
转载本文请注明出处:https://yudonglee.me/deepseek-r1-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 4 月,2026 年 6 月有修订,补充了与系列后续论文的呼应。
本文是 DeepSeek 论文专题系列的第 12 篇,详解 DeepSeek 公司 2025 年 1 月发表的 DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (arXiv:2501.12948)。这是 DeepSeek 推理主线的旗舰之作——也是开源 reasoning 模型史上影响力最大的一篇 paper。论文包含两个独立模型:(1) DeepSeek-R1-Zero:从 V3-Base 出发,跳过 SFT 直接做 RL,仅用 rule-based reward,首次实证证明纯 RL 可以让 base model 发展出长链推理能力。训练过程中观察到著名的 “Aha moment”——模型自发地学会 self-reflection、backtracking、verification 等元认知行为;(2) DeepSeek-R1:在 R1-Zero 的基础上加入 cold-start SFT + 四阶段训练 pipeline,输出更可读、更稳定、更通用的 production-quality reasoning 模型。R1 在 AIME 2024 (79.8%)、MATH-500 (97.3%)、Codeforces (96.3 percentile) 上达到或超过 OpenAI o1 水平。论文同时发布了 R1-Distill 系列(Qwen 1.5B-32B 与 Llama 8B-70B),证明 R1 的 reasoning 能力可以高效蒸馏到小模型。R1 的发布直接引爆了”DeepSeek moment”——2025 年 1 月 27 日 NVIDIA 单日下跌 17%($590B 市值蒸发),重新定义了 AI 行业对 reasoning model scaling 的预期。
一、为什么 R1 是开源 reasoning 的里程碑
W1 序言里我们把 DeepSeek 论文分为四条主线,推理(Reasoning)主线的演化路径是:

R1 在这条主线上是真正的旗舰——前面所有方法论积累(GRPO、合成数据、proof assistant feedback、tree search)都为 R1 铺路。
1.1 R1 之前的 reasoning model 现状
2024 年 9 月 OpenAI 发布 o1——业界第一个 large-scale “thinking-then-answering” 模型。o1 在 AIME 2024 上达到 83.3%(相比 GPT-4o 的 9.3% 是 9× 提升),震惊业界。但 OpenAI 没有公开 o1 的训练细节,开源社区只能从 API 调用观察其行为,无法复刻。
开源社区在 R1 之前的尝试:
- Qwen QwQ-32B-Preview (2024-11):用类似 o1 的 long-CoT 数据 SFT,AIME 2024 50.0%
- Llama-3-Reasoning 各种 fine-tune:用 SFT 模拟 long-CoT,效果有限
- rStar (Microsoft, 2024-11):用 MCTS + SLM 模拟推理,但需要外部推理框架
这些工作的共同点是还原 o1 的”行为”(长 CoT 输出),但没有捕捉到 o1 的”训练方法”。业界普遍认为 o1 需要某种神秘的 reasoning training 配方,开源难以复刻。
1.2 R1 的两个关键突破
R1 论文给出了两个开源界从未有过的突破:
- R1-Zero 证明:纯 RL 就能从 base model 训出 reasoning 能力——不需要任何 SFT、不需要长 CoT 数据集、不需要 reward model,只需要 GRPO + rule-based reward
- R1 系列 Match OpenAI o1:在 AIME、MATH、Codeforces 等推理 benchmark 上,开源 R1 第一次与闭源 o1 平起平坐
这两点合起来彻底改变了开源 reasoning model 的格局——从”模仿 o1 行为”升级到”用开源方法独立训出 o1 级模型”。
1.3 R1 与 V3 的关系
R1 直接以 W12 详解过的 V3-Base (671B/37B MoE) 为起点。整个 R1 训练 pipeline 完全建立在 V3 的基础设施之上:
| V3 的贡献 | R1 中的体现 |
|---|---|
| 671B/37B MoE 架构 | 直接复用,参数不变 |
| MLA 长上下文 | R1 的 long-CoT 输出可达数千 token,需要 long context |
| Aux-Loss-Free 训练稳定性 | R1 RL 阶段的 router 不变(继承 V3) |
| FP8 + DualPipe | R1 RL 训练同样跑在 FP8 + DualPipe 上 |
| GRPO(V3 alignment 阶段) | R1 直接复用 GRPO,但 reward 设计完全不同 |
可以说没有 V3,R1 不可能在同样的成本结构内训练完成——V3 是 R1 的物理基础设施,R1 是 V3 之上的”reasoning 训练 add-on”。
二、R1-Zero:纯 RL 的可行性证明
R1-Zero 是 R1 论文中学术意义最大的一部分——它证明了reasoning 能力可以完全从 RL 中”涌现”,不需要任何 reasoning trace 训练数据。
2.1 R1-Zero 的训练设计
R1-Zero 的训练设置非常简洁:
- 基模:DeepSeek-V3-Base(不是 V3-Chat,是没经过 SFT/RL 的 base model)
- 训练算法:GRPO(W5 详解)
- 训练数据:约 144K 数学题和代码题(带 ground-truth 答案)
- 跳过 SFT:直接从 V3-Base 开始 RL,不经过任何监督微调
最关键的是 reward 设计——R1-Zero 完全用 rule-based reward:

- Accuracy Reward
 :
: - 数学题:把模型输出的答案 extract 出来,与 ground truth 比较,对 = 1.0、错 = 0.0
- 代码题:把模型生成的代码送入 sandbox 执行 unit test,通过 = 1.0、失败 = 0.0
- Format Reward
 :要求模型把推理过程放在
:要求模型把推理过程放在 <think>...</think>标签内、最终答案放在<answer>...</answer>标签内。格式正确 = 0.1,格式错 = 0
注意几个反直觉的细节:
- 没有 reward model:没有用 V3 或任何模型给输出打分
- 没有过程奖励:reward 只看最终答案,不看推理过程中间步骤
- 没有 KL penalty:标准 PPO/GRPO 通常加 KL[π_θ || π_ref] 防漂移,R1-Zero 直接省略了
这套极简的 reward 设计是 R1-Zero 的核心创新——证明 reasoning 能力不需要复杂的 reward engineering就能涌现。
2.2 Aha Moment:reasoning 能力的自发涌现
R1-Zero 训练过程中,DeepSeek 团队观察到一个被广泛传播的现象——Aha Moment。
具体地说,在训练大约 4000 步左右,模型生成的 reasoning trace 中出现了类似下面的内容:
模型自发地学会了:
- Self-reflection:检查自己的推理过程(”Wait, let me reconsider”)
- Backtracking:发现错误后退回重新尝试(”Let me try a different approach”)
- Step-by-step verification:把推理步骤拆细,逐步验证
- Calculation-then-check:先计算再验算
这些是人类推理时的元认知行为——R1-Zero 没有被任何训练数据明确教过这些,纯粹从”答对得分、答错不得分”的简单 reward signal 中学到了它们对提高准确率有帮助。
Aha Moment 的本质:这是 RL 在足够多 trial-and-error 后发现的”reasoning 策略”。模型尝试了短回答(容易错)、长回答(也会错)、自我检查的回答(更准确),最终 RL gradient 强化了第三种行为。这是 RL 在 reasoning 任务上的最早一次清晰可观察的”策略发现”。
2.3 训练动态:response length 自发增长
R1-Zero 训练过程中另一个关键观察是 response length 的自发增长:
- 训练初期:平均 response length ~500 token
- 训练中期:~1500 token
- 训练后期:~4000-6000 token
response 越长,模型有更多空间做 self-reflection 与 verification。这种”长度增长”完全是 RL 自发发现的——没有任何 reward 直接鼓励长输出。
更妙的是 accuracy 与 length 高度相关:随着 length 增长,AIME 2024 准确率从 ~15% 提升到 ~71%。这印证了”more thinking → better answers”的直觉。
2.4 R1-Zero 的评测结果
R1-Zero 训练完成后的核心 benchmark:
| Benchmark | DeepSeek-V3 (基模) | R1-Zero | 提升 |
|---|---|---|---|
| AIME 2024 (pass@1) | 39.2% | 71.0% | +31.8 |
| AIME 2024 (cons@64) | – | 86.7% | – |
| MATH-500 | 90.2% | 95.9% | +5.7 |
| GPQA-Diamond | 59.1% | 73.3% | +14.2 |
| LiveCodeBench | 40.5% | 50.0% | +9.5 |
R1-Zero 在数学和代码任务上的提升非常显著——AIME 从 39.2% 跳到 71.0% 是 1.8× 的提升。这说明纯 RL 确实能从 base model 中”激发”reasoning 能力,且效果非常好。
2.5 R1-Zero 的局限
但 R1-Zero 也有几个明显问题:
- 可读性差:long-CoT 输出经常中英文混杂(一段中文一段英文随意切换)
- 格式不一致:有时忘记
<think>标签,有时回答冗长 - 重复内容:长 reasoning 中常出现 redundant verification
- 通用对话能力弱:因为只在数学/代码 prompt 上做 RL,其他任务表现一般
这些问题让 R1-Zero 不能直接当产品发布——你不能给用户一个一会儿说中文一会儿说英文的对话助手。
为了得到 production-quality 模型,DeepSeek 团队设计了更复杂的 R1 训练 pipeline。
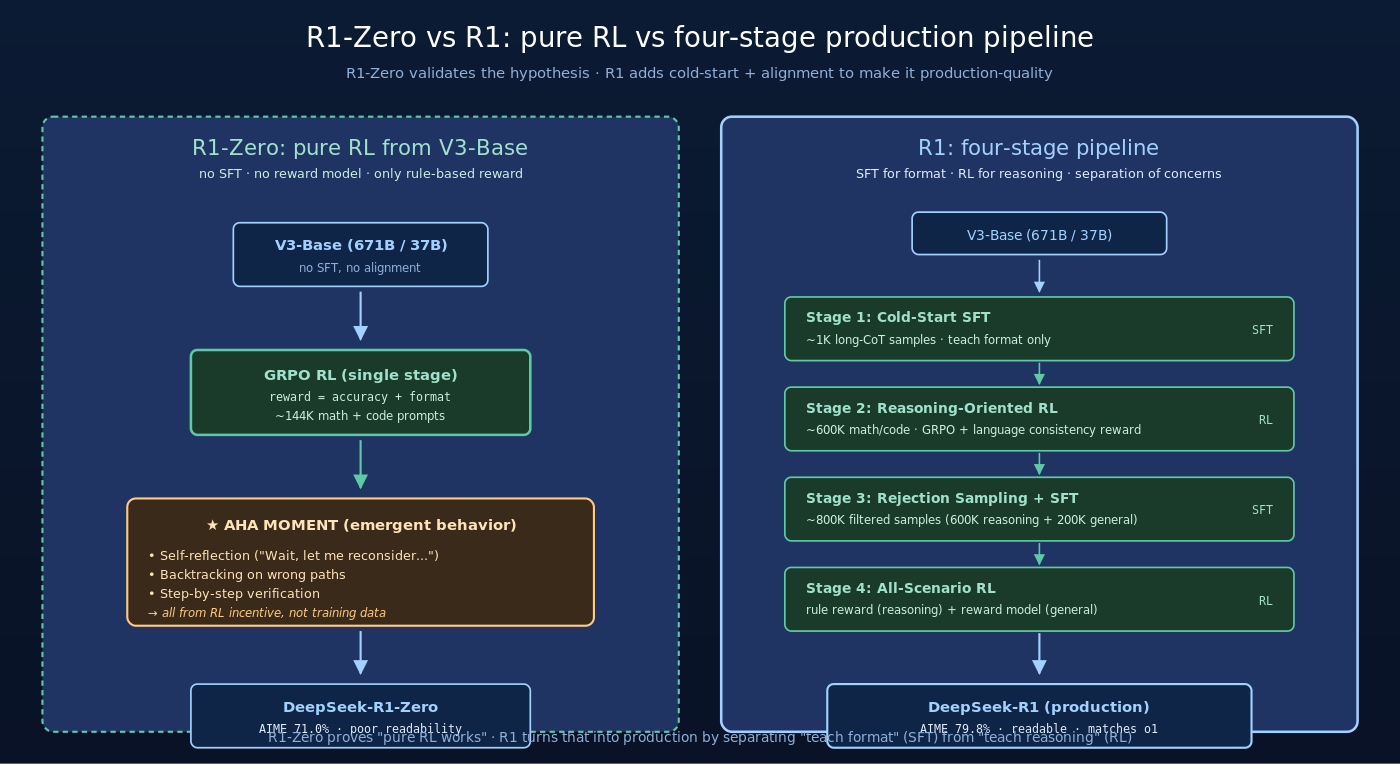
三、R1:四阶段 production-quality 训练 pipeline
R1 的核心思路是用少量 SFT 数据”指导”RL,让 RL 在保持 reasoning 能力的同时输出可读、统一格式、通用对话能力强的模型。整个 pipeline 分四阶段。
3.1 Stage 1:Cold-Start SFT
R1 的第一步是用极少量(约 1000 条)高质量 long-CoT 样本对 V3-Base 做 SFT。这些样本的来源:
- 从 V3 + prompting 生成长 CoT 输出
- 从 R1-Zero 的高分输出中筛选
- 人工标注修正格式、清理语言混杂
样本格式严格遵循:
Cold-start 阶段非常轻量(约 1000 步 SFT)。它的作用是:
- 给模型 “清晰格式的种子“
- 让模型从 R1-Zero 的混乱输出中收敛到可读输出
- 不影响 reasoning 能力的发展空间(因为只有 1000 条样本,模型很容易在后续 RL 中超越这些样本质量)
Cold-start 的设计哲学:用最少的人工干预解决 R1-Zero 的可读性问题。SFT 用来教”格式”,RL 用来教”推理”。两者分工明确,互不干扰。
3.2 Stage 2:Reasoning-Oriented RL
第二阶段:在 cold-start 模型上做大规模 GRPO,但 reward 比 R1-Zero 更精细:

新增的 Language Consistency Reward 解决 R1-Zero 的中英文混杂问题:
- 检测 response 中中文字符 / 英文字符的比例
- 如果不一致(如中文 prompt 但输出大量英文),扣分
- 比例阈值约 0.95
这个新 reward 让 R1 在保持 reasoning 能力的同时输出语言一致的回答——一个非常工程化的修复。
Stage 2 训练数据扩展到 ~600K 道数学/代码/STEM 题。RL 训练运行直到模型 reasoning benchmark 不再提升。
3.3 Stage 3:Rejection Sampling + SFT
Stage 2 完成后,模型已经是”reasoning 专家”,但仍不擅长 general conversation。Stage 3 用 rejection sampling + SFT 扩展能力:
Step 1: 用 Stage 2 模型生成大量样本
对 ~600K 个 reasoning prompt 和 ~200K 个 general prompt,让 Stage 2 模型生成多个候选回答。
Step 2: Rejection Sampling 过滤
- 对 reasoning 样本:用 ground-truth 答案验证,保留答对的
- 对 general 样本:用 V3 当 critic 评分,保留高分的
Step 3: 在 V3-Base 之上做 SFT
用上述 ~800K 筛选样本对 V3-Base(注意是 base model 不是 Stage 2 模型)做 SFT,得到一个”通用且会推理”的模型。
为什么要回到 V3-Base 重新 SFT 而不是在 Stage 2 之上继续?因为 Stage 2 模型已经偏向 reasoning 任务,直接做 general SFT 容易导致 catastrophic forgetting。回到 base model 重新开始 SFT,可以让模型在通用与推理两方面都达到 balanced 状态。
3.4 Stage 4:All-Scenario RL
最后一阶段是全场景 RL——既要保持 reasoning 能力又要 align with 人类偏好。
reward 由两部分组成:

- Rule-based reward:仍然用在 reasoning 任务(math/code)
- Reward model:在 general dialogue 任务上用 reward model 评分
GRPO 训练同时处理 reasoning 和 general prompt,让模型在两个维度上同时优化。这一阶段大约 1000 步训练,让模型从”reasoning 专家 + general 笨拙”变成”reasoning 专家 + general 也不错”。
3.5 完整 pipeline 总结
整个 R1 训练 pipeline:
| 阶段 | 起点 | 训练方式 | 数据规模 | 目标 |
|---|---|---|---|---|
| Stage 1 | V3-Base | SFT | ~1K | 教格式 |
| Stage 2 | Stage 1 | GRPO RL | ~600K | 教推理 |
| Stage 3 | V3-Base | SFT | ~800K | 教通用能力 |
| Stage 4 | Stage 3 | GRPO RL | mixed | 全场景对齐 |
整个 pipeline 的”四阶段”设计本身是一种关注点分离——每个阶段只负责一种能力,避免目标冲突。这与 W10 Aux-Loss-Free、W11 Janus 的”解耦”哲学完全一致。
四、R1 Distillation:把 reasoning 能力蒸到小模型
R1 论文还有一个非常重要的延伸实验——Distillation。
4.1 Distillation 的设计
DeepSeek 团队用 R1 生成的 ~800K 高质量 reasoning 样本(包含详细的 long-CoT trace),对开源小模型做 SFT:
- Qwen 系列:1.5B / 7B / 14B / 32B
- Llama 系列:8B / 70B
注意 distillation 不需要 RL——只是普通的 SFT,把 R1 的 reasoning trace 当 training data。
4.2 Distillation 结果
R1-Distill 系列的 benchmark 表现:
| 模型 | AIME 2024 | MATH-500 | GPQA |
|---|---|---|---|
| Qwen2.5-32B-Instruct(baseline) | 16.7 | 78.0 | 41.4 |
| QwQ-32B-Preview(专门推理模型) | 50.0 | 90.6 | 50.5 |
| R1-Distill-Qwen-32B | 72.6 | 94.3 | 62.1 |
| Llama-3.3-70B-Instruct | 13.0 | 67.4 | 49.0 |
| R1-Distill-Llama-70B | 70.0 | 94.5 | 65.2 |
| R1-Distill-Qwen-7B | 55.5 | 92.8 | 49.1 |
| R1-Distill-Qwen-1.5B | 28.9 | 83.9 | 33.8 |
关键观察:
- R1-Distill-Qwen-32B (72.6 AIME) 超过 QwQ-32B-Preview (50.0):用 R1 蒸馏的小模型超过同尺寸的专门推理模型
- R1-Distill-Qwen-1.5B (28.9 AIME) 接近 GPT-4o (9.3):1.5B 蒸馏模型在 reasoning 任务上击败了 GPT-4o
- R1-Distill 全面优于直接 RL:DeepSeek 实验显示,用 R1 输出做 SFT 比让小模型自己跑 R1 那套 RL 流程效果更好(因为小模型的 base capacity 不够支撑 long-CoT 涌现)
4.3 Distillation 的方法论意义
R1-Distill 系列的成功证明了几件事:
- Reasoning 能力可以”传染”:一旦在大模型上训出来,可以高效地传递给小模型
- 小模型不需要复杂 RL:直接学习大模型的 reasoning trace 就能获得 reasoning 能力
- 蒸馏模型可以走商业化:32B 模型在单卡 GPU 上可推理,1.5B 模型可以跑在手机上,让 reasoning 能力真正”民主化”
R1-Distill 系列的发布让任何开发者都能在自己的硬件上跑 reasoning 模型——这是 R1 商业冲击的另一面。
五、评测全景:R1 vs OpenAI o1
R1 发布时(2025-01)与 OpenAI o1 的全面对比:
5.1 数学与推理 benchmark
| Benchmark | OpenAI o1 | DeepSeek-R1 | GPT-4o | Claude 3.5 Sonnet |
|---|---|---|---|---|
| AIME 2024 (pass@1) | 79.2 | 79.8 | 9.3 | 16.0 |
| AIME 2024 (cons@64) | – | 86.7 | – | – |
| MATH-500 | 96.4 | 97.3 | 74.6 | 78.3 |
| GPQA-Diamond | 75.7 | 71.5 | 49.9 | 65.0 |
| LiveCodeBench | 63.4 | 65.9 | 33.4 | 36.3 |
关键观察:
- R1 在 AIME 2024 上超过 o1(79.8 vs 79.2)——这是开源 reasoning 模型第一次超过 OpenAI 闭源模型在 frontier 推理 benchmark 上的表现
- R1 在 MATH-500 上同样超过 o1(97.3 vs 96.4)
- R1 的 GPQA 略低于 o1(71.5 vs 75.7)——GPQA 是博士级科学问答,o1 的世界知识仍有优势
- R1 大幅领先 GPT-4o 与 Claude 3.5 Sonnet——证明 reasoning 模型与传统 chat 模型处于不同水位
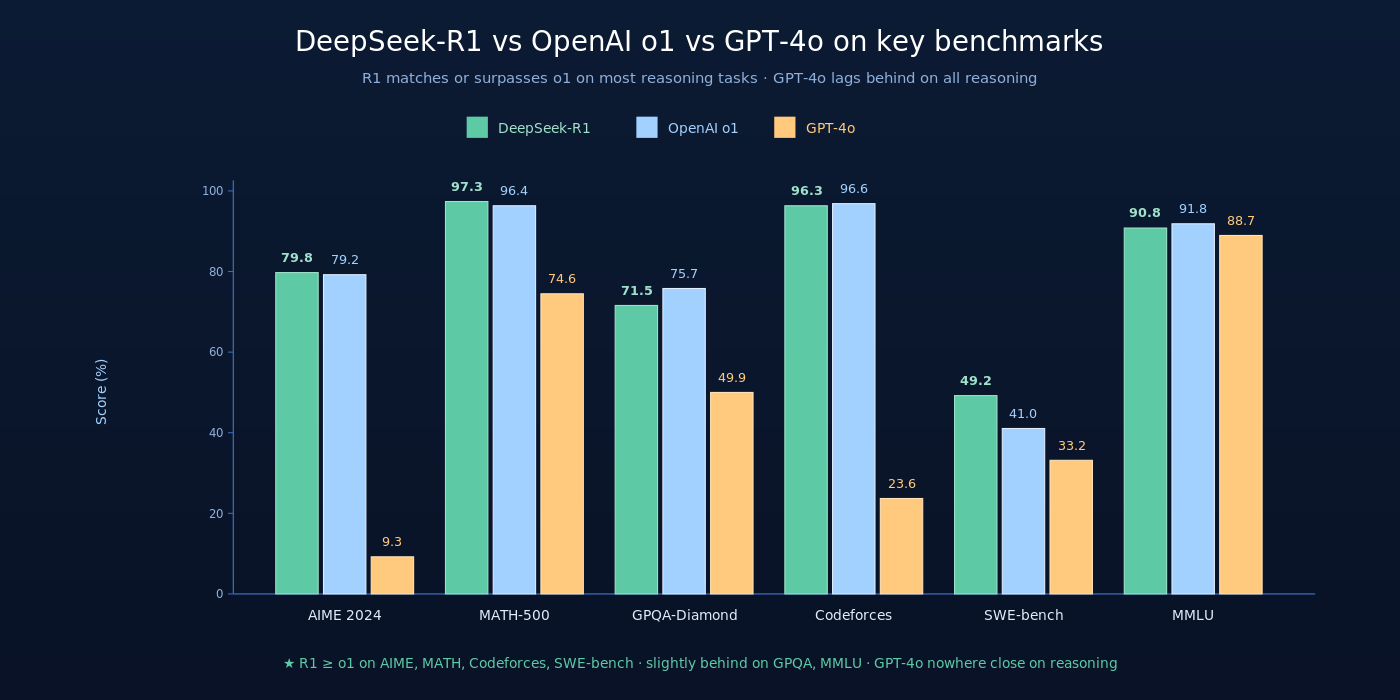
5.2 代码与编程
| Benchmark | OpenAI o1 | DeepSeek-R1 | GPT-4o |
|---|---|---|---|
| Codeforces (percentile) | 96.6 | 96.3 | 23.6 |
| SWE-bench Verified | 41.0 | 49.2 | 33.2 |
| LiveCodeBench (Pass@1) | 63.4 | 65.9 | 33.4 |
R1 在编程任务上全面对齐或超过 o1——SWE-bench Verified(真实 GitHub issue 修复)上 R1 (49.2) 显著超过 o1 (41.0),说明 R1 不仅在竞赛代码上强,也擅长真实工程任务。
5.3 通用能力
| Benchmark | OpenAI o1 | DeepSeek-R1 | GPT-4o |
|---|---|---|---|
| MMLU | 91.8 | 90.8 | 88.7 |
| MMLU-Pro | 84.0 | 84.0 | 73.3 |
| AlpacaEval | 30.7 | 87.6 | 51.1 |
| ArenaHard | – | 92.3 | – |
R1 在通用对话 benchmark 上也很强——AlpacaEval 87.6 远高于 GPT-4o 的 51.1。这是 R1 Stage 4 全场景 RL 的成果,证明 R1 不只是”reasoning 专家”,也是”全能 chatbot”。
5.4 整体结论
R1 在大多数 reasoning benchmark 上与 o1 同水位甚至略超,在通用 benchmark 上略低但仍非常竞争。考虑到 R1 是完全开源 + MIT 协议 + API 价格仅为 o1 的 1/30,R1 的 cost-performance 比例无可争议。
六、DeepSeek Moment:1 月 27 日的市场冲击
R1 发布两周后,2025 年 1 月 27 日,全球资本市场发生了被后来称为 “DeepSeek Moment” 的事件。当天:
- NVIDIA 单日下跌 17%,市值蒸发约 5900 亿美元——史上单日最大市值损失
- Broadcom、TSMC、Vertiv 等 AI 基础设施股集体下跌 10-20%
- OpenAI、Anthropic、xAI 的估值预期被重新审视
- 整个”AI scaling = 无限 CapEx”叙事被动摇
事件的核心是 R1 论文揭示的事实:
一个完全开源、训练成本不到 GPT-4o 三十分之一的模型,可以匹敌 OpenAI o1。
这对市场的逻辑挑战是:
- 资本支出假设被动摇:之前 AI 行业的假设是”frontier model 需要 100M+ 美元 + 50,000+ GPU”。R1 证明这是错的——558 万美元 + 2048 GPU 就够了
- CapEx ROI 被重估:Microsoft、Meta、Google 已经投入数百亿美元买 GPU,现在面对一个用极小成本就能匹敌的开源对手
- AI infrastructure stocks 的估值被压缩:如果 GPU 需求远低于预期,NVIDIA 的高估值难以维持
值得注意的是,R1 论文的方法论部分完全开源——R1-Zero 的 GRPO 配置、R1 的四阶段 pipeline、distillation 流程全部详细公开。这意味着任何团队都可以复刻 R1。市场对”无法复刻的护城河”的预期也因此被重置。
DeepSeek Moment 后 NVIDIA 股价部分恢复,但行业对”高效训练 + 开源 reasoning”的关注度永久性提升了一个台阶。Microsoft、Meta、Anthropic 都在 R1 之后调整了 reasoning 模型路线图,更注重”少算力 + 多优化”。
我对”DeepSeek Moment”叙事的三点冷思考
市场叙事往往比论文跑得快。把上面的市场反应放回技术语境里看,我认为有三个地方值得泼冷水:
- “558 万美元”是一个被普遍误读的口径。这个数字出自 V3 技术报告,统计的是最后一次成功预训练的 GPU 租用成本折算——不含前期实验试错、数据构建、人力和自建集群的资本开支;严格说它还是 V3 的数字,R1 在其上的 RL 训练成本论文并未完整披露。SemiAnalysis 当时就估算 DeepSeek 的硬件总投入远超这个量级。拿”600 万美元干翻 OpenAI”做标题没问题,拿来做投资或工程决策的依据就危险了。
- “匹敌 o1″成立的范围比传播中窄。R1 对齐 o1 的证据集中在 AIME / MATH / Codeforces 这类可验证 reward 的任务上——这恰恰是 GRPO + rule-based reward 路线最受益的分布。而在指令遵循、多语言长尾、事实性这些维度,不少早期使用者的反馈明显弱于 o1。Benchmark 对齐 ≠ 产品能力对齐,这个区别在当时的狂热里几乎没人提。
- 方法论开源 ≠ 人人可复刻。GRPO 配置和四阶段 pipeline 公开后,社区(如 HuggingFace 的 Open-R1)很快复现了 distill 路线,但 R1-Zero 式”从 base 模型直接 RL 出 reasoning”的复现要困难得多——它对 base model 质量、reward 工程和数据配方高度敏感。换句话说,R1 真正的护城河不在 RL 算法,而在 V3 这个底座。
事后看,NVIDIA 股价的恢复也印证了另一层逻辑:训练效率提升并没有减少算力总需求,反而通过降低单位成本扩大了总盘子——Nadella 在事发当天引用的”Jevons 悖论”,可能是那一周最被低估的判断。
七、与 OpenAI o1 / o3 的对比与差异
R1 与 OpenAI o1/o3 系列的对比:
7.1 训练方法对比
| 维度 | OpenAI o1 (推测) | DeepSeek-R1 |
|---|---|---|
| 训练算法 | PPO + reward model | GRPO + rule-based reward |
| 训练数据 | 闭源,可能包含人类标注 long-CoT | 开源 reasoning prompt + V3 生成 |
| 是否需要 SFT | 是 | R1-Zero 不需要;R1 仅 1K cold-start |
| 推理时是否暴露 CoT | 不暴露(思考过程隐藏) | 完全暴露(用户可见) |
| 开源程度 | 闭源 | MIT 完全开源 |
OpenAI 选择隐藏 o1 的 CoT 输出,理由是”保护模型 IP”。R1 选择完全暴露 CoT——这让用户可以验证模型的推理过程,也让研究者可以研究 reasoning 行为。
7.2 部署与商业差异
| 维度 | OpenAI o1 | DeepSeek-R1 |
|---|---|---|
| API 定价(输入) | $15/M tokens | $0.55/M tokens (~3.6%) |
| API 定价(输出) | $60/M tokens | $2.19/M tokens (~3.6%) |
| 开源权重 | 无 | MIT 协议完全开源 |
| 自部署支持 | 不支持 | 支持,671B 单机 H100×8 可推理 |
R1 的开源 + 低价让它在企业落地中比 o1 容易得多——尤其对数据敏感的金融、医疗、政府场景,私有部署 R1 是合规上的唯一选项。
7.3 后续发展
R1 之后,OpenAI 在 2025 年 4 月发布 o3——号称在 ARC-AGI 上取得突破。但 o3 的训练成本估计 >$1B,公开 API 不久后被 OpenAI 限制访问。DeepSeek 在 2025 年 5 月发布 R1-0528(小幅升级),后续工作持续在 W14 NSA、W15 Math-V2 等论文上推进。
可以说 R1 之后 OpenAI 与 DeepSeek 在 reasoning model 路线上分化:
- OpenAI:继续走”更大模型 + 更多算力”路线(o3、o4)
- DeepSeek:走”更高效训练 + 更精细蒸馏”路线(R1-Distill、Math-V2、V3.2)
两条路线都有价值,长期会持续竞争。
八、局限与衔接 NSA / V3.2
R1 是一项里程碑工作,但仍有几个明显局限:
- 多语言能力不均衡:R1 的训练数据以中英文为主,对法语、日语、阿拉伯语等其他语言的 reasoning 能力较弱
- 长上下文极限仍 128K:与 V3 相同。复杂 reasoning 任务(如分析整本书)超出 128K 上下文时性能下降
- 工具调用能力较弱:R1 不擅长 function calling、code interpreter 等 agentic 工具使用——这是 W17 V4 prelude 的发力方向
- 多模态缺失:R1 仅文本输入。多模态 reasoning(看图思考)需要等 VL3 / Janus-Pro 与 R1 的融合
- Hallucination 在 long-CoT 中放大:长 reasoning trace 中模型可能在中间步骤产生错误事实,影响最终答案
衔接 NSA / V3.2
R1 的 128K 上下文上限是后续工作的主要突破点:
- W14 NSA (Native Sparse Attention):2025-02 发布,把 attention 从 dense 改为 sparse,让上下文上限突破 1M token
- W16 V3.2:把 NSA 集成到 V3 架构,发布支持百万级上下文的版本
这两项工作让 R1 系列的 reasoning 能力可以应用到更长的输入——比如”分析一整本论文””调试一个完整 codebase”。
写在最后
DeepSeek-R1 是 DeepSeek 系列里影响力最大的一篇 paper——也是开源 AI 历史上最重要的论文之一。
它做对的三件事:
- R1-Zero 实证证明纯 RL 的可行性:第一次清晰证明”reasoning 能力不需要 reasoning trace 训练数据”,仅靠 RL incentivization 就能涌现 self-reflection、backtracking、verification 等元认知行为
- R1 四阶段 pipeline 提供可复制的工程方案:cold-start SFT → reasoning RL → general SFT → all-scenario RL,每个阶段目标清晰,整体可以被任何团队复刻
- Distillation 系列把 reasoning 民主化:1.5B 蒸馏模型超过 GPT-4o,让 reasoning 能力可以跑在手机上
这三件事的累积效应不仅是技术突破,更是整个 AI 行业格局的重新洗牌。1 月 27 日的 DeepSeek Moment 让全行业重新审视”高 CapEx + 闭源”路线的可持续性。
回到这个系列的整体脉络,R1 是 DeepSeek 12 个月内 12 篇论文积累的”高潮”:
- W3 DeepSeekMoE → 提供 V3 的架构骨架
- W5 DeepSeekMath → 提供 GRPO 算法
- W7 V2/MLA → 提供长上下文经济性
- W8 Prover → 提供 environment reward 方法论
- W10 Aux-Loss-Free → 提供训练稳定性
- W12 V3 → 提供 frontier-class base model
- W13 R1(本文)→ 总集成 + reasoning 突破
可以说每一篇论文都是 R1 的工程拼图。
下一篇 W14 我们详解 NSA (Native Sparse Attention)(arXiv:2502.11089),这是 DeepSeek 在 R1 之后发布的注意力机制创新——把 attention 从 dense 改为 sparse,让上下文窗口突破 1M token。NSA 是 R1 之后 reasoning 模型扩展到”超长推理”的关键基础设施。
参考资料
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv:2501.12948, 2025.
- DeepSeek-R1 GitHub repository:
- OpenAI, Learning to Reason with LLMs, technical post about o1, 2024-09.
- DeepSeek-AI, DeepSeek-V3 Technical Report, arXiv:2412.19437, 2024.
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, arXiv:2402.03300, 2024.
- Liu et al., Understanding R1-Zero-Like Training: A Critical Perspective, arXiv:2503.20783, 2025.
- Team Qwen, QwQ-32B-Preview Release, blog post, 2024-11.
- Wang et al., Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, arXiv:2408.15664, 2024.
- SemiAnalysis, DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts, 2025-01. semianalysis.com
- Hugging Face, Open-R1: A fully open reproduction of DeepSeek-R1. github.com/huggingface/open-r1
![]()
2026-06-09 at 5:59 下午
R1-Zero 用 144K 题、R1 Stage 2 用 600K 题——这些数学/代码题的 ground-truth 答案是怎么大规模获取的?