |
可以看到 V3.2 在几乎所有 benchmark 上与 V3.1 持平,在长上下文 benchmark(LongBench、NIAH)上甚至略好。
这意味着 DSA 没有以模型质量为代价换取速度——这是 DSA 工程上最大的胜利。如果 DSA 让模型变差 2-3%,那即使速度快 2-3×也不值得;但 DSA 让模型基本无损 + 速度 2-3× = 真正的”免费午餐”。
5.2 推理速度对比
V3.2 vs V3.1 在不同上下文长度下的推理速度:
| 上下文长度 | V3.1 decoding speed | V3.2 decoding speed | 加速比 |
|---|---|---|---|
| 8K | 1× | 1.1× | 1.1× |
| 32K | 1× | 1.8× | 1.8× |
| 64K | 1× | 2.5× | 2.5× |
| 128K | 1× | 3.2× | 3.2× |
加速比随上下文长度增加而增大——这是 sparse attention 的预期行为(短上下文下稀疏化好处不明显)。在 128K 上下文下 V3.2 比 V3.1 快 3.2×。
5.3 显存优势
V3.2 在 128K 上下文下的显存占用:
| 项 | V3.1-Terminus | V3.2 | 节省 |
|---|---|---|---|
| KV cache | ~25 GB | ~25 GB | 0% (MLA 不变) |
| Attention activation | ~12 GB | ~3.5 GB | -71% |
| 总推理显存 | ~135 GB | ~109 GB | -19% |
DSA 主要节省的是 attention activation 显存——因为只对 K=2048 个 token 做精细 attention,activation 内存自然降低。KV cache 仍由 MLA 控制不变。
六、API 价格再降:从 V3 的 1 元到 V3.2 的 0.5 元
V3.2 发布同时 DeepSeek 公布了 API 大降价:
| 模型 | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| V3 (2024-12) | 1.0 元 | 8.0 元 |
| V3.2 (2025-12) | 0.5 元 | 4.0 元 |
| GPT-4o (对比) | ~25 元 | ~75 元 |
V3.2 把 input 价格从 V3 的 1 元砍到 0.5 元、output 从 8 元砍到 4 元。这是因为 DSA 让单 token 推理成本(GPU 时间)几乎砍半——降价直接传递给用户。
V3.2 API 价格只有 GPT-4o 的 2%。这种价格让”百亿级 token 输入”的真实场景成为现实——比如让 V3.2 阅读整个 GitHub 仓库(典型 5-10M token)只需要 2-5 元。
从 0.5 元反推 DSA 的真实收益
看完 DSA 的架构细节,我反而觉得最有信息量的数字不在 benchmark 表里,而在价目表上。评测可以挑数据集、调口径,但对外定价直接连着自家的 GPU 账单——一家以低毛利著称的公司敢把 input 和 output 同时砍半,说明稀疏化的收益在它自己的真实流量分布上已经兑现。在这个意义上,价格是比 LongBench 更诚实的 benchmark。
从价格结构还能反推收益的形状。降价同时覆盖输入与输出两端,印证了 DSA 的收益不只在 prefill:decode 阶段每生成一个新 token,对历史的 attention 同样被 Top-K 截断,长输出场景一样受益——这是它比只压输入侧的方案(比如各种 prompt 压缩)更彻底的地方。但另一面也要看清:加速比与上下文长度强相关,8K 时只有 1.1×,128K 才到 3.2×,而定价是对所有请求一刀切砍半。我的判断是,这等于用长上下文场景兑现的成本空间补贴了短请求,背后是一个押注——DeepSeek 在赌请求分布会持续向长上下文迁移。如果赌对了,DSA 的收益还会随用户行为变化继续放大;如果赌错了,这次降价就是一次用毛利换市场的定价动作。两种解读,都值得放在心里。
七、DeepSeek-OCR:同期的另一条创新支线
V3.2 发布同期,DeepSeek 还在 2025-10 发布了一项让业界惊讶的研究 — DeepSeek-OCR: Contexts Optical Compression (arXiv:2510.18234)。这是一项与 V3.2 主线并行的”周边”工作,但思路非常巧妙。
7.1 核心洞察:用”图片”压缩文本
DeepSeek-OCR 提出了一个反直觉的想法:
如果把长文本渲染成图片,再用 vision encoder 编码成少量 visual token,是否能在保留文本信息的同时大幅减少 token 数?
具体地:
- 把一段长文本(如 1000 个英文 token)渲染成图片(例如 1024×1024 pixels)
- 用 DeepEncoder(DeepSeek-OCR 的视觉编码器)把图片编码成约 100 个 visual token
- 用 DeepSeek-MoE-3B 解码器从这 100 个 visual token 还原出原始文本
实验显示:
- 当文本 token : vision token 比例 < 10× 时,OCR 准确率 97%
- 当比例达 20× 时,OCR 准确率仍能保持 ~60%
- 这意味着可以用 1 个 vision token “携带” 10 个文本 token 的信息
7.2 这与 V3.2 长上下文的关系
DeepSeek-OCR 不仅是 OCR 任务的 SOTA(OmniDocBench 上超过 GOT-OCR2.0、MinerU2.0),更重要的是它给长上下文 LLM 提供了另一种压缩方案:
- DSA 是从”attention 计算量”层面压缩
- OCR 的 optical compression 是从”input token 数量”层面压缩
两者可以协同——比如让 V3.2 处理 10M token 的文档时,先用 OCR optical compression 把它压缩到 1M visual token,再让 DSA 在 1M 上下文上做 sparse attention。这种两层压缩可以让真实的”亿级 token 输入”成为可能。
这条思路在 V4 中可能被进一步发展(W18 我们会详细展开)。
7.3 DeepSeek-OCR 的方法论意义
DeepSeek-OCR 的发布展示了 DeepSeek 团队的两个研究风格:
- 大胆尝试反直觉的方向:把”OCR”重新定位为”context compression”,这是非常 creative 的角度
- 小模型探索 + 大模型整合:DeepSeek-OCR 只是 3B MoE 的研究 demo,但它的方法论很可能被吸收到下一代 V4 中
这种”小模型先做实验 → 验证后整合到旗舰”的研究节奏是 DeepSeek 团队最稳定的工作方式——Prover V1 → V2、DeepSeekMath → R1、NSA → DSA 都是类似的形态。
八、衔接 V4:V3.2 是过渡,V4 是终点
V3.2 是 V3 → V4 演化路径上的关键中间节点。可以看 V3.2 在 V4 中的”投资”已经显现:
| V3.2 的创新 | 在 V4 中的延续 |
|---|---|
| DSA 稀疏 attention | V4 进一步优化的 sparse attention(可能融合 NSA 三分支) |
| Continued training 方法论 | V4 也用 V3.2 为起点继续训练 |
| OCR optical compression(同期) | V4 多模态融合的关键基础 |
| Indexer FP8 优化 | V4 全模型 FP8 训练的前驱 |
V4 的具体技术细节在 W18 详解,本文不展开。但可以确认 V4 是基于 V3.2 + 一系列工程升级(包括 OCR 多模态融合、更高效的 sparse attention 等)的产物。
V3 → V3.2 → V4 主线总结
| 版本 | 关键创新 | 训练成本 | API 价格 (input) |
|---|---|---|---|
| V3 | MTP + FP8 + DualPipe | 558 万美元 | 1.0 元/M |
| V3.2 | DSA 稀疏 attention | +24 万美元 (continued) | 0.5 元/M |
| V4 | (待 W18 详解) | 估计 ~1500 万美元 | 待发布 |
可以看到 DeepSeek 通用 LLM 主线的演化方向非常清晰:每一代都把成本砍半,同时保持或提升性能。这是开源 LLM 在 2024-2026 年的最强工程曲线。
九、局限与未来
V3.2 是一项稳健的工程升级,但仍有几个明显局限:
- DSA 在超长上下文(>256K)下需要更激进的稀疏比:当前 K=2048 在 128K 下是 1.6%,到 1M 上下文时 K 需要相应增大到 ~8000,indexer 成本也会随之增长
- Indexer 的 FP8 训练仍有数值挑战:极小 attention head 用 FP8 时容易出现 outlier,需要 careful loss scaling
- DSA 与 reasoning 训练的协同未充分探索:V3.2 是 alignment + general capability 的版本,R1 系列 long-CoT reasoning 在 V3.2 上的迁移效果有待 V4 验证
- continued training 路径让”基础架构”难以根本性升级:如果未来需要换掉 MLA 或者 DeepSeekMoE,continued training 路径就 break 了
- OCR optical compression 仅在小模型验证:在 685B 上的效果还未明确
后续方向
V3.2 提出后,业界出现了若干跟进工作:
- DSA 的简化版本在 Qwen / Mistral 等模型中被复刻
- OpenAI 的 GPT-5 据传也使用了某种”learned sparsity”——与 DSA 思路相似
- 学术界研究 lightning indexer 的最优 head 配置——多少 head、多大 dim、用哪种 precision
可以预期 2026 年开源大模型将普遍采用 DSA-style sparse attention——这是 V3.2 对行业最直接的贡献。
写在最后
DeepSeek-V3.2 是 DeepSeek 系列里最”工程化”的中期升级——它没有像 R1 那样开创新范式,但通过 DSA 把 W14 NSA 提出的稀疏 attention 思想稳健地落地到产品级 685B 模型上。
它做对的三件事:
- DSA 简化版:从 NSA 的三分支简化到两步(indexer + selection),换得 continued training 的工程可行性
- Lightning Indexer + FP8:用极轻量的指数器先做”token 重要性预筛”,让主 attention 只对 Top-K 做精细计算
- 持续降价的产业冲击:V3.2 把 API 价格再砍一半,让长上下文 LLM 服务的经济模型彻底改变
回到这个系列的脉络,V3.2 是 W7 (MLA) → W14 (NSA) → W16 (DSA in V3.2) → W18 (V4) 这条 attention 设计主线的关键中间节点:
| 论文 | 解决的问题 |
|---|---|
| W7 MLA | KV cache 显存 |
| W14 NSA | 注意力计算量(研究阶段) |
| W16 DSA in V3.2(本文) | 注意力计算量(工程落地) |
| W18 V4 | (待详解) |
下一篇 W17 我们详解 V4 prelude 系列——这是 V4 发布前 DeepSeek 在 2025 下半年到 2026 年初发布的几项 supporting work,包括 inference-time scaling、reward modeling 新方法、agentic capabilities 等。这些工作累积起来成为 V4 的方法论基础,理解它们就理解了 V4 真正”贵”在哪些维度。
参考资料
- DeepSeek-AI, DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, arXiv:2512.02556, 2025.
- DeepSeek-V3.2-Exp GitHub repository:
- Introducing DeepSeek-V3.2-Exp, DeepSeek API Docs, 2025-09-29.
- DeepSeek-V3.2-Exp in vLLM: Fine-Grained Sparse Attention in Action, vLLM Blog, 2025-09-29.
- Yuan et al., Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, arXiv:2502.11089, 2025.
- DeepSeek-AI, DeepSeek-OCR: Contexts Optical Compression, arXiv:2510.18234, 2025.
- DeepSeek-AI, DeepSeek-V3 Technical Report, arXiv:2412.19437, 2024.
- A Technical Tour of the DeepSeek Models from V3 to V3.2, Sebastian Raschka, 2025.
- DeepSeek Sparse Attention: How Lightning Indexing Revolutionizes LLM Efficiency, Medium, 2025.
![]()
2026-06-12 at 5:55 下午
2.2 说 indexer 对每个 query 与所有历史 K 算 score,仍是 O(N) per query——那么在 decode 阶段,序列越长 indexer 这步本身就越贵