
转载本文请注明出处:https://yudonglee.me/deepseek-coder-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 2 月,2026 年 6 月有修订,补充了与系列后续论文的呼应。
本文是 DeepSeek 论文专题系列的第 3 篇,详解 DeepSeek 公司 2024 年 1 月发表的 DeepSeek-Coder: When the Large Language Model Meets Programming — The Rise of Code Intelligence (arXiv:2401.14196)。这篇论文不像 DeepSeekMoE 那样提出新架构,但在训练数据组织方式上做了一项关键转换——从 file-level 训练升级到 repo-level 训练,配合 Fill-in-the-Middle (FIM) 双模目标和 16K 长上下文,让 1.3B / 6.7B / 33B 三档代码模型在发布时即位列开源 SOTA。其中 6.7B 模型已经追平 CodeLlama-34B,33B-Instruct 在 HumanEval 上超过 GPT-3.5-turbo。这篇论文也是 DeepSeek 系列里代码主线的起点,后续 Coder-V2、V3 内置 coding 能力、V4 的 agentic coding,都以此为根。
一、为什么 DeepSeek 要把代码模型单独成线
W1 序言里我们把 DeepSeek 的 30+ 篇论文归为四条主线,第三条就是 代码(Code)主线:

为什么不把 coding 直接放进通用 LLM 训练?两个原因:
- 数据组织方式不同——自然语言文本的最大单位是文档/书章,而代码的最大语义单位是 repository(项目仓库)。一个函数的语义往往依赖同 repo 内其他文件定义的类、接口、常量。file-level 训练相当于把每个文件当独立文档处理,模型看不到跨文件的依赖。
- 数据配比不同——代码数据稀疏(GitHub 高质量代码远少于 CommonCrawl 的文本),且语种极度长尾(Python、Java、JavaScript 占大头,Rust、Solidity 等小语种数据极少)。通用 LLM 的 6:1 文本:代码混合解决不了小语种 coverage 的问题。
DeepSeek-Coder 给出的解法是:单独训练专门的代码模型,从数据采集起就以 repo 为基本单位。这条思路后来在 Coder-V2 里被进一步放大(涵盖 338 种编程语言),并在 V3 的 coding 能力建设中得到延续。
具体地看,DeepSeek-Coder 相对 CodeLlama(Meta, 2023-08)、StarCoder(BigCode, 2023-05)这两个同期开源代码模型贡献了什么?三点核心创新:
- Repo-level training with topological dependency sort:在一个 repo 内部按文件之间的 import/include 依赖做拓扑排序,再把整个 repo 拼成一条长序列训练
- FIM 双模混合(50% PSM + NTP):在标准 next-token prediction 之外,加入 Prefix-Suffix-Middle / Suffix-Prefix-Middle 两种 FIM 模式,50% 配比让模型同时具备代码补全与中段填空能力
- 16K 长上下文扩展:在 base model 之上再用 200B tokens 把 RoPE base 调整后做长上下文继续预训练,覆盖整个文件甚至小型 repo
下面我们按论文顺序展开。
二、模型家族与发布节点
DeepSeek-Coder V1 提供三档参数规模,每档都有 Base 与 Instruct 两个版本:
| 规模 | Layers | d_model | n_heads | 训练 tokens |
|---|---|---|---|---|
| DeepSeek-Coder 1.3B | 24 | 2048 | 16 | 2T |
| DeepSeek-Coder 6.7B | 32 | 4096 | 32 | 2T |
| DeepSeek-Coder 33B | 62 | 7168 | 56 | 2T |
所有模型采用与 DeepSeek LLM 相同的 Transformer 骨架:Pre-norm + RMSNorm + SwiGLU + RoPE + GQA(33B 模型采用 GQA,1.3B 与 6.7B 采用 MHA)。架构本身没有引入新的组件——这是有意为之,DeepSeek-Coder 把所有研究火力都投到了数据与训练目标上。
数据 pipeline 上,DeepSeek-Coder 训练语料包含 87 种编程语言、2T tokens,构成上是 87% 代码 + 13% 自然语言(中英双语),完全从零训练(不像 CodeLlama 是从 LLaMA-2 继续预训练)。
从零训练 vs 继续预训练:CodeLlama 选择从 LLaMA-2 起点做 500B tokens 代码继续预训练,DeepSeek-Coder 选择从零训练 2T tokens。后者数据量大约 4 倍、计算成本也高约 4 倍,但好处是 tokenizer、数据配比、长上下文从一开始就为代码优化。两条路线后来被 V2 / V3 系列同时印证:通用 LLM 内置 coding 走”继续训练”路线,专门代码模型走”从零训练”路线。
三、数据创新:Repo-Level 训练
3.1 file-level 训练的局限
绝大多数早期代码模型(CodeGen、Codex、StarCoder 等)都采用 file-level training:把每个源代码文件视为独立样本,截断到固定上下文窗口(通常 2K-4K)后送入训练。
这种做法的根本问题是:真实编程任务很少在单文件内闭合。一个 Python 工程通常有 models.py、utils.py、config.py、api/views.py 等多个文件,写 views.py 时几乎一定要 import models.py 里定义的类。file-level 训练让模型看不到这种跨文件依赖,结果是:
- 模型生成的代码经常 hallucinate 不存在的接口
- 给出的 import 路径与实际 repo 结构不符
- 在多文件协作 benchmark(如 CrossCodeEval、RepoBench)上表现远低于单文件 benchmark
3.2 DeepSeek-Coder 的解法:repo-level + 拓扑排序
DeepSeek-Coder 的数据 pipeline 完整流程是:
- 以 repo 为单位采集:从 GitHub 拉取整个 repository,而非散文件
- 依赖图构建:解析每个文件的 import / include / require 语句,识别同 repo 内其他文件的引用关系,构建 directed dependency graph
- 拓扑排序:在依赖图上做拓扑排序,保证被依赖的文件排在依赖它的文件之前
- 拼接成长序列:按拓扑顺序把所有文件拼成一条长序列,每个文件之间用特殊分隔符(路径标识)隔开
- 长上下文截断:用 16K 上下文窗口截断(很多小到中等 repo 可以完整放入一个样本)
伪代码示意:
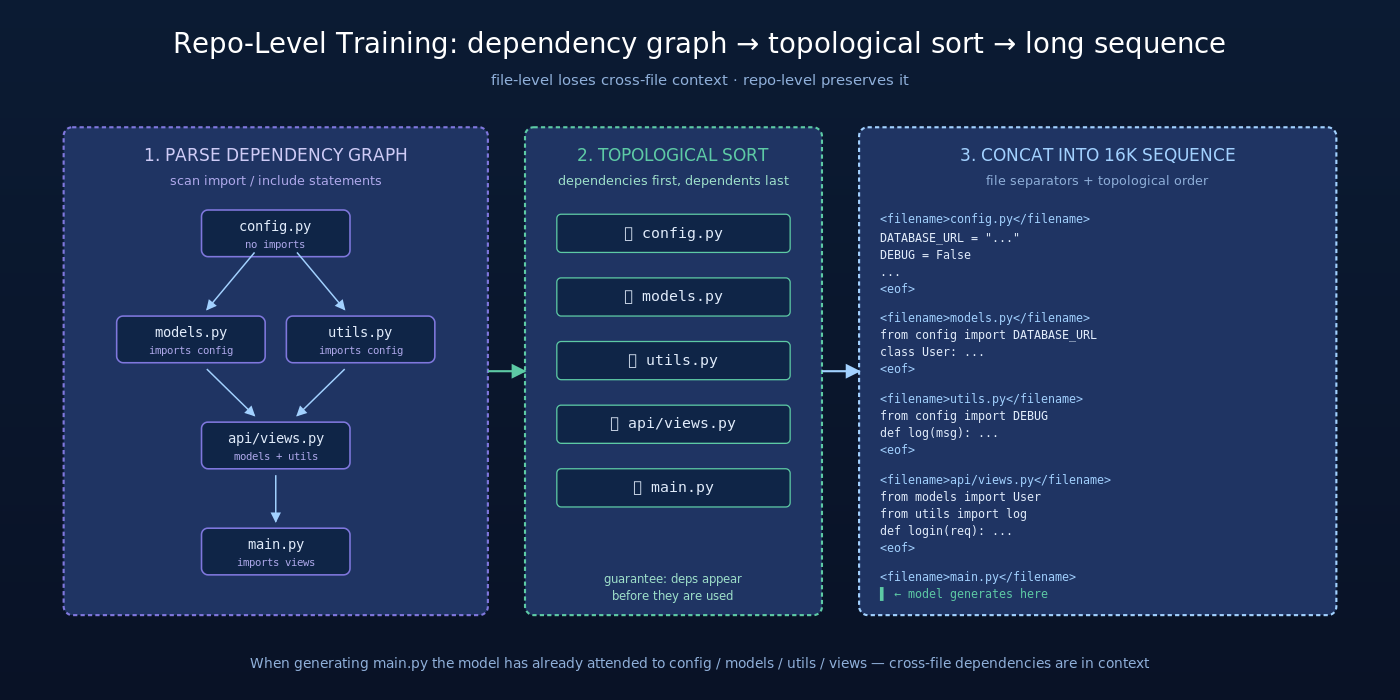
这样做的好处是:
- 模型在生成
views.py时,真的看过models.py的内容(因为拓扑排序保证models.py在views.py之前) - 跨文件的类型、函数签名、常量定义都进入了 attention 范围
- 在 repo-level benchmark(CrossCodeEval、RepoBench)上获得显著提升
论文里展示的消融实验:用 1B 模型做对照,repo-level 训练相对 file-level 训练,HumanEval 提升 6.7%(30.5% → 37.2%),MBPP 提升 9.4%(44.6% → 54.0%)。注意 HumanEval 和 MBPP 都是单文件 benchmark,repo-level 训练能带来这样的提升说明它不只对跨文件场景有效——长上下文里积累的”周边知识”对单文件生成也有正向贡献。
3.3 一个工程上的细节:解析 87 种语言的依赖
要做拓扑排序,必须先能解析每种语言的依赖语法。Python 有 import、Java 有 import、C/C++ 有 #include、Rust 有 use、Go 有 import……每种语言的语法不同,路径解析规则也不同(相对路径、模块路径、package 别名)。
DeepSeek-Coder 论文里没有给出 87 种语言的具体解析规则,但工程上这是一个相当重的实现——需要为每种语言写一套依赖提取器。这也是为什么”repo-level 训练”听起来简单,但同期 CodeLlama / StarCoder 都没有完整做出来的原因。这部分工程红利最终转化为模型能力上的优势。
四、训练目标:FIM 双模混合
4.1 为什么需要 FIM
标准 next-token prediction (NTP) 只训练模型”看到前缀,预测下一个 token”,但实际编程任务里非常常见的是中段填空:
模型不仅看到了前缀(函数签名 + base case),还看到了后缀(return 之后的部分上下文,可能是测试或调用)。光靠 NTP 训练的模型无法直接利用后缀信息。
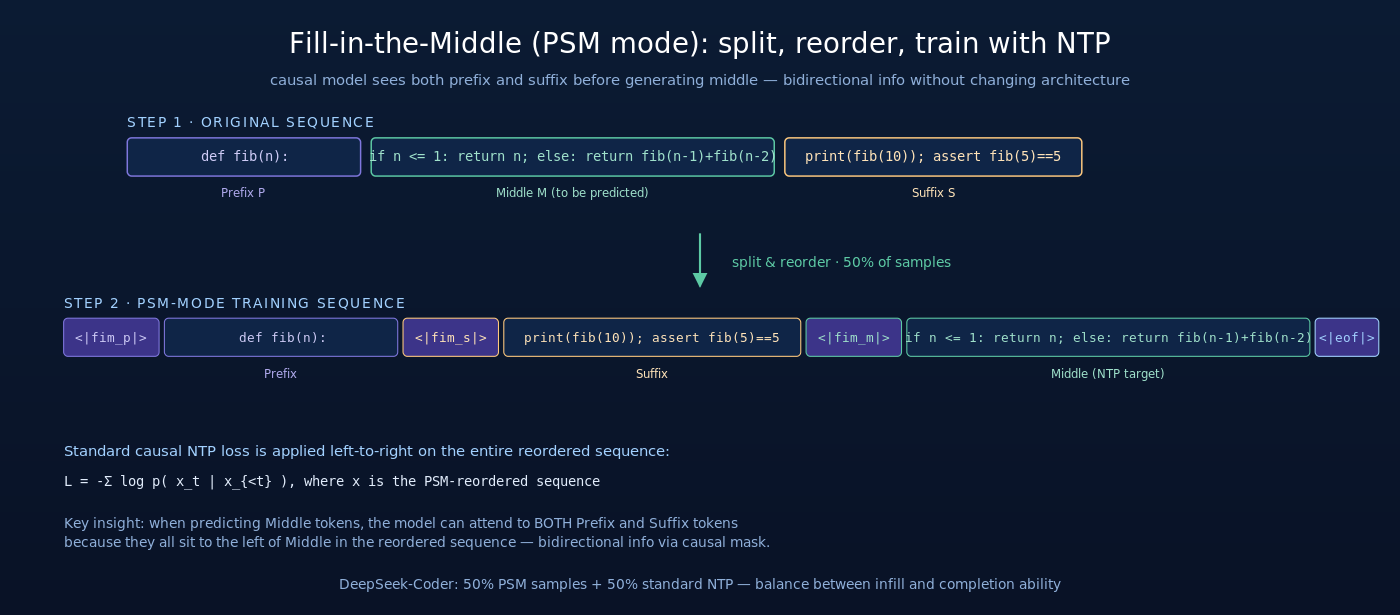
Fill-in-the-Middle (FIM) 是 OpenAI 在 2022 年提出的训练技巧(Bavarian et al., 2022):把一段连续 token 序列切成三段 prefix / middle / suffix,重新排列后训练模型预测 middle。
4.2 PSM 与 SPM 两种模式
DeepSeek-Coder 实现了 FIM 的两种排列:
- PSM (Prefix-Suffix-Middle):训练时把序列重排为
<fim_prefix> Prefix <fim_suffix> Suffix <fim_middle> Middle <fim_end>,模型从左到右预测,看到 prefix 和 suffix 后生成 middle - SPM (Suffix-Prefix-Middle):把 suffix 放在 prefix 之前
数学上,对一段原始 token 序列  ,随机选两个切点
,随机选两个切点  ,则:
,则:
- Prefix:

- Middle:

- Suffix:

PSM 模式下训练样本为:
![[\text{fim\_prefix}], P, [\text{fim\_suffix}], S, [\text{fim\_middle}], M, [\text{fim\_end}]](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-1784d39c98f184659aa5a6062e2cf38a_l3.png "Rendered by QuickLaTeX.com")
模型仍然做标准的 left-to-right next-token prediction,但因为 prefix 和 suffix 都在 middle 之前,模型在生成 middle 的每个 token 时可以同时利用两侧上下文。
4.3 50% FIM + 50% NTP 的配比选择
DeepSeek-Coder 的训练配比是:50% 样本走 FIM (PSM 模式)、50% 走标准 NTP。这个比例来自消融实验——100% FIM 会让模型在标准 code completion 上退化(因为它习惯了”看到后缀”才能预测),50/50 配比在 FIM 任务和补全任务之间取得平衡。
后来 V2-Coder 沿用了类似配比,业界(CodeLlama-7B、StarCoder)也基本收敛到 50% 这个值。
NTP 与 FIM 的本质区别:NTP 是 causal——模型只能看到左侧上下文;FIM 是 bidirectional-aware——通过 token 重排把”未来上下文”塞到当前位置之前,让 causal 模型间接获得双向信息。这是用最低成本(不改架构)达到了 BERT 类双向模型的部分能力。
五、长上下文:16K 训练 + RoPE base 调整
DeepSeek LLM 的默认上下文是 4K,但代码任务普遍需要更长的窗口(一个完整文件经常超 4K,repo-level 序列更是动辄上万 token)。
DeepSeek-Coder 用两步把上下文扩到 16K:
- Base 阶段(2T tokens):直接用 16K 窗口训练,但 RoPE 的 base 参数从 LLaMA 默认的 10000 调大,对应 NTK-aware 位置插值的思路——base 越大,RoPE 频率谱越拉长,模型在更长距离上仍能维持相对位置信号
- 继续预训练阶段(200B tokens):在 16K 窗口上再做 200B tokens 的继续预训练,专门强化长上下文场景
理论上 RoPE base 调整后模型能外推到 64K,但论文里给出的”可靠工作区间”是 16K——再长会出现性能下降。这与 LLaMA-2 长上下文论文的观察一致:位置编码外推的上限通常远小于理论值,实际产品上线一般取 1/3 到 1/2 的理论上限。
六、Instruct 阶段:2B tokens 的指令微调
Base 阶段结束后,DeepSeek-Coder 用 2B tokens 的指令数据对 Base 模型做 SFT(监督微调)得到 Instruct 版本。指令数据涵盖:
- 代码生成(自然语言描述 → 代码)
- 代码补全(部分代码 + 注释 → 完整代码)
- 代码解释(代码 → 自然语言解释)
- Bug 修复(错误代码 + 报错 → 修复代码)
- 代码翻译(语言 A 的代码 → 语言 B 的代码)
- 多轮对话(迭代式修改)
指令格式遵循 Alpaca-style:
这里 SFT 的细节比较常规,论文没有专门展开。真正决定 Instruct 模型质量的还是 Base 模型——好的 Base + 标准 SFT = 好的 Instruct,反过来不成立。
七、评测结果:开源 SOTA 与跨 size 比较
7.1 HumanEval 与 MBPP
HumanEval 与 MBPP 是当时最常用的两个 Python 函数级 benchmark。DeepSeek-Coder-Base 的成绩(论文表 5):
| 模型 | HumanEval (Python) | MBPP |
|---|---|---|
| StarCoder-15B | 33.6% | 43.3% |
| CodeLlama-7B | 33.5% | 41.4% |
| CodeLlama-13B | 36.0% | 47.0% |
| CodeLlama-34B | 42.4% | 55.2% |
| DeepSeek-Coder-1.3B | 34.8% | 46.2% |
| DeepSeek-Coder-6.7B | 49.4% | 60.6% |
| DeepSeek-Coder-33B | 56.1% | 66.0% |
关键观察:
- DeepSeek-Coder-6.7B (49.4%) 已经超过 CodeLlama-34B (42.4%)——这是这篇 paper 最有冲击力的结果。同期 7B 量级的开源模型,前一个 SOTA 是 CodeLlama-7B 33.5%,DeepSeek-Coder 直接把 6.7B 拉到了 4.94 倍参数模型的水位线之上
- DeepSeek-Coder-1.3B (34.8%) 已经追平 CodeLlama-7B (33.5%)——5.4 倍参数差距被抹平
- DeepSeek-Coder-33B (56.1%) 超过 CodeLlama-34B (42.4%) 13.7 个百分点——同等参数规模下的代际差
7.2 多语言:HumanEval Multilingual 与 DS-1000
HumanEval-Multilingual 把 HumanEval 翻译到 Python、Java、JavaScript、C++、TypeScript、PHP、Bash 等 7 种语言。DeepSeek-Coder-33B 平均 50.3%,CodeLlama-34B 41.0%——领先 9.3 个百分点。
DS-1000(数据科学场景,pandas、numpy、scipy 等库的真实使用):DeepSeek-Coder-33B 40.2%,CodeLlama-34B 34.3%——领先 5.9 个百分点。
7.3 LeetCode Contest(防止数据污染的关键测试)
HumanEval 和 MBPP 已经发布多年,存在被预训练数据”污染”的风险(模型可能在训练集里见过题目+答案)。DeepSeek-Coder 团队额外构建了 LeetCode Contest 评测集——2023 年 7 月之后(即所有训练数据截止之后)的 LeetCode 周赛题目。结果:
- DeepSeek-Coder-33B-Instruct:27.8%
- GPT-3.5-Turbo:19.4%
- GPT-4:48.1%
这个结果说明:DeepSeek-Coder-33B-Instruct 已经超过 GPT-3.5-Turbo,但与 GPT-4 仍有较大差距。这个相对位置在 2024 年初是非常强的开源代码模型水位。
7.4 数学与通用能力:13% 自然语言数据的红利
虽然 DeepSeek-Coder 是代码模型,但 13% 自然语言(含中英双语)数据让它在通用任务上表现也不弱:
- MMLU:DeepSeek-Coder-33B 41.6%(CodeLlama-34B 29.4%)
- GSM8K:DeepSeek-Coder-33B 60.7%(CodeLlama-34B 30.3%)
- C-Eval:DeepSeek-Coder-33B 40.2%(CodeLlama-34B 7.0%)
这点很重要——很多代码模型为了专注于代码完全放弃自然语言能力,结果是用户必须维护”代码模型 + 通用模型”两套系统。DeepSeek-Coder 保留 13% 自然语言数据后,一个模型同时是不错的代码生成器和合格的双语对话助手。这种”代码主、通用兼”的数据配比后来被 Coder-V2 沿用。
八、与同期对手的差异:为什么 DeepSeek-Coder 跑得快
把 DeepSeek-Coder 与同期三个主要竞品对比:
| 维度 | CodeLlama (Meta) | StarCoder (BigCode) | WizardCoder | DeepSeek-Coder |
|---|---|---|---|---|
| 训练起点 | LLaMA-2 继续预训练 | 从零训练 | CodeLlama + Evol-Instruct | 从零训练 |
| 训练 tokens | 500B(继续) | 1T | – | 2T |
| 数据组织 | file-level | file-level | file-level | repo-level + 拓扑排序 |
| 训练目标 | NTP + 部分 FIM | NTP + FIM | NTP(SFT-only) | NTP + 50% FIM (PSM/SPM) |
| 上下文 | 16K | 8K | – | 16K (RoPE base 调整) |
| 语言数 | 主流几种 | 86 | – | 87 |
| HumanEval-34B 同档(Python) | 42.4% | – | – | 56.1% |
可以看到 DeepSeek-Coder 的领先不是来自某个单点突破,而是来自数据组织、训练目标、训练量三方面的同时优化。这是 DeepSeek 团队从 LLM 时代就形成的工程哲学——单点优化容易被追平,组合优化才能拉开代际差。后续 V2 / V3 / R1 都体现了这种”多点并进”的研究风格。
HumanEval 高分与”好用的代码模型”之间隔着什么
需要给上面的评测优势泼一点冷水:HumanEval/MBPP 体系与真实工程场景的相关性是有限的。它们测的是”函数级、自包含、题面清晰”的代码生成——而真实开发中的高频任务是跨文件理解、在已有代码上改动、调试报错,这些维度后来 SWE-bench 一出来就让所有在 HumanEval 上接近饱和的模型现了原形。另外,公开 benchmark 的数据污染问题在代码领域尤其严重(LeetCode 风格题解在 GitHub 上无处不在),同期各家模型分数的可比性要打折扣。
有意思的是,以这个标准回看,DeepSeek-Coder 真正被低估的卖点反而不是 HumanEval 分数,而是 repo-level 训练 + FIM 双模混合这两个数据层设计——它们针对的恰恰是”跨文件依赖”和”在光标处补全”这两个 IDE 产品的核心场景。补全产品的体验由三件事决定:FIM 质量、首 token 延迟、上下文组装策略,其中只有第一件与论文 benchmark 有关。这也解释了为什么 6.7B 这个 size 在当时的开源补全生态里被大量采用:它是”FIM 训练充分 + 延迟可接受”交集里的最优解,而不是榜单上分数最高的那个。
九、局限与衔接 Coder-V2
DeepSeek-Coder V1 是一个非常强的开源代码模型,但仍有几个明显局限:
- Dense 架构限制规模:33B Dense 推理成本比同等能力的 MoE 高得多。半年后发布的 Coder-V2 直接换成 MoE 架构(236B 总参 / 21B 激活),HumanEval 进一步提升到 90%+ 水位
- 语言数量仍偏少:87 种语言看起来不少,但实际 GitHub 上活跃的编程语言(包括 DSL、配置语言)有 300+。Coder-V2 扩到 338 种语言
- 缺少数学推理专项训练:虽然 GSM8K 60.7% 不算差,但与 DeepSeekMath / R1 这类专门的推理模型差距明显
- 指令数据偏少(2B tokens):相比同期 WizardCoder 用了大量合成数据,DeepSeek-Coder 的 Instruct 阶段比较克制——这也解释了为什么 Base 与 Instruct 差距不像 WizardCoder 那么大
- 没有 RLHF 阶段:直接 SFT 后即发布,没有 reward modeling + PPO/DPO。这个能力后来在 R1 系列里专门补足
Coder-V2 在 V1 基础上的关键改动(W 系列后续会专门展开)
| 维度 | V1 | V2 |
|---|---|---|
| 架构 | Dense (33B 上限) | MoE (236B / 21B 激活) |
| 训练 tokens | 2T | 6T |
| 编程语言数 | 87 | 338 |
| 上下文 | 16K | 128K |
| 数学推理 | 60.7% (GSM8K) | 90%+ (借助 DeepSeekMath 数据) |
可以看到 Coder-V2 是把 V1 的所有维度都放大一个量级——这是 DeepSeek 一贯的”V2 是 V1 升级版”节奏(DeepSeek LLM → DeepSeek-V2、DeepSeek-VL → DeepSeek-VL2 也都是同样的形态)。
写在最后
DeepSeek-Coder V1 是 DeepSeek 系列里最不”花哨”但工程含量最高的一篇 paper:
- 没有新架构(与 DeepSeek LLM 同骨架)
- 没有新损失函数(NTP + FIM 都是现成的)
- 没有新硬件优化
但它把三件已有的事做到了极致:repo-level 数据组织、FIM 双模训练、长上下文 + RoPE 调整。结果是一个 6.7B 的模型在最关键的 HumanEval / MBPP 上超过对手的 34B 模型,33B 模型在 LeetCode Contest 上超过 GPT-3.5-Turbo。
这种”用工程组合拳跑赢架构创新”的研究路线,是 DeepSeek 系列后来反复验证的方法论——V3 的 FP8、DualPipe 训练优化、R1 的 GRPO + Cold-Start,本质都是这类多点工程优化的成果。
下一篇 W5 我们详解 DeepSeekMath(arXiv:2402.03300),这是 DeepSeek 第一篇专门的推理模型论文,提出了影响整个行业的 GRPO 算法,并为后来的 R1 与 OpenAI o1 系列定下了 RL-for-reasoning 的范式。
参考资料
- Guo et al., DeepSeek-Coder: When the Large Language Model Meets Programming — The Rise of Code Intelligence, arXiv:2401.14196, 2024.
- DeepSeek-Coder GitHub repository:
- Bavarian et al., Efficient Training of Language Models to Fill in the Middle, arXiv:2207.14255, 2022.
- Rozière et al., Code Llama: Open Foundation Models for Code, arXiv:2308.12950, 2023.
- Li et al., StarCoder: may the source be with you!, arXiv:2305.06161, 2023.
- Luo et al., WizardCoder: Empowering Code Large Language Models with Evol-Instruct, arXiv:2306.08568, 2023.
- DeepSeek-AI, DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence, arXiv:2406.11931, 2024.
- Chen et al., Evaluating Large Language Models Trained on Code (HumanEval), arXiv:2107.03374, 2021.
![]()
2026-02-17 at 9:54 上午
“33B 在 LeetCode Contest 超 GPT-3.5″这个对比,GPT-3.5 在 2024 年初已经是相对老的模型了,拿它当主要对标对象,赢面本来就大。