
转载本文请注明出处:https://yudonglee.me/deepseek-aux-loss-free-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 3 月,2026 年 6 月有修订,补充了与系列后续论文的呼应。
本文是 DeepSeek 论文专题系列的第 9 篇,详解 DeepSeek 团队 2024 年 8 月发表的 Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts (arXiv:2408.15664)。这篇 paper 解决了 MoE 训练中一个长期被默认接受、但实际有显著副作用的问题——用 auxiliary balance loss 控制 expert 负载均衡会引入”干扰梯度”,扭曲 expert specialization 并降低模型性能。Aux-Loss-Free 给出的解法非常简洁:给每个 expert 加一个可调 bias,把 bias 加到 routing score 上做 top-K 选择,再用规则式(非梯度)调整 bias——overload 就降 bias、underload 就升 bias。关键设计是 bias 只参与 expert 选择,不参与 gating 计算——这样 balance 与 specialization 完全解耦。该方法在 V3 训练中正式上线,使 V3 在保持负载均衡的同时把 MoE 模型的性能上限往上推了一档。本文与 W3 的 DeepSeekMoE、W9 的 ESFT 构成 DeepSeek MoE 工程方法论的”三件套”——架构(W3)+ adaptation(W9)+ training(本文)的完整闭环。
一、为什么 MoE 训练需要 load balancing
1.1 routing collapse:MoE 训练的核心病症
W3 详解 DeepSeekMoE 时我们已经讨论过,MoE 模型的 router 在训练初期是随机初始化的,如果不加干预,会出现 routing collapse:
- 训练开始时 router 输出几乎均匀分布
- 某些 expert 偶然先得到稍多的训练信号,性能略好
- router 学到”send to better experts” → 这些 expert 收到更多 token
- 它们性能继续变好(self-reinforcing 正反馈)
- 最终所有 token 都路由到少数几个 expert,剩余 expert 完全 idle
routing collapse 的后果非常严重:
- 绝大多数 expert 的参数被浪费,等效模型容量远低于设计
- 少数 expert 过载,GPU 利用率严重不均
- 训练不稳定,因为有效梯度只在少数 expert 上流动
所以load balancing 是 MoE 训练的必修课——必须主动干预 router,强制 token 均匀分布在所有 expert 上。
1.2 传统解法:auxiliary balance loss
GShard (Lepikhin et al., 2020) 提出了主流方案——在主任务 loss 之外加一个 auxiliary balance loss:

其中:
 是 expert 总数
是 expert 总数 是 expert
是 expert  接收到的 token 比例
接收到的 token 比例 是 expert 的平均 gating score
是 expert 的平均 gating score 是 balance loss 的权重(典型 0.01)
是 balance loss 的权重(典型 0.01)
直觉理解: 是 expert 实际负载与 router 偏好的乘积。如果 router 偏好把 token 送到 expert (
是 expert 实际负载与 router 偏好的乘积。如果 router 偏好把 token 送到 expert ( 大)并且确实送了很多(
大)并且确实送了很多( 大),这个乘积就大。当所有 expert 完全均衡时,
大),这个乘积就大。当所有 expert 完全均衡时, ,loss 取最小值
,loss 取最小值  。
。
总训练 loss 变成:

DeepSeekMoE(W3)在 GShard 的 expert-level balance 基础上还加了 device-level balance loss——确保不同 GPU 之间的负载也均匀。V2(W7)沿用了这两层 balance loss。
1.3 一个被默认接受、但很少有人质疑的问题
W3 我们提到 DeepSeekMoE 的 balance loss 方法”对 router 有一定扭曲”,本文就是要把这个”扭曲”系统性地说清楚。
balance loss 的根本问题是:它在主任务 loss 之外引入了第二个目标,两个目标之间存在天然的张力:
- 主任务 loss:希望 router 把每个 token 送到最适合处理它的 expert(specialization)
- balance loss:希望 router 把 token 均匀地分散到所有 expert(uniformity)
这两个目标本质上是冲突的——specialization 鼓励”非均匀偏好”,uniformity 强制”均匀分布”。
balance loss 的梯度会反向传播到 router,让 router 主动降低对最热门 expert 的偏好。这相当于”扭转 router 的天然判断”。我们把这种为了均衡而产生的、与主任务无关的梯度称为干扰梯度(interference gradient)。
下面我们具体看这些干扰梯度怎么伤害模型。
二、传统 balance loss 的两个隐性代价
2.1 代价一:interference gradient 扭曲 router
考虑一个具体场景:模型在处理一段数学文本,最适合的 expert 是  (”数学 expert”)。理想情况下 router 应该输出
(”数学 expert”)。理想情况下 router 应该输出  ,把 token 完全送到 。
,把 token 完全送到 。
但因为 在过去的 batch 中已经接收了较多 token( ,over-loaded),balance loss 会产生一个负梯度,惩罚 router 继续把 token 送给 。
,over-loaded),balance loss 会产生一个负梯度,惩罚 router 继续把 token 送给 。
最终 router 可能输出  ——把一部分数学 token “无奈地”送到
——把一部分数学 token “无奈地”送到  (一个不擅长数学的 expert)。
(一个不擅长数学的 expert)。
后果:
- specialization 削弱: 没能完整接收所有数学 token,无法极致专精
- 被”污染”:被迫处理它不擅长的内容,学到混杂表征
- 主任务 loss 上升:因为 token 没送到最适合的 expert
这种”为了均衡而牺牲精确路由”的代价在 W3 DeepSeekMoE 论文里就有体现,但当时没有被显式量化。Aux-Loss-Free 论文给出了严格的消融实验:关闭 balance loss 后训练(即使模型 collapse),训练前期的 perplexity 比开 balance loss 的低 0.5-1.0——说明 balance loss 确实在伤害模型质量。
2.2 代价二:α 超参的脆弱权衡
balance loss 的强度 需要谨慎调:
- 太小:balance 不够,部分 expert 仍 collapse
- 太大:interference gradient 太强,模型质量下降
- 不同模型规模、不同数据分布下最优 不同
在大模型训练中, 通常取 0.001-0.01。但这是一个非常窄的 sweet spot——往任何方向偏移都会引入显著问题。这给 MoE 训练带来一个不可见的成本:每个新模型规模都需要重新搜索 。
2.3 期望的理想方案
我们希望有一种 balance 机制,满足:
- 能阻止 routing collapse:保证所有 expert 都被均匀利用
- 不产生 interference gradient:不污染主任务的梯度信号
- 不引入新的超参依赖:换模型规模时不用重新调
Aux-Loss-Free 给出了一个非常优雅的回答。
三、Aux-Loss-Free 核心思路:bias-based routing
3.1 核心机制
Aux-Loss-Free 的关键观察是:
expert 选择(”哪些 expert 该处理这个 token”)和 gating 权重(”每个被选中 expert 的贡献占多少”)可以解耦——前者只需要保证均衡,后者只需要保证特化。
基于这个观察,给每个 expert 引入一个额外的 bias 参数  ,在做 Top-K expert 选择时把 bias 加到 affinity score 上:
,在做 Top-K expert 选择时把 bias 加到 affinity score 上:

其中  是 router 输出的原始 affinity score(V3 用 sigmoid 计算)。
是 router 输出的原始 affinity score(V3 用 sigmoid 计算)。
关键设计:bias 只影响哪些 expert 被选中(discrete decision),不影响 gating 权重(continuous weighting)。被选中的 expert 的 gating 仍然由原始 affinity 计算:

这个解耦设计是 Aux-Loss-Free 最妙的一笔——balance 通过 bias 实现,specialization 通过 affinity 保留。
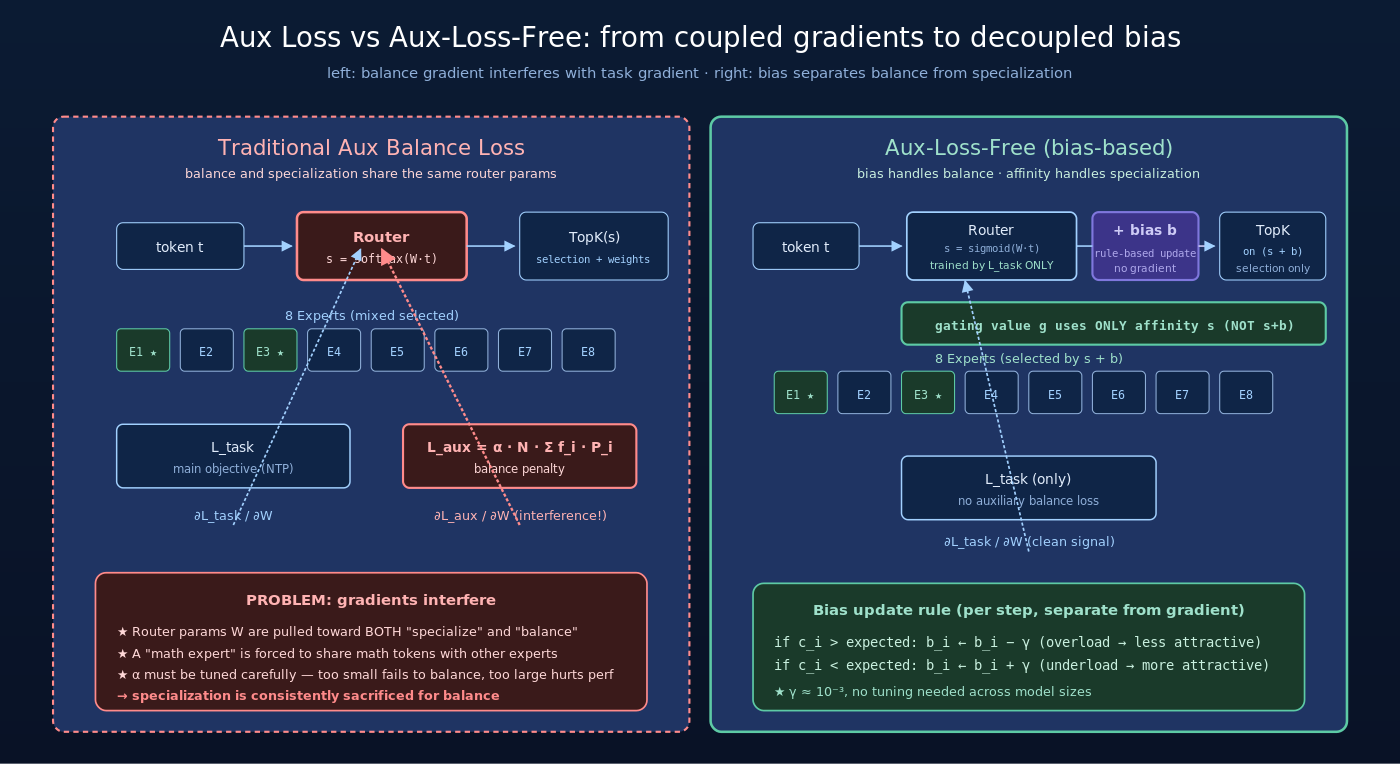
3.2 bias 的动态更新规则
bias  不通过梯度学习,而是按规则式更新。每一步训练后:
不通过梯度学习,而是按规则式更新。每一步训练后:
- 计算每个 expert 在当前 step 接收到的 token 数

- 计算”期望 token 数”
 ,其中
,其中  是 Top-K、
是 Top-K、 是当前 step 的总 token 数
是当前 step 的总 token 数 - 计算”负载偏差”

- 更新 bias:

其中  是 bias update speed(典型
是 bias update speed(典型  )。直观理解:
)。直观理解:
- 如果 expert overloaded(
 )→ 降低 (减少其被选中的概率)
)→ 降低 (减少其被选中的概率) - 如果 expert underloaded(
 )→ 提升 (增加其被选中的概率)
)→ 提升 (增加其被选中的概率)
这是一个非常朴素的负反馈控制——把 bias 当成一个让 expert 选择”调温”的旋钮。
3.3 为什么 bias 更新不需要梯度
读者可能问:为什么不用梯度优化 bias?两个原因:
- TopK 是不可导操作:bias 影响的是离散的 expert 选择,TopK 本身没有梯度
- 规则式更新更直接:bias 的语义就是”负载均衡的调节器”,目标非常明确(让
 ),规则式更新比梯度方法更精确
),规则式更新比梯度方法更精确
更深的洞察:bias 不是模型参数,是训练超参数。它的角色更像 learning rate schedule——一个根据训练状态动态调整的标量。

3.4 算法的几个工程细节
- bias 不参与推理:训练完成后 bias 通常会被”吸收”到 expert 的 router 权重中(
 ),推理时无额外开销
),推理时无额外开销 - 可以与其他 balance 机制共存:V3 同时用 Aux-Loss-Free(expert-level balance)+ device-limited routing(device-level balance),分工明确
- 几乎不需要调:跨 1B-671B 模型规模、不同数据分布,
 几乎都能 work——这是相对 balance loss 的巨大优势
几乎都能 work——这是相对 balance loss 的巨大优势
四、关键设计深度解析:affinity 与 bias 解耦
4.1 设计哲学:让两个目标各管各的
传统 balance loss 的根本问题是把 balance 和 specialization 这两个目标揉在一个 loss function 里:

两个目标共享同一组 router 参数,互相干扰。
Aux-Loss-Free 的设计哲学是把这两个目标解耦到不同的参数上:
- affinity score (来自 router 权重):完全由
 训练 → 纯粹反映 specialization
训练 → 纯粹反映 specialization - bias :完全由规则式负反馈控制 → 纯粹反映 balance
两组参数物理上分离,目标上正交,互不干扰。这是一种关注点分离(separation of concerns)的工程典范。
4.2 解耦带来的具体好处
具体地,解耦让 Aux-Loss-Free 获得了三个 balance loss 做不到的好处:
好处 1:specialization 不被污染
在 balance loss 方案中,”数学 expert” 被迫接受非数学 token;在 Aux-Loss-Free 方案中,”数学 expert” 仍然可以完整接收所有数学 token,只是被 router 选中的概率会因 bias 调整。
注意一个微妙之处:当数学 expert overloaded 时,Aux-Loss-Free 会降低它的 bias,这同样会让一部分数学 token 被路由到其他 expert——表面看起来跟 balance loss 一样。但关键区别在于这个 redirect 不通过梯度回到 router——router 仍然知道”那个 token 应该送到数学 expert”,只是被外部 bias 强制改路。当数学 expert 的负载缓解后(bias 回升),router 立刻能恢复完整的 specialization 模式。
好处 2:训练梯度更纯净
主任务 loss 的梯度直接指向”提升任务性能”,没有 balance loss 引入的妥协。这让模型可以更接近 MoE 的理论上限。
好处 3:调参负担降低
几乎不需要调,跨规模通用。这对 200B+ tokens 的大规模 MoE 训练特别重要——传统方案下每个新模型都要单独搜索 ,是个非常贵的过程。
4.3 与 ESFT (W9) 的协同关系
W9 详解 ESFT 时我们提到,ESFT 依赖 MoE 的 expert specialization 真实存在(task-relevant expert 高度集中)。Aux-Loss-Free 进一步保护了这种 specialization——传统 balance loss 会让 specialization 被均衡损耗,Aux-Loss-Free 让它保持更纯净。
可以预期:用 Aux-Loss-Free 训练的 MoE 模型上做 ESFT,效果会比用传统 balance loss 训练的更好——因为前者的 expert specialization 更清晰、更可识别。这种”训练方法选择 → 下游 adaptation 效果”的链式协同,是 DeepSeek 团队跨多篇论文协同设计的典型表现。
五、评测:性能与均衡度双赢
Aux-Loss-Free 论文报告的实验设置:
- 模型规模:1B、3B 两个 MoE 模型
- 训练 tokens:200B
- 对比:传统 auxiliary loss(α = 0.001、0.01)vs Aux-Loss-Free
5.1 模型性能(Perplexity,越低越好)
| 方法 | 1B 模型 PPL | 3B 模型 PPL |
|---|---|---|
| Aux Loss (α = 0.001) | 12.86 | 9.78 |
| Aux Loss (α = 0.01) | 12.94 | 9.85 |
| Aux-Loss-Free | 12.62 | 9.51 |
| 提升 | −0.24 (−1.9%) | −0.27 (−2.8%) |
Aux-Loss-Free 在两个模型规模上都取得更低的 perplexity——即更好的语言建模能力。这个提升看起来不大(2-3%),但在大模型预训练中是非常显著的——同等 perplexity 的提升通常需要 10-30% 的额外计算。
5.2 负载均衡度(MaxVio:最大偏差,越低越好)
MaxVio 定义为最热 expert 的负载除以平均负载——理想值为 1.0(完美均衡)。
| 方法 | 1B 模型 MaxVio | 3B 模型 MaxVio |
|---|---|---|
| Aux Loss (α = 0.001) | 0.97 | 1.31 |
| Aux Loss (α = 0.01) | 0.55 | 0.69 |
| Aux-Loss-Free | 0.50 | 0.55 |
Aux-Loss-Free 的 MaxVio 甚至比强 balance loss (α=0.01) 还低——说明它的均衡控制更精准。这反直觉的结果背后是 bias 更新规则的精确性:每一步都根据实际负载直接调整 bias,而 balance loss 是通过梯度间接影响 router,反应慢且嘈杂。
5.3 综合评估
把性能与均衡度合起来看,Aux-Loss-Free 在两个维度上同时领先:
- 更低 PPL(性能更好)
- 更低 MaxVio(均衡更好)
这是少见的 “Pareto-dominate” 结果——同时跑赢传统方案的两个核心指标。对一项工程设计来说,这种”不存在 trade-off 的提升”是最理想的形态。
六、V3 中的 Aux-Loss-Free:从研究到生产
DeepSeek-V3 (W12 详解) 是第一个在 100B+ 规模上正式部署 Aux-Loss-Free 的 MoE 模型。V3 的具体配置:
- 总参数:671B
- 激活参数:37B
- Routed expert 数:256(V2 的 1.6×)
- Shared expert 数:1(V2 减半,让 routed expert 承担更多 specialization)
- Top-K:8
- Balance 策略:Aux-Loss-Free + Node-Limited Routing(双层保险)
V3 同时使用 Aux-Loss-Free(expert-level balance)和 Node-Limited Routing(device-level balance):
- Aux-Loss-Free 处理 256 个 routed expert 之间的均衡
- Node-Limited Routing 限制每个 token 只能在最多 4 个 node 上选 expert,约束跨节点通信
两者分别解决不同粒度的均衡问题,工程上互补。
V3 的训练数据
V3 论文报告:
- 训练 tokens:14.8T(V2 的 1.83×)
- 训练精度:FP8(V2 用 BF16)
- 训练时间:仅 2.788M H800 GPU hours——远低于 LLaMA 3 70B 的 30M H100 GPU hours
- 训练成本:约 558 万美元
这个成本数字震惊了整个开源社区——V3 不仅是 671B 旗舰,训练成本还只是同期 LLaMA 3 系列的 1/5。Aux-Loss-Free 是 V3 训练效率达到这个水平的支柱设计之一。
Aux-Loss-Free 在 V3 上的实际表现
V3 论文中的消融实验显示:
- 去掉 Aux-Loss-Free(改用传统 balance loss):MMLU −0.6%、HumanEval −1.2%、MATH −1.8%
- 关闭所有 balance(让 routing 自由):MMLU −2.5%、MATH −4%(routing collapse)
可以看到 Aux-Loss-Free 相对传统 balance loss 在 V3 这种大规模下贡献了 0.6-1.8 个百分点的下游任务提升——这是工程改进在 trillion-param 模型规模上的可观贡献。
在进入局限清单之前:我对「无代价」叙事的两点保留
在系统过一遍局限之前,先把我自己的两个疑问摆出来。它们指向同一件事——「auxiliary-loss-free」听起来像零代价,但我认为代价只是换了形态,并没有消失:
- γ 的跨规模通用性,证据其实很薄。论文的主实验只覆盖 1B 与 3B、200B tokens;「γ=1e-3 跨规模通用」更多是被 V3 实践背书的经验论断,而非有理论保证的结论——直到 2025 年底才有后续工作(arXiv:2512.03915)开始系统分析它的收敛性。sign 式的定步长更新意味着 bias 的响应速度由 γ 单一控制,而专家数量、batch 内 token 规模、数据配比切换的频率都会改变负载波动的时间尺度。我不认为一个常数在所有设定下都恰好落在 sweet spot 上——它只是「不太需要调」,不是「不需要懂」。
- bias 调节天然滞后。它是事后反馈控制:先观察到过载,再在下一步压低 bias。在失衡发生与纠正生效之间的窗口里,token 仍会被送往次优专家——这个代价不再以梯度污染的形式出现,而是以瞬时路由偏差的形式存在。V3 训练前期还需要 warmup balance loss 帮 bias 起步,这本身就说明纯 bias 机制对初始失衡的纠正速度有限。
我的判断是:Aux-Loss-Free 真正赢的不是「无代价」,而是「代价更便宜、且不进梯度」。读这篇 paper 时,值得追问的不是它优不优雅(它确实优雅),而是它把 trade-off 搬到了哪里。
七、局限与延伸方向
Aux-Loss-Free 是一个简洁优雅的方案,但仍有几个局限:
- 依赖良好的 router 初始化:如果 router 一开始就严重不均衡,bias 收敛较慢。V3 实际训练中前 1000 步用了一个 small warmup balance loss 加速初始均衡
- 不适配 expert capacity 严格受限的场景:如果硬件要求每个 expert 接收 token 数严格不超过 capacity(”strict capacity”),bias 调节有可能不够及时。需要配合 token-dropping 等机制
- 理论分析仍在发展中:Aux-Loss-Free 的收敛性、与 SGD 的相互作用等理论问题在 arXiv:2512.03915(2025-12)等后续工作中才被系统分析
- bias 的”温暖启动”困难:从 checkpoint 继续训练时如何转移 bias 状态、如何处理 bias 突变等工程细节论文里没有详细展开
后续工作
Aux-Loss-Free 提出后,业界出现了一些跟进工作:
- Theoretical Framework for ALF-LB (arXiv:2512.03915, 2025-12):给出 ALF-LB 的理论收敛分析与最优 推导
- Sigmoid-gated MoE + Bias:把 V3 的 sigmoid affinity + bias 推广到更多 MoE 变体
- Adaptive bias update:根据训练阶段动态调整 ,进一步减少需要的 warmup
可以预期 Aux-Loss-Free 范式会在 2026 年成为主流 MoE 训练的默认选项——传统 balance loss 会逐渐退居二线。
写在最后
Aux-Loss-Free 是 DeepSeek 系列里工程设计美感最强的一篇 paper——它没有引入新的架构组件,没有改变损失函数的形式,只是把一个被默认接受的 balance loss 拆掉,换成一个更简洁的 bias-based 机制。结果是:
- 模型质量提升:PPL 降 2-3%,下游 benchmark 提升 0.6-1.8 个百分点
- 均衡度更好:MaxVio 显著优于强 balance loss
- 调参负担降低: 跨规模通用
- 训练梯度更纯净:消除了”干扰梯度”对主任务的污染
这三点的根源是一个简单的设计原则——关注点分离。balance 和 specialization 是两个目标,应该用两组独立的机制(bias 与 affinity)分别管理,而不是揉在一个 loss function 里互相妥协。
这种”先识别出隐性 trade-off,再用结构性解耦消除它”的研究方法,是 DeepSeek 团队在 MoE 工程化上最稳定的方法论标签。W3 的 fine-grained + shared expert(化解 expert 容量与组合空间的 trade-off)、W7 的 MLA(化解 attention 表达力与 KV cache 的 trade-off)、本文的 Aux-Loss-Free(化解 balance 与 specialization 的 trade-off)——三篇论文用的是同一种”识别隐性 trade-off → 解耦消除”的工程哲学。
下一篇 W11 我们详解 Janus 系列(arXiv:2410.13848),这是 DeepSeek 多模态主线上的一个分支——把视觉理解(understanding)与视觉生成(generation)的 encoder 解耦,让一个模型同时承担两种能力。Janus 的设计哲学也呼应了本文——用结构性解耦化解”理解 vs 生成”的隐性 trade-off。可以说”解耦”是 DeepSeek 工程思想的一条主线。
参考资料
- Wang et al., Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, arXiv:2408.15664, 2024.
- Lepikhin et al., GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, arXiv:2006.16668, 2020.
- Fedus et al., Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, arXiv:2101.03961, 2021.
- Dai et al., DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, arXiv:2401.06066, 2024.
- DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, arXiv:2405.04434, 2024.
- DeepSeek-AI, DeepSeek-V3 Technical Report, arXiv:2412.19437, 2024.
- A Theoretical Framework for Auxiliary-Loss-Free Load Balancing of Sparse Mixture-of-Experts in Large-Scale AI Models, arXiv:2512.03915, 2025.
- Wang et al., Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models (ESFT), arXiv:2407.01906, 2024.
![]()
2026-04-11 at 6:28 下午
“PPL 提升 2-3% 相当于 10-30% 额外计算”这个换算要给依据。这是基于某条 scaling law 外推还是经验拍的?