
转载本文请注明出处:https://yudonglee.me/deepseekmath-v2-explained/ | 作者:yudonglee
本文是 DeepSeek 论文专题系列的第 14 篇,详解 DeepSeek 公司 2025 年 11 月发表的 DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning (arXiv:2511.22570)。这是 DeepSeek 推理主线在 R1 之后的延续——把”答案验证”扩展到”推理过程验证”,提出 Self-Verifiable Reasoning 方法论:训练一个accurate 且 faithful 的 LLM-based verifier,再让 generator 用 verifier 当 reward 来学习”识别并修正自己证明中的问题”。模型在 685B 基模(V3.2-Exp)上训练,在 IMO 2025 上解出 5/6 题获金牌、CMO 2024 获金牌、Putnam 2024 拿到 118/120(人类最高分仅 90)。这是开源数学推理模型第一次明确达到顶尖数学竞赛 gold 水位。论文同时提出了 “generation-verification gap” 这一新概念——只要 verifier 一直能识别 generator 错的地方,generator 就持续有提升空间。这套思路把 reasoning model 训练从 R1 的 “outcome-based RL”(只看答案对错)推进到 “process-aware RL”(看推理过程是否经得起验证),是 reasoning 训练范式的关键演进。
一、为什么 R1 之后需要 process-aware RL
W13 详解 R1 时我们提到 R1 的 RL 训练完全基于 outcome-based reward:
- 数学题:答案对 = +1,错 = 0
- 代码题:unit test 通过 = +1,失败 = 0
这种设计在 R1 paper 里非常成功——纯 RL 让 V3-Base 涌现出 Aha Moment 与 long-CoT 推理能力。但 outcome-based reward 在更难的问题上有几个根本局限。
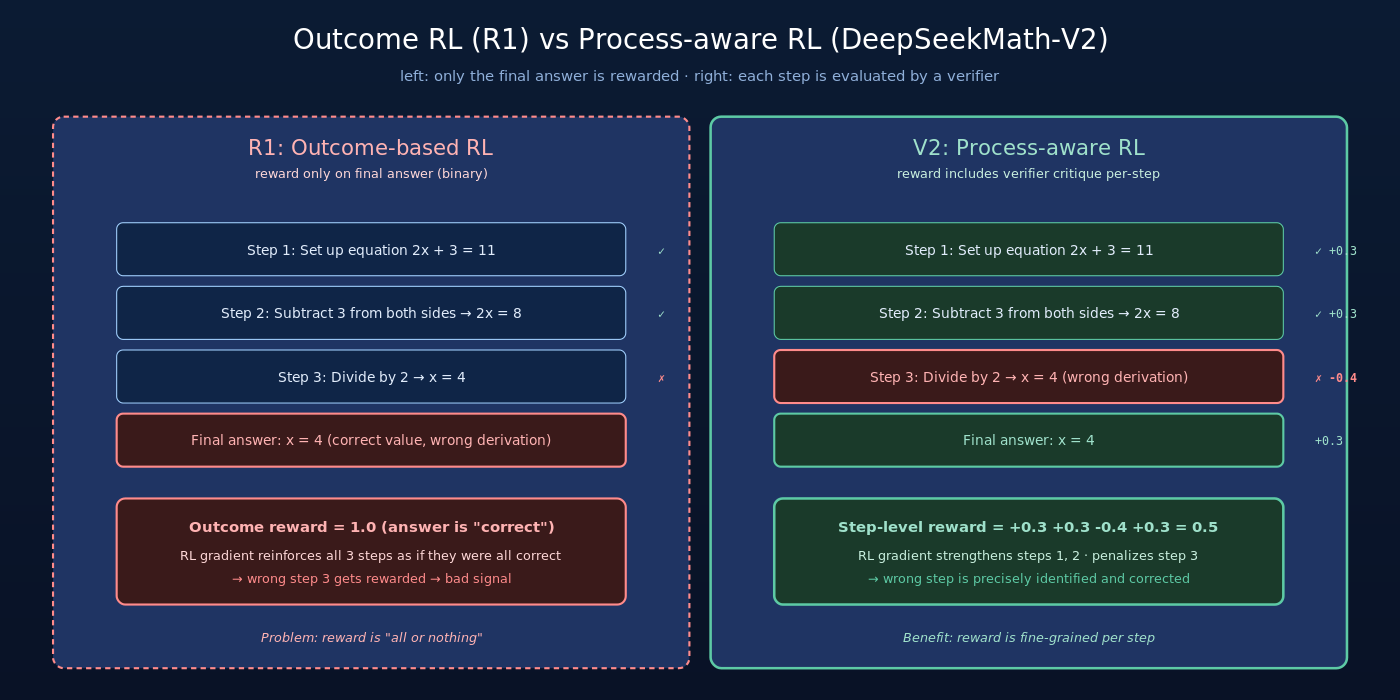
1.1 局限一:错误推理也可能蒙对答案
考虑一道选择题,模型用错误的推理过程恰好选中正确选项,outcome reward 仍然 = 1.0——RL 会”奖励错误的推理”。这种 false reward signal 在选择题、判断题、有限离散答案的题目里特别常见。
更隐蔽的情况:在长 reasoning 中,前 9 步逻辑严密,但第 10 步算错了导致最终答案错。outcome reward 只看到”错”,反向传播会惩罚整段 reasoning——包括前 9 步正确的推理。RL signal 完全没有区分”哪一步真的错了”。
这种”reward 与推理过程不对齐”的现象在 R1 的训练日志中已经被观察到。当题目难度上升时(如 AIME → Putnam → IMO),outcome reward 的 noise 越来越大,模型很难继续提升。
1.2 局限二:竞赛级数学题的特殊性
数学竞赛题(IMO、CMO、Putnam)有一个特点:最终答案往往是简单数值或表达式,但证明过程才是核心。比如证明”对所有正整数 n,n² + n 是偶数”——答案就是这个命题,但完整证明需要 5-10 步严密推导。
对这类题:
- outcome 只能判”陈述对不对”,但出题者真正考核的是”证明过程是否严密”
- 即使最终结论对,证明中可能有 logical gap、未证明的引理、不严密的归纳——这些在数学奥林匹克评分里都会扣分
要让 LLM 真正解决竞赛级数学题,必须在证明过程层面上做验证——不只看答案,还要看推理是否每一步都站得住脚。
1.3 业界的尝试:Process Reward Model (PRM)
OpenAI、Google DeepMind 等团队在 R1 之前就尝试过 Process Reward Model (PRM)——训练一个模型给推理过程的每一步打分。但 PRM 路线有几个根本困难:
- 训练数据难得:需要大量”步骤级标注”的样本(每一步对错)。人工标注极慢且昂贵
- PRM 容易被 hack:generator 可能学会输出”形式上像对的”但实际错的步骤
- PRM 训练与 generator 训练耦合:当 generator 进步后,PRM 的”对错判断标准”也需要更新
这些困难让 PRM 路线在 R1 之前一直无法 scale。
1.4 DeepSeekMath-V2 的回答
DeepSeekMath-V2 给出的解法是 Self-Verifiable Reasoning——不是训练一个分数式 PRM,而是训练一个完整的 LLM-based verifier:
Verifier 不打分,而是”逐步阅读”generator 的证明,识别其中存在的逻辑问题、未证明的步骤、计算错误,输出一个 critique。
generator 用 verifier 的 critique 当 reward signal——既学”答案对不对”,也学”证明是否经得起 verifier 检查”。这套思路在 paper 里被命名为 generation-verification gap——只要 verifier 持续能找出 generator 的错误,generator 就有持续提升的空间。
下面详细展开。
二、Self-Verifiable Reasoning:核心思路
2.1 设计哲学:用 LLM 验证 LLM
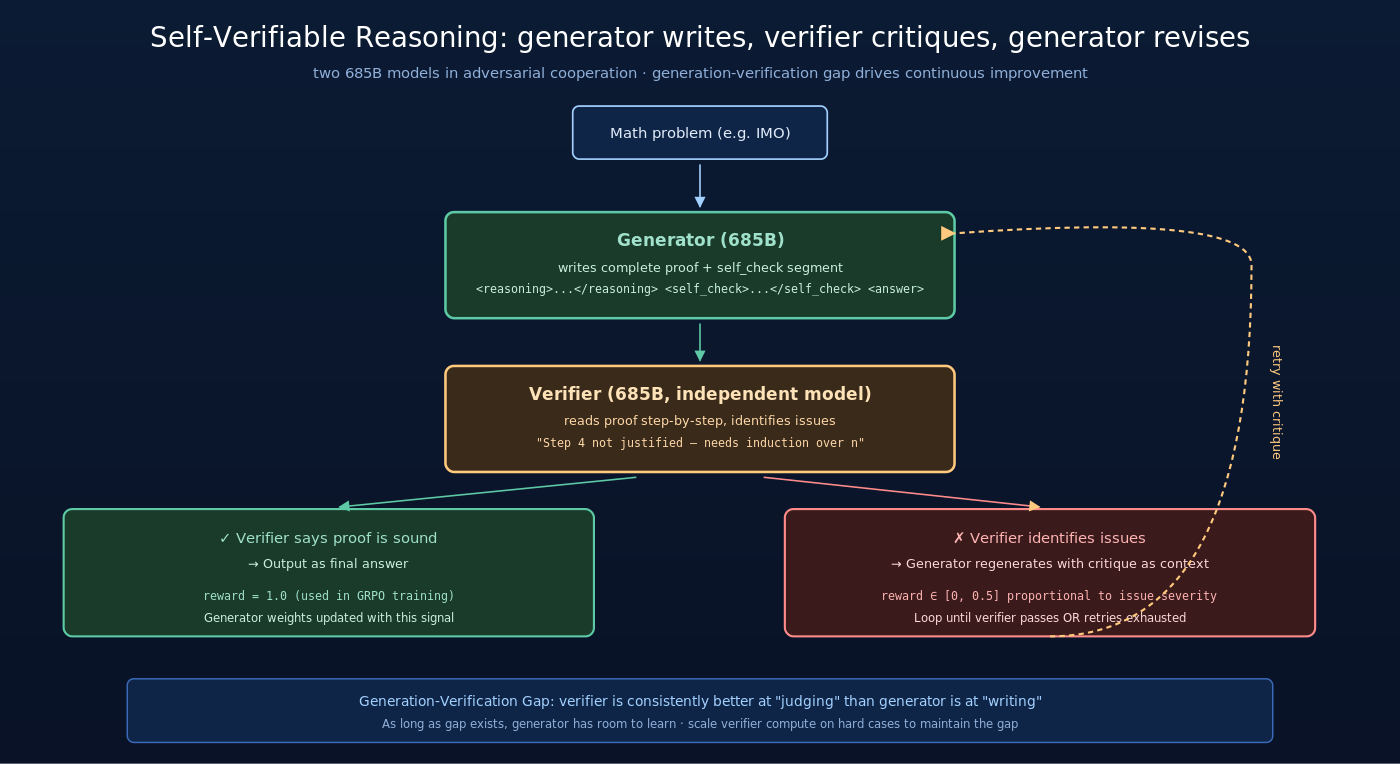
DeepSeekMath-V2 的核心范式:

- Generator:标准的 reasoning model,输入题目,输出完整证明
- Verifier:另一个 LLM,输入”题目 + 证明”,输出对证明的批改(critique)
Verifier 的输出是自然语言的批改,例如:
这种 critique 不是简单的 +1 / 0 分数,而是结构化的批改文本——既指出错误位置,也解释为什么错。
2.2 用 verifier 作为 generator 的 reward
训练 generator 时,verifier 充当 reward model。具体地:
- Generator 对一道题采样 G 个完整证明
- Verifier 对每个证明输出 critique
- 根据 critique 的内容计算 reward: – 完全无误:+1.0 – 有局部错误:+0.5(部分对) – 关键步骤错:0.2 – 根本错误:0
- GRPO 更新 generator policy
这相当于把 verifier 的 critique 量化为 reward signal,比 outcome reward 信息密度高得多。
2.3 Generator 学会 “自我批改”
更关键的设计——让 generator 在输出最终证明前先自己 verify。具体地,generator 的输出格式扩展为:
这相当于 generator 自己当自己的第一个 verifier。模型在生成过程中主动审视并修正自己的推理——这是 reasoning 行为的更高级形态。
Aha Moment 2.0:W13 R1 的 Aha Moment 是模型自发涌现”self-reflection”行为;DeepSeekMath-V2 把这个能力结构化、可训练化——self_check 不再是偶发现象,而是 generator 必须执行的标准步骤,且其质量被 verifier 严格评估。这是从”涌现”到”工程”的范式跃迁。
三、Generator-Verifier 架构详解
3.1 两个模型还是一个模型?
DeepSeekMath-V2 的实现选择是两个独立的 LLM:
- Generator:基于 DeepSeek-V3.2-Exp-Base 训练,685B 参数
- Verifier:同样基于 V3.2-Exp-Base 训练,685B 参数
两个模型独立训练、独立部署。这与 W8 Prover V1 的”自我蒸馏”思路(用同一个模型生成 + 验证)不同。
为什么用两个独立模型?三个原因:
- 角色分工避免目标冲突:generator 优化”生成正确证明”,verifier 优化”识别错误证明”,两个目标天然对立(adversarial 关系)
- 避免循环 self-reinforcement:单模型自我验证会强化已有偏见——错的步骤生成时被认为对,验证时还是认为对
- 可独立 scale:在 generator 进步后可以单独加大 verifier 的训练投入,而不必拖累 generator
这种”对抗式双模型”设计在 GAN、AlphaGo 等系统里早有先例——DeepSeekMath-V2 把它应用到 reasoning training 上。
3.2 Verifier 的训练数据从哪来
Verifier 训练的关键问题是怎么获得”证明 + 是否正确”的训练样本:
- 人工标注:贵、慢、规模受限
- 用 outcome 自动标注:对错答案的关联性弱(如前面提到的”错推理蒙对答案”问题)
DeepSeekMath-V2 的解法是 iterative bootstrap:
Round 1:
- 用现有数据集(如 mathlib、AOPS)的”标准答案 + 证明”作为正样本
- 用 generator 输出的”错误证明”作为负样本(通过 outcome 判错)
- 训练初版 verifier
Round 2:
- 用 round-1 verifier 标注新数据
- 对其中”verifier 判错但 generator 坚持”的样本,做人工 spot-check
- 把高置信度样本加入 verifier 训练集
Round N:循环迭代——每一轮 verifier 都比上一轮更敏锐,generator 也被推得更强。这是 generator-verifier 的 co-evolution(共同进化)。
3.3 维持 “Generation-Verification Gap”
DeepSeekMath-V2 论文提出的最有方法论意义的概念是 generation-verification gap:
在某个能力水位上,generator 生成正确证明所需的能力与verifier 判断该证明是否正确所需的能力之间存在 gap——verifier 通常比 generator 更容易。
这个观察很重要:
- 让一个 LLM 写一道 IMO 题的证明很难(需要构造、洞察)
- 让一个 LLM 验证一道 IMO 题的证明是否对相对容易(只需要逐步检查每一步是否 follow)
只要 verifier 持续比 generator “看得清”,generator 就有学习的空间——verifier 像老师一样指出 generator 的错误,generator 像学生一样不断改正。
但 gap 会随着 generator 变强而缩小——generator 接近 verifier 的水平后,verifier 难以再给出有效 critique,训练 signal 变弱。DeepSeekMath-V2 的核心工程任务就是维持这个 gap:
- scale verification compute:让 verifier 在 hard-to-verify 的证明上花更多 inference compute(多 round 推理、tool 使用、互相 verify)
- automatic labeling of hard cases:把 generator 输出的”verifier 判错但 generator 拒不修改”的难例自动标注,作为 verifier 的新训练数据
通过这两个机制,verifier 始终比 generator 强一档,generator 也就持续有提升空间。
3.4 训练算法:GRPO with Verifier Reward
具体训练算法仍是 W5 的 GRPO,但 reward 函数变了:

 :最终答案对错 (0 或 1)
:最终答案对错 (0 或 1) :verifier 对证明 critique 的量化分数
:verifier 对证明 critique 的量化分数
 在 V2 中取约 0.5——outcome 与 verifier reward 大约同等权重。
在 V2 中取约 0.5——outcome 与 verifier reward 大约同等权重。
3.5 Test-Time 推理:自验证 + 多轮修正
DeepSeekMath-V2 在推理时有两个新流程:
Pattern 1: 单轮自验证
Pattern 2: 多轮 ensemble
V2 论文报告 Pattern 2 配合大 N 在难题上效果显著——例如对 Putnam 2024 用 N=32 候选 + verifier 选择 + 修正循环,最终得分从 N=1 的 ~50/120 提升到 N=32 的 118/120。这是 test-time compute scaling 在 reasoning task 上的清晰例证。
四、评测:竞赛数学金牌水平
DeepSeekMath-V2 在三大顶尖数学竞赛上的成绩:
4.1 IMO 2025 (国际数学奥林匹克 2025)
IMO 是全球最高难度的高中数学竞赛,6 道题,每题 7 分,总分 42 分。
| 模型 | 解出题数 | 得分 | 等级 |
|---|---|---|---|
| GPT-4o | 0 / 6 | <14 | 未通过 |
| OpenAI o1 (估算) | 1 / 6 | ~14-20 | 铜牌附近 |
| DeepSeekMath-V2 | 5 / 6 | ~35 | 金牌 |
| 人类金牌 cutoff (2025) | – | 35 | 金牌 |
DeepSeekMath-V2 是开源模型第一次在 IMO 上达到金牌水位——这是数学 AI 的历史性时刻。
4.2 CMO 2024 (中国数学奥林匹克 2024)
CMO 难度大约与 IMO 相当,是中国选拔 IMO 国家队的关键考试。
| 模型 | 得分 | 等级 |
|---|---|---|
| DeepSeekMath-V2 | gold-level | 金牌 |
具体分数论文未细化披露,但 V2 在 CMO 2024 上达到金牌水位。
4.3 Putnam 2024 (美国 Putnam 大学生数学竞赛 2024)
Putnam 是全球最难的大学生数学竞赛,12 题、120 分。多数顶尖大学数学专业学生的中位数得分仅 ~2 分;当年的最高人类得分 90 分。
| 选手类型 | 得分 |
|---|---|
| 2024 Putnam 中位数(参赛学生) | ~2 / 120 |
| 2024 Putnam 最高人类分数 | 90 / 120 |
| DeepSeekMath-V2(test-time compute scaling) | 118 / 120 |
V2 的 118/120 几乎是完美分数,比当年最高人类分数(90)还高 28 分。这是数学 AI 历史上第一次在一项主流人类数学竞赛上全面超过最强人类——是个标志性事件。
4.4 综合能力
| Benchmark | DeepSeek-R1 (W13) | OpenAI o1 | DeepSeekMath-V2 |
|---|---|---|---|
| AIME 2024 | 79.8 | 79.2 | ~85+ |
| MATH-500 | 97.3 | 96.4 | ~98+ |
| IMO 2025 | <2/6 | 1/6 (估算) | 5/6 |
| Putnam 2024 | ~30/120 (估算) | ~50/120 (估算) | 118/120 |
V2 相对 R1 在所有数学 benchmark 上都有显著提升,特别在最难的 IMO / Putnam 上质的飞跃。
为什么 V2 比 R1 强这么多:核心是 Generator-Verifier + Test-Time Compute Scaling 两个工程突破。R1 是单次生成、outcome reward 训练;V2 是多次生成 + verifier 筛选 + 自我修正 + process-aware RL 训练。两者在能力上下界都不同。
118/120 的成绩单,先核对三个口径
这份成绩单背后的能力跃迁我并不怀疑——从 R1 的不足两题到 5/6,量级差距不是评分噪声能解释的。但「金牌」「118/120」这些词从竞赛语境平移到模型身上时,有三个口径需要先对齐。
口径一:算力预算。Putnam 选手是限时闭卷六小时,V2 的 118 分是 N=32 采样加多轮验证修正堆出来的,两边消耗的「思考资源」完全不可比。这个分数证明的是 test-time scaling 有效,而不是「比最强人类高 28 分」这种字面比较成立。
口径二:评分由谁执行。IMO 与 Putnam 的组委会并不为模型阅卷,所谓金牌水位与 118 分,是论文团队对照评分标准的自评或委托评估。证明题的评分天然带主观裁量——一个 logical gap 是扣一分还是整题不给,松紧之间分数可以差很远。自评分数应当默认打折扣看待。
口径三:self-verification 的盲区。从 32 个候选里挑出最优解的 verifier 与 generator 同源、共享训练管线,verifier 漏判的错误类型不会体现在最终分数里。换句话说,分数的可信上界受 verifier 盲区的限制,而这个盲区有多大,论文并没有给出独立的第三方度量。
五、与 R1 / Prover 系列的对比
DeepSeekMath-V2 整合了 DeepSeek 推理主线前两个分支的方法论:
5.1 V2 与 R1 的差异
| 维度 | DeepSeek-R1 (W13) | DeepSeekMath-V2 (W15) |
|---|---|---|
| 基模 | DeepSeek-V3 (671B) | DeepSeek-V3.2-Exp (685B) |
| RL reward | outcome only (binary) | outcome + verifier critique |
| 是否需要 verifier 模型 | 否 | 是(独立 685B verifier) |
| 推理时 | 单次生成 | 自验证 + 多轮修正 |
| 适用领域 | 通用 reasoning | 专精数学竞赛 |
| 长度可达 | ~32K tokens | 单次证明 + 验证可达数十 K |
| 关键贡献 | “纯 RL 可行” | “process-aware RL 可行” |
V2 不是 R1 的替代品,而是 R1 思路的专项深化——在数学领域用更精细的 reward signal 把能力推到极致。V2 的方法论后续可能被迁移到代码(unit test → verifier 的扩展)、形式证明(Lean 验证 → 强化版 verifier)等场景。
5.2 V2 与 Prover V1/V1.5/V2 的关系
回顾 W8 详解的 Prover 系列:
| 维度 | Prover (W8) | DeepSeekMath-V2 (W15) |
|---|---|---|
| 证明语言 | 形式化 Lean 4 | 自然语言 |
| 验证方式 | Lean 4 编译器(”完美”verifier) | LLM-based verifier(”近似”verifier) |
| 适用范围 | 已形式化的题目 | 任意自然语言数学题 |
| 工程复杂度 | 需要 autoformalize 流程 | 不需要形式化 |
| Verifier 是否需要训练 | 否(Lean 是 ground truth) | 是(核心训练任务) |
可以看到 Prover 与 V2 是两条互补路线:
- Prover 走”形式化”路线——用完美的 Lean verifier 提供绝对干净的 reward signal,但只能处理已形式化的题目
- V2 走”自然语言”路线——用 LLM verifier 提供近似的 reward signal,但能处理任意自然语言数学题
V2 的 verifier 在某种意义上是”近似 Lean”——它不能给出绝对的 0/1 验证,但能给出非常细致的 critique。这种近似让 V2 可以应用到 IMO 这种完全不可能形式化在 Lean 内的题目(因为题目语言、几何直觉、组合构造等远超 Lean 当前能力)。
V2 与 Prover-V2(W8 简略提到的 671B 形式证明模型)的对比也很有意思——两者都是 671B+ 模型,但前者用 LLM verifier、后者用 Lean verifier。可以预期未来的”终极证明系统”会是两者融合——LLM 先用 V2 的 self-verifiable 给出自然语言证明,然后形式化到 Lean 让 Prover-V2 给出严格证明。这是 DeepSeek 推理主线的可能终点形态。
六、Test-Time Compute Scaling:reasoning 的新维度
DeepSeekMath-V2 让 test-time compute scaling(测试时算力扩展)作为 reasoning 模型的核心维度浮现。
6.1 三个 scaling 维度
LLM 性能可以从三个维度提升:
- Model size scaling(模型规模):传统主线,更大模型更好
- Pretraining compute scaling(预训练算力):更多数据 + 更多 step
- Test-time compute scaling(推理算力):在推理时花更多算力(多采样、自验证、tree search)
R1 已经隐含使用了 test-time compute(长 CoT 输出更多 token 等于花更多推理算力)。DeepSeekMath-V2 把这个维度显式化、工程化——通过 verifier + 多采样 + 修正循环,让推理算力可以”自由调档”:
- 简单题:1 次生成够了
- 中等题:4 次采样 + verifier 筛选
- 难题:32 次采样 + 多轮验证修正
- 极难题:可以投入任意多算力
V2 在 Putnam 2024 上的 118/120 就是用 N=32+ 采样达成的——投入更多推理算力,准确率持续上升。这与 OpenAI o1/o3 系列的”think harder, score higher”理念完全一致。
6.2 这个维度的产业意义
Test-time scaling 改变了 LLM 推理服务的经济模型:
- 传统:fixed pricing per token,算力固定
- 新模型:variable pricing based on problem difficulty,算力可调
DeepSeek 在 V2 发布后调整了 API 服务——支持 “reasoning depth” 参数,用户可以选择”快速回答”或”深度推理”。后者价格高 5-10×,但 accuracy 提升显著。这是 AI 服务定价的新维度。
七、局限与未来方向
DeepSeekMath-V2 是一项重磅工作,但仍有几个局限:
- 仅在数学领域验证:方法论是通用的,但目前只在数学上做了大规模实验。代码、逻辑、科学推理的迁移性需要后续验证
- Verifier 仍可能犯错:LLM-based verifier 不像 Lean 那样”绝对正确”——它可能漏判某些细微错误,或误判某些非标准但正确的证明
- 训练成本高:两个 685B 模型同步训练 + iterative co-evolution,成本远超 R1
- 推理成本随难度爆涨:test-time scaling 让难题的推理成本可能比 R1 高 100×。商业落地时如何收费是新挑战
- 未公开训练细节:相比 R1 的开源透明度,V2 的具体训练数据、verifier 架构等细节披露较少
后续方向
V2 之后的可能演进:
- Generator-Verifier 用于代码:把”unit test 通过”扩展到”代码 review”——让 verifier 模型给出代码的 critique,generator 修正
- Multi-domain verifier:训练一个统一 verifier 同时验证数学、代码、逻辑、科学推理
- Verifier-as-Service:把 verifier 做成独立服务,让其他 AI 系统调用——一个”通用 AI 阅卷员”
- Verifier 与 Lean 融合:自然语言 verifier + Lean 形式验证的两段式 pipeline
写在最后
DeepSeekMath-V2 是 DeepSeek 推理主线继 R1 之后最大的方法论突破。它做对的三件事:
- 从 outcome RL 推进到 process-aware RL:通过 verifier 提供细粒度的 reward signal,让 RL 不再只看答案对错
- Generator-Verifier 对抗式协同:两个独立 685B 模型互相驱动,generation-verification gap 维持持续提升空间
- Test-time compute scaling 工程化:让推理算力成为 reasoning 模型的可调维度,难题花更多算力换取更高准确率
这三件事的协同效应让 V2 在 IMO 2025、CMO 2024、Putnam 2024 上达到金牌水位,让开源 reasoning 模型第一次明确进入”顶尖人类数学家”水平。
回到这个系列的整体脉络,V2 与前几篇的关系:
- W5 DeepSeekMath → 启动 GRPO + outcome reward 范式
- W8 Prover → 启动形式证明 + Lean verifier 范式
- W13 R1 → 把 outcome RL 推到 frontier 通用模型
- W15 V2(本文)→ 把 reasoning 推到 process-aware RL,整合 R1 + Prover 思路
下一篇 W16 我们详解 DeepSeek-V3.2 / Insights / OCR 系列——这是 DeepSeek 在 V3 与 R1 主线之外的几项”周边”工作:V3.2 是把 NSA 集成进 V3 的旗舰升级,Insights 是新的数据治理方法论,OCR 是为多模态 reasoning 准备的视觉文本基础设施。这些工作虽然 visibility 不如 V3 / R1 大,但都是后续 V4 的关键工程拼图。
参考资料
- DeepSeek-AI, DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning, arXiv:2511.22570, 2025.
- DeepSeek-Math-V2 GitHub repository:
- DeepSeek-Math-V2 Hugging Face model:
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, arXiv:2402.03300, 2024.
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv:2501.12948, 2025.
- Xin et al., DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition, arXiv:2504.21801, 2025.
- Lightman et al., Let’s Verify Step by Step (PRM), arXiv:2305.20050, 2023.
- DeepSeekMath-V2 Scores IMO 2025 Gold: Open Math AI Record, ExploreAI Tools, 2025.
- DeepSeek AI Releases DeepSeekMath-V2: The Open Weights Maths Model That Scored 118/120 on Putnam 2024, MarkTechPost, 2025-11-28.
![]()
2026-06-09 at 6:08 下午
深挖 generation-verification gap:文章说 gap 会随 generator 变强而缩小,靠”scale verification compute + 自动标注难例”来维持。但有个根本问题——谁来验证 verifier?