
转载本文请注明出处:https://yudonglee.me/deepseekmoe-explained/ | 作者:yudonglee
📝 首发于 2026 年 1 月。2026-06 修订:更新了系列导航与后续模型的关联内容。
本文是 DeepSeek 论文专题系列的第 2 篇,详解 DeepSeek 公司 2024 年 1 月发表的 DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models (arXiv:2401.06066)。这篇论文是 DeepSeek 后续所有 MoE 模型(V2 / V3 / V4 / Coder-V2)的架构起点,提出了两个互相补充的设计:(1) Fine-grained Expert Segmentation——把一个大专家切成 mN 个小专家,让路由组合空间从
暴涨到
;(2) Shared Expert Isolation——保留少量”必经”的共享专家承接共性知识,让 routed expert 专注于差异化模式。两者合起来让一个 2.8B 激活参数的 16B MoE 在多数 benchmark 上追平甚至超越 LLaMA-2 7B,FLOPs 只用了后者约 40%。
一、为什么这篇 paper 是 DeepSeek 系列的”地基”
在《DeepSeek LLM 详解》末尾我们提到,DeepSeek 团队 2024-01-05 发布了第一篇 67B Dense 论文,仅 6 天之后(2024-01-11)就发布了 DeepSeekMoE。这两篇论文是同一时期、同一团队的产物,但研究方向截然不同——Dense 路线和 MoE 路线,DeepSeek 显然在两条路线上同时下注。
事后看,MoE 这条线才是真正主线:
- DeepSeek-V2 (2024-05):用 DeepSeekMoE 设计 + MLA,做出 236B 总参 / 21B 激活的 MoE
- DeepSeek-V3 (2024-12):把 DeepSeekMoE 设计放大到 671B 总参 / 37B 激活,叠加 FP8、MTP、DualPipe
- DeepSeek-V4 (2026-04):1.6T 总参 / 49B 激活,仍以 DeepSeekMoE 的 fine-grained + shared 为底座
- DeepSeek-Coder-V2 (2024-06):把这套设计移植到代码模型
可以说理解后续所有 DeepSeek MoE 模型,都必须先把这篇 paper 读透。它本身的 16B 模型不算大,benchmark 也不是顶尖,但提出的两个设计原则是 DeepSeek 工程哲学最核心的一块。
具体地看,这篇论文相对 GShard、Switch Transformer 等前置 MoE 工作真正贡献了什么?三点:
- fine-grained expert segmentation:在 FLOPs 不变的前提下,把 N 个大专家切成 mN 个小专家、Top-K 也相应放大为 mK,使可激活组合数指数级膨胀
- shared expert isolation:从 mN 个专家里拨出
 个固定为”共享专家”(所有 token 必经),让剩下的 routed expert 专注于差异化知识
个固定为”共享专家”(所有 token 必经),让剩下的 routed expert 专注于差异化知识 - double-axis balance loss:在传统 expert-level balance loss 之外,引入 device-level balance loss,缓解多机训练时单机过载的问题
下面我们先补足 MoE 的基础原理,再按论文顺序展开这三点。
二、前置:标准 MoE 与它的两个失败模式
2.1 MoE 是什么
Mixture-of-Experts (MoE) 是一种把 dense FFN 替换为多个”专家”FFN + 一个路由器(router)的结构。对 Transformer block 来说,原来的 FFN 是:

MoE 把它替换为:

其中  是第
是第  个专家网络,
个专家网络, 是路由器给 token
是路由器给 token  分配到专家 的权重,且
分配到专家 的权重,且  。
。
为了控制计算量,实际只激活 Top-K 个专家(其他  ):
):

其中  是路由 logits。Switch Transformer 用 Top-1(K=1),GShard 用 Top-2(K=2),Mixtral 8×7B 用 Top-2,DeepSeekMoE 用 Top-K,K 通常较大(8 起步)。
是路由 logits。Switch Transformer 用 Top-1(K=1),GShard 用 Top-2(K=2),Mixtral 8×7B 用 Top-2,DeepSeekMoE 用 Top-K,K 通常较大(8 起步)。
MoE 的”魅力”在于:总参数量很大( FFN 参数),但单 token 计算量只激活 K 个专家——稀疏激活让 inference 计算量等价于
FFN 参数),但单 token 计算量只激活 K 个专家——稀疏激活让 inference 计算量等价于  倍的 dense 模型,但容量是完整
倍的 dense 模型,但容量是完整  倍。
倍。
2.2 标准 MoE 的两个失败模式
但传统 MoE(Switch Transformer、GShard、Mixtral)在实践中暴露了两个问题:
失败模式 1:knowledge hybridity(知识混杂)
当专家数 较小(如 Mixtral 的 8 个、Switch Transformer 早期的 64 个但每个非常大)时,单个专家被迫”什么都学一点”。比如:
- Expert A 既学了”数学推理”,又学了”诗歌创作”
- Expert B 既学了”代码生成”,又学了”日常对话”
这导致专家内部知识”混合堆叠”,专家特化(specialization)不彻底。论文里把这个现象叫 knowledge hybridity。
失败模式 2:knowledge redundancy(知识冗余)
任何 token 都会用到一些”通用知识”(基本语法、常识、推理框架等)。在标准 MoE 里,每个 routed expert 都得保留这部分通用知识——否则只要它被路由到,就答不上来。
后果:所有专家都有一块相似的”通用知识区域”,多次冗余存储。论文里把这个叫 knowledge redundancy。
这两个失败模式合起来产生一个矛盾:
想让专家特化(解决问题 1),就得让每个专家更”专精”——但这又加剧了通用知识在不同专家间的冗余(问题 2)。
DeepSeekMoE 的两个核心设计就是分别针对这两个失败模式:fine-grained segmentation 解决 hybridity,shared expert isolation 解决 redundancy。
三、Fine-grained Expert Segmentation:组合空间的指数级放大
3.1 核心思想
传统 MoE 假设”每个专家是一个完整 FFN,宽度  “。Fine-grained segmentation 把这个假设打破:专家可以更窄。
“。Fine-grained segmentation 把这个假设打破:专家可以更窄。
具体来说:把传统 个专家、每个 intermediate 维度 、Top-K 激活的设置,改成  个专家、每个 intermediate
个专家、每个 intermediate  、Top-mK 激活。
、Top-mK 激活。
举个例子, 时:
时:
| 维度 | 传统 MoE | DeepSeekMoE Fine-grained |
|---|---|---|
| 专家数量 | 16 | 64(4 倍) |
| 单专家 FFN 中间维度 | |  |
| 单专家参数量 |  |  |
| 总参数(FFN) |  |  (不变) (不变) |
| Top-K 激活 |  |  (2 × 4) (2 × 4) |
| 单 token 激活参数 |  |  (不变) (不变) |
总参数与单 token 激活参数都保持不变——只是更细地”切分”了路由空间。但路由组合数从 跳到 。
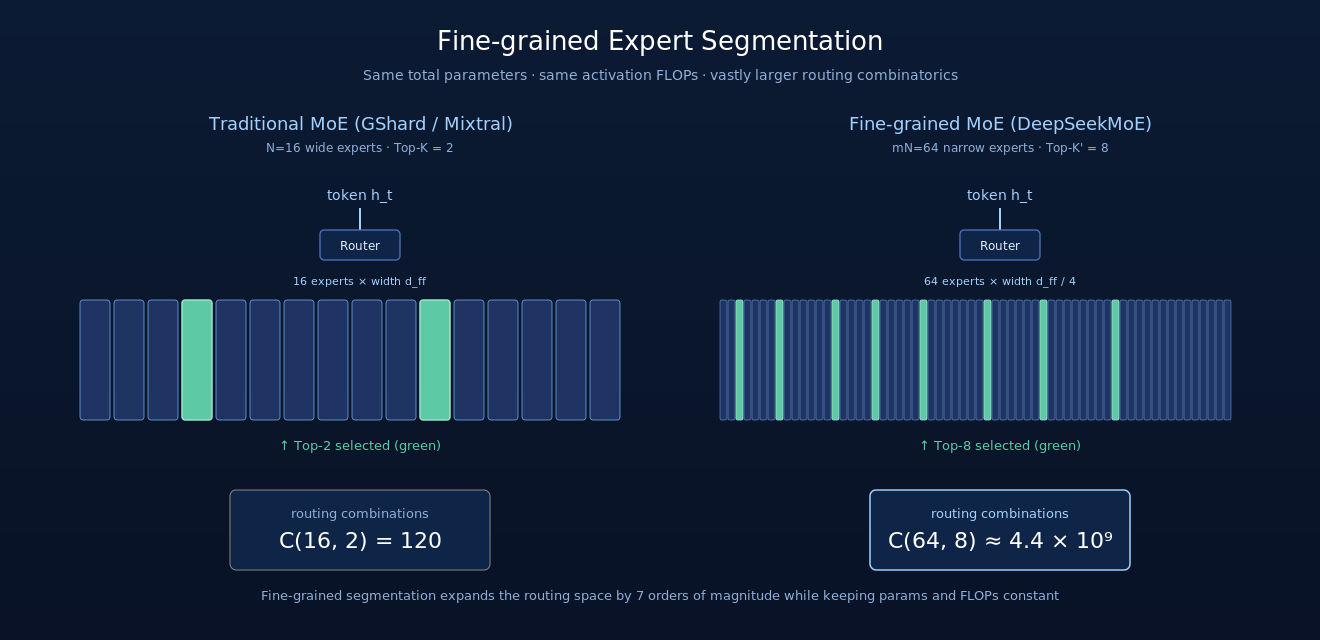
图 1:Fine-grained Expert Segmentation 的核心思想——把传统 16 个宽专家(左)切成 64 个窄专家(右),总参数与单 token 激活 FLOPs 完全不变;但 Top-K 也相应放大(K=2 → K’=8),路由组合空间从 120 暴涨到 44 亿。绿色高亮表示被路由选中的专家。
3.2 为什么组合空间更大就更好
直觉解释:MoE 的本质是”按 token 选择不同的子网络”,可选子网络数量越多,模型就越能找到与每个 token 匹配度最高的子结构。
具体到训练动力学:更细的专家意味着每个专家可以更专精地承载某个语义维度——比如”代码缩进风格”、”数学符号解析”、”中文古文语料”等粒度的微观知识,而不是被迫把多种不相关的知识混塞进同一个专家里。
论文给出的消融实验:
在 2B 参数规模上做对比,把传统 N=16 / K=2 的 GShard 配置切换为 fine-grained N=64 / K=8(参数和算力完全相同),下游任务 Pile loss 显著下降,HumanEval、GSM8K 等 benchmark 也相应提升。
这证明了 fine-grained 不是免费午餐意义上的”小聪明”,而是确实改变了模型学习的归纳偏置。
3.3 工程代价:路由器和通信
天下没有免费午餐。Fine-grained 的代价主要在两块:
代价 1:路由器输出维度变大
路由器要输出 个 logits,参数和 FLOPs 都是原来的  倍。但路由器本身是很小的线性层(
倍。但路由器本身是很小的线性层( ),相对 FFN 的总计算量来说,这个增加可以忽略。
),相对 FFN 的总计算量来说,这个增加可以忽略。
代价 2:all-to-all 通信粒度变细
MoE 的分布式训练需要把 token 通过 all-to-all 通信发送到承载对应专家的设备上。专家数从 16 → 64 后,token 被路由到的”目标设备集合”更分散,理论上单次 all-to-all 的延迟略有增加。
DeepSeek 在 V2/V3 里用 device-level balance loss + node-limited routing 来缓解这个问题(后面会讲)。在 16B 这一代,这个问题还不严重。
四、Shared Expert Isolation:把通用知识独立出来
4.1 核心思想
Fine-grained 让专家更小、更专精,但还没解决”通用知识冗余”。Shared Expert Isolation 的做法非常直接:
从
个仍是 routed expert,参与 Top-K 选择。
这样一来:
– 共享专家承担”任何 token 都需要的通用知识”——基本语法、常识、上下文整合
– Routed expert 只需要承担”差异化的特殊知识”——领域专用、风格专用、token 类型专用
公式上,DeepSeekMoE 的输出变为:

注意共享专家不带 gating 权重(也可以理解为  )——所有 token 都会过它。
)——所有 token 都会过它。
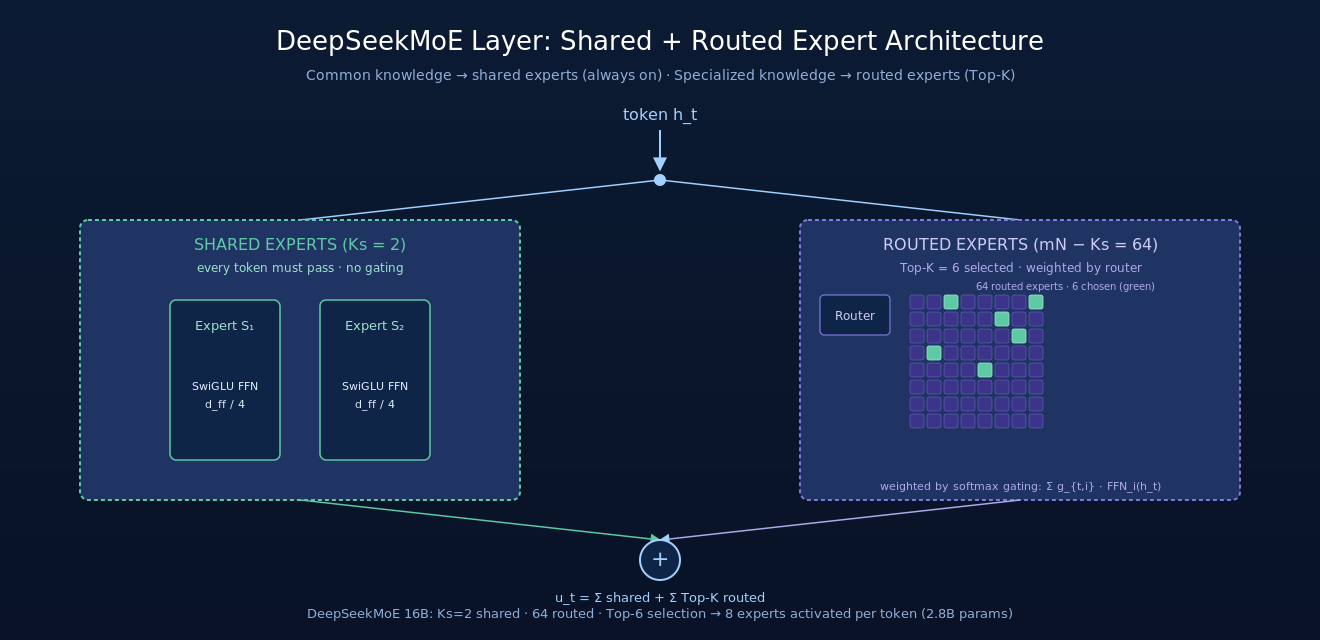
图 2:DeepSeekMoE 一层 MoE 的完整数据流——token 同时进入左侧的”共享专家”(始终激活、无路由)和右侧的”路由专家”(Top-K=6 由 router 选择)。每 token 实际激活 2 个 shared + 6 个 routed = 8 个专家,参数量 2.8B。Router 只对 routed expert 做选择,共享部分独立于路由决策。
4.2 容量预算的重新分配
引入共享专家相当于把”专家容量预算”做了二次切分:
- 总专家容量 = 共享部分 + 路由部分
- 单 token 激活容量 = 共享部分 + 路由部分
举例 DeepSeekMoE-16B 的配置: 个共享专家 + 64 个 routed 专家,Top-6 路由:
个共享专家 + 64 个 routed 专家,Top-6 路由:
- 总激活专家 = 2(必经)+ 6(路由选择)= 8 个
- 总参数中:共享专家占 2/(2+64) ≈ 3%,但每个 token 都过,所以它学到的知识被高密度复用
- Routed 专家占 97%,但每个 token 只走 6/64 ≈ 9.4%,每个 routed expert 被访问的”频次”很低,可以特化
这个二次切分的智慧在于:通用知识需要”被反复学习” → 放共享专家;差异化知识需要”足够细分的容器” → 放 routed expert。两者所需的训练动力学完全不同,分开处理是合理的设计。
4.3 与传统 MoE 路由 prior 的对比
理论上,传统 MoE 也能”自学”出某个专家专门承载通用知识——你期望路由器自然倾向于把所有 token 都路由到这个”通用专家”上。但实践中这几乎不会发生:
- 如果某个专家被路由频次显著高于其他,load balance loss 会惩罚这个专家,强迫路由器分散选择
- 即使没有 balance loss,路由器随机初始化时不知道”哪个专家该当通用专家”,等到它学到时通常已经收敛到一个次优的混合分配
Shared Expert Isolation 等于把”哪个专家是通用专家”作为先验明确告诉模型——这是 architecture prior 而非 learned behavior。后者更稳定,也更省训练数据。
五、Load Balance:双轴辅助损失
5.1 为什么 MoE 训练需要 balance loss
MoE 训练的”老问题”:路由器很容易陷入少数专家被频繁路由、多数专家很少甚至从不被路由的极端状态(routing collapse)。原因是 self-reinforcement——某个专家偶然学得稍好时,路由器倾向于给它更多 token,这个专家进一步变好,路由器更倾向给它… 形成正反馈。
后果:
1. 那些少被路由的专家”饿死”——参数没机会被训练
2. 实际表达能力等价于 K 个 dense FFN(不是 N),MoE 的总参优势被浪费
解决方案是引入 auxiliary loss(辅助损失),强迫路由分配相对均匀。
5.2 Expert-level Balance Loss
最经典的做法是 Switch Transformer 提出的负载均衡 loss。DeepSeekMoE 沿用类似公式,但只对 routed expert 部分(共享专家不需要均衡,反正必经)。
定义两个统计量:
- $f_i = \frac{m K}{T (mN – K_s)} \sum_{t=1}^{T} \mathbb{1}\{\text{token } t \text{ 路由到 routed expert } i\}$:归一化的路由频率
 :路由器对 expert 的平均 softmax 概率
:路由器对 expert 的平均 softmax 概率
Expert-level balance loss 是两者的内积:

 是 balance factor。这个 loss 的极小值点对应
是 balance factor。这个 loss 的极小值点对应  ,即均匀分布。
,即均匀分布。
DeepSeek-V2-Lite 用了  ,比 Switch Transformer 的默认
,比 Switch Transformer 的默认  小一个数量级——这个超参数选小一些可以减少 balance loss 对模型质量的扭曲(aux loss 本质是个干扰项,越小越好),但太小又会导致负载不均。
小一个数量级——这个超参数选小一些可以减少 balance loss 对模型质量的扭曲(aux loss 本质是个干扰项,越小越好),但太小又会导致负载不均。
5.3 Device-level Balance Loss
DeepSeekMoE 新提出的部分。当 很大、专家分布在多个 device(GPU 节点)上时,仅靠 expert-level balance loss 不够:
Expert-level loss 只保证”每个专家被路由频次接近”,但不能保证”每个 device 上的总路由频次接近”。
比如 64 个专家分到 8 个 device,每 device 8 个专家。即便每个专家都得到 1/64 的 token,但如果某个 device 上的专家被密集激活的时间段重叠,那个 device 的 GPU 利用率会爆掉,其他 device 闲着。
Device-level balance loss 用一个更松的均衡约束直接施加在 device 维度上:

其中:
–  是 device 数量
是 device 数量
–  是 device 上所有专家的平均路由频率
是 device 上所有专家的平均路由频率
–  是 device 上所有专家的总平均概率
是 device 上所有专家的总平均概率
Device-level loss 不强求专家间均衡(保留专家特化的自由度),只强求 device 间均衡(保护 GPU 利用率)。
DeepSeekMoE 的实证:单独用 expert-level loss 时 device 间最大负载差异约 23%;加上 device-level loss 后降到 8% 以下。
5.4 一个有趣的伏笔
DeepSeekMoE 这套 double-axis balance loss 已经比 Switch Transformer 的单纯 expert loss 进了一步,但 DeepSeek 团队后来又发现这两个 aux loss 本身仍然扭曲了 router 的最优分配——这一观察直接催生了 2024 年 8 月发表的 Auxiliary-Loss-Free Load Balancing(arXiv:2408.15664),用一种 bias-based 动态调整完全替代 aux loss。这条算法演进线索我们留到后面的 W10 单独详解。
六、DeepSeekMoE-16B:架构与训练
6.1 模型超参
| 维度 | DeepSeekMoE 16B |
|---|---|
| 总参数 | 16.4B |
| 激活参数(每 token) | 2.8B |
| Transformer 层数 | 28(其中第 1 层为 dense FFN) |
| Hidden dim | 2048 |
| Attention heads | 16 |
| 单 head dim | 128 |
| Attention 类型 | MHA(非 GQA) |
| 词表 | 102,400(与 DeepSeek LLM 同) |
| Context length | 4096 |
| 专家数(routed) | 64 |
| 共享专家数 | 2 |
| Top-K(routed) | 6 |
| 单专家 FFN intermediate | 1408 |
注意第 1 层用 dense FFN 不用 MoE——这是 DeepSeek 系列的标准做法(V2 / V3 都延续)。理由是低层主要学习通用模式提取,路由稀疏化对低层反而有害。
6.2 训练数据
- 总 tokens:2T(中英双语,与 DeepSeek LLM 7B 完全相同的数据)
- 目的:与 DeepSeek LLM 7B 形成”控制变量对照”——同样的数据、同样的训练流程,对比 dense vs MoE 谁更高效
6.3 训练 hyperparameter
- Multi-step LR schedule(与 DeepSeek LLM 同)
- AdamW,
 ,
, 
- Max grad norm = 1.0
- Batch size 与 LR 按 DeepSeek LLM Scaling Law 公式预测(见《DeepSeek LLM 详解》5.3 节)
6.4 PyTorch 化的路由实现(简化版)
下面是 DeepSeekMoE 路由层的简化 PyTorch 实现,便于理解:
实际生产实现还要做 expert parallel、capacity factor、token dropping、稀疏 kernel 优化等,但核心逻辑就是上面这几行。
七、性能验证:用 40% FLOPs 追平 LLaMA-2 7B
7.1 与 DeepSeek LLM 7B 的对照
这是论文最严谨的一组对照:DeepSeekMoE 16B 与 DeepSeek LLM 7B(同团队、同数据、同训练流程,只是 dense vs MoE)。
| Benchmark | DeepSeek LLM 7B Base | DeepSeekMoE 16B Base |
|---|---|---|
| MMLU (5-shot) | 48.2 | 45.0 |
| HumanEval | 28.1 | 26.8 |
| GSM8K (8-shot) | 17.4 | 18.8 |
| C-Eval | 44.1 | 40.6 |
| 平均 | — | 接近 |
| 训练 FLOPs | ~2 PetaFLOPs/token (7B激活) | ~0.8 PetaFLOPs/token (2.8B激活) |
DeepSeekMoE 16B 用 40% 的 FLOPs 接近 dense 7B 的水平——这是 MoE 设计本应实现的”稀疏激活 → 更高效”的承诺。Switch Transformer / GShard 等早期 MoE 工作在同等比较下往往会输给 dense 基线,DeepSeekMoE 是少数能做到”等性能 + 显著省 FLOPs”的 MoE 工作。
7.2 与 GShard 的消融
论文最有说服力的对照是与 GShard 的直接消融:在 2B 参数规模上保持总参 + 总激活 FLOPs 完全相同,只切换专家配置。
| 配置 | Pile loss ↓ |
|---|---|
| GShard (N=16, K=2) | 2.39 |
| + Fine-grained (N=64, K=8) | 2.32(提升 0.07) |
| + Shared Expert (Ks=2, N=62, K=6) | 2.29(再提升 0.03) |
每一步都带来显著(且单调)的 loss 下降,证明两个创新各自独立有效。
7.3 专家特化的可视化
论文里有一组实验把 DeepSeekMoE 16B 训练后的路由分布画出来——按”代码”、”数学”、”通用文本”等数据类别统计每个专家被路由的频率。结论是:
- 共享专家:路由频率几乎是常数(任何 token 都过,符合设计)
- Fine-grained routed experts:呈现明显的”专精分布”——某些专家在代码 token 上被频繁路由,某些在数学 token 上,某些在通用文本上,分布稀疏且区分度高
而同等 FLOPs 的 GShard 配置下,专家的”专精分布”远没有这么稀疏——每个专家都呈现”什么都能接一点”的均匀分布,正好对应了第二节讲的 knowledge hybridity 失败模式。
这个可视化是 DeepSeekMoE 设计哲学最直观的实证:专家越细,特化越彻底。
可视化没画出来的那张图:64 个专家的集群账单
路由热力图很漂亮,但作为工程师,我更关心它背后没画出来的那张图——token 在集群里的物理流向。Fine-grained 把专家从 16 切到 64、Top-K 从 2 放大到 8,FLOPs 账面上不变,但 all-to-all 通信的代价结构变了:每个 token 的激活专家更多、目的地集合更分散、单条消息更小,通信模式从「少量大包」变成「大量小包」,对互连带宽和延迟都更不友好。专家并行调度同理——专家数越多,placement 与负载波动的方差越大,流水线气泡越难压。我认为这正是论文要把 device-level balance loss 写进来的原因:它不是锦上添花,而是 fine-grained 能跑起来的前提条件。
还应该连着看 DeepSeek 后来的配套动作:V3 的 node-limited routing 限制跨节点扇出、DualPipe 做计算-通信重叠、2025 年开源的 DeepEP 专门优化 MoE 场景的 all-to-all——这套架构从一开始就是和自家 infra 协同设计的。我的判断是:fine-grained 在 DeepSeek 自家集群上成立,不代表搬到任何集群都成立。如果你的互连带宽、通信库和并行策略没有对齐到这个水位,照抄 64 选 8 的配置很可能只复现了参数表,复现不了 MFU。值得追问的一个问题是:你的训练框架的 all-to-all 实现是否针对小消息做过优化——这往往比专家数本身更决定成败。
八、对后续工作的影响
DeepSeekMoE 的两个设计原则被后续所有 DeepSeek MoE 模型沿用:
| 模型 | 总参 / 激活 | Routed 专家数 | Shared 专家数 | Top-K |
|---|---|---|---|---|
| DeepSeekMoE 16B (2024-01) | 16B / 2.8B | 64 | 2 | 6 |
| DeepSeek-V2 (2024-05) | 236B / 21B | 160 | 2 | 6 |
| DeepSeek-V3 (2024-12) | 671B / 37B | 256 | 1 | 8 |
| DeepSeek-V4 (2026-04) | 1.6T / 49B | (公开数据) | (公开数据) | (公开数据) |
可以看到 V3 把共享专家压缩到 1 个、routed 专家放大到 256 个——这个演化方向其实是”进一步放大 routed expert 的特化深度,同时削减共享专家的冗余”。
更值得注意的是 DeepSeek 系列完全没有改变这套设计的本质——fine-grained + shared 这两条公理沿用了两年半未变。同期 Mixtral、Qwen MoE 都尝试过其他 MoE 变体,但最终都向 DeepSeekMoE 范式收敛(Qwen-2 MoE 已经几乎完全照抄)。这是 DeepSeekMoE 作为”奠基论文”的实证。
另外两个间接影响:
- DeepSeek-V3 引入的 Auxiliary-Loss-Free Load Balancing(W10 详解)正是为了解决 DeepSeekMoE 这套 double-axis balance loss 对 router 的扭曲——没有 DeepSeekMoE 把 balance loss 用到极致,团队就不会观察到这个扭曲并设计出 bias-based 替代方案
- DeepSeek-V3 的 Node-Limited Routing 也是 DeepSeekMoE device-level balance loss 思路的延伸——device-level 是”软约束”,node-limited 是”硬约束”,两者解决的是同一个 GPU 利用率问题
写在最后
DeepSeekMoE 是 DeepSeek 系列里单点创新最纯粹的一篇 paper——它没有引入新的训练范式(如 R1 的 GRPO),没有新的硬件优化(如 V3 的 FP8 + DualPipe),没有新的位置编码(如 V2 的 MLA)。它只做了一件事:重新思考 MoE 的专家粒度与角色划分,然后用一个 16B 的小模型把这件事做实证。
但就是这一件事,决定了 DeepSeek 后续所有 MoE 模型的形状。如果说《DeepSeek LLM 详解》给整个系列定下了 Scaling Law 与数据流水线的方法论起点,那 DeepSeekMoE 就是给 V2 / V3 / V4 定下了架构骨架。
下一篇 W4 我们详解 DeepSeek-Coder 系列(V1 + V2 合篇),看 DeepSeek 把这套 MoE 设计移植到代码模型上时做了哪些调整。
参考资料
- Dai et al., DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, arXiv:2401.06066, 2024.
- DeepSeek-MoE GitHub repository:
- Fedus et al., Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, arXiv:2101.03961, 2022.
- Lepikhin et al., GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, arXiv:2006.16668, 2020.
- Shazeer et al., Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, arXiv:1701.06538, 2017.
- Jiang et al., Mixtral of Experts, arXiv:2401.04088, 2024.
- Wang et al., Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, arXiv:2408.15664, 2024.
- DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, arXiv:2405.04434, 2024.
![]()
2026-02-17 at 10:51 上午
第六节说”第 1 层用 dense FFN 不用 MoE,因为低层学通用模式提取、稀疏化对低层有害”。这个”低层不稀疏”是 DeepSeek 的经验结论还是有 ablation 支撑?