
转载本文请注明出处:https://yudonglee.me/deepseek-vl-explained/ | 作者:yudonglee
📝 首发于 2026 年 2 月。2026-06 修订:更新了系列导航与后续模型的关联内容。
本文是 DeepSeek 论文专题系列的第 5 篇,详解 DeepSeek 公司 2024 年 3 月发表的 DeepSeek-VL: Towards Real-World Vision-Language Understanding (arXiv:2403.05525)。这是 DeepSeek 多模态主线的开篇之作,提出了三个互相支撑的设计:(1) Hybrid Vision Encoder——SigLIP-L 与 SAM-B 并行编码,用低分辨率 384×384 抓全局语义、用高分辨率 1024×1024 抓细节像素;(2) Real-world 数据策略——专门覆盖网页截图、PDF、OCR、图表、知识类内容,而非局限于学术 benchmark;(3) 保 LLM 能力的三阶段训练 pipeline——通过精细的数据配比与模块解冻顺序,防止视觉训练破坏语言能力。论文同时发布 7B 与 1.3B 两个版本,在 MMBench、MMMU、GQA 等多模态 benchmark 上取得同尺寸开源 SOTA,且在 MMLU、HumanEval 等语言任务上几乎不退化。这个设计在 2024-12 的 VL2 中被进一步升级到 MoE 架构 + Dynamic Tiling。
一、为什么 VL 是 DeepSeek 系列的独立主线
W1 序言里我们把 DeepSeek 的论文分为四条主线,第四条是多模态(Multimodal)主线:

为什么 DeepSeek 把多模态单独立项,而不像 GPT-4 或 Gemini 那样直接把视觉能力塞进通用 LLM?两个原因:
- 视觉与语言的训练动力学不一样:视觉模态需要的预训练数据量、batch size、学习率与语言模态都不同;如果直接混在一起 joint training,常见结果是”视觉学得不够,语言反而退化”。这是同期 LLaVA、Qwen-VL、InternVL 共同遭遇的问题
- Real-world 多模态场景的数据形态特殊:用户实际把图像扔给模型的场景,超过 60% 是 OCR、屏幕截图、文档、图表——这些场景需要模型同时具备高分辨率细节识别与强语言推理能力。学术 benchmark(VQA、COCO Caption)覆盖不到这些 use case
DeepSeek-VL 给出的解法是:专门设计一个多模态模型,从架构、数据、训练 pipeline 三个层面同时为 real-world 场景优化。这条思路后来在 VL2(MoE 化、Dynamic Tiling)、Janus(统一理解与生成)里持续放大。
具体地看,DeepSeek-VL 相对同期 LLaVA-1.5(Haotian Liu 等,2023-10)、Qwen-VL(Alibaba,2023-08)、InternVL-1.0(Shanghai AI Lab,2023-12)这三个开源多模态模型贡献了什么?三点核心创新:
- Hybrid Vision Encoder:双视觉编码器并行(SigLIP-L 384×384 + SAM-B 1024×1024),在不显著增加计算成本的前提下同时获取全局语义与局部细节
- Real-world data taxonomy:基于真实用户使用场景设计指令数据,专门强化 OCR、PDF、屏幕截图、图表理解这类高频痛点
- 三阶段训练 + LLM warm-up:在 VL pretraining 中维持 50%+ 文本数据比例,防止语言能力退化
下面按论文顺序展开。
二、模型概览与初始化选择
DeepSeek-VL 提供两档参数规模:
| 模型 | LLM Backbone | Vision Encoder | 总参数 | 主要用途 |
|---|---|---|---|---|
| DeepSeek-VL-1.3B | DeepSeek LLM 1.3B Base | SigLIP-L + SAM-B | ~1.8B | 端侧、轻量场景 |
| DeepSeek-VL-7B | DeepSeek LLM 7B Base | SigLIP-L + SAM-B | ~7.5B | 主力模型 |
每个规模又分 Base 版(用于继续训练)与 Chat 版(用于直接对话)。
注意 backbone 初始化的选择——DeepSeek-VL 从 DeepSeek LLM Base 起点初始化,不是从 Coder-Base 或 Math-Base。这跟 DeepSeekMath 选择 Coder-Base 起点形成对比:
- Math 选择 Coder-Base:代码训练 → 数学推理迁移
- VL 选择 LLM Base:视觉理解需要的是通用语言能力与常识推理,而不是代码或数学特化能力
这种”按 backbone 能力匹配下游模态”的设计判断,是 DeepSeek 系列在 V2/V3 之前就形成的方法论。
架构上,LLM 部分完全沿用 DeepSeek LLM 的 Transformer 配置(Pre-norm、RMSNorm、SwiGLU、RoPE、GQA),没有引入任何架构改动。所有创新都集中在视觉编码器与连接策略上。
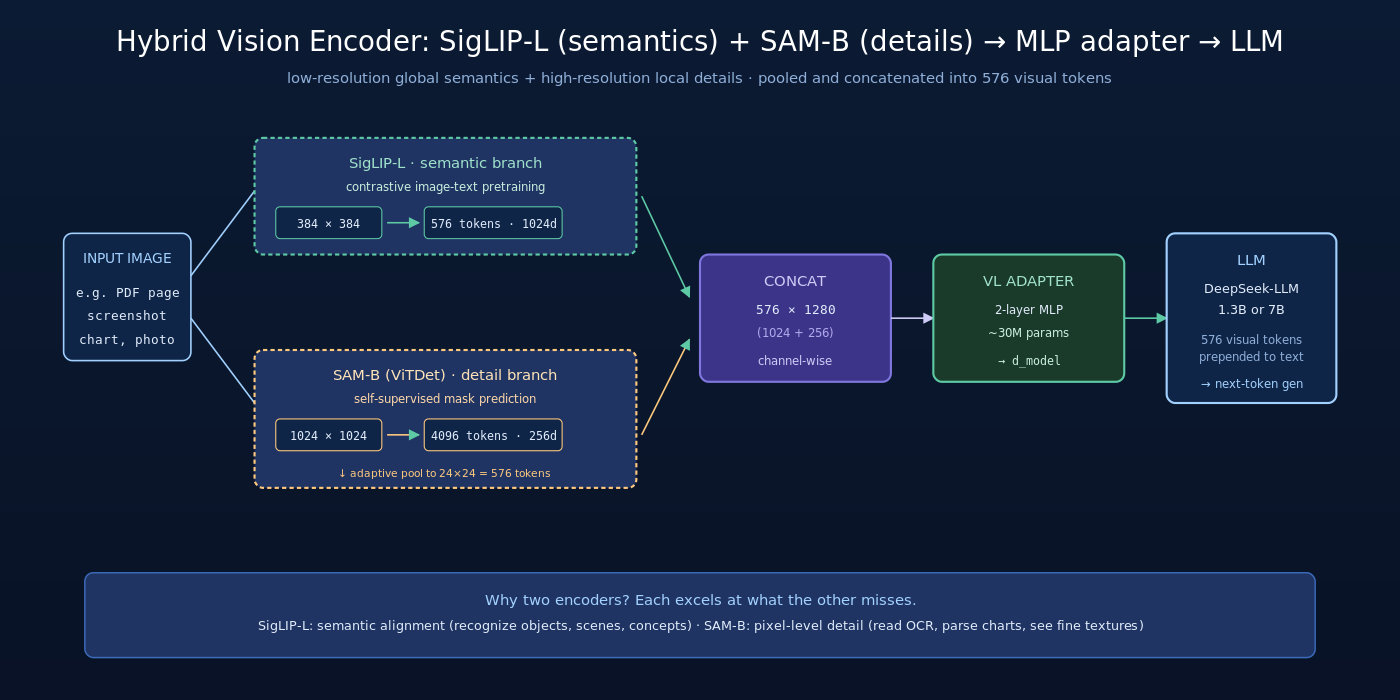
三、核心创新一:Hybrid Vision Encoder
3.1 单视觉编码器的两难
主流视觉编码器(CLIP、SigLIP、ViT)的输入分辨率通常是 224×224 或 336×336,最高到 384×384。原因是 ViT 的计算成本随 patch 数二次增长——512×512 输入用 14×14 patch 就有 1369 个 token,attention 复杂度  ,已经接近主流 LLM 上下文窗口的总 token 数。
,已经接近主流 LLM 上下文窗口的总 token 数。
这带来一个核心矛盾:
- 低分辨率(384×384)足以捕捉全局语义(”这是一只猫”、”画面中有 5 个人”)
- 但 real-world 场景普遍需要高分辨率细节(OCR 文字、图表小标签、UI 按钮、表格单元格)
同期方案分两派:
- LLaVA-1.5 派:用单个 CLIP-336 编码器,分辨率上限到 336×336 — 简单但细节差
- Qwen-VL 派:用 448×448 输入 + 位置编码插值 — 略提升但触顶后会失真
DeepSeek-VL 的解法是两个编码器并行,各自承担擅长的工作。
3.2 Hybrid Vision Encoder 架构
DeepSeek-VL 的视觉编码器结构:
| 编码器 | 输入分辨率 | 训练目标 | 擅长 |
|---|---|---|---|
| SigLIP-L | 384 × 384 | Image-text contrastive (sigmoid loss) | 全局语义、跨模态对齐 |
| SAM-B (ViTDet backbone) | 1024 × 1024 | Self-supervised mask prediction (SAM 预训练) | 高分辨率细节、局部纹理 |
两个编码器对同一张图像并行编码:
- SigLIP-L 输出
 个 patch token(24×24,每 patch 16×16 像素),每个 token 维度 1024
个 patch token(24×24,每 patch 16×16 像素),每个 token 维度 1024 - SAM-B 输出
 个 patch token(64×64),每个 token 维度 256
个 patch token(64×64),每个 token 维度 256 - 对 SAM-B 输出做 adaptive pooling 到 24×24 = 576 token,与 SigLIP-L 输出对齐
- 两路在 channel 维度 concat → 形成 576 × (1024+256) = 576 × 1280 的视觉特征
- 通过两层 MLP Vision-Language Adaptor 投影到 LLM 的 embedding 维度
最终图像被编码为 576 个 visual token,直接拼接到文本 token 序列前送入 LLM。
3.3 为什么不同损失函数训练的编码器可以这样合并
一个直觉性的担心是:SigLIP-L 用 contrastive 损失训练(追求语义对齐),SAM-B 用 mask prediction 训练(追求像素恢复),两者的特征空间几何完全不同。直接 concat 后送入 MLP 不会冲突吗?
答案是:Vision-Language Adaptor 在训练中学会处理这种差异。具体地:
- SigLIP-L 输出的特征在”语义判别”维度上更结构化
- SAM-B 输出的特征在”位置/纹理/细节”维度上更结构化
- MLP adapter 把这两组特征线性变换到一个统一的 LLM-friendly 子空间
实际效果:
- SigLIP-L 贡献的 token 帮助 LLM “认出图里有什么”
- SAM-B 贡献的 token 帮助 LLM “看清细节、读清文字”
这种”语义编码器 + 细节编码器”的双流设计后来被多家工作复用(如 InternVL-1.5、MiniCPM-V)。
3.4 计算成本分析
读者会担心两个编码器是否让推理成本翻倍。实际不会:
- SigLIP-L 用 384×384 输入,patch 数 576,attention 是

- SAM-B 用 1024×1024 输入但 patch 数 4096,attention 是
 ——这是大头
——这是大头 - 但 SAM-B 是纯前向、参数仅 90M,远小于 LLM
- 总体上 vision encoder 计算成本占整个 forward 的 5-15%,没有质变
更重要的是,SAM-B 与 SigLIP-L 在训练时常常被冻结(见下面三阶段),实际的训练显存占用与单编码器方案相当。
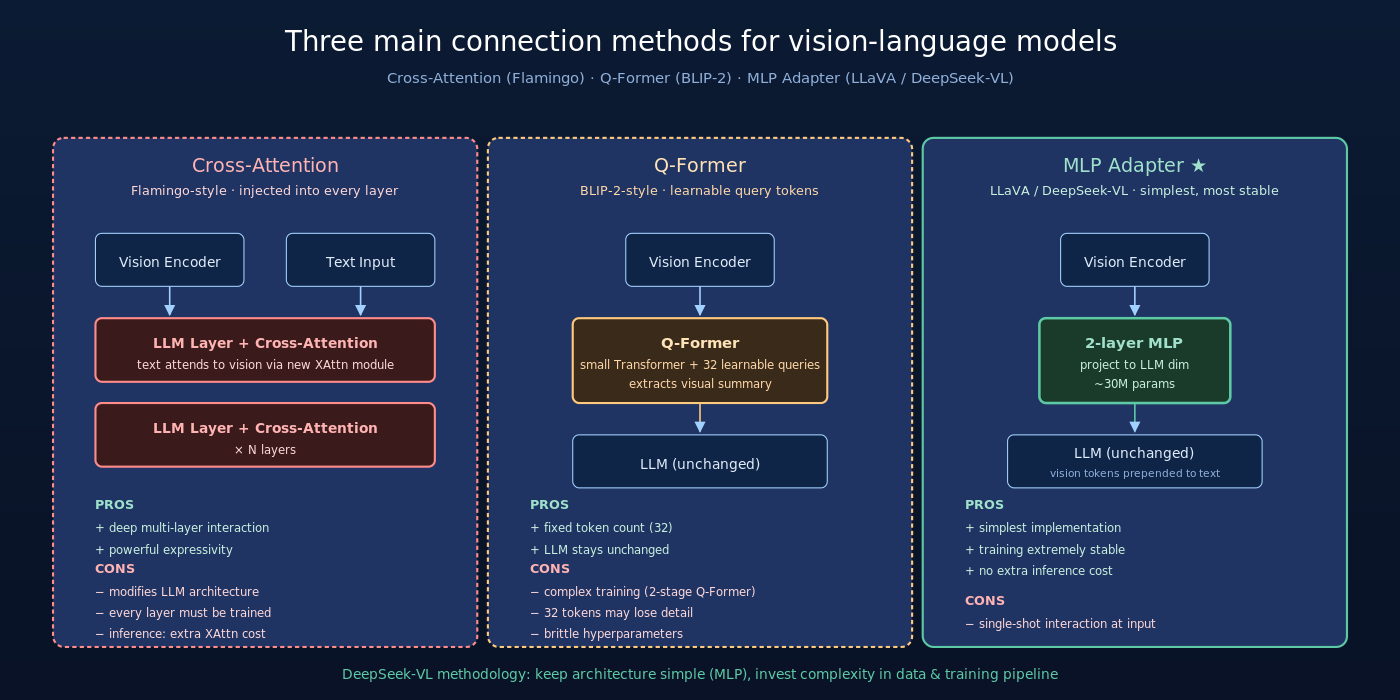
四、核心创新二:Vision-Language Adapter 与三种主流连接方式
多模态模型把视觉特征接入 LLM 的方式有三派主流方案,DeepSeek-VL 选择了其中最简单的一种(MLP adapter),但效果反而最稳定。下面对比三种方案。
4.1 三种主流连接方式
方案 A:Cross-Attention(Flamingo-style)
视觉特征不直接进入 token 序列,而是通过额外的 cross-attention 层在 LLM 每一层做”视觉-语言交互”。LLM 自身保持 unchanged,cross-attention 是新加的。
- 优点:理论上信息混合更深
- 缺点:需要修改 LLM 架构、训练时所有 cross-attention 层都要更新、推理时引入额外计算
方案 B:Q-Former(BLIP-2-style)
用一个小 Transformer 模块作为”视觉-语言桥梁”,输入视觉特征,输出固定数量的 query token(如 32 个)。query token 当作”视觉摘要” prepended 到文本前。
- 优点:可学习的 query 提取视觉摘要、token 数固定
- 缺点:Q-Former 本身需要专门设计、训练复杂
方案 C:MLP Adapter(LLaVA-style / DeepSeek-VL 选择)
最朴素的方案:视觉特征通过 2-3 层 MLP 投影到 LLM embedding 维度,然后直接当 token 拼到文本前。LLM 不做任何架构修改。
- 优点:实现简单、训练稳定、推理无额外开销
- 缺点:信息只在序列起点交互一次,理论表达力较弱
4.2 DeepSeek-VL 为什么选 MLP Adapter
论文里没有专门列消融实验,但选择 MLP adapter 与 DeepSeek-VL 的整体方法论一致:
方法论原则:在架构上保守,在数据和训练 pipeline 上激进。
具体到 VL:
- 架构保守:MLP adapter 是已验证的简单方案,把所有不确定性集中到训练 pipeline 与数据策略上
- 训练激进:通过精细的三阶段训练(下一节展开)保 LLM 能力、稳视觉学习
- 数据激进:通过 real-world data taxonomy 强化下游 user experience
实际效果证明,MLP adapter 的”理论缺陷”在足够数据 + 精细训练下并不构成 bottleneck。这与同期 LLaVA-1.5 的发现一致——简单架构 + 大数据通常胜过复杂架构 + 小数据。
五、核心创新三:三阶段训练 + LLM 能力保持
DeepSeek-VL 的训练 pipeline 分为三个阶段,每个阶段的可训练模块、数据配比、学习率都不同:
5.1 Stage 1: Vision-Language Adapter 单独训练
目标:让 adapter 学会把视觉特征映射到 LLM 能理解的 embedding 空间,不动 LLM 本身。
- 可训练:只有 Vision-Language Adapter(两层 MLP,~30M 参数)
- 冻结:SigLIP-L、SAM-B、LLM
- 数据:1.27M 图文对(图像 caption pair)
- 学习率:相对较高,因为只有 MLP 需要学
这一阶段非常轻量,1.5 天内完成。
为什么必须有 Stage 1:如果跳过这一步直接训练 LLM,视觉特征会以”随机噪声”的形式进入 LLM,强迫 LLM 同时学习”如何理解视觉信号”和”如何完成下游任务”——双重负担会让 LLM 现有能力大幅退化。Stage 1 相当于先给 LLM 一个”翻译好的视觉信号”再做联合训练。
5.2 Stage 2: Joint Vision-Language Pretraining
目标:在保 LLM 语言能力的前提下,让模型真正”看懂”视觉。
- 可训练:Vision-Language Adapter + LLM
- 冻结:SigLIP-L、SAM-B
- 数据配比:70% 视觉-语言数据 + 30% 纯文本——这是 DeepSeek-VL 与其他方案的关键差异
- 训练 tokens:约 400B
70/30 配比的设计:同期 LLaVA-1.5 / Qwen-VL 在 Stage 2 几乎全部用 VL 数据(≤10% 纯文本),结果是模型 MMLU、HumanEval 等语言任务普遍掉 5-15 个百分点。DeepSeek-VL 把纯文本拉到 30%,让 LLM “持续被语言任务复习”,最终在 MMLU 上几乎不掉点。
论文的消融实验(仅 1.3B 模型)显示:
| 配比 | VL 平均成绩 | MMLU |
|---|---|---|
| 100% VL 数据 | 63.2 | 31.5(基线 41.8 → −10.3) |
| 70% VL + 30% 文本 | 62.1 | 41.5(仅 −0.3) |
| 50% VL + 50% 文本 | 58.7 | 41.7 |
可以看到 70/30 配比是”VL 损失最小 + 语言能力几乎不退化”的甜点。
5.3 Stage 3: Supervised Fine-Tuning(Instruct 阶段)
目标:基于真实用户使用场景做指令微调,让模型适应实际对话与任务。
- 可训练:SigLIP-L + Vision-Language Adapter + LLM
- 冻结:SAM-B(因为 SAM-B 处理高分辨率细节,对 instruct 任务足够稳定)
- 数据:根据真实用户场景设计的指令数据(taxonomy 见下一节)
- 训练 tokens:约 1B(远小于 Stage 2)
为什么 SigLIP-L 在 Stage 3 才解冻?因为 SigLIP-L 已经用大规模 image-text pair 训练过,pretrained 表征基本对齐 LLM 需求;只在 instruct 阶段做轻微 fine-tune 让它适应 user 的 prompt 分布即可。提前解冻会破坏 SigLIP-L 的语义表征。
这三个阶段的设计精度很高——可训练模块、冻结模块、数据配比都经过仔细的消融实验确定。这是 DeepSeek 团队”工程精细化”风格的典型体现。
六、核心创新四:Real-World Data Taxonomy
6.1 学术 benchmark 与真实使用的差距
主流多模态 benchmark(VQAv2、COCO Caption、GQA)的题目分布与真实用户使用差距很大:
- 学术 benchmark 偏好:自然场景图(人、动物、物体)+ 简单语义问答(”图里有什么”、”颜色是什么”)
- 真实用户偏好:屏幕截图、PDF 截图、表格、图表、手写文字、白板、Slide
前者只需”识别物体”,后者需要”识别+读字+解析结构”。早期多模态模型在学术 benchmark 上得分很高,但用户把屏幕截图扔进去就立刻露馅。
6.2 DeepSeek-VL 的 use case taxonomy
DeepSeek-VL 团队从真实用户使用日志中提炼出 use case taxonomy,覆盖六大类:
- Recognition:识别图中物体、场景、人物
- Conversion:图 → 文本(OCR、表格转 markdown、公式转 LaTeX)
- Analytical Reasoning:图表分析、统计图解读、数据可视化理解
- Logical Reasoning:数学题图、几何题图
- Textbook:教科书插图、知识类内容
- Multilingual:多语言 OCR、多语言文档
针对每一类,团队手动收集或合成对应的指令样本,确保 instruct 数据集对真实使用场景有足够覆盖。最终 SFT 数据集中:
- Recognition / Conversion 占 ~40%(覆盖 OCR 与文档场景)
- Analytical / Logical Reasoning 占 ~30%(覆盖图表与推理)
- Textbook / Multilingual 占 ~20%(覆盖知识与多语言)
- 通用对话 占 ~10%
这种”从真实用户日志反推训练数据”的做法是 DeepSeek-VL 的方法论核心,也是论文标题 “Towards Real-World Vision-Language Understanding” 的具体落点。
6.3 这种数据策略为什么重要
对比 LLaVA-1.5 的训练数据(主要来自 COCO、Visual Genome 等学术 dataset),DeepSeek-VL 的数据更接近 real-world 分布。结果是:
- 在 OCR-heavy benchmark(DocVQA、ChartQA)上 DeepSeek-VL-7B 显著领先 LLaVA-1.5-7B
- 在自然场景 benchmark(GQA、VQAv2)上两者接近,但 DeepSeek-VL 没有为了提升这类 benchmark 牺牲其他能力
这是”数据组织匹配下游使用”的工程红利,与 Coder V1 的 “repo-level training” 是同一种思路在不同模态上的应用。
七、评测结果
DeepSeek-VL-7B 在 2024-03 发布时的 benchmark 全景(与同期同尺寸开源模型对比):
| Benchmark | DeepSeek-VL-7B | LLaVA-1.5-7B | Qwen-VL-Chat-7B | InternVL-1.0-7B |
|---|---|---|---|---|
| MMBench (en) | 73.2 | 64.3 | 60.6 | 64.2 |
| MMMU | 36.6 | 35.3 | 35.9 | 32.2 |
| GQA | 61.9 | 62.0 | 57.5 | 60.9 |
| POPE | 88.1 | 85.9 | – | – |
| DocVQA | 49.6 | 8.5 | 65.1 | – |
| ChartQA | 48.0 | 17.8 | 49.8 | – |
| HumanEval (语言任务) | 40.2 | 26.8 | 33.5 | – |
| MMLU (语言任务) | 49.5 | 32.5 | 40.0 | – |
关键观察:
- 多模态 benchmark 上 DeepSeek-VL-7B 全面领先 LLaVA-1.5-7B——尤其 DocVQA(49.6 vs 8.5)说明 hybrid encoder + real-world data 的策略对 OCR 类任务效果显著
- 语言任务上 DeepSeek-VL-7B 比 LLaVA-1.5-7B 高 15-20 个百分点——这是 Stage 2 用 70/30 配比保 LLM 能力的直接结果
- 与 Qwen-VL-Chat-7B 互有胜负:DeepSeek-VL 在 MMBench / MMMU / POPE 上领先,Qwen-VL 在 DocVQA / ChartQA 上略好(因 Qwen-VL 用了更专门的 OCR 训练数据)
整体上 DeepSeek-VL-7B 在 多模态能力与语言能力的 trade-off 上做得是同期最好的——很多 VL 模型为了拉高多模态分数会牺牲语言能力,DeepSeek-VL 几乎没有这种 trade-off。
7.1 与商业模型 GPT-4V 的对比
论文里还做了一个有意思的人工评测:用 100 个 real-world 测试用例,让标注员对比 DeepSeek-VL-7B 与 GPT-4V 的回复质量。结果:
- Recognition / Conversion 任务:DeepSeek-VL 接近 GPT-4V
- Commonsense Reasoning:DeepSeek-VL 接近 GPT-4V
- Complex Reasoning(长链推理、数学题图):GPT-4V 明显领先
这个结果反映了 7B vs 万亿级模型的客观差距——简单视觉理解任务可以追平,但复杂推理任务仍需大模型支撑。这也是后来 VL2 上 MoE 化(让有效参数规模放大)的直接动机。
评测分数之外:一代 VL 在真实文档场景的天花板
对这组评测结果,有两个 benchmark 不会告诉你的边界。第一,分辨率天花板:一代 VL 的 hybrid encoder 高分辨率分支固定在 1024×1024,对海报、UI 截图这类场景够用,但对中文密集文档(小字号、多栏排版、表格套表格)这种 OCR-heavy 场景,固定分辨率意味着小字符在下采样后不可恢复——这是结构性限制,不是训练数据能弥补的。真正解决要等到后续版本引入动态分块(dynamic tiling)路线,把高分辨率图切成多个 tile 分别编码。第二,评测形式偏差:MMBench 这类选择题式 benchmark 对”感知粗粒度正确”很宽容,模型只要大致看对就能选对答案;而真实业务里的 VL 需求(发票字段抽取、图表读数、界面元素定位)要求像素级精确,选择题分数对这类场景的预测力很弱。
所以读这张评测表的正确方式是:它证明了 DeepSeek-VL 在”通用看图说话”维度站上了第一梯队,但如果你的场景是文档智能,一代 VL 与同期 GPT-4V 的真实差距比表格上大,应该直接评估 VL2 之后的版本。
八、局限与衔接 VL2
DeepSeek-VL V1 是一个非常稳定的多模态 7B 模型,但仍有几个明显局限:
- 分辨率上限 1024×1024:对于超高分辨率图像(4K 屏幕截图、A4 全页 PDF)仍需要先缩放,缩放过程中文字会模糊
- Dense 架构限制规模:要进一步提升能力必须线性增加参数,推理成本高
- 统一的 vision encoder:所有图像都走同一个编码 pipeline,无法根据图像内容动态分配计算(自然图像 vs 文档需要不同的编码精度)
- 没有视觉生成能力:模型只能”理解”图像,不能”生成”图像
- 多图理解能力弱:训练数据以单图为主,多图对比、视频理解能力不足
VL2(2024-12,arXiv:2412.10302)针对这些局限做了系统升级:
VL2 在 V1 基础上的关键改动
| 维度 | DeepSeek-VL | DeepSeek-VL2 |
|---|---|---|
| 架构 | Dense 7B | MoE (4.5B / 16B / 27B) |
| LLM Backbone | DeepSeek LLM 7B | DeepSeek-V2 (MLA + DeepSeekMoE) |
| 分辨率 | 固定 384 + 1024 | Dynamic Tiling(任意分辨率) |
| 多图 | 弱 | 原生支持 |
| 数据规模 | ~400B VL tokens | ~800B VL tokens |
VL2 的核心升级是 Dynamic Tiling:把任意分辨率的图像切成多个 tile,每个 tile 分别编码后再拼接。这样既能处理超大图像(理论上无上限),又能保证每个 tile 的精度。这套思路后来被 Qwen-VL2、InternVL-2 大量复用,成为 2025 年开源多模态模型的标准配置。
关于 VL2 的详细架构(特别是从 V1 的 7B Dense 跨越到 27B MoE 这一巨变)我们会在后续单独成文展开,本文不再深入。
视觉生成方向:Janus 系列
DeepSeek 多模态主线在 2024-10 之后还分出了 Janus 分支——专门做”统一视觉理解与生成”,把 understanding 与 generation 解耦到不同的 visual encoder。这条线是另一种思路(生成能力 vs 理解能力的分工),与 VL/VL2 主线互补。Janus 在 W11 我们会专门展开。
写在最后
DeepSeek-VL 是 DeepSeek 系列里首次跨出纯语言领域的论文。它做对的三件事:
- Hybrid Vision Encoder:用工程组合(SigLIP-L + SAM-B)解决了”全局语义 vs 局部细节”的两难,在不显著增加计算的前提下大幅提升 real-world 场景能力
- 70/30 数据配比保 LLM 能力:精细的训练 pipeline 让多模态训练不退化语言能力,避免了同期 LLaVA / Qwen-VL 普遍存在的”VL 能力上、语言能力下”的零和问题
- Real-world data taxonomy:从真实用户日志反推训练数据,让模型在用户最常用的 OCR / 文档 / 图表场景上特别强
这三件事都不是单点突破,而是多个工程决策的组合。这与 DeepSeek 系列其他论文(LLM、Coder、Math)一致的”组合工程压制单点架构创新”风格完全相同——也是 DeepSeek 团队最稳定的方法论标签。
下一篇 W7 我们详解 DeepSeek-V2(arXiv:2405.04434),这是 DeepSeek 通用 LLM 主线上的第一个 MoE 旗舰,引入了著名的 MLA (Multi-head Latent Attention) 注意力机制——把 KV cache 压缩到 1/13,让 236B 总参的模型可以在长上下文推理中保持高 token 吞吐。MLA 是 DeepSeek 后续所有 V 系列模型的标准件,与 DeepSeekMoE 一起构成 V2/V3/V4 的两个支柱。
参考资料
- Lu et al., DeepSeek-VL: Towards Real-World Vision-Language Understanding, arXiv:2403.05525, 2024.
- DeepSeek-VL GitHub repository:
- Wu et al., DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding, arXiv:2412.10302, 2024.
- Zhai et al., Sigmoid Loss for Language Image Pre-Training (SigLIP), arXiv:2303.15343, 2023.
- Kirillov et al., Segment Anything (SAM), arXiv:2304.02643, 2023.
- Liu et al., Improved Baselines with Visual Instruction Tuning (LLaVA-1.5), arXiv:2310.03744, 2023.
- Bai et al., Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond, arXiv:2308.12966, 2023.
- Chen et al., InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, arXiv:2312.14238, 2023.
![]()
2026-03-17 at 6:46 下午
1.3B 上 70/30 是甜点,不代表 7B 上也是——大模型对”灾难性遗忘”的抵抗力通常更强,可能 7B 上 85/15 就够、能学更多 VL。把 1.3B 的最优配比直接用到 7B 是否最优?