
转载本文请注明出处:https://yudonglee.me/deepseek-grm-explained/ | 作者:yudonglee
本文是 DeepSeek 论文专题系列的第 16 篇,详解 DeepSeek 公司 2025 年 4 月发表的 Inference-Time Scaling for Generalist Reward Modeling (arXiv:2504.02495)。这是 V4 发布前 DeepSeek 在 reward modeling 上的关键准备工作——把 R1 的 outcome-based reward、V2 的 verifier critique 思想推广到更普适的 Generalist Reward Modeling (GRM) 场景。论文提出两个核心创新:(1) Pointwise GRM 架构——把 reward model 重新设计为”生成式批改员”,对每个输入独立输出 critique 与分数,而非传统的成对比较或单点回归;(2) SPCT (Self-Principled Critique Tuning)——通过在线 RL 训练让 GRM 学会自适应生成评分原则 (principle) 与精准批评 (critique),再用并行采样 + meta-RM 投票实现推理时 scaling。DeepSeek-GRM 在 RewardBench、PandaLM 等 reward model benchmark 上同时超过 GPT-4o / Claude-3.5-Sonnet 的内部 RM。更重要的是,这套 GRM 是 V4 训练时使用的 reward model 直接前驱——理解 GRM 就理解了 V4 RL 阶段所依赖的”评分基础设施”。本文同时简略提及同期 prelude 工作 DeepSeek-Prover-V2 与 R1-0528,作为 V4 完整方法论的几条支线。
一、V4 前夕:reward modeling 是 reasoning training 的最后短板
W1 序言把 DeepSeek 论文分为四条主线,通用 LLM 主线的演化路径是:

V3.2(W16 详解)已经把 attention 经济性问题解决到位(DSA)、reasoning 主线在 R1 / Math-V2 上演化到金牌水位、多模态在 Janus / VL 系列上推进到顶级。V4 的下一步要走的方向是什么?
答案是 reward modeling 本身的 scaling。
1.1 R1 与 V2 揭示的瓶颈
W13 R1 和 W15 Math-V2 都展示了 RL training 对 reasoning model 的重要性。但两者都依赖特定形态的 reward:
- R1 使用 rule-based reward:math 题答案对错、code unit test 通过率、format 标签匹配——只能用在有客观答案的场景
- V2 使用 verifier critique reward:训练一个独立的 685B verifier 模型给 generator 打分——只适用于数学证明这种”步骤可验证”的领域
但真实世界的大部分任务没有这种”对错可判定”的特征——比如让模型写一首诗、做产品 design review、做客户支持对话。这些场景的 reward 必须依赖人类偏好或某种主观评判。
这就是传统 RLHF (Reinforcement Learning from Human Feedback) 范式的来源——训练一个 reward model 模仿人类偏好。但传统 RM 在 R1 之后暴露了几个根本问题:
1.2 传统 reward model 的三个根本问题
问题一:架构不支持 scaling
主流 reward model 用 Bradley-Terry pairwise loss 训练——给定两个回答 A 和 B,模型预测哪个更好。这种架构有两个限制:
- 一次只能看一对,无法处理三个以上候选的复杂偏好
- 输出是单个 scalar(”A 好”),没有理由——模型无法解释为什么 A 比 B 好
更关键的是,传统 RM 的推理过程是单次前向 inference——没有像 R1 那样”思考更久得分更高”的 scaling 机制。
问题二:训练时 scaling 与推理时 scaling 错位
R1 系列证明了推理时投入更多 compute 可以显著提升 reasoning 模型质量(long CoT、test-time sampling 等)。但reward model 没有对应的推理时 scaling 机制——它只能给出一个固定 inference cost 的分数。
这就形成一个不对称:generator 越来越强(用更多推理算力),但 critic(reward model)原地踏步——RL training signal 的”分辨率”成为新的瓶颈。
问题三:principle 与 critique 分离
传统 RM 直接给一个 scalar 分数,但人类做评判时往往先想清楚”判断标准”(principle),再针对具体回答写”评语”(critique),最后才给出分数。这种”先 principle 后 critique”的过程被传统 RM 完全省略,结果是 RM 的判断难以解释、难以校准、难以让 generator 真正学到什么。
1.3 DeepSeek-GRM 的回应
DeepSeek-GRM 论文针对上述三个问题给出的解法是:
- 架构升级:把 RM 从”输出 scalar”改为”生成 principle + critique + score”的生成式 GRM
- 训练算法升级:用 SPCT (Self-Principled Critique Tuning) 在线 RL 训练 GRM 学会主动生成 principle 与 critique
- 推理 scaling 升级:通过并行采样 + meta-RM 投票,让 RM 推理时也能用更多 compute 换取更高质量
这三个升级合起来让 reward modeling 第一次具备了与 generator 对等的 scaling 能力——给 V4 的 RL 训练奠定基础。下面分别展开。
二、Pointwise GRM:从 scalar 到 generative
2.1 三种 reward model 范式
业界 reward model 主要有三种范式:
A. Scalar RM (传统)
输入:prompt + response
输出:单个 scalar 分数(如 0.7)
代表:OpenAI’s original RLHF RM, Anthropic Claude RM
- 优点:训练简单,推理快
- 缺点:无解释,无 scaling,质量上限低
B. Pairwise RM (改进版)
输入:prompt + response A + response B
输出:A 好 / B 好(或 P(A > B))
代表:DPO 训练用的 RM
- 优点:直接捕捉偏好
- 缺点:固定 pairwise,无法处理三个以上选项
C. Pointwise Generative RM (DeepSeek-GRM 的选择)
输入:prompt + response
输出:自然语言 critique + 分数 + reasoning trace
代表:DeepSeek-GRM
- 优点:可解释、可 scale、支持任意候选数
- 缺点:训练复杂、推理 slower
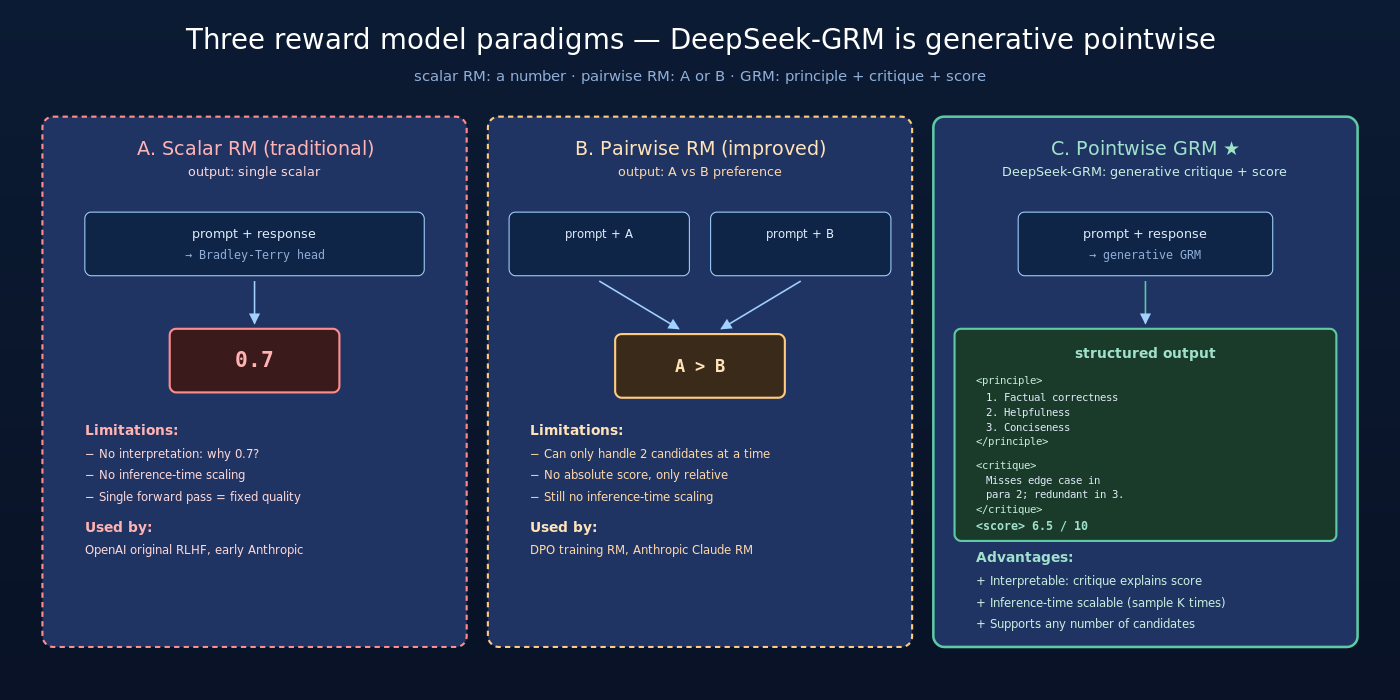
2.2 DeepSeek-GRM 的输出格式
DeepSeek-GRM 对每个 (prompt, response) 对生成结构化输出:
这种格式让 GRM 的输出像人类批改员一样——先想清楚标准,再针对回答写评语,最后给分。
2.3 为什么 pointwise 而非 pairwise
主流方案如 Anthropic constitutional AI 也用 critique-style RM,但通常是 pairwise(比较两个回答)。DeepSeek-GRM 坚持 pointwise(独立评估每个回答),原因有三:
- 支持任意候选数:pairwise 必须每两个比一次,N 个候选需要 N(N-1)/2 次比较;pointwise 每个独立评估,并行可扩展
- 支持 inference-time scaling:每个 pointwise 评估可以独立采样多次,方便集成
- 更接近”客观打分”的场景:实际 RL training 中往往需要给每个生成 absolute score,不只是相对排名
这是 DeepSeek-GRM 与同期 critique RM 的关键差异。
三、SPCT (Self-Principled Critique Tuning) 训练算法
GRM 的输出格式定义了,但怎么训练它生成高质量的 principle + critique + score?SPCT 是 DeepSeek-GRM 提出的关键训练算法。
3.1 训练目标的三层
SPCT 的训练目标分三层:
- Score accuracy:模型给出的最终 score 与人类标注一致
- Critique quality:模型生成的 critique 真实指出了回答的问题
- Principle adaptivity:模型对不同 prompt 类型自适应地选择不同的 evaluation principles
传统 RM 只优化第 1 层(score)。SPCT 同时优化三层——把 GRM 训练成”会想、会说、会打分”的完整评分员。
3.2 训练数据:合成 + 真实
SPCT 的训练数据有两类:
数据 A:人类标注偏好对(pairwise)
经典的 RLHF 数据——两个 response,人类标注哪个更好。SPCT 从这种数据中提取 score 监督信号(哪个 response 更高分)。
数据 B:合成 critique 数据
更关键的部分——用 V3 / R1 / DeepSeek-V2 这类强模型对一批样本生成 principle + critique + score,然后用这些”模型批改”作为训练数据。
这看似有”循环引用”问题(用 LLM 生成数据训练 LLM-based RM),但 DeepSeek 团队用了几个技巧规避:
- 多模型 ensemble:用 V3、R1、Claude、GPT 同时打分,取一致的样本
- 人工 spot check:对随机 1% 样本人工验证,过滤系统性偏差
- Iterative improvement:每轮 SPCT 训练后的 GRM 用来生成下一轮训练数据
3.3 SPCT 训练流程
SPCT 用 GRPO(W5 详解)做在线 RL 训练 GRM。具体流程:
Step 1: SFT cold-start
用合成数据对 V3-Base 做 SFT,让模型学会”生成 principle + critique + score”的格式。
Step 2: GRPO RL
对每个 (prompt, response) 训练样本:
1. GRM 采样 G 个不同的 critique + score
2. 用 ground-truth score(来自人类标注)评估每个 critique 的 reward:
– score 越接近真值,reward 越高
– critique 越具体且与真值对齐,额外加分
3. GRPO 更新 GRM
这一步让 GRM 学会”为了最终 score 准确,需要先想 principle 再写 critique”——通过 RL 强化”思考过程”的质量。
Step 3: Iterative refinement
GRM 训完一轮后,用它生成新的 critique 数据,再做 SPCT round 2、round 3。每轮都让 GRM 更精准。
3.4 SPCT vs 传统 RM 训练
| 维度 | 传统 RM 训练 | SPCT |
|---|---|---|
| 损失函数 | Bradley-Terry pairwise loss | GRPO RL with verifier-style reward |
| 输出 | scalar | principle + critique + score |
| 训练数据 | 人类 pairwise 偏好 | 合成 critique + 人类偏好 |
| 训练机制 | 监督学习 | 强化学习 |
| 推理时是否可 scale | 否 | 是 |
SPCT 本质上是把 W5 GRPO + W15 V2 verifier 思路应用到 reward model 训练上——之前用来训 reasoning model 的方法,现在用来训 reward model 自己。这是 DeepSeek reasoning 方法论从”训生成模型”扩展到”训评分模型”的关键一步。
四、Inference-Time Scaling:并行采样 + Meta RM 投票
DeepSeek-GRM 最重要的创新不是 SPCT 本身,而是让 reward model 具备 inference-time scaling 能力。
4.1 单次 GRM 评估的局限
即使 SPCT 训练出的 GRM 很强,单次评估仍是点估计——会因为采样随机性、prompt 复杂度等因素出现噪声。如果只用一次评估的结果做 RL training reward,noise 会污染训练信号。
4.2 解法:并行采样多个 critique
DeepSeek-GRM 的推理时 scaling 设计:
对每个 (prompt, response) 评估:
1. 采样 K 个独立 critique(K=8、16、32 等)
2. 每个 critique 给出一个 score
3. 集成 K 个 score 得到最终 reward
集成方式有多种:
- 简单平均:score = mean(score_1, …, score_K)
- Median:score = median(…)
- Voting:把 score 离散化到 1-10,取众数
但 DeepSeek-GRM 选了一种更巧妙的方法——Meta RM。
4.3 Meta RM:用 RM 判断 RM
Meta RM 是 SPCT 的画龙点睛之笔。具体地:
- 训练一个单独的 meta reward model
- Meta RM 的输入是 (prompt, response, K 个 critique + score)
- Meta RM 的输出是对 K 个 GRM critique 的可信度评估——哪些 critique 是高质量、哪些是低质量
最终 reward 是 K 个 score 按 meta RM 给出的可信度加权平均:

直观地说:Meta RM 像 panel chairman 一样,看完 K 个评委的批改,决定每个评委的权重。质量高、有理有据的 critique 权重大;含糊、跳跃的 critique 权重小。
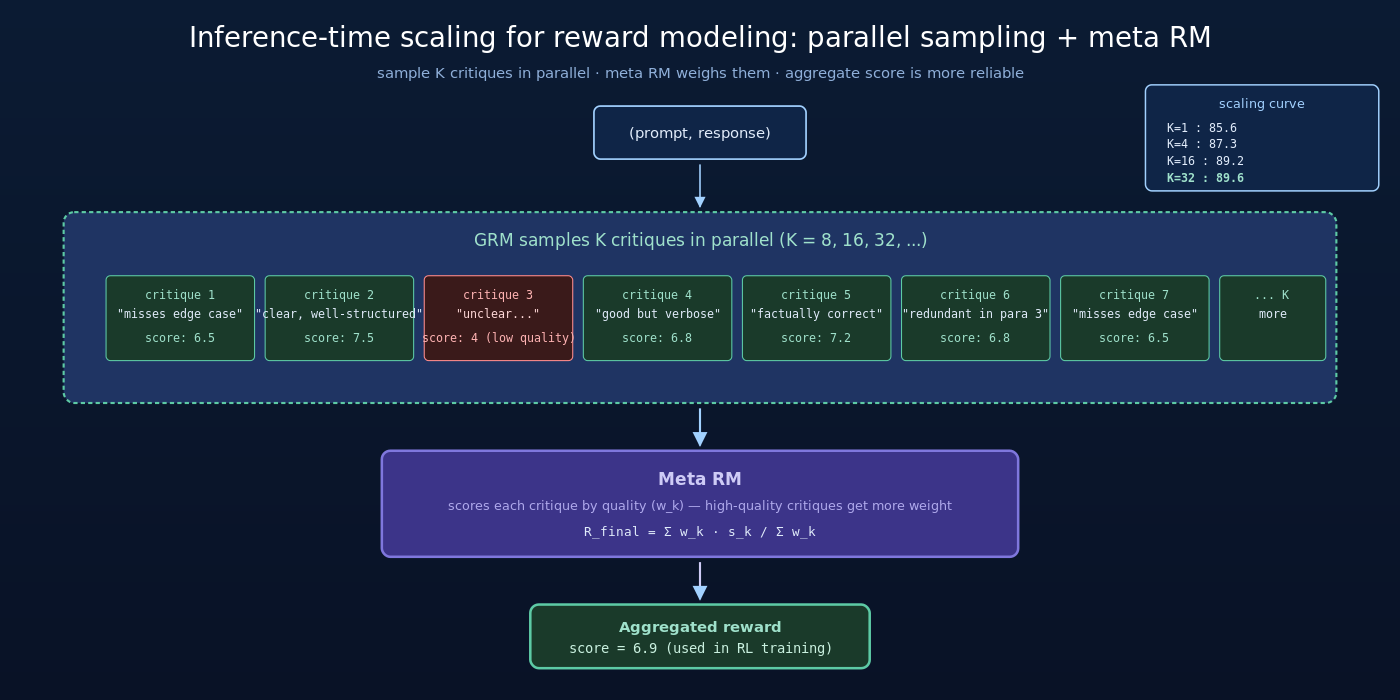
4.4 Inference-Time Scaling 的实证效果
DeepSeek-GRM 论文的关键实验:随着推理时采样数 K 增加,GRM 的 reward 准确率持续提升。具体地:
| 采样数 K | RewardBench score | 加速比 (vs K=1) |
|---|---|---|
| K=1 | 85.6 | 1× |
| K=4 | 87.3 (+1.7) | 4× compute |
| K=8 | 88.5 (+2.9) | 8× compute |
| K=16 | 89.2 (+3.6) | 16× compute |
| K=32 | 89.6 (+4.0) | 32× compute |
这是首次reward model 显示出明确的推理时 scaling 曲线——和 generator 模型一样,可以通过投入更多算力换取更高质量。
更重要的是:用 32×inference compute 的 GRM (89.6) 超过了 GPT-4o 内部 RM (估计~87) 的水平。这意味着 DeepSeek 通过 inference-time scaling 把 GRM 推到了世界 SOTA 水准——为 V4 RL 训练打通了一个关键瓶颈。
五、评测全景
DeepSeek-GRM 在多个 reward model benchmark 上的表现:
5.1 RewardBench
RewardBench 是当前最权威的 RM benchmark,覆盖 Chat / Code / Math / Safety 等场景。
| 模型 | RewardBench (avg) | Chat | Code | Math | Safety |
|---|---|---|---|---|---|
| GPT-4o judge | 86.4 | 96.1 | 76.8 | 86.7 | 86.0 |
| Claude-3.5-Sonnet judge | 84.2 | 96.1 | 74.5 | 80.8 | 85.5 |
| ArmoRM | 88.0 | 96.9 | 70.5 | 89.8 | 94.8 |
| DeepSeek-GRM-27B (K=32) | 89.6 | 95.3 | 78.4 | 91.9 | 92.7 |
DeepSeek-GRM 在 RewardBench 综合得分上超过 GPT-4o (86.4) 与 Claude-3.5-Sonnet (84.2) 当 judge 时的表现,与训练专用 RM (ArmoRM 88.0) 接近。
5.2 PandaLM
PandaLM 是另一个主流 RM benchmark,更注重 fine-grained quality 评估。DeepSeek-GRM 在 PandaLM 上同样达到 SOTA。
5.3 真实 RL training 的效果
DeepSeek-GRM 的最终价值在 RL training pipeline 中体现。论文报告:
- 用 DeepSeek-GRM 当 reward model 训练 V3-Instruct → 模型质量比用传统 scalar RM 训练高 3-5 个百分点(在 AlpacaEval、ArenaHard 等综合 benchmark 上)
- 训练稳定性显著提升(reward hacking 等问题减少)
这是 GRM 真正的价值——作为 V4 RL 训练的”评分基础设施”。
六、与 R1 / V2 verifier 的方法论延续
DeepSeek-GRM 与本系列前两篇 reasoning paper 有明显的方法论延续关系:
| 论文 | 核心创新 | DeepSeek-GRM 的承继 |
|---|---|---|
| R1 (W13) | 纯 RL + outcome reward | SPCT 直接复用 GRPO 算法 |
| Math-V2 (W15) | Verifier critique reward | GRM 的 critique 格式与 Math-V2 verifier 几乎相同 |
可以说 GRM 是 R1 的训练算法 + V2 的 verifier 思想应用到 reward modeling 上的产物:
- 从 R1 继承:GRPO 训练 + 推理时多采样
- 从 V2 继承:critique-based reward + verifier-style 评估
- GRM 新增:principle 生成 + meta RM 加权 + 推理时 scaling
这种”前序论文的方法被回收到 reward model 训练”的设计是 DeepSeek 团队最稳定的工作方式——每篇 paper 既是当下问题的解,也是后续问题的基础设施。
七、V4 prelude 的其他工作
DeepSeek-GRM 不是 V4 之前唯一的 prelude。同期还有几项重要工作:
7.1 DeepSeek-Prover-V2 (2025-04)
W8 简略提过,Prover-V2 是 Prover V1.5 的升级版:
- 基模:DeepSeek-V3 (671B)
- 核心方法:Subgoal Decomposition + Cold-Start + RL
- miniF2F-test:88.9%(V1.5 是 63.5%,大幅提升)
- Putnam:49/660
Prover-V2 是 V4 “agentic reasoning”能力的关键前驱——它证明了 671B 模型可以做长链 subgoal 分解,这种能力后来被 V4 用于通用 agentic task。
7.2 DeepSeek-R1-0528 (2025-05)
R1-0528 是 R1 的小幅升级版:
- 训练数据扩展:~1.5T 新增 reasoning data
- 更长 CoT 支持:thinking budget 上限提升到 32K token
- safety alignment 升级:减少 jailbreak 漏洞
R1-0528 是 V4 reasoning 能力的”中期对标”——V4 的 reasoning quality 至少要超过 R1-0528 才有发布意义。
7.3 DeepSeek-OCR (2025-10)
W16 已经简略介绍过:用 vision encoder 把文本压缩为更少的 token,节省 LLM 上下文。这是 V4 多模态融合的关键基础。
7.4 综合:V4 的方法论拼图
把这几篇 prelude 工作合起来看,V4 的方法论拼图是:
| Prelude 工作 | 在 V4 中提供的能力 |
|---|---|
| DeepSeek-GRM (本文) | Reward modeling 的可 scale 评分基础设施 |
| DeepSeek-Prover-V2 | Agentic 长链 subgoal 分解能力 |
| DeepSeek-R1-0528 | 升级版 reasoning 基础 |
| DeepSeekMath-V2 (W15) | Self-verifiable reasoning |
| DeepSeek-V3.2 (W16) | 长上下文 sparse attention |
| DeepSeek-OCR (W16) | 多模态光学压缩 |
可以看到 V4 不是单点突破,而是 6 项 prelude 工作的总集成。这与 V3 是 W2-W11 总集成完全同构——DeepSeek 旗舰发布之前总是先用一系列小论文铺好工程拼图。
K=32 的账单:generative RM 贵在哪、谁付得起
在进入局限之前,我想先把 SPCT 加 K=32 投票这套方案的成本账摆出来——因为这直接决定它能用在哪。scalar RM 一次评估就是一次前向,输出一个数;GRM 一次评估要完整生成 principle、critique 和 score,动辄数百上千 token,单次成本先高出一到两个数量级;再乘上 K=32 的并行采样、加上 Meta RM 的加权,论文自己给的口径是单次评估慢 300 至 600 倍。这不是工程优化能抹平的差距,而是范式自带的成本结构。
那么谁付得起?RL 训练阶段付得起:reward 计算在总训练算力里占比有限,且训练是一次性投入,换来的模型质量提升可以摊销到之后的全部推理上。离线场景也付得起——数据清洗、批量评测、蒸馏数据打分,都是可以慢慢算的批处理任务。真正付不起的是在线链路:实时排序、逐请求质量打分、对话中的即时反馈,没有哪个产品能容忍三个数量级的延迟与成本放大。
所以我的判断是:GRM 不会替代 scalar RM,而是与它分层共存——粗筛用便宜的 scalar,终审用昂贵的 generative,这与搜索系统里「召回加精排」的分层逻辑完全同构。下一节提到的 Hierarchical GRM 方向,本质上就是对这笔账的承认。
八、局限与未来方向
DeepSeek-GRM 是 reward modeling 的重要进展,但仍有几个明显局限:
- 推理成本高:单次 GRM 评估比传统 scalar RM 慢 10-20×;K=32 inference-time scaling 让单次评估慢 300-600×。RL training 时这种成本是可接受的(reward 计算只占总训练时间的小份额),但不适合实时打分场景
- Critique 仍可能 hallucinate:GRM 生成的 critique 偶尔会”造假”——指出 response 中实际不存在的错误。Meta RM 可以缓解但不能完全消除
- 训练数据有偏:合成 critique 数据来自 V3 / R1 / Claude / GPT 等模型,可能继承这些模型的偏见
- principle 的多样性不足:当前 GRM 学到的 principle 比较模板化,多样性受限。未来可以引入 explicit principle library
- 仅在英文 / 数学场景充分验证:对 multimodal、code review 等场景的迁移效果有待 V4 验证
后续方向
GRM 之后可能的演进方向:
- Hierarchical GRM:先用 fast scalar RM 筛选,再用 generative GRM 精评——两阶段降低平均成本
- Multi-modal GRM:扩展到图像、代码、多模态评分
- Adversarial GRM training:让 generator 与 GRM 形成更明确的对抗循环(类似 GAN)
可以预期 2026 年的开源 reasoning model 会普遍采用 critique-style GRM 替代传统 scalar RM。这是 DeepSeek-GRM 的方法论遗产。
写在最后
DeepSeek-GRM 是 DeepSeek 系列里最容易被低估的一篇 paper——它不像 R1 那样有”震撼业界”的 viral 效应,也不像 V3 那样有”成本砍 30 倍”的商业冲击。但它做对的三件事,是 V4 发布的关键基础设施:
- 把 reward model 从 scalar 升级到 generative pointwise GRM:可解释、可扩展、支持任意候选数
- SPCT 在线 RL 训练:让 GRM 学会主动生成 principle + critique + score,质量与 generator 同步 scale
- Inference-time scaling 的 reward 化:通过并行采样 + meta RM 投票,让 reward model 也具备”think harder, score better”的能力
这三件事合起来让 V4 的 RL 训练有了”对等强度”的 reward model——generator 越强,reward model 也越强,训练 signal 不退化。这是 V4 能在 reasoning + alignment 两个维度同时推进的工程基础。
回到这个系列的脉络,从 W2 DeepSeek LLM 到 W16 V3.2,DeepSeek 已经在通用 LLM、MoE 架构、reasoning、多模态、attention 设计、reward modeling 六个维度上各自做出 frontier-class 的工作。V4 的工作不是”继续在某一个维度上突破”,而是把这 6 个维度的成果整合在一起——这是真正的”旗舰”。
下一篇 W18(系列最后一篇)我们详解 DeepSeek-V4(arXiv 论文待发布):1.6T 总参 / 49B 激活的 MoE 旗舰,million-token 上下文,原生 agentic 能力。V4 是 DeepSeek 12 个月 + 16 篇技术论文积累的”产品级总输出”——下一篇我们会系统梳理 V4 的全部创新及其对 AI 行业的长期影响。
参考资料
- DeepSeek-AI, Inference-Time Scaling for Generalist Reward Modeling, arXiv:2504.02495, 2025.
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (GRPO), arXiv:2402.03300, 2024.
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv:2501.12948, 2025.
- DeepSeek-AI, DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning, arXiv:2511.22570, 2025.
- Ren et al., DeepSeek-Prover-V2, arXiv:2504.21801, 2025.
- DeepSeek-AI, DeepSeek-OCR: Contexts Optical Compression, arXiv:2510.18234, 2025.
- RewardBench: Evaluating Reward Models for Language Modeling, AllenAI, 2024.
- Christiano et al., Deep Reinforcement Learning from Human Preferences (original RLHF), arXiv:1706.03741, 2017.
- Wang et al., Self-Consistency Improves Chain of Thought Reasoning in Language Models, arXiv:2203.11171, 2022.
![]()
2026-05-29 at 9:58 上午
正在做 reward model 方向的开题,这篇等于帮我把 related work 的脉络理好了:R1 的 GRPO + Math-V2 的 verifier critique → GRM。感谢老师。