
转载本文请注明出处:https://yudonglee.me/deepseek-janus-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 3 月,后随系列连载持续修订,最近一次更新于 2026 年 6 月。
本文是 DeepSeek 论文专题系列的第 10 篇,详解 DeepSeek 公司 2024 年 10 月发表的 Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation (arXiv:2410.13848) 与 2025 年 1 月发表的 Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling (arXiv:2501.17811)。这两篇论文是 DeepSeek 多模态主线的另一条独立分支,与 W6 的 DeepSeek-VL 并行存在。Janus 的核心创新是把视觉理解(understanding)与视觉生成(generation)的编码路径完全解耦——用 SigLIP 抽取语义特征服务于理解,用 VQ tokenizer 离散化像素细节服务于生成,两条路径汇入同一个统一 Transformer。这种”双路径 + 单主干”的设计让一个 7B 模型在 GenEval 上拿到 80%、超过 DALL-E 3 (67%) 与 SD3 (74%),同时在多模态理解 benchmark 上也保持竞争力。Janus 的设计哲学呼应了 W10 Aux-Loss-Free 的”关注点分离(separation of concerns)”——当两个目标天然冲突时,不要试图用一个机制同时满足,而要用结构性解耦让它们各自走最优路径。
一、为什么”统一多模态”听起来美好却难做
1.1 多模态主线上的两个独立任务
视觉与语言模型的核心任务可以分为两大类:
- 多模态理解(multimodal understanding):输入图像 + 文本 → 输出文本(VQA、image captioning、OCR、文档理解)
- 多模态生成(multimodal generation):输入文本 → 输出图像(text-to-image、conditional image gen)
业界过去几年发展出两类专门模型:
- 理解类:LLaVA、Qwen-VL、InternVL、DeepSeek-VL(W6 详解)——用 LLM 处理 vision token 输出文本
- 生成类:Stable Diffusion、DALL-E 3、SDXL——用 diffusion model 从文本生成图像
这两条线分别都很成熟。但用户最理想的状态是一个模型同时承担两种能力——就像 ChatGPT 既能看图又能画图。GPT-4o(OpenAI, 2024-05)就是这种”端到端统一多模态”的代表。
1.2 统一多模态的两个学派
在开源社区,统一多模态主要有两派技术路线:
学派 A:双模型拼接
把一个理解类模型和一个生成类模型简单拼起来——用户问”画一只猫”时模型路由到 DALL-E,问”图里有什么”时路由到 LLaVA。
- 优点:实现简单,复用现有模型
- 缺点:不是真正的统一模型,两个能力之间无法相互增强;两个模型独立训练,能力分布割裂
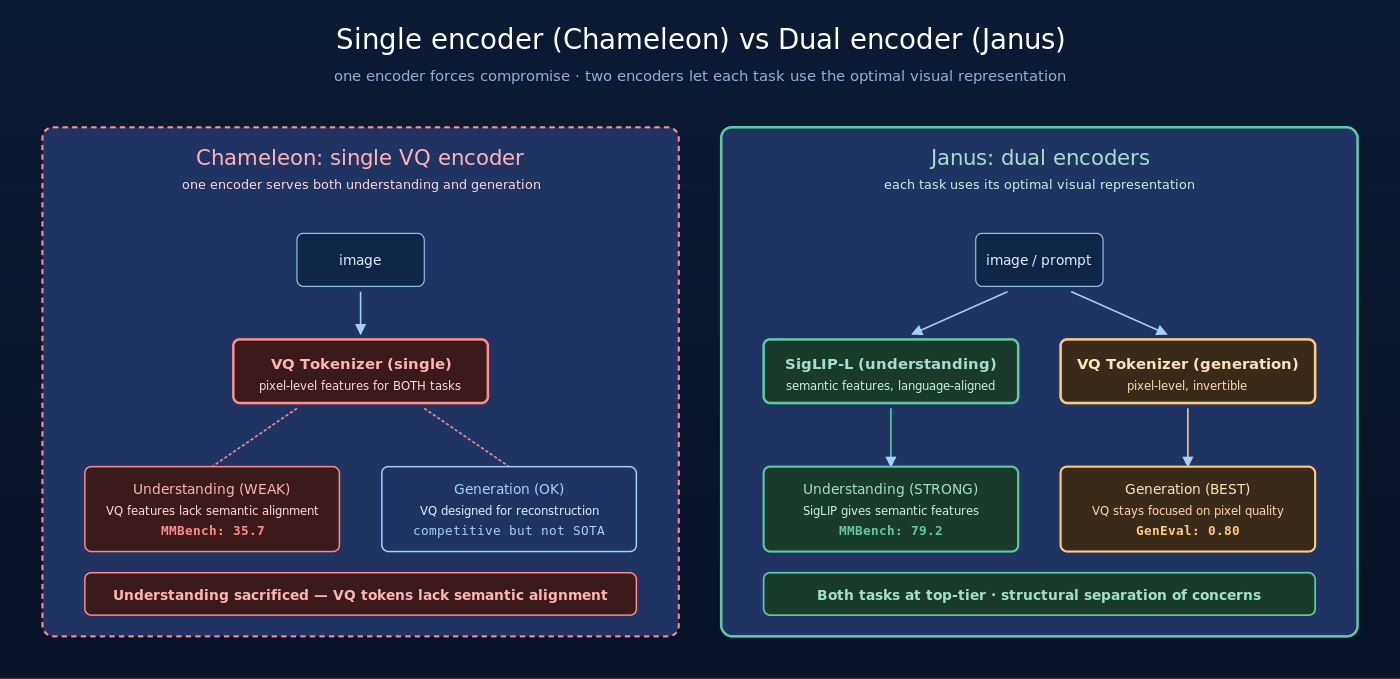
学派 B:单一架构、单一 encoder(Chameleon-style)
Meta 的 Chameleon (2024-05) 是这条路线的代表——用一个统一的 vision encoder 既处理理解又处理生成。图像被 tokenize 成一系列 visual token,文本和图像 token 在同一序列里混合,整个序列由一个统一的 autoregressive Transformer 处理。
- 优点:架构干净统一,理解与生成可以共享表征
- 缺点:单一 encoder 必须同时满足理解所需的”高层语义”和生成所需的”低层像素细节”——两个需求天然冲突,常常顾此失彼
Chameleon 论文里报告,在多模态理解 benchmark 上 Chameleon 显著弱于专门的理解模型(LLaVA)。这就是单 encoder 方案的”双面诅咒”:为了能生成,模型必须保留低层细节;为了能理解,模型必须抽取高层语义;一个 encoder 难以兼顾两者。
1.3 Janus 的解法:双 encoder + 单主干
Janus 给出的方案是一个非常优雅的折中:
视觉编码路径解耦——理解走一条 encoder 路径,生成走另一条 encoder 路径。两条路径汇入同一个统一 Transformer。
这相当于让两个目标各走各的最优路径,最后在一个共享的 LLM 主干上汇合。下面我们详细看这套设计如何实现。
二、Chameleon 单 encoder 的根本问题
要理解 Janus 的设计动机,必须先理解 Chameleon 为什么会失败。
2.1 理解任务需要什么样的视觉特征
对于”图里有什么”这类理解任务,模型需要的视觉特征是:
- 高层语义:识别物体类别、场景类型、活动
- 抽象表征:对纹理、颜色、视角变化不敏感
- 与语言空间对齐:能与文本 embedding 做有意义的相似度计算
这种特征通常由 contrastive learning 训练的 encoder(如 CLIP、SigLIP)产生——它们学习”图文匹配”任务,输出的特征天然与语言对齐。
2.2 生成任务需要什么样的视觉特征
对于”画一只猫”这类生成任务,模型需要的视觉特征是:
- 低层细节:纹理、颜色、阴影、像素级别的信息
- 可逆:从特征能完整恢复出图像
- 离散化:autoregressive 生成需要把图像离散成 token 序列
这种特征通常由 VQ-VAE 或 VQ-tokenizer(如 VQGAN、LlamaGen tokenizer)产生——它们把图像压缩成 8000-16384 个离散 codebook entries,可以无损或近无损还原。
2.3 两种特征的根本冲突
CLIP 类语义特征与 VQ 类像素特征是完全不同的数学对象:
| 维度 | CLIP/SigLIP 特征 | VQ tokenizer 特征 |
|---|---|---|
| 训练目标 | image-text contrastive | reconstruction (VQ-VAE) |
| 表征性质 | continuous, semantic | discrete, pixel-level |
| 与语言对齐 | 强(直接训练目标) | 弱(无对齐约束) |
| 重构图像 | 弱(高层抽象,丢细节) | 强(设计就是为了重构) |
| 维度 | 1024-2048 | 离散 16384 词表 |
Chameleon 选择用 VQ tokenizer 作为单一 encoder——这样可以生成,但理解能力会因为缺少语义对齐而下降。Janus 论文展示了这个 trade-off 的具体数字:
- Chameleon 7B 在 MMBench 上得分 35.7
- 同等规模 LLaVA-1.5 7B 得分 64.3
- 两者差距 28.6 个百分点——足以说明单 encoder 在理解任务上的损失
这就是 Chameleon 范式的根本局限——架构干净的代价是某一项能力大幅退化。
三、Janus 核心设计:双路径视觉编码
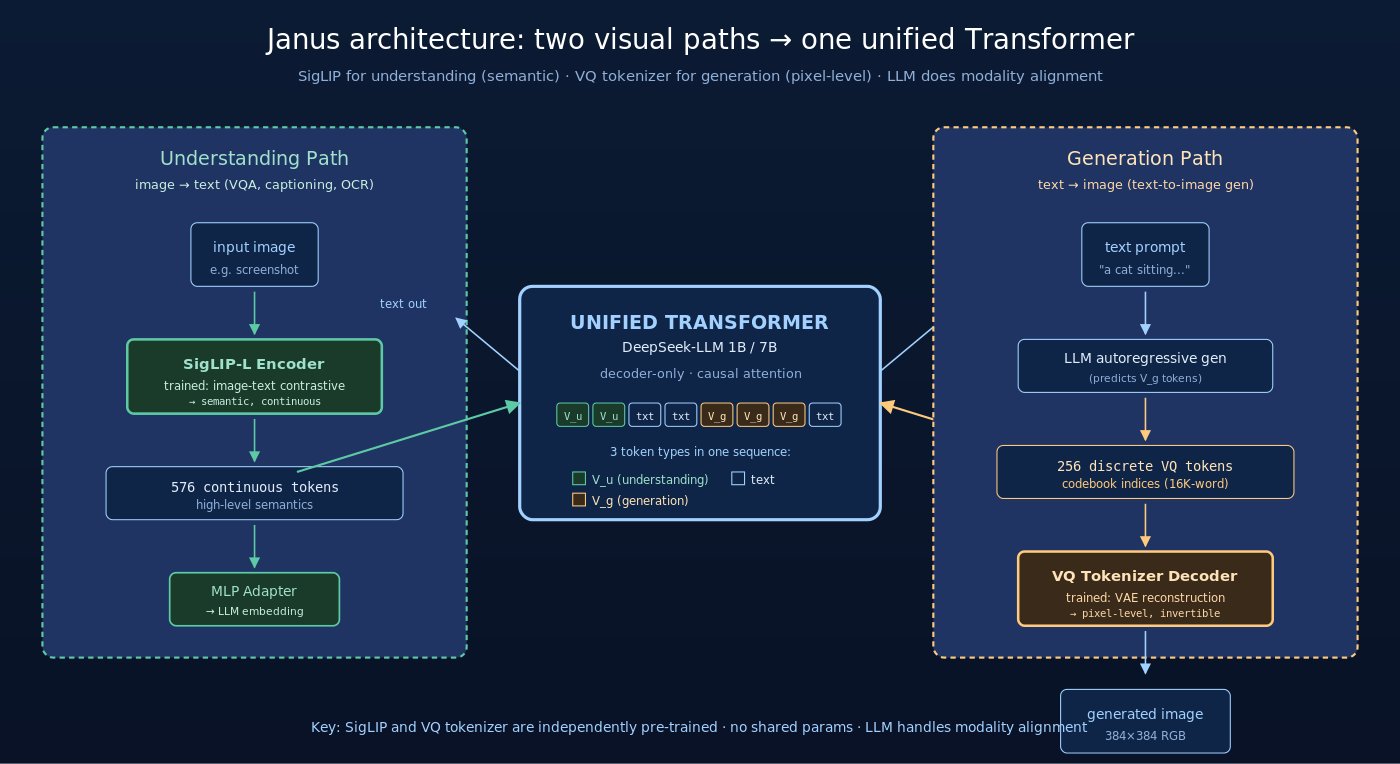
3.1 整体架构
Janus 的架构由三部分组成:
- 理解路径(Understanding Encoder):用 SigLIP-L 处理输入图像,输出 576 个语义 token,经 MLP adapter 投影到 LLM embedding 空间
- 生成路径(Generation Encoder/Tokenizer):用 VQ tokenizer(基于 LlamaGen 训练的 VQ-VAE)把图像编码成离散 token 序列(典型 256 或 576 个 token)
- 统一 Transformer 主干:基于 DeepSeek-LLM 1.3B 的 decoder-only Transformer,同时接收文本 token、理解视觉 token、生成视觉 token
3.2 数据流
不同任务的数据流:
任务 A:图像理解(image → text)
- 图像 → SigLIP-L encoder → 576 个连续语义 token
- MLP adapter 投影到 LLM embedding 维度
- 文本 prompt token 与 vision token 拼接,送入 LLM
- LLM 自回归生成文本回答
任务 B:图像生成(text → image)
- 文本 prompt token 送入 LLM
- LLM 自回归生成 image VQ token 序列(典型 256 个)
- VQ tokenizer 的 decoder 把 image token 反编码为像素图像
任务 C:混合输入(看图说话生成新图、image-conditioned image gen 等)
- 输入图像 → SigLIP-L → 理解 token
- 文本 prompt + 理解 token → LLM
- LLM 输出文本与生成 token 混合序列
- 生成 token 部分 → VQ decoder → 图像输出
3.3 关键设计巧思
巧思 1:理解与生成使用不同的视觉 token 格式
- 理解视觉 token 是连续的(直接是 SigLIP encoder 的输出特征)
- 生成视觉 token 是离散的(VQ tokenizer 的 codebook index)
LLM 内部用不同的 embedding lookup 处理这两种 token:
- 连续 token:通过 MLP adapter 直接映射到 LLM embedding 空间
- 离散 token:通过专门的 image embedding table 映射
这相当于 LLM 有三种 token 类型:text token、understanding visual token(连续)、generation visual token(离散)。三种类型在同一个序列里混合处理,但 LLM 知道每种 token 的来源与去向。
巧思 2:理解路径与生成路径完全独立训练
SigLIP-L encoder 与 VQ tokenizer 是独立预训练的——前者用图文对比训练,后者用 VAE reconstruction 训练。两者之间没有共享参数,互不影响。
这保证了:
- 理解能力受 SigLIP 的语义表征质量决定
- 生成能力受 VQ tokenizer 的重构质量决定
- 两者解耦,不会互相拖累
巧思 3:LLM 主干承担”模态对齐”工作
虽然两个 encoder 的输出特征空间完全不同,但都通过 adapter 投影到同一 LLM 的 embedding 空间。LLM 在训练中自然学到”如何使用这两种视觉信息”——它不需要知道它们的几何性质,只需要知道每种 token 对应什么任务。
这是一种很高级的关注点分离——视觉路径只负责”提取最适合下游任务的特征”,模态对齐工作完全交给 LLM。
四、训练策略:三阶段
Janus 沿用了 W6 DeepSeek-VL 的”三阶段渐进训练”思路,但具体配置不同:
4.1 Stage 1: Adapter 训练(visual ↔ language alignment)
- 可训练:MLP adapter(理解路径)+ image embedding table(生成路径)
- 冻结:SigLIP-L、VQ tokenizer、LLM 主干
- 数据:~1M 图文对(理解)+ ~1M 文本-图像对(生成)
- 目标:让两个 adapter 学会把视觉信息投影到 LLM 能理解的 token 空间
4.2 Stage 2: 统一预训练(unified pretraining)
- 可训练:MLP adapter + image embedding + LLM 主干
- 冻结:SigLIP-L、VQ tokenizer
- 数据混合:50% 理解数据 + 30% 生成数据 + 20% 纯文本(保持语言能力)
- 目标:让 LLM 同时学会”处理理解 token”与”产生生成 token”两种能力
4.3 Stage 3: SFT(监督微调)
- 可训练:MLP adapter + image embedding + LLM 主干
- 冻结:SigLIP-L、VQ tokenizer
- 数据:精细整理的指令数据,涵盖 image captioning、VQA、text-to-image 各种任务
- 目标:让模型适应具体下游任务的指令格式
4.4 三个阶段的训练成本分配
- Stage 1:~1% 总训练计算(轻量、快速)
- Stage 2:~85% 总训练计算(主要训练阶段)
- Stage 3:~14% 总训练计算(精细调整)
这种”Stage 2 占大头”的配比与 W6 DeepSeek-VL 类似——保 LLM 能力的核心阶段是 unified pretraining,而非 SFT。
五、Janus-Pro:数据 + 模型 scaling
Janus V1 的 1.3B 模型在小规模上验证了双 encoder 设计的可行性。2025 年 1 月发布的 Janus-Pro(arXiv:2501.17811)在两个维度上做了系统升级:
5.1 模型规模升级
Janus-Pro 提供两个版本:
- Janus-Pro 1B:与 V1 相同的 1.3B backbone(实际 1B 量级)
- Janus-Pro 7B:升级到 7B backbone(基于更强的 DeepSeek-LLM 7B)
5.2 训练数据升级
V1 vs Pro 的数据规模对比:
| 数据类别 | Janus V1 | Janus-Pro |
|---|---|---|
| 多模态理解数据 | ~10M | ~80M(8× 扩展) |
| 文本生图数据(真实图像) | ~25M | ~72M(3× 扩展) |
| 文本生图数据(合成图像) | 0 | ~72M(新增) |
关键新增:Janus-Pro 引入了大规模合成图像数据——用现有 SOTA 生成模型(如 SD3、DALL-E 3)产出的高质量图文对作为训练数据。这种”用生成模型增强生成模型”的 bootstrap 思路与 W7 DeepSeek-Math 的合成证明数据、W8 DeepSeek-Prover 的 autoformalization 数据是同一种方法论。
5.3 训练策略优化
Janus-Pro 还做了一些 Stage 2 训练的微调:
- 更长的 Stage 2 训练:从 V1 的 200B tokens 增加到 700B
- 更精细的损失权重平衡:理解 loss 与生成 loss 的相对权重经过专门搜索
- 加入 classifier-free guidance training:在生成路径上加入 CFG 训练样本,提升 text-to-image alignment
六、评测结果
6.1 Text-to-Image 生成 benchmark
Janus-Pro-7B 在文本生图主流 benchmark 上的成绩:
| 模型 | GenEval | DPG-Bench |
|---|---|---|
| Stable Diffusion 1.5 | 0.43 | – |
| SDXL | 0.55 | 74.65 |
| DALL-E 3 (OpenAI) | 0.67 | 83.50 |
| SD3-Medium | 0.74 | 84.08 |
| Janus-Pro 1B | 0.73 | 82.63 |
| Janus-Pro 7B | 0.80 | 84.19 |
关键观察:
- GenEval 上 Janus-Pro-7B 拿到 80%,明显超过 DALL-E 3 的 67% 与 SD3 的 74%——这是开源统一多模态模型在文本生图任务上第一次明确跑赢专门的 diffusion 生成模型
- Janus-Pro 1B 已经接近 SD3-Medium——小模型也有竞争力
- DPG-Bench 上 Janus-Pro-7B 超过所有对比模型——长 prompt 跟随能力最强
6.2 多模态理解 benchmark
Janus-Pro-7B 在理解任务上的表现:
| 模型 | MMBench | MMMU | POPE | MM-Vet |
|---|---|---|---|---|
| Chameleon 7B | 35.7 | 22.4 | – | 8.3 |
| LLaVA-1.5 7B | 64.3 | 36.4 | 86.1 | 31.1 |
| Qwen2-VL 7B | 80.5 | 54.1 | – | 62.0 |
| Janus-Pro 7B | 79.2 | 41.0 | 87.4 | 50.0 |
关键观察:
- MMBench 上 Janus-Pro-7B (79.2) 几乎与 Qwen2-VL 7B (80.5) 持平——这是”统一多模态” 第一次在理解任务上追平专门的理解模型
- 大幅领先 Chameleon 7B(35.7 → 79.2)——说明双 encoder 解耦比单 encoder 强 2× 以上
- POPE 上 87.4 是开源最佳之一——hallucination 控制能力强
6.3 综合评估
Janus-Pro-7B 是目前开源唯一一个在理解与生成两方面都达到 top-tier 水平的统一模型。其他对比:
- Chameleon:架构统一,理解能力差
- DeepSeek-VL(W6)/LLaVA:理解强,无生成能力
- DALL-E 3/SD3:生成强,无理解能力
- Janus-Pro:双 top-tier
这是双 encoder 解耦设计的最直接价值——用结构性解耦同时获得两种能力的”专门级”水平,而非妥协式融合。
先弄清 GenEval 在测什么
把 GenEval 的 80% 当成「Janus 画图超过 DALL-E 3」的证据之前,我认为先要弄清这个 benchmark 在测什么。GenEval 的子任务是物体共现、计数、颜色绑定、相对位置——本质上测的是 prompt 遵循能力,而不是画质。分辨率、质感、光影、人脸与文字细节这些用户一眼就能感知的维度,GenEval 基本不计分。
这恰好解释了统一模型为什么在这类评测上占便宜:以 LLM 为主干的架构,语言理解与组合解析天然强,prompt 遵循类指标自然好看;而 Janus 的生成路径是 384×384 的 VQ tokenizer,重构精度有限,画质恰恰是它的短板——论文自己也承认小字符与人脸细节不如 SD3。换句话说,GenEval 放大了 Janus 的长处,又恰好不惩罚它的短处。
所以我的判断是:「统一理解+生成」在评测上的领先是真实的,但口径偏窄;产品上文生图的用户决策主要由画质与美学驱动,这部分 GenEval 并不背书。值得追问的是:如果同时报告人类偏好类评测(ELO 或盲评胜率),Janus 的排名是否还能保持?论文没有给出这组对照,读者需要自己留一个问号。
七、与系列其他论文的”解耦”主线呼应
Janus 的”解耦”设计哲学不是孤例——回顾 DeepSeek 系列前几篇 paper,”识别隐性 trade-off → 用结构性解耦消除”是反复出现的主线:
| 论文 | 隐性 trade-off | 解耦方案 |
|---|---|---|
| W3 DeepSeekMoE | expert 容量 vs 路由组合空间 | fine-grained expert(专精)+ shared expert(通用) |
| W6 DeepSeek-VL | 全局语义 vs 局部细节 | SigLIP-L(语义)+ SAM-B(细节) |
| W7 V2/MLA | attention 表达力 vs KV cache | content 部分(latent 压缩)+ RoPE 部分(小维度) |
| W10 Aux-Loss-Free | balance vs specialization | bias(balance)+ affinity(specialization) |
| W11 Janus(本文) | 理解 vs 生成 | SigLIP 路径(理解)+ VQ 路径(生成) |
可以看到这是 DeepSeek 团队最稳定的工程哲学——当观察到一个组件需要同时承担多个目标且这些目标天然冲突时,不要试图用单一机制妥协,而要把不同目标拆到不同组件上各自优化。
这种哲学的本质是结构上的关注点分离(separation of concerns)——一个非常古老的软件工程原则,但在深度学习架构设计中并不总是被显式遵循。DeepSeek 团队反复用它作为破解性能瓶颈的工具,得到的累积效果是非常可观的。
八、局限与未来方向
Janus / Janus-Pro 是一项里程碑式的工作,但仍有几个明显局限:
- 训练成本较高:双 encoder + 大数据让 Janus-Pro-7B 的训练成本约为同规模 DeepSeek-VL 的 2-3 倍
- VQ tokenizer 限制图像质量上限:当前 VQ tokenizer 的重构 PSNR 约 21-25dB,仍低于 diffusion model 的连续表征。这导致 Janus 生成的图像在极精细细节(小字符、人脸)上不如 SD3
- 生成分辨率较低:V1 / Pro 都在 384×384 分辨率训练,输出图像质感受限。未来需要 dynamic tiling 或 patch 分级以支持更高分辨率
- 视频与 3D 生成未涉及:当前仅支持静态图像,扩展到视频需要额外的 temporal modeling
后续方向:JanusFlow 与统一生成
DeepSeek 在 2024-11 还发布了 JanusFlow(arXiv:2411.07975)——把 Janus 的 autoregressive 生成 head 替换为 rectified flow 生成 head。Rectified flow 是 diffusion 的简化版,理论上能产出更高质量的图像。JanusFlow 验证了”双 encoder 解耦 + 任意 generation head”的灵活性——理解路径不变,生成路径可以从 AR 换成 flow、换成 diffusion,模块化非常清晰。
这种”主干稳定 + 头部可替换”的设计是 Janus 系列后续演化的重要方向。可以预期未来会出现 Janus + better tokenizer、Janus + diffusion head、Janus + video generation 等多种变体,但双 encoder 解耦的核心设计会保持不变。
写在最后
Janus 是 DeepSeek 多模态主线上最具方法论意义的一篇 paper。它不是单点性能突破(虽然 GenEval 80% 确实是突破),而是给出了一个统一多模态模型应该如何设计的清晰范式:
- 不要追求架构的”绝对统一”:单一 encoder 听起来优雅,但面对天然冲突的两个任务(理解 vs 生成)会顾此失彼
- 解耦视觉编码路径:理解走语义 encoder,生成走 VQ tokenizer,两条路径互不干扰
- 保留主干统一:所有视觉信息最终汇入同一个 LLM,让模态对齐工作交给 LLM 主干自然学习
这套设计让 Janus-Pro-7B 在理解 benchmark 上接近 Qwen2-VL、在生成 benchmark 上超过 DALL-E 3——这是开源统一多模态模型的第一次”双向 top-tier”。
回到序言里 DeepSeek 论文四条主线,Janus 与 W6 DeepSeek-VL 并行存在——前者负责”理解 + 生成统一”,后者负责”纯理解优化”。两条路线分工明确,互相支撑。可以预期未来 DeepSeek 的多模态产品会逐步收敛到 Janus 的统一架构上,因为这是更通用的形态。
下一篇 W12 我们详解 DeepSeek-V3(arXiv:2412.19437)——这是 DeepSeek 通用 LLM 主线上的旗舰之作,把 W3 DeepSeekMoE、W7 MLA、W10 Aux-Loss-Free 三项支柱设计放大到 671B 总参 / 37B 激活的规模,同时引入 FP8 训练、DualPipe 调度、MTP (Multi-Token Prediction) 等多项硬件级与算法级工程优化,把训练成本压到震惊整个行业的 558 万美元水位。V3 是 DeepSeek 系列中工程深度最高、影响力最大的单篇 paper——下一篇我们会系统梳理它的每一项创新。
参考资料
- Wu et al., Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation, arXiv:2410.13848, 2024.
- Chen et al., Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling, arXiv:2501.17811, 2025.
- JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation, arXiv:2411.07975, 2024.
- Janus GitHub repository:
- Chameleon Team, Chameleon: Mixed-Modal Early-Fusion Foundation Models, arXiv:2405.09818, 2024.
- Zhai et al., Sigmoid Loss for Language Image Pre-Training (SigLIP), arXiv:2303.15343, 2023.
- Sun et al., Autoregressive Model Beats Diffusion: LlamaGen (VQ Tokenizer), arXiv:2406.06525, 2024.
- Lu et al., DeepSeek-VL: Towards Real-World Vision-Language Understanding, arXiv:2403.05525, 2024.
![]()
2026-04-17 at 11:23 上午
第七节那张”解耦哲学贯穿全系列”的表读着很爽,但有点”事后归因”的味道。