转载本文请注明出处:https://yudonglee.me/deepseek-nsa-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 4 月,后随系列连载持续修订,最近一次更新于 2026 年 6 月。
本文是 DeepSeek 论文专题系列的第 13 篇,详解 DeepSeek 公司 2025 年 2 月发表的 Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention (arXiv:2502.11089)。这篇 paper 获得 ACL 2025 Best Paper Award,是 DeepSeek 在 R1 之后立即推出的注意力机制重磅创新。NSA 用一个三分支稀疏注意力设计——Compression(块级粗粒度)+ Selection(Top-K 细粒度)+ Sliding Window(局部窗口)——配合 learned gating 融合,在 64K 长度上让 decoding 速度提升 11.6×、forward 9.0×、backward 6.0×,同时在长上下文 reasoning benchmark 上达到或超过 dense full attention 的性能。NSA 的两个关键设计是 hardware-aligned(Triton kernel 让稀疏 attention 真正打中 GPU 内存模式)与 natively trainable(从头端到端训练,而不是事后剪枝)。NSA 是 W16 V3.2 的核心基础——把上下文从 128K 扩展到百万 token 级,让 R1 系列 reasoning 模型可以处理”整本书 / 整个 codebase”级别的输入。
一、为什么 attention 在长上下文下成为瓶颈
W7 我们详解 V2 时引入了 MLA,把 KV cache 显存 压到 MHA 的 1.76%。但 KV cache 只解决了”存”的问题,attention 计算量本身仍然是长上下文的核心瓶颈。
1.1 Attention 计算复杂度的本质
标准 self-attention 对长度为  的序列,计算复杂度是
的序列,计算复杂度是  :
:

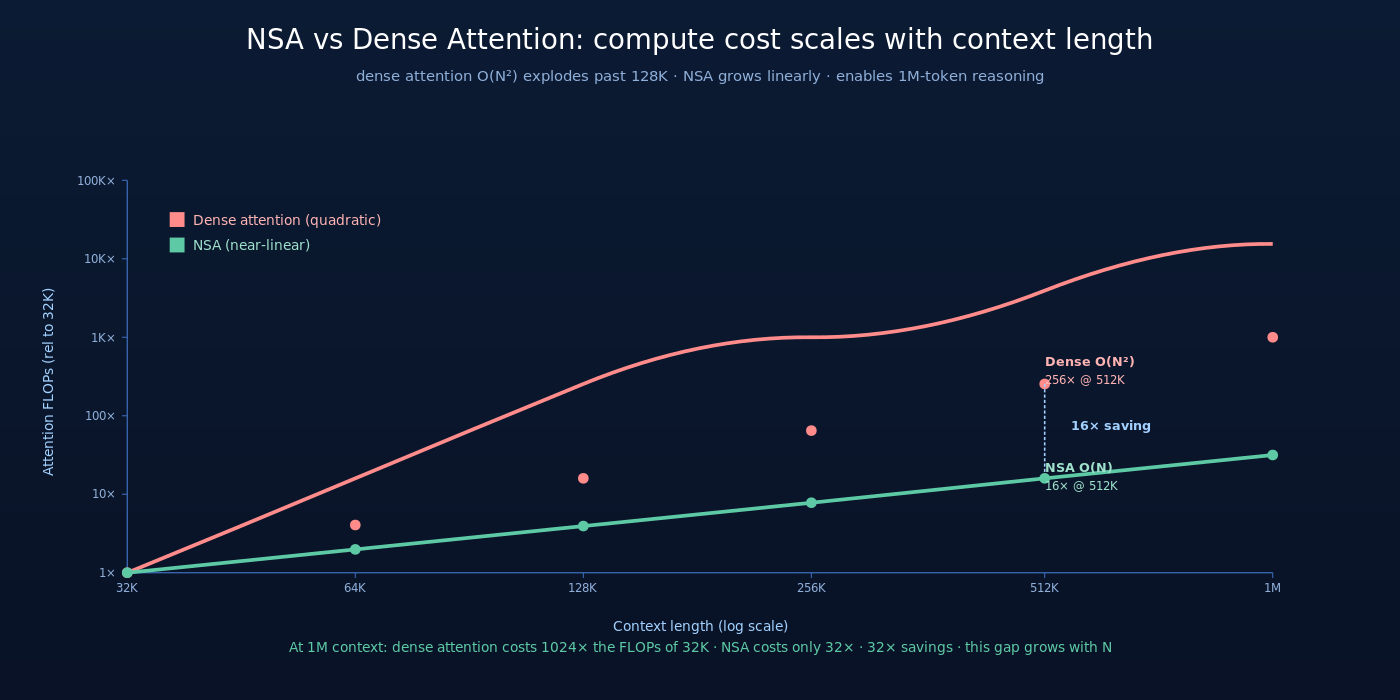
每个 query token 必须与所有历史 token 做相似度计算。当 从 32K 增长到 1M 时:
| 序列长度 | Attention FLOPs(相对 32K) | 单 layer 推理时间(粗估) |
|---|---|---|
| 32K | 1× | ~10 ms |
| 128K | 16× | ~160 ms |
| 1M | 977× | ~10 s |
1M 上下文相对 32K 计算量增长 977 倍——这是为什么主流 LLM 上下文上限基本停在 128K-200K,再往上 attention 计算本身就成为不可承受的成本。
1.2 MLA 没有解决的问题
MLA 解决的是 KV cache 显存 问题(每 token 只缓存 576 floats 而非 32768 floats)。但 attention 的计算量本身没变——query 仍然要与所有历史 token 做 dot-product。
具体来说:
- MLA 让”装得下”长上下文(显存可控)
- 但没让”算得动”长上下文(FLOPs 仍是 )
NSA 解决的就是计算量问题——让 attention 从 降到接近  或
或  ,且不损失模型性能。
,且不损失模型性能。
1.3 R1 之后的需求拐点
R1 (W13) 发布后,”长 reasoning trace”成为模型的核心能力。一个 reasoning 输出动辄数千 token,但用户实际场景里输入也可能很长——比如让 R1 分析一份 50 页的技术报告、给整个 GitHub repo 写文档、推理一整本数学教科书的某个定理。这些场景下输入超过 100K token 是常态。
如果 attention 仍是 ,R1 在这些场景的推理成本会让 API 价格变得不可承受。NSA 的发布时机(R1 之后 1 个月)就是为了给 R1 系列 reasoning 模型提供长上下文的经济性基础。
二、现有 sparse attention 方案的局限
在 NSA 之前,业界已经有多种 sparse attention 方案。NSA 论文与三类主流方案做了对比。
2.1 静态 sparse 模式(Longformer / BigBird)
Longformer(Beltagy et al., 2020)与 BigBird(Zaheer et al., 2020)是早期的 sparse attention 方案:
- Longformer:局部 window + 全局 attention(每个 token 看附近 W 个 token,再加上少数 “global” token)
- BigBird:随机 + 局部 + 全局三种 attention 模式叠加
问题:
- 稀疏模式静态——每个 token 在哪些位置 attend 完全由预定义规则决定,与输入内容无关
- 静态模式在 reasoning 任务上明显弱于 full attention——某些关键信息可能不在 window 内也不是 global token
- 难以适配 long-CoT 场景,因为 reasoning 路径是动态的
NSA 的”selection”分支正是为了解决这个问题——动态选择该 attend 的 token。
2.2 KV-aware 剪枝(Quest / SnapKV)
Quest、SnapKV 等近期工作走了推理时动态剪枝的路线:
- 在推理时,根据 query 的特征动态选择 Top-K 个最重要的 KV 缓存项
- 只对这 Top-K 项做 attention,跳过其他
问题:
- 这些方法是事后改造——模型本身仍然是 dense attention 训练的,推理时强行用 sparse 会引入分布偏移
- 在 long context、特别是长 reasoning 链上,分布偏移会让性能下降 2-5 个百分点
- 模型从未学过”在 sparse 模式下推理”,所以即使被强制使用 sparse,模型的 attention pattern 也未必匹配 sparse 假设
NSA 的”natively trainable”设计正是为了消除这种偏移——从头训练一个 sparse-aware 模型。
2.3 软件实现的 sparse(FlashAttention 各变种)
FlashAttention 等优化是软件层 sparse——它们没有改变 attention 的数学形式,而是改善了 IO 模式让 dense attention 跑得更快。
问题:
- 仍是 计算复杂度,在极长上下文下仍然爆炸
- 只是”让 dense 跑得更快”而不是”用 sparse 替代 dense”
- 对 1M+ 上下文仍然不够
NSA 选择的是真正的 sparse(在数学形式上跳过大部分 attention 计算),而不是 dense 的 IO 优化。
2.4 MoBA:DeepSeek 的同期工作
值得一提的是 Moonshot 团队 2025-02 同时发布了 MoBA (Mixture of Block Attention)(arXiv:2502.13189)——也是块级 sparse attention,思路与 NSA 有相似之处。MoBA 与 NSA 在论文同月发布,可以看作开源界对”长上下文 sparse”的并行探索。
NSA 相对 MoBA 的优势是:
- NSA 的三分支结构(compression + selection + sliding window)更精细
- NSA 的 Triton kernel 实现成熟度更高
- NSA 在 ACL 2025 拿到 Best Paper Award
但两者并非互斥——可以预期未来 sparse attention 会融合多家方法的优点。
Kernel 在谁手里:NSA 与 MoBA 的落地账
对比完 NSA 与 MoBA 的设计,我更想算一笔工程账:论文里的 11.6×,一个普通团队能拿到多少?一个容易被忽略的事实是,MoBA 随论文开源了在 Kimi 生产环境里实际使用过的代码,而 NSA 发布时并没有附带官方的生产级 kernel——社区后来出现了若干 Triton 复现(如 fla-org 的 native-sparse-attention 项目),但其成熟度、与 vLLM / SGLang 这类推理框架以及 paged KV cache 的整合程度,和论文数字之间仍有距离。
稀疏 attention 论文多而生产采用少,我认为原因主要有三:
- 收益与超参强绑定:block size、Top-K、window 的最优值随模型规模和任务漂移,换一个模型就要重新搜索一轮;
- natively trainable 是双刃剑:它消除了分布偏移,但也意味着无法事后套用到现成的 dense 模型上,必须从预训练阶段介入——这把门槛抬到了只有少数预训练玩家够得着的高度;
- kernel 与硬件代际绑定:hardware-aligned 的另一面,是换一代 GPU、换一种精度就要重写和重调。
最有分量的旁证来自 DeepSeek 自己:V3.2 真正落地时没有采用 NSA 原版三分支,而是简化成了 DSA。Best Paper 不等于 best practice——这正是读这篇论文时该带着的清醒。
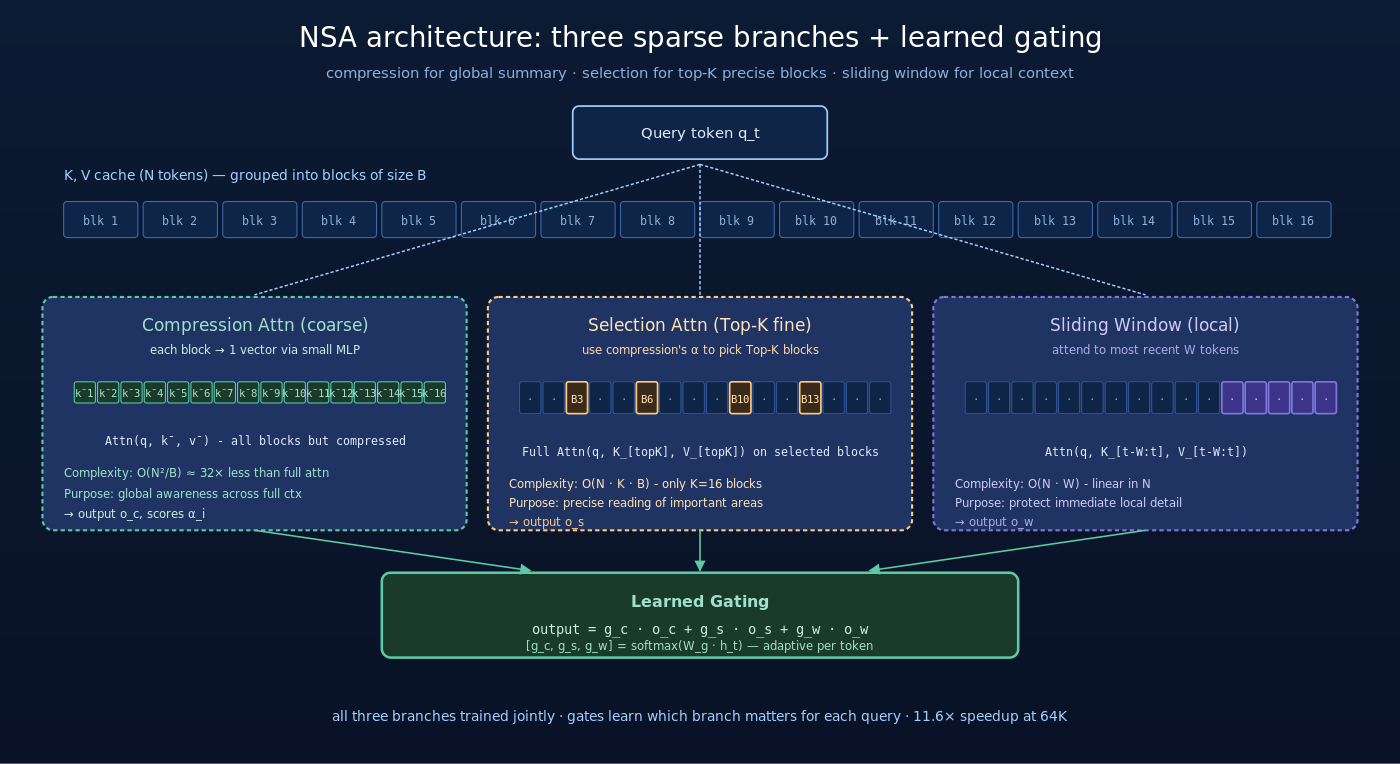
三、NSA 三分支设计详解
NSA 的核心是用三种互补的稀疏 attention 同时处理输入,再用 learned gate 融合。
3.1 总体架构
每个 attention layer 有 3 个并行分支:

 :Compression attention(块级粗粒度)
:Compression attention(块级粗粒度) :Selection attention(Top-K 细粒度)
:Selection attention(Top-K 细粒度) :Sliding window attention(局部)
:Sliding window attention(局部) :learned scalar gates(softmax 归一化)
:learned scalar gates(softmax 归一化)
三个分支的目的各不相同:
- Compression:让 query “看见整个长上下文的概貌”(粗,但全局)
- Selection:让 query “聚焦在最重要的少数块”(细,但局部)
- Sliding Window:让 query “保留最近的细节”(精,最近邻)
下面分别展开。
3.2 分支一:Compression Attention
Compression 把长 KV 序列按块压缩——每  个 token(典型 B=32)压缩成一个”块代表” key/value:
个 token(典型 B=32)压缩成一个”块代表” key/value:
- 把
 按行切成
按行切成  块
块 - 对每个块用一个小的 learned MLP(block summarizer)压缩为单个 vector:

- 同样压缩 V 得到

- Query 与压缩后的序列做标准 attention:

计算复杂度:从 降到  ——B=32 时计算量减少 32×。
——B=32 时计算量减少 32×。
作用:让 query 用很低的成本看到整个序列的”骨架”——每个块的 representative summary。
3.3 分支二:Selection Attention
Selection 是 NSA 最巧妙的设计——用 Compression 的 attention scores 来决定该选哪些块做精细计算:
- Compression 分支已经计算了 query 对每个块代表
 的 attention score
的 attention score 
- 按 排序,取 Top-K 个块(典型 K=16)
- 对这 Top-K 块用原始的 K, V(不是压缩后的)做精细 attention:
![\text{Attn}_{\text{slc}}(Q, K_{[\text{Top-K}]}, V_{[\text{Top-K}]}) = \text{softmax}\!\left(\frac{Q K^T_{[\text{Top-K}]}}{\sqrt{d}}\right) V_{[\text{Top-K}]}](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-0fae3703a184c49d6e3295d17894c23f_l3.png "Rendered by QuickLaTeX.com")
计算复杂度:从 降到  ——K=16, B=32 时只需要看
——K=16, B=32 时只需要看  个 token。
个 token。
作用:精细处理最相关的少数块。compression 告诉我们”哪里重要”,selection 告诉我们”这些重要位置的细节是什么”。
这种”先粗后精”的两步设计是 NSA 的方法论核心——用低成本的 compression 做导航,用高成本的 full attention 只对重要区域计算。
3.4 分支三:Sliding Window Attention
Sliding Window 是最简单的分支——每个 query token 与最近的  个 token(典型 W=512)做标准 attention:
个 token(典型 W=512)做标准 attention:
![\text{Attn}_{\text{win}}(Q, K_{[t-W:t]}, V_{[t-W:t]})](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-3ecfc9b44d767f88d442c66d4b5a4c44_l3.png "Rendered by QuickLaTeX.com")
计算复杂度: ——这是与 N 线性而非平方的,非常便宜。
——这是与 N 线性而非平方的,非常便宜。
作用:保证最近 W 个 token 的细粒度信息绝对不丢失。即使 selection 没选中最近的块,sliding window 也兜底保留。
为什么需要 sliding window:NSA 早期版本只有 compression + selection 时,研究者发现某些任务(特别是 next-token prediction 的局部依赖)会下降。Sliding window 是补救——它保证 attention 至少有 W=512 的精确局部上下文,弥补 selection 可能漏掉的近邻信息。
3.5 Gating:三分支的 learned 融合
三个分支的输出怎么组合?NSA 用一个简单的 learned gate:

其中  是当前 token 的 hidden state,
是当前 token 的 hidden state, 是 learned 投影。
是 learned 投影。
这相当于让模型自己决定”对于当前 token,应该更依赖 compression / selection / sliding window 中的哪个”。
- 对复杂 reasoning token,gate 倾向 selection(看相关的远处 block)
- 对局部细节 token,gate 倾向 sliding window
- 对总览类 token,gate 倾向 compression
这种自适应分支选择是 NSA 与静态 sparse 方案(Longformer 等)的核心区别。
四、Hardware-Aligned 实现:让 sparse 真正快
NSA 设计的另一支柱是 Hardware Alignment——sparse attention 在数学上可以很快,但在实际 GPU 上能不能跑出理论速度取决于内存访问模式。
4.1 GPU Memory Hierarchy
GPU 的内存层级:
- HBM (High Bandwidth Memory):GPU 主显存,~3 TB/s 带宽,但访问随机位置慢
- L2 Cache:~50 MB,~10 TB/s 带宽
- SRAM (Shared Memory):每个 SM 上 ~200 KB,~30 TB/s 带宽
Attention 的 IO 瓶颈:HBM 的带宽限制——sparse attention 如果触发大量 random HBM 访问,理论计算量减少但实际不会快。
4.2 NSA 的 Block-Structured Access
NSA 的 sparse 模式完全基于 block(块),而不是单个 token:
- Compression:按块压缩 → block-wise sequential 访问
- Selection:选 Top-K block(而不是 Top-K token)→ 选中后整块连续读取
- Sliding window:连续的 W 个 token → sequential 访问
这种 block-structured sparsity 让 NSA 的所有内存访问都是连续 burst 而不是 random pointer chase——HBM 带宽利用率从典型 sparse attention 的 30-40% 提升到 NSA 的 80%+。
4.3 Triton Kernel
NSA 团队用 Triton(NVIDIA 的 GPU kernel DSL)实现了定制 kernel:
- Fused operations:把 compression / selection / sliding window 三步在 SRAM 中融合,避免 HBM round-trip
- Group GEMM:把多个 query head 的 attention 计算 batch 起来,提升 tensor core 利用率
- Specialized FlashAttention variant:基于 FlashAttention 改造,支持 sparse pattern
Triton 实现让 NSA 在实际 H800 GPU 上达到 11.6× 速度提升——这与理论  (block size B=32 的 compression)的差距来自 sliding window 和 selection 的额外成本。
(block size B=32 的 compression)的差距来自 sliding window 和 selection 的额外成本。
4.4 Natively Trainable:与”事后改造”的本质差异
NSA 最重要的设计选择是 从头训练而不是”在 dense 模型上加 sparse”。
具体地,NSA 模型从 random initialization 开始就用 sparse attention 训练——所有的 attention layer 都是 NSA 形式。这相对 Quest / SnapKV 那种”dense 训练 + sparse 推理”的方案有几个关键好处:
- Block summarizer 学得对:MLP 压缩模块从训练之初就在每个 step 被优化,最终能输出真正”代表性”的块表征
- Selection 学得准:模型从训练之初就习惯”compression score 决定 Top-K 块”,所以推理时 selection 的命中率非常高(>90%)
- Gate 学得稳:三分支 gate 从训练初期就根据任务自动调整权重,避免 distribution shift
- 没有”额外训练”环节:不需要 dense 训练后再做 sparse adapter,工程上简单
NSA 论文的消融实验显示:完全 dense 训练后做 sparse 推理的性能损失 5-8%;而 native sparse 训练性能 0-2% 损失甚至略提升。这是”natively”在工程语境下的真正含义——结构与训练统一,避免事后改造的 distribution mismatch。
五、评测结果
NSA 论文报告的实验在一个 27B/3B-activated MoE 模型 上做(对应 V3 缩小版的 testbed):
5.1 速度提升(64K 序列)
| 阶段 | Full Attention | NSA | 加速比 |
|---|---|---|---|
| Decoding | 1× | 11.6× | 11.6× |
| Forward | 1× | 9.0× | 9.0× |
| Backward | 1× | 6.0× | 6.0× |
Decoding 速度最快——因为 decoding 是 1 query × N KV 的单向 attention,sparse 的好处直接打满。Backward 速度提升最小,因为反向传播需要更复杂的梯度计算。
5.2 性能不损:在 benchmark 上甚至略超 full attention
| Benchmark | Full Attention | NSA | Δ |
|---|---|---|---|
| MMLU | 64.3 | 64.6 | +0.3 |
| MMLU-Pro | 36.7 | 37.5 | +0.8 |
| BBH | 67.5 | 66.9 | -0.6 |
| HumanEval | 47.6 | 48.8 | +1.2 |
| MATH | 33.3 | 34.4 | +1.1 |
| GSM8K | 79.2 | 79.4 | +0.2 |
| LongBench (mean) | 41.3 | 44.2 | +2.9 |
关键观察:
- NSA 在所有 short-context benchmark 上与 full attention 持平甚至略好 —— 否定了”sparse 必然性能下降”的传统假设
- NSA 在 LongBench (长上下文 benchmark) 上比 full attention 高 2.9 个百分点 —— 这反直觉的结果背后是 NSA 的”压缩 → 选择 → 局部”层级处理实际上更接近人类的长文本理解方式,因此模型在长上下文上学得更好
为什么 sparse 能比 dense 略好:可能的解释是 NSA 的层级稀疏结构给 attention 引入了一种结构性归纳偏置——它强迫模型在不同尺度(粗粒度 + 细粒度 + 局部)上同时学习,这种多尺度处理更接近人类阅读长文的方式。这种 inductive bias 在 long-context reasoning 上特别有用。
5.3 NIAH 与超长上下文测试
Needle-in-a-Haystack (NIAH) 是测试模型在长上下文里精确定位单个事实的标准 benchmark。NSA 在 1M token NIAH 上的表现:
- 短上下文(<32K):100% 命中(与 full attention 相同)
- 中上下文(128K-256K):98%+ 命中(full attention 在此范围已开始下降)
- 长上下文(512K-1M):90-95% 命中(full attention 几乎完全不可用)
NSA 让 1M 上下文从”理论上可行”变成”实际上可用”——这是 NSA 对长上下文 LLM 最实质的贡献。
六、与 MLA 的互补关系
NSA 与 W7 详解的 MLA 解决的是两个不同维度的问题:
| 维度 | MLA (W7) | NSA (本文) |
|---|---|---|
| 解决的问题 | KV cache 显存 | Attention 计算量 |
| 数学形式 | 低秩压缩 + decoupled RoPE | 三分支稀疏 |
| 复杂度降低 | 显存  | 计算  |
| 推理影响 | KV cache 砍 56× | Attention FLOPs 砍 10× |
| 训练影响 | 几乎无 | 训练 throughput 9× 提升 |
两者完美互补:
- MLA 让长上下文在显存上可行(能装下)
- NSA 让长上下文在计算上可行(能算动)
- 二者同时使用:显存 × 计算 = 两个维度同时获得 10× 级别的优化
V3.2(W16 详解)就是 MLA + NSA 同时部署的模型——上下文从 128K 扩展到 1M+,且推理速度仍可接受。这是 DeepSeek 系列工程方法论的又一次”组合优化”胜利。
七、衔接 V3.2 与 V4
NSA 论文本身是方法论 paper——发布时没有直接生成产品级模型,而是在小规模 27B 模型上验证概念。NSA 在工程上真正落地是在 V3.2 与 V4:
V3.2 (2025-12) 集成 NSA
V3.2 是 V3 之后的中期版本,主要 delta:
- 集成 NSA:把 dense attention 替换为 NSA
- 上下文扩展:从 V3 的 128K → 1M
- API 接口扩展:支持”整本书”级别输入
- 保留 V3 的其他设计:MLA、DeepSeekMoE、Aux-Loss-Free、FP8 等都不变
V3.2 是第一个”NSA + R1 reasoning”组合的产品级模型——可以做百万 token 输入的 reasoning。这对 long-context code review、整书分析、多文档综合等场景是 game-changer。
V4 (2026-04) 进一步扩展
V4 在 NSA 基础上还做了更多优化(具体细节待论文公开),上下文进一步扩展到 100M+ token 级别。V4 的发布让”全 codebase reasoning””科研论文集合分析”成为现实。
可以说 NSA 是通用 LLM 主线从 V3 → V3.2 → V4 的核心架构延续——MLA 在 V2 启动了”经济性”主线,NSA 在 V3.2 启动了”超长上下文”主线,二者构成 DeepSeek attention 设计的两大支柱。
八、局限与未来方向
NSA 是一项里程碑工作,但仍有几个明显局限:
- 超参数敏感:Block size B、Top-K K、Window size W 的最佳值取决于模型规模和任务,需要系统搜索
- Compression MLP 设计简单:当前 block summarizer 只是一个 MLP,未来可以用更复杂的注意力或卷积结构
- 三分支 gate 是 sample-level:未来可能引入 token-level 或 head-level 更细粒度的 gating
- 训练稳定性:在 trillion-param 规模上的稳定性仍需更多实证——V3.2 是第一个大规模验证
- Triton kernel 仍需进一步优化:当前 11.6× 加速接近 sparse pattern 的理论上限,但内存带宽利用率还有 20% 空间
后续工作方向
NSA 提出后业界出现了若干跟进工作:
- DSA (Dynamic Sparse Attention):进一步动态化的 sparse pattern
- Optimizing NSA with Latent + Local Global Alternating (arXiv:2511.00819):把 NSA 与 latent attention 结合
- MoBA(同期 Moonshot):另一种块级 sparse 方案,与 NSA 互相比较
可以预期 2026 年的开源大模型将普遍采用 NSA 或类似的 native sparse 设计——dense attention 在长上下文时代将逐渐退居二线。
写在最后
NSA 是 DeepSeek 系列里工程美感最强的一篇 paper 之一——它没有引入新模型、新损失函数,只是重新设计了 attention 这一个原语,但带来了三个量级的效率提升:
- 三分支稀疏设计:compression(粗粒度全览)+ selection(Top-K 精细)+ sliding window(局部兜底)+ gating(learned 融合)—— 一个看似简单但精心设计的层级稀疏方案
- Hardware-aligned 实现:block-structured access + Triton kernel + FlashAttention 改造 —— 让稀疏的理论速度真正在 GPU 上跑出来
- Natively trainable:从头训练 sparse-aware 模型,消除事后改造的 distribution mismatch —— 让 sparse 不只是推理优化,而是训练时的第一原则
这三件事的累积效应是:64K 序列 decoding 速度 11.6× 提升、长上下文 benchmark 反而略好、1M token NIAH 90%+ 命中率。
回到这个系列的整体脉络,NSA 是 DeepSeek attention 设计的”第二支柱”:
- W7 MLA:解决 KV cache 显存问题
- W14 NSA(本文):解决 attention 计算量问题
两者合起来让 DeepSeek 的长上下文 LLM 在 trillion-param 规模上仍然经济可用——这是 V3.2 和 V4 系列旗舰得以发布的工程基础设施。
下一篇 W15 我们详解 DeepSeekMath-V2(arXiv:2511.07823),这是 DeepSeek 推理主线在 R1 之后的延续——把”答案验证”扩展到”推理过程验证”,提出 Self-Verifiable Reasoning 方法论,让模型可以自主判断自己的推理是否正确。这是从 R1 的”outcome-based RL”向”process-based RL”的演进,也是 reasoning 模型走向真正可信赖的关键一步。
参考资料
- Yuan et al., Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, arXiv:2502.11089, 2025. ACL 2025 Best Paper.
- NSA Triton implementation (community):
- Beltagy et al., Longformer: The Long-Document Transformer, arXiv:2004.05150, 2020.
- Zaheer et al., Big Bird: Transformers for Longer Sequences, arXiv:2007.14062, 2020.
- Tang et al., Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference, arXiv:2406.10774, 2024.
- Li et al., SnapKV: LLM Knows What You are Looking for Before Generation, arXiv:2404.14469, 2024.
- Lu et al., MoBA: Mixture of Block Attention for Long-Context LLMs, arXiv:2502.13189, 2025.
- Dao et al., FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, arXiv:2205.14135, 2022.
- DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, arXiv:2405.04434, 2024.
- Optimizing Native Sparse Attention with Latent Attention and Local Global Alternating Strategies, arXiv:2511.00819, 2025.
![]()
2026-05-17 at 6:14 下午
gating 是 sample-level(每个 token 一组 g_c/g_s/g_w)。但不同 attention head 的功能差异很大(有的 head 管局部、有的管长程),用一组 token 级 gate 把三分支输出对所有 head 统一加权,会不会太粗?