
转载本文请注明出处:https://yudonglee.me/deepseekmath-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 2 月,后随系列连载持续修订,最近一次更新于 2026 年 6 月。
本文是 DeepSeek 论文专题系列的第 4 篇,详解 DeepSeek 公司 2024 年 2 月发表的 DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (arXiv:2402.03300)。这是一篇里程碑式的论文——它不仅把开源数学推理模型推到 GSM8K 88.2% / MATH 51.7%(接近 GPT-4 当时水位)的 7B 模型,更重要的是首次提出了 GRPO (Group Relative Policy Optimization) 算法:移除 PPO 中的 value model (critic)、改用组内归一化估计 advantage。GRPO 后来成为 DeepSeek-R1、Qwen-QwQ、Kimi-K0 等所有主流开源 reasoning 模型的标准训练算法,可以说定义了 2024-2026 年开源 reasoning model 的 RL 训练范式。除了 GRPO 之外,本文还会展开论文的另一项核心贡献——用 fastText 迭代分类器从 Common Crawl 挖出 120B tokens 高质量数学语料,这套数据 pipeline 后来也被多家公司复刻。
一、为什么 Math 是 DeepSeek 系列的关键分支
W1 序言里我们把 DeepSeek 的论文分为四条主线,第二条是推理(Reasoning)主线:

这条线在国际社区影响力最大——R1 直接定义了”开源 reasoning model”的工程范式,把 OpenAI o1 拉到平民价位。而 R1 的所有方法论根源都在 DeepSeekMath 这篇 paper 里。
为什么 DeepSeek 把数学单独立项?两个原因:
- 数学是 reasoning 的最佳代理任务:数学题有客观答案(可以用规则判断对错),不需要主观人类标注 reward;同时数学题有可验证的中间步骤,可以做 step-level analysis。这种”答案可自动验证”的特性让 RL training 不依赖昂贵的 reward model
- 数学能力的可迁移性强:早期 DeepSeek-LLM、DeepSeek-Coder 都发现,提高模型的数学推理能力会顺带提高它在代码、逻辑、长链推理等任务上的表现。把数学作为单点突破,回收的能力是全局性的
具体地看,相对同期 Llemma (Princeton)、InternLM-Math、WizardMath 三个数学专项模型,DeepSeekMath 真正贡献了什么?三点核心:
- 120B tokens 高质量数学语料:用 fastText 迭代分类器从 Common Crawl 挖出 35.5M 数学网页、120B tokens——这是当时最大规模的开源数学预训练语料
- GRPO 算法:去掉 PPO 的 critic 网络,改用组内 reward 归一化估计 advantage,节省 ~50% 训练显存
- 三阶段训练管线:math pretraining → math instruction tuning → math RL with GRPO——后来被 R1 直接沿用并放大
下面按论文顺序展开。
二、模型概览与初始化选择
DeepSeekMath 提供三个 7B 模型变体:
| 模型 | 训练方式 | 核心用途 |
|---|---|---|
| DeepSeekMath-Base | DeepSeek-Coder-Base v1.5 7B + 500B tokens 继续预训练(其中 120B 为数学语料) | 数学 base model |
| DeepSeekMath-Instruct | Base + SFT(780K 指令样本,含 CoT 与 Tool-Integrated Reasoning) | 数学指令模型 |
| DeepSeekMath-RL | Instruct + GRPO RL(仅 144K 数学 prompt) | 数学 RL 模型 |
一个有意思的设计选择:DeepSeekMath-Base 不是从 DeepSeek-LLM 初始化,而是从 DeepSeek-Coder-Base v1.5 7B 初始化。
这与”code pretraining 帮助 reasoning”的直觉相符——代码本身有强语法结构、强逻辑链、强符号操作,对数学推理是天然适配的预训练任务。论文的消融实验确认:从 Coder-Base 起点训练,比从 DeepSeek-LLM 7B Base 起点训练,最终 MATH benchmark 高 6-8 个百分点。
这个发现后来被 V2 / V3 反复利用——V3 在通用 LLM 训练里也专门安排了一定比例的 code data 来增强 reasoning。
架构上,DeepSeekMath-Base 完全沿用 DeepSeek-Coder-Base v1.5 的 7B 配置:32 层、4096 dim、32 head、SwiGLU、RoPE、4K context。论文没有引入任何新的架构组件——所有创新都集中在数据 pipeline 和 RL 算法上。
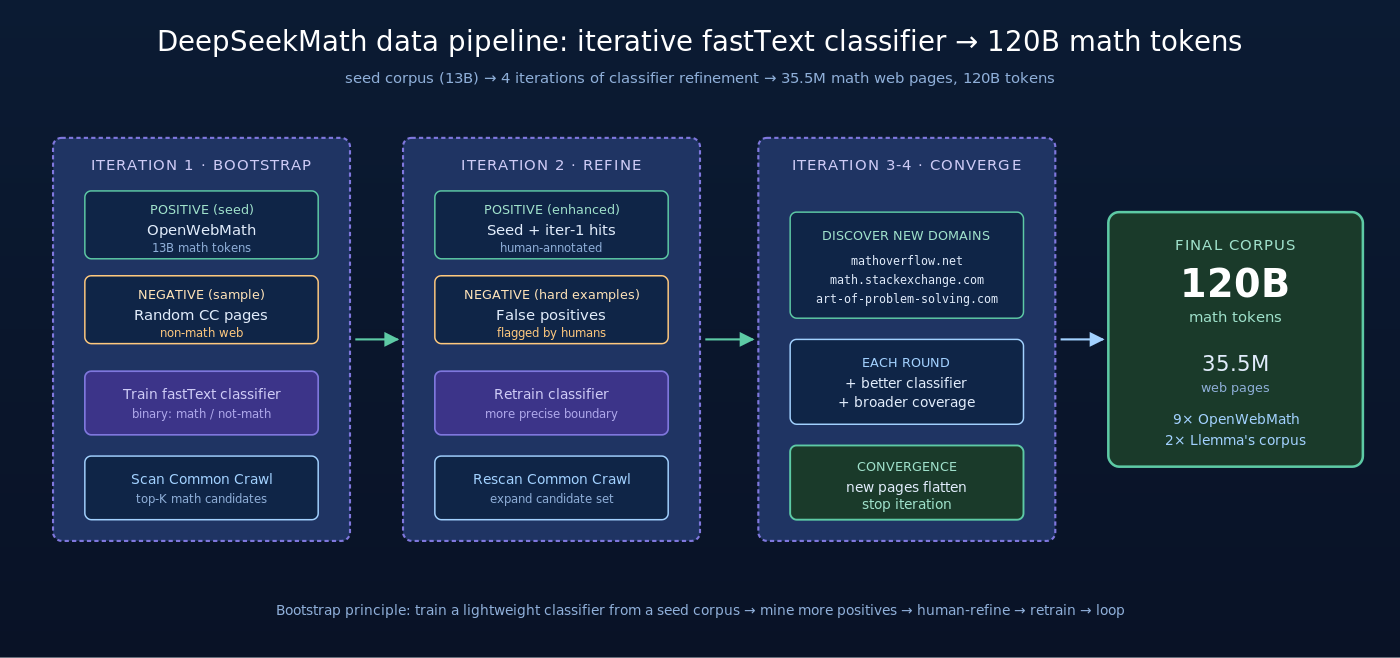
三、数据 pipeline:fastText 迭代分类器挖出 120B 数学语料
3.1 起点:OpenWebMath 与 Common Crawl 的取舍
数学预训练语料的核心矛盾是质量 vs 规模:
- 高质量数学语料(arXiv、教科书、MathOverflow)很干净,但总量小(10-30B tokens)
- Common Crawl 总量大(10T+ tokens),但数学含量稀疏(<0.5%)
之前的开源数学模型(Llemma、InternLM-Math)主要走”高质量小规模”路线。DeepSeekMath 的选择是反向——从 Common Crawl 中精细挖掘,最终拿到 120B tokens,比 Llemma 的 55B 高一倍以上。
3.2 fastText 迭代分类器流程
整个 pipeline 是四轮迭代:
第一轮:
- 正样本:OpenWebMath(13B tokens 高质量数学网页,由社区维护)
- 负样本:从 Common Crawl 随机采样的非数学网页
- 训练 fastText 二分类器(极轻量,单机分钟级训练完成)
- 用分类器在 Common Crawl 上打分,取 top-K 数学网页
第二轮起:
- 对上一轮挖出的数学网页做人工标注,剔除假阳性
- 用增强后的正样本重新训练 fastText 分类器
- 再次扫描 Common Crawl,取更精准的 top-K
- 重复
每轮迭代都会:
– 扩大正样本规模(覆盖更广的数学领域)
– 减少假阳性(分类器变得更挑剔)
– 发现新的数学密集域名(论文里特别提到 mathoverflow.net、math.stackexchange.com 等)
四轮迭代后,最终从 40B 网页中选出 35.5M 数学网页,对应 120B tokens——这是 OpenWebMath 的 9 倍多。
3.3 这套 pipeline 为什么重要
DeepSeekMath 的数据 pipeline 本身就是一个独立贡献。后续多家公司(包括 Microsoft 的 Phi 系列、Qwen-Math)都复刻了类似的思路:
核心方法论:用一个轻量分类器(fastText、small LM)从大规模文本中迭代挖掘高质量子集,每一轮迭代用上一轮产出 + 人工反馈训练更精准的分类器。这是一种用计算换数据质量的 bootstrap 范式,特别适合”领域稀疏但海量”的场景。
后来 R1 的训练数据扩展也用了类似的思路——只是把分类器目标换成了”reasoning 密集网页”而不是”数学网页”。可以说 DeepSeekMath 的数据 pipeline 是 DeepSeek 数据团队的第一次实战。
四、Base 阶段:500B tokens 数学继续预训练
DeepSeekMath-Base 7B 在 DeepSeek-Coder-Base v1.5 7B 之上继续预训练 500B tokens,配比是:
- 56% 数学网页(从上面的 120B 数学语料中采样)
- 20% 代码(保留 Coder 的代码能力,避免遗忘)
- 10% arXiv 论文
- 10% 数学相关教科书与考试题
- 4% 自然语言
注意几个细节:
- 数学网页虽然只占 56%,但因为采样比例较高、训练 epoch 较多,实际计算贡献接近 70%
- 保留 20% 代码是关键——消融实验显示,完全去掉代码会让 reasoning 能力显著下降
- 50K vocab 不变(不专门为数学符号扩展 tokenizer)——好处是不需要重新训练 embedding,坏处是数学符号 token 效率不高
Base 阶段训练完成后的 benchmark(5-shot 或 4-shot, no CoT prompting):
| Benchmark | DeepSeekMath-Base 7B | Llemma 7B | Llemma 34B |
|---|---|---|---|
| GSM8K | 64.2% | 36.4% | 51.5% |
| MATH | 36.2% | 18.0% | 25.0% |
| MMLU-STEM | 56.5% | 49.0% | 53.9% |
可以看到 DeepSeekMath-Base 7B 不仅大幅领先同等规模的 Llemma 7B,还超过了 Llemma 34B。这是 120B 高质量数学语料 + Coder 初始化双重红利的结果。
五、Instruct 阶段:CoT + Tool-Integrated Reasoning
Instruct 阶段用 780K 数学指令样本对 Base 做 SFT。这里指令数据有两种格式:
- Chain-of-Thought (CoT):自然语言一步步推理,最后给出答案
- Tool-Integrated Reasoning (TIR):在 CoT 中插入 Python 代码片段,模型可以”调用”代码计算器来辅助数值运算
CoT vs TIR 是数学推理的两种风格:
- CoT 的好处是端到端可读,输出就是给人看的解题过程
- TIR 的好处是精确计算,对涉及大数运算、矩阵操作的题目精度更高
DeepSeekMath-Instruct 同时支持两种模式(通过 prompt 切换)。SFT 后的成绩:
| Benchmark | Instruct CoT | Instruct TIR |
|---|---|---|
| GSM8K | 82.9% | 83.7% |
| MATH | 46.8% | 57.4% |
TIR 在 MATH 上比 CoT 高 10.6 个百分点——这是因为 MATH 题目包含大量代数化简、积分、概率计算等需要符号运算的步骤,调用 Python 直接算比让模型”心算”靠谱得多。
CoT vs TIR 的本质差异:CoT 是把”工具”内化到模型权重里(模型必须自己学会算 23×47),TIR 是把”工具”外化到环境里(模型只需学会”什么时候该调用工具”)。前者考验模型对数值的内部表示,后者考验模型的工具使用决策。这个分野在后来的 agentic LLM、code interpreter 等方向得到了充分发展。
六、RL 阶段:GRPO 算法详解(核心创新)
DeepSeekMath 最有影响力的贡献是 GRPO (Group Relative Policy Optimization) 算法。下面我们系统对比 PPO 和 GRPO。
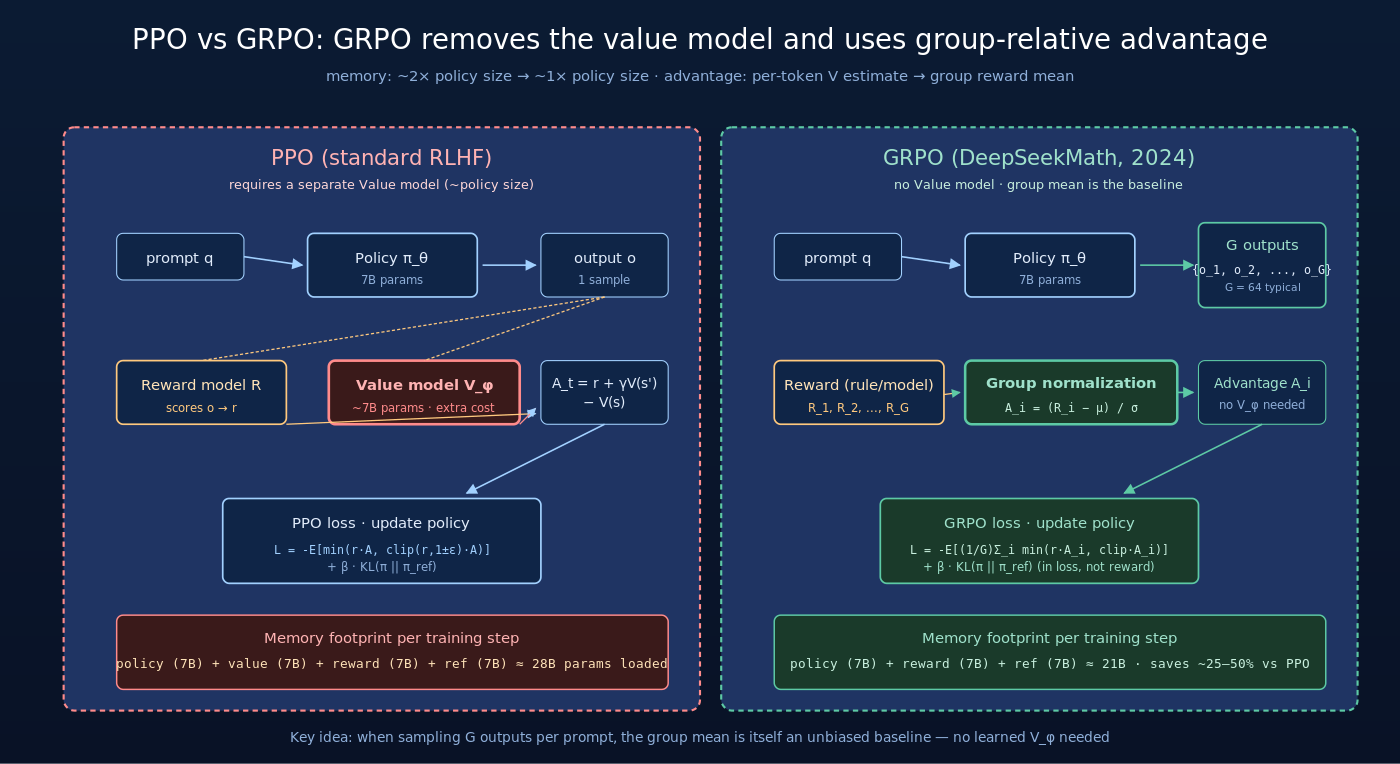
6.1 PPO 的标准做法
PPO 是 RLHF 的标准算法。对于一个 prompt  ,PPO 流程:
,PPO 流程:
- 用当前策略
 采样一个输出
采样一个输出 
- 用 reward model
 给 打分得到 reward
给 打分得到 reward 
- 用 value model
 估计每个 token 的预期未来回报
估计每个 token 的预期未来回报 
- 用 GAE 计算 advantage

- 用 clipped surrogate loss 更新
核心 PPO loss:
![\mathcal{L}_{\text{PPO}} = -\mathbb{E}\left[\min\left(r_t(\theta) A_t,\; \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t\right)\right] + \beta \cdot \text{KL}[\pi_\theta \| \pi_{\text{ref}}]](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-cf7858208602e214dc9d59cf44161c48_l3.png "Rendered by QuickLaTeX.com")
其中  是重要性比率。
是重要性比率。
PPO 的关键问题:value model 和 policy model 同等大小(通常都是 7B+),训练时显存占用至少翻倍。这对大模型 RL 训练是非常重的负担。
6.2 GRPO 的核心改动:去掉 critic
GRPO 观察到一个简单的事实:
如果对同一个 prompt 采样多个输出
,那么这一组的 reward 平均值天然就是一个无偏 baseline,根本不需要 value model 来估计。
具体流程:
- 对 prompt ,用当前策略采样 G 个输出(典型 G=64)
- 对每个输出
 计算 reward
计算 reward  (这里 reward 可以是基于规则的——比如数学题答案对不对)
(这里 reward 可以是基于规则的——比如数学题答案对不对) - 组内归一化 advantage:

- 用 clipped surrogate loss 更新策略
GRPO loss:
![\mathcal{L}_{\text{GRPO}} = -\mathbb{E}\left[\frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min\left(r_{i,t} A_i,\; \text{clip}(r_{i,t}, 1-\epsilon, 1+\epsilon) A_i\right)\right] + \beta \cdot \text{KL}[\pi_\theta \| \pi_{\text{ref}}]](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-85a9c20bf23cf00d67932cac69f66f3e_l3.png "Rendered by QuickLaTeX.com")
注意几个细节:
- 每个输出 内的所有 token 共享同一个 advantage
 ——这是 outcome-supervised 的简化(trajectory-level reward)
——这是 outcome-supervised 的简化(trajectory-level reward) - 没有 value model ——节省约 50% 训练显存
- KL 项直接加到 loss 里(而非像 PPO 那样作为 reward 的 penalty)——这是 GRPO 与 PPO 的另一个微妙差异
6.3 GRPO 相对 PPO 的优劣
GRPO 的优势:
- 显存节省 ~50%:去掉 value model 后,能在同等显存预算下训练更大的 policy model
- 实现更简单:没有 value model 需要单独训练、维护、对齐
- 天然适配 outcome reward:组内 reward 归一化对”答案对/错”这类稀疏 outcome reward 非常友好
- batch 效率高:因为对每个 prompt 采样 G 个输出,可以高效并行 rollout
GRPO 的代价:
- 不能利用 step-level reward:每个输出内的所有 token 共享一个 advantage,无法精细到 token-level reward
- G 越大越好但越贵:典型 G=64,rollout 成本是 PPO 的 64 倍(虽然不需要 value model 训练)
- 对稀疏 reward 敏感:如果整组 reward 都是 0(全错)或都是 1(全对),advantage 归一化失效
6.4 GRPO 在 DeepSeekMath 上的效果
仅用 144K 数学 prompt 做 GRPO(这是非常少的 RL 数据量),DeepSeekMath-RL 7B 相对 Instruct 的提升:
| Benchmark | Instruct CoT | RL (GRPO) | 提升 |
|---|---|---|---|
| GSM8K | 82.9% | 88.2% | +5.3 |
| MATH | 46.8% | 51.7% | +4.9 |
| 匈牙利国家奥数 | 30.0% | 35.0% | +5.0 |
注意”匈牙利国家奥数”是 out-of-domain 测试集——RL 训练数据里没有任何 Hungarian 题目,但 GRPO 训练让模型在 Hungarian 上也提升了 5 个百分点。这说明 GRPO 不是简单的”在训练集上过拟合”,而是真的提升了 reasoning 通用能力。
6.5 GRPO 对后续工作的影响
GRPO 提出后,几乎所有主流开源 reasoning 模型都采用了它:
- DeepSeek-R1-Zero (2025-01):纯 GRPO RL,跳过 SFT 直接训练 reasoning 能力
- DeepSeek-R1 (2025-01):GRPO + Cold-Start + 多阶段 RL
- Qwen-QwQ-32B (2025-02):基于 GRPO 的开源 reasoning
- Kimi-K0 (2025-03):GRPO 变体
- Yi-Reasoning (2025):GRPO
后来出现的 GRPO 变体(DAPO、GSPO 等)都是在 GRPO 框架内做局部改进,没有改变”去 critic + 组内归一化”这一核心范式。这就是为什么我们说 GRPO 定义了 2024-2026 年的开源 reasoning RL 范式。
补丁清单:GRPO 公式里后来被社区修掉的几处偏差
需要提醒一句:6.2 节那条 loss 公式并不是定论。R1 引爆大规模复现之后,社区在 GRPO 的原始形式里找出了至少两处系统性偏差,读完本节应该立刻补上这份「补丁清单」:
- length bias:公式里 1/|o_i| 的序列内归一化,让长回答的每个 token 分到的梯度更小——对负 advantage 的回答,写得越长惩罚被稀释得越厉害,客观上鼓励模型「错得啰嗦」。Dr. GRPO(Liu et al., 2025)指出并移除了这一项,同时去掉了组内 std 归一化——后者会放大「全对或全错边缘」题目的权重,引入 difficulty bias。
- 组内方差失效:当一组 G 个采样全对或全错时,advantage 全为零,这部分 rollout 算力完全浪费,训练后期尤其严重。DAPO(2025)的 dynamic sampling 直接把这类组过滤掉重采,并引入 clip-higher 解耦上下裁剪边界、缓解熵塌缩,还提出了 token-level 的 loss 聚合来对冲长度问题。
我的判断是:GRPO 的历史地位在「去 critic + 组内 baseline」这个框架,而不在公式细节——细节几乎每一项都被后续工作动过手术。所以读这篇 paper 的正确姿势是连着补丁一起读:GRPO 给框架,Dr. GRPO 修统计偏差,DAPO 修训练动力学。只读原文就照搬公式去训练,等于主动选用了一份 2024 年版本的已知 bug 集合。
七、评测结果:7B 模型逼近 GPT-4 数学水位
DeepSeekMath-RL 7B 在 2024 年 2 月发布时的 benchmark 全景:
| Benchmark | DeepSeekMath-RL 7B | GPT-3.5 | GPT-4 (当时) | Llemma 34B |
|---|---|---|---|---|
| GSM8K (CoT) | 88.2% | 80.8% | 92.0% | 51.5% |
| MATH (CoT) | 51.7% | 34.1% | 52.9% | 25.0% |
| MATH (TIR) | 58.8% | – | – | – |
| Hungarian National Math | 35.0% | 23.3% | 68.0% | – |
关键观察:
- DeepSeekMath-RL 7B 的 MATH 成绩(51.7%)几乎与 GPT-4 当时水平(52.9%)持平——这是 7B vs 万亿级闭源大模型的成绩
- GSM8K 88.2% 已经接近 GPT-4 的 92.0%——同样是 7B vs 万亿级
- 匈牙利国家奥数仍与 GPT-4 有差距——这反映了 7B 模型在真正困难、非套路化的奥数题上的天花板
这是 2024 年 2 月开源数学模型的 SOTA。对照同期 Llemma 34B(25%)就能看出代际差。
八、局限与对 R1 的奠基
DeepSeekMath 是一篇里程碑,但仍有几个明显局限:
- 只覆盖数学一个领域:reasoning 能力没有迁移到代码、长链推理、规划等其他任务
- RL 数据规模小(144K):GRPO 的 sample efficiency 还没有被充分压榨
- 没有 reasoning trace 的精细监督:每个输出只用 outcome reward(答案对错),中间步骤的质量没有被显式优化
- CoT 与 TIR 互不融合:模型在两种模式间切换,没有一个统一的”什么时候该用工具”决策机制
- Cold-start 问题没解决:如果直接对 Base 做 GRPO(不经过 Instruct SFT),训练会非常不稳定甚至发散
这些局限全部被 R1 论文解决:
| 局限 | R1 的解法 |
|---|---|
| 只覆盖数学 | R1 训练数据扩展到代码、逻辑、STEM 多领域 |
| RL 数据小 | R1 用更大规模 RL 数据 + 多轮 reward iteration |
| 缺中间步骤监督 | R1 引入 reasoning 格式监督 + 答案精度 reward 组合 |
| CoT/TIR 分裂 | R1 统一在 long-CoT 框架下,模型自主决定推理深度 |
| Cold-start 不稳 | R1 引入 Cold-Start SFT 阶段稳定 RL 起点 |
可以说R1 是 DeepSeekMath 的”问题清单”的完整解答。这种”先发现问题、再用大模型升级版本解决”的研究节奏,是 DeepSeek 系列一贯的方法论——和 LLM → V2、Coder V1 → V2 是同样的形态。
另外两个间接影响:
- GRPO 的 advantage 归一化催生了一系列变种:DAPO(动态采样)、GSPO(更精细的 token-level 加权)、Dr.GRPO(debias 处理)
- 数据 pipeline 的 fastText 迭代分类器思路被复用到 R1 的 reasoning 数据采集、V3 的 code/math 子集采集中
写在最后
DeepSeekMath 是 DeepSeek 系列里学术影响力最大的一篇 paper。如果说 DeepSeekMoE 定义了 V2 / V3 / V4 的架构骨架,那 DeepSeekMath 就定义了 R1 系列的训练范式。
它做对了三件事:
- 用数据 pipeline 解决”数学数据稀缺”问题:120B tokens 用 fastText 迭代分类器从 CC 中挖出,比之前的开源数学语料大一个量级
- 用 GRPO 解决”PPO 显存爆炸”问题:去 critic + 组内归一化,把大模型 RL 训练成本降低近 50%
- 用三阶段管线(math pretraining → SFT → RL)建立 reasoning training 标准流程:这套流程后来被 R1 直接复用并放大
这三件事的影响远超数学领域——后续整个开源 reasoning model 浪潮都建立在它的方法论之上。从 R1-Zero 的”纯 RL”实验,到 R1 的”Cold-Start + 多阶段 RL”,再到 2025-2026 年的各种 reasoning 模型,GRPO 始终是默认选项。
下一篇 W6 我们详解 DeepSeek-VL 系列(V1 + V2 合篇),看 DeepSeek 是如何把通用 LLM 的能力扩展到视觉理解领域,以及 hybrid vision encoder、dynamic tiling 这些设计为多模态预训练带来的工程红利。
参考资料
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, arXiv:2402.03300, 2024.
- DeepSeek-Math GitHub repository:
- Schulman et al., Proximal Policy Optimization Algorithms, arXiv:1707.06347, 2017.
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv:2501.12948, 2025.
- Azerbayev et al., Llemma: An Open Language Model For Mathematics, arXiv:2310.10631, 2023.
- Paster et al., OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text, arXiv:2310.06786, 2023.
- Joulin et al., Bag of Tricks for Efficient Text Classification (fastText), arXiv:1607.01759, 2016.
- Ahmadian et al., Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs (RLOO), arXiv:2402.14740, 2024.
![]()
2026-03-02 at 6:50 下午
建议把”GRPO 变种谱系”单独画一张图——GRPO → DAPO(动态采样解决全错组)→ GSPO(token-level 加权)→ Dr.GRPO(去 std bias)