
转载本文请注明出处:https://yudonglee.me/deepseek-v2-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 2 月,2026 年 6 月有修订,补充了与系列后续论文的呼应。
本文是 DeepSeek 论文专题系列的第 6 篇,详解 DeepSeek 公司 2024 年 5 月发表的 DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model (arXiv:2405.04434)。这是 DeepSeek 通用 LLM 主线上的第一个 MoE 旗舰,首次提出了 Multi-head Latent Attention (MLA) 注意力机制——通过对 K / V 做低秩 latent 压缩,把 KV cache 砍到标准 MHA 的约 7%(93.3% 压缩率),让 236B 总参 / 21B 激活的 MoE 模型可以在长上下文推理中保持高吞吐。MLA 之后成为 DeepSeek 所有 V 系列模型(V3、V4)的标准件,与 DeepSeekMoE 并称为 DeepSeek 架构的”双支柱”。除了 MLA 之外,本文还会展开 V2 的整体设计:128K 长上下文、8.1T tokens 预训练、与 V1 / V2-Coder / V3 的演化关系,以及 MLA 与 RoPE 不兼容时的 decoupled RoPE 工程解法。
一、为什么 V2 是 DeepSeek 系列的旗舰转折点
W1 序言里我们把 DeepSeek 论文分为四条主线,第一条通用 LLM 主线的演化路径是:

V2 是这条主线上的关键转折点——从 Dense 切换到 MoE,从此 DeepSeek 通用 LLM 不再走”放大 Dense 参数”的传统 scaling law 路线,而是走”放大 MoE 总参 + 控制激活参数”的路线。这个架构选择决定了后续 V3 / V4 的所有形状。
V2 相对 V1 (67B Dense) 的核心数据:
| 维度 | DeepSeek LLM 67B | DeepSeek-V2 236B |
|---|---|---|
| 总参数 | 67B | 236B |
| 推理时激活 | 67B | 21B |
| 推理成本 | 1× | ~0.42×(节省 ~58%) |
| 训练成本 | 1× | ~0.57×(节省 ~42%) |
| 最大上下文 | 4K | 128K |
| KV cache 大小 | 1× MHA | ~0.073× MHA(MLA 压缩到 7.3%) |
| 训练 tokens | 2T | 8.1T |
注意这里的反直觉数字:236B 模型的推理成本居然只有 67B 的 42%。这不是因为某个单点优化,而是 MLA + MoE 同时作用的结果——MoE 让”激活参数”远小于”总参数”,MLA 让”KV cache 显存”远小于标准做法。两者合起来重新定义了”大模型”的成本曲线。
具体地看,V2 相对当时的主流开源模型(LLaMA-2 70B、Mixtral 8×22B、Qwen-1.5 72B)贡献了什么?三点:
- MLA (Multi-head Latent Attention):对 K / V 做低秩 latent 压缩,把 KV cache 砍到 MHA 的 7.3%——这是 V2 论文最有原创性的技术贡献
- DeepSeekMoE 架构正式上规模:W3 详解过的 fine-grained + shared expert 设计被放大到 236B 参数级别,验证了这套设计在大规模下的稳定性
- 128K 长上下文经济化:MLA 的 KV 压缩让 128K 长上下文推理的显存成本降到可接受范围,这是同期其他开源 70B+ 模型做不到的
下面按论文顺序展开,重点放在 MLA。
二、模型概览与初始化
DeepSeek-V2 提供两个版本:
| 模型 | 总参 | 激活参数 | 主要用途 |
|---|---|---|---|
| DeepSeek-V2 | 236B | 21B | 主力模型 |
| DeepSeek-V2-Lite | 16B | 2.4B | 端侧、轻量场景 |
V2 是从零训练的(不像 V2-Coder 从 V2 继续训练),训练数据 8.1T tokens 包含通用文本、代码、数学、中英文等。
架构上 V2 的关键配置:
- 60 层 Transformer
- 128 个 attention head(这是个非常大的数字,对应 MLA 设计需求)
- d_model = 5120
- MoE 部分:160 个 routed expert + 2 个 shared expert,Top-K = 6(沿用 DeepSeekMoE 设计)
- MLA 部分:d_c = 512 (latent dim), d_r = 64 (per-head RoPE dim)
- GQA-style?不是——V2 用的是 MLA 而非 GQA
注意一个细节:V2 的 attention head 数(128)远大于 LLaMA-2 70B 的 64。这与 MLA 设计有关——MLA 的好处之一是让”多 head”的成本变低(因为 KV cache 只与 latent dim 相关,与 head 数无关),所以 V2 团队可以放心地用 128 head 来增强表达能力。
三、核心创新:Multi-head Latent Attention (MLA)
3.1 标准 MHA 的两个问题
要理解 MLA 解决了什么问题,先回顾标准 Multi-Head Attention (MHA) 的工作流程。对一个 token  :
:

其中  (实际是 d × (n_h × d_h),但 n_h × d_h = d)。然后拆成
(实际是 d × (n_h × d_h),但 n_h × d_h = d)。然后拆成  个 head 做 attention。
个 head 做 attention。
MHA 的两个痛点:
- 训练显存压力:
 三个矩阵都是
三个矩阵都是  参数量,反向传播需要存储完整激活
参数量,反向传播需要存储完整激活 - 推理 KV cache 爆炸:自回归生成时需要缓存所有历史 token 的
 ,cache 大小是
,cache 大小是  (L 是序列长度)。对 128 head × 128 head_dim × 60 layer 的模型,单 token KV cache 高达 1.97 MB——一个 32K 上下文的 batch 就需要 60+ GB 显存
(L 是序列长度)。对 128 head × 128 head_dim × 60 layer 的模型,单 token KV cache 高达 1.97 MB——一个 32K 上下文的 batch 就需要 60+ GB 显存
这两个问题在长上下文推理中尤其突出。开源社区的传统解法:
- MQA (Multi-Query Attention):所有 Q head 共享 1 个 K / V head,cache 砍到
 ——节省巨大但模型质量明显下降
——节省巨大但模型质量明显下降 - GQA (Grouped-Query Attention):折中方案,n_g 个 K/V head 服务多个 Q head——LLaMA-2 70B 用的是 GQA,质量略好于 MQA 但仍弱于 MHA
MLA 的目标是保持 MHA 的表达能力,同时获得接近 MQA 的 cache 压缩比——理论上是不可能的”鱼与熊掌”,MLA 通过低秩 latent 压缩实现了这个目标。
3.2 MLA 的核心思路:低秩 latent 压缩
核心观察:与其分别为每个 head 维护独立的  ,不如把所有 head 的 K / V 信息压缩成一个低维 latent 向量
,不如把所有 head 的 K / V 信息压缩成一个低维 latent 向量  ,需要时再”解压”出每个 head 的 K / V。
,需要时再”解压”出每个 head 的 K / V。
MLA 的前向计算(先不考虑 RoPE):


 是 down-projection(压缩矩阵)
是 down-projection(压缩矩阵) 是 up-projection(解压矩阵)
是 up-projection(解压矩阵)- 是每个 token 的 latent 向量,维度

V2 的具体配置: ,相比
,相比  ,压缩比为
,压缩比为  。
。
关键的工程优势:推理时只需要缓存 而不是  。每个 token 的 cache 大小从
。每个 token 的 cache 大小从  (float) 降到 ——理论上能压到 1/64。
(float) 降到 ——理论上能压到 1/64。
但这里有一个非常微妙的问题:在 attention 计算中,K 和 Q 要做矩阵乘  ,如果只存了
,如果只存了  ,岂不是每次推理都要重新做
,岂不是每次推理都要重新做  解压?这不就抵消了 cache 节省吗?
解压?这不就抵消了 cache 节省吗?
答案是 MLA 的另一个工程巧妙之处——matrix absorption(矩阵吸收)。
3.3 推理时的 Matrix Absorption 技巧
在 attention 计算里:

注意  只与
只与  这一侧的运算相关,与历史 token 无关。所以推理时可以预先把 吸收到 Q 的投影中:
这一侧的运算相关,与历史 token 无关。所以推理时可以预先把 吸收到 Q 的投影中:

然后 attention 直接变成:

——只需要存 ,不需要解压成 K,attention 直接在 latent 空间做。
同样的吸收对 V 也成立: 可以吸收到输出投影
可以吸收到输出投影  里。
里。
为什么这个吸收可行:因为 与  之间没有非线性(softmax 在
之间没有非线性(softmax 在  之后才作用),所以两个线性变换可以合并。这是 MLA 设计的精细之处——压缩与吸收是配套设计的。
之后才作用),所以两个线性变换可以合并。这是 MLA 设计的精细之处——压缩与吸收是配套设计的。
实际上 V2 论文里还对 Q 也做了类似的低秩分解( ),主要目的是减少训练时的激活显存(推理时 Q 不需要 cache,所以 Q 压缩对推理意义不大)。
),主要目的是减少训练时的激活显存(推理时 Q 不需要 cache,所以 Q 压缩对推理意义不大)。
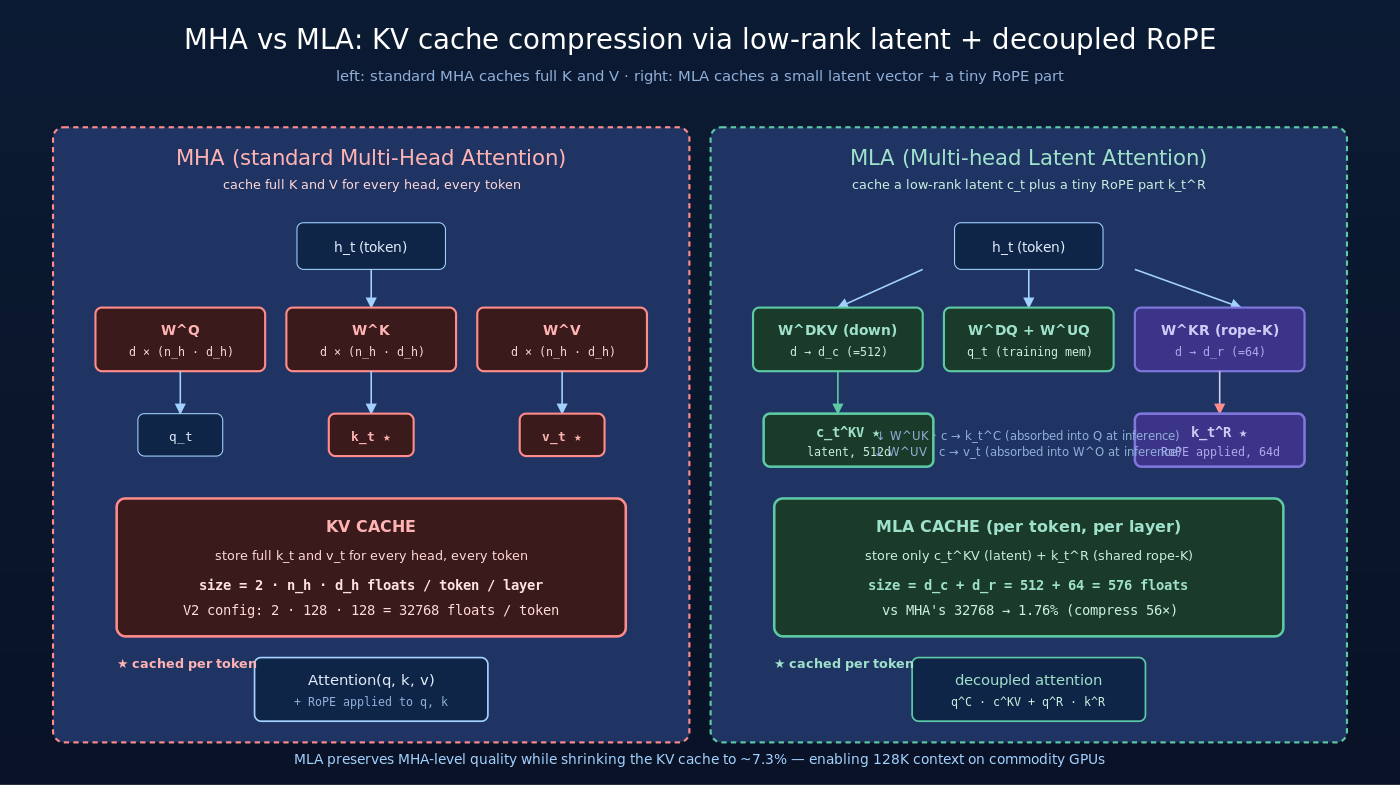
3.4 工程挑战:MLA 与 RoPE 不兼容
到这里 MLA 看起来已经很优雅了,但有一个致命问题:RoPE(Rotary Position Embedding,旋转位置编码)和 MLA 的 latent 压缩天然不兼容。
RoPE 的工作方式是对 K(和 Q)做一个位置相关的旋转:

其中  是一个位置
是一个位置  决定的旋转矩阵。问题是:
决定的旋转矩阵。问题是:
- 如果在
 之后才应用 RoPE,那 attention 计算变成
之后才应用 RoPE,那 attention 计算变成  ,
, 是位置相关的,无法预先吸收——matrix absorption 失效
是位置相关的,无法预先吸收——matrix absorption 失效 - 如果想做 absorption,就要在 上直接做 RoPE,但 RoPE 是对 K 这种正交分量做旋转,对 latent 做 RoPE 没有几何意义
DeepSeek-V2 的解法是 decoupled RoPE(解耦 RoPE)——把每个 head 的 K 切成两部分:
![k_t = [\,\underbrace{k_t^C}_{\text{content (no RoPE)}};\, \underbrace{k_t^R}_{\text{RoPE}}\,] \in \mathbb{R}^{d_h + d_r}](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-5b27f992e4b8a1717056f48a0d0a1bb4_l3.png "Rendered by QuickLaTeX.com")
- content 部分
 ——走 latent 压缩,不应用 RoPE,可以做 matrix absorption
——走 latent 压缩,不应用 RoPE,可以做 matrix absorption - RoPE 部分
 ——直接从
——直接从  算,应用 RoPE,所有 head 共享同一个
算,应用 RoPE,所有 head 共享同一个  (类似 MQA)
(类似 MQA)
Q 也对应做分解:
![q_t = [\,q_t^C;\, q_t^R\,],\quad q_t^C = W^{UQ} c_t^Q,\quad q_t^R = \text{RoPE}(W^{QR} c_t^Q)](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-9fb9bc382e0253bb683624eb433ea3c5_l3.png "Rendered by QuickLaTeX.com")
attention 计算变成:

- 第一项:在 latent 空间做(吸收 )
- 第二项:在小维度的 RoPE 子空间做
Cache 内容:每个 token 只需缓存:
- (latent 向量,维度 )
- (RoPE 部分,维度
 ,所有 head 共享)
,所有 head 共享)
总 cache 大小 =  (float)/ 每 token / 每 layer。
(float)/ 每 token / 每 layer。
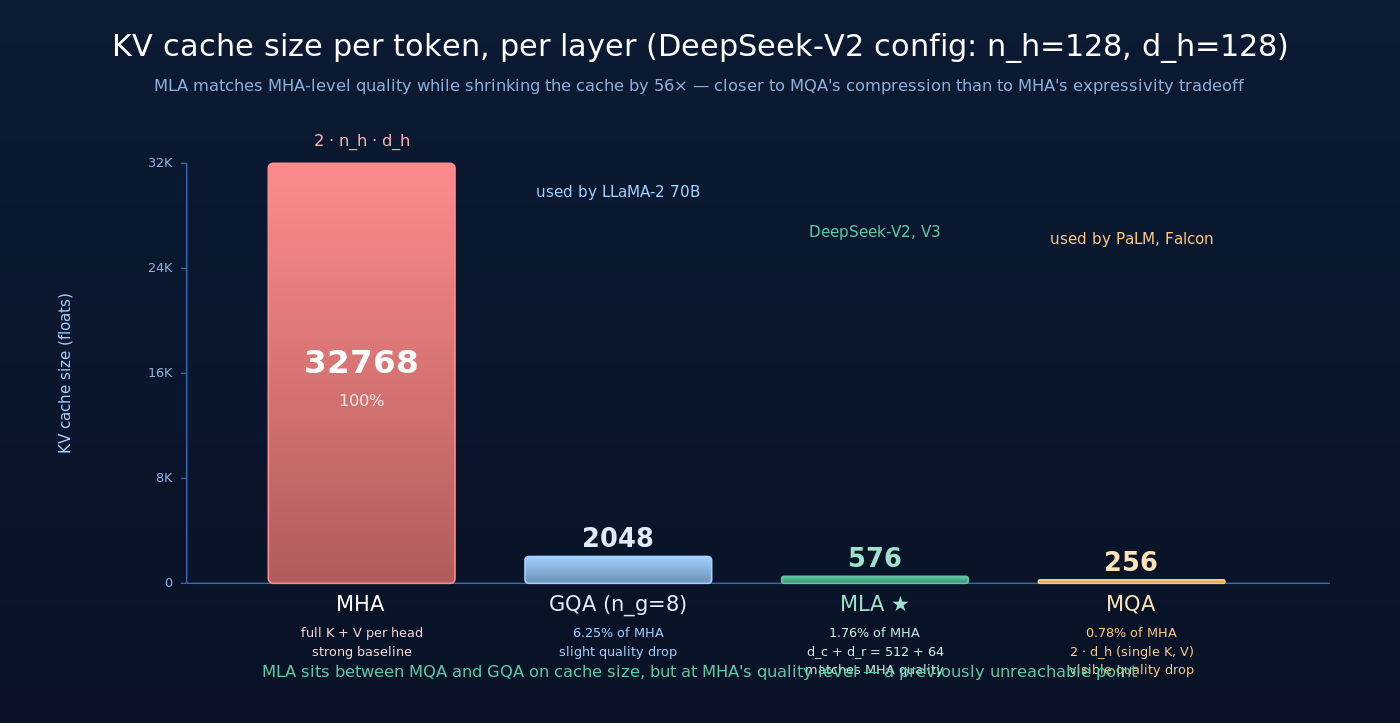
3.5 KV cache 大小对比
把不同 attention 变体的 KV cache 量化对比(基于 V2 配置: ):
):
| 变体 | KV cache / token / layer | 相对 MHA | 模型质量 |
|---|---|---|---|
| MHA |  | 100% | 强(baseline) |
| MQA |  | 0.78% | 明显弱于 MHA |
| GQA (n_g=8) |  | 6.25% | 略弱于 MHA |
| MLA (V2 配置) |  | 1.76% | 接近或略超 MHA |
注意:
- MLA 的 cache 大小(576)已经接近 MQA(256)的水平——但模型质量保持了 MHA 级
- 相对 GQA-8,MLA 在 cache 上小 3.5×,在质量上还略好
- 如果与 GQA-1(即 MQA)对比,MLA 的 cache 大约是其 2.25×,但质量明显更好
V2 论文官方报告的对比数字是与 DeepSeek 67B Dense 相比 KV cache 减少 93.3%——背后正是 MLA 这套设计。
3.6 MLA 的训练稳定性
MLA 由于引入了额外的低秩分解,理论上会有一些训练稳定性挑战。V2 论文里报告了几个工程实践:
- RMSNorm 应用在 上:在压缩之后立即做 normalization,防止 latent 表征 drift
- 与 初始化使用 scaled normal:避免训练初期 latent 解压后数值不稳
- 学习率调度:MLA 部分对学习率更敏感,需要相比 MHA 略低的初始学习率
这些都是工程细节,但累积起来决定了 MLA 能否成功跑到 236B 规模——纸面公式看起来漂亮,实战落地要面对这些 trade-off。
四、DeepSeekMoE 在 V2 中的应用
V2 的 MoE 部分完全沿用 W3 详解过的 DeepSeekMoE 设计:fine-grained expert + shared expert。这里只补充 V2 规模下的具体配置:
| 项 | DeepSeekMoE 16B | DeepSeek-V2 236B |
|---|---|---|
| 总参 | 16B | 236B |
| 激活参数 | 2.8B | 21B |
| Routed expert 数 | 64 | 160 |
| Shared expert 数 | 2 | 2 |
| Top-K | 6 | 6 |
| 每 token 激活 expert | 6 + 2 = 8 | 6 + 2 = 8 |
可以看到 V2 把 routed expert 数从 64 放大到 160,但 Top-K 和 shared expert 数都保持不变——这是 DeepSeekMoE 设计的”按比例放大”路径。
V2 还引入了 W3 没有的两个 MoE 工程细节:
- Device-limited routing:限制每个 token 在多少个 device 上做 expert 选择,约束在 ≤4 个 device。这是 DeepSeekMoE device-level balance loss 的硬约束版本,减少跨设备通信
- Token-dropping strategy:训练时如果某个 expert 收到的 token 数超过 capacity(容量),多出来的 token 会被 drop。V2 设了一个温和的 drop ratio(≤0.05),平衡稳定性与计算效率
这两个工程优化都是为了让 MoE 在大规模分布式训练里跑得稳——本质是 GPU 集群约束驱动的 architectural decision。
五、训练 pipeline 与长上下文扩展
V2 的训练分四个阶段:
5.1 Pretraining (8.1T tokens)
完整从零训练,数据配比:
- 通用文本 ~70%(英中双语为主)
- 代码 ~17%
- 数学 ~10%
- 其他(多语言、知识类)~3%
注意代码占比 17% 明显高于 DeepSeek-LLM 67B(约 10%)——这反映了 DeepSeek 团队在 V1 之后从 Math 论文学到的经验:代码数据对 reasoning 能力有显著正向贡献,所以 V2 通用 LLM 训练里就主动加大代码占比。
5.2 Long Context Extension (32K → 128K)
Pretraining 默认是 32K 上下文,扩展到 128K 用的是 YaRN-style RoPE 频率缩放:

其中  是缩放因子。然后用 100B tokens 在 128K 窗口上做继续预训练。
是缩放因子。然后用 100B tokens 在 128K 窗口上做继续预训练。
这里的工程要点是:MLA 让长上下文训练真正经济。32K → 128K 的扩展需要 attention 计算量是原来的 16×(attention 复杂度是序列长度平方),加上 KV cache 也是 4×。如果不是 MLA 把 cache 压到 1.76%,长上下文训练显存会爆炸。
5.3 SFT (1.5M 指令样本)
监督微调阶段,与之前 DeepSeek-Coder / Math 的 SFT 类似,使用对话格式与多种任务覆盖。
5.4 RL (DeepSeekMath 的 GRPO)
V2 的 RL 阶段直接用 W5 详解过的 GRPO 算法——这是 GRPO 首次被用到 DeepSeek 主线通用 LLM 上(之前只在 Math 这种垂直领域用过)。
V2 的 reward modeling 与 R1 不同——V2 用了更传统的 reward model + GRPO 组合,没有 R1 的 reasoning-format reward。这部分细节论文里没有大量展开,因为 V2 的目标是”对话质量提升”而非”reasoning 能力突破”,后者要等到 W11 的 R1 才会被系统性解决。
六、评测结果与推理经济性
V2 发布时的 benchmark 全景(与同期开源旗舰对比):
| Benchmark | DeepSeek-V2 (236B / 21B) | LLaMA-3 70B | Mixtral 8×22B | Qwen-1.5 72B |
|---|---|---|---|---|
| MMLU | 78.5 | 82.0 | 77.8 | 76.3 |
| BBH | 78.9 | 81.0 | 78.8 | 77.4 |
| HumanEval | 81.1 | 81.7 | 75.0 | 71.3 |
| MBPP | 72.0 | 70.4 | 64.2 | 66.4 |
| GSM8K | 79.2 | 81.9 | 70.5 | 78.9 |
| MATH | 43.6 | 30.7 | 28.7 | 39.9 |
| C-Eval (中文) | 81.7 | 67.5 | 61.4 | 84.1 |
关键观察:
- MMLU、BBH、HumanEval 上 V2 与 LLaMA-3 70B 互有胜负——这是一个 21B 激活 vs 70B 激活的对比,从这个角度看 V2 的能力密度更高
- 数学(MATH)上 V2 大幅领先——继承自 DeepSeekMath 团队的数据 pipeline
- 中文 C-Eval 上 V2 仅次于 Qwen-1.5 72B——双语训练数据的红利
6.1 推理经济性:V2 真正的 USP
V2 论文最重要的一张图是推理成本对比:
| 模型 | 激活参数 | KV cache | 单 GPU 最大 batch | 相对吞吐 |
|---|---|---|---|---|
| DeepSeek 67B Dense | 67B | 1× MHA | 16 | 1× |
| DeepSeek-V2 | 21B | 0.073× MHA | 256 | 5.76× |
236B 模型的吞吐反而是 67B Dense 的 5.76×——这就是 MLA + MoE 双柱设计的工程成果。具体到 API 定价,V2 发布时的价格约 1元 / 百万 input tokens,是同期 GPT-4 价格的 1%。这是开源社区第一次看到”大模型 + 经济推理”同时实现。
V2 对市场的意义:V2 把”开源大模型经济性”从单纯的参数效率(small model)路线,转向了”大总参 + 小激活 + 压缩 cache”的工程组合。这套思路后来被 V3 进一步放大(671B / 37B),并影响了 Qwen-MoE、Kimi-VL 等多个开源模型的设计选择。
七、局限与衔接 V3
DeepSeek-V2 是一个里程碑式的 MoE 旗舰,但仍有几个局限:
- 激活参数 21B 还偏小——某些复杂推理任务(MATH 高难题、长链 reasoning)的 SOTA 模型激活参数普遍在 70B+。V3 把激活参数放大到 37B 是直接回应
- 没有 FP8 训练——V2 仍用 BF16,训练成本与精度 trade-off 没有压到极限。V3 引入 FP8 训练把训练显存进一步砍半
- Pipeline 并行效率——V2 用的是标准 1F1B 调度,bubble 较大。V3 引入 DualPipe 把调度优化到接近 zero-bubble
- DeepSeekMoE 的 balance loss 副作用——V2 用 expert-level + device-level balance loss,对 router 有一定扭曲。V3 用 Auxiliary-Loss-Free Load Balancing(W11 详解)解决这个问题
- 128K 上下文外推不稳定——V2 在 128K 接近上限时性能略下降。V3.2 引入 NSA (Native Sparse Attention) 把可靠上下文拓展到百万级
V3 在 V2 基础上的关键升级(W12 详解)
| 维度 | DeepSeek-V2 | DeepSeek-V3 |
|---|---|---|
| 总参 / 激活 | 236B / 21B | 671B / 37B |
| 训练精度 | BF16 | FP8 |
| MoE Routed Expert | 160 | 256 |
| MoE Shared Expert | 2 | 1 |
| Pipeline 调度 | 1F1B | DualPipe |
| Load Balance | Aux Loss | Aux-Loss-Free |
| 训练 tokens | 8.1T | 14.8T |
V3 是把 V2 的所有维度都放大 + 工程精修一遍的结果。MLA 和 DeepSeekMoE 这两个支柱设计保持不变——这进一步印证了 V2 这一代奠基架构的稳定性。
MLA 对行业的影响
MLA 提出之后,业界出现了若干跟进工作:
- TransMLA(Towards Economical Inference,arXiv:2502.14837):研究如何把现有的 MHA / GQA 模型转换为 MLA,让任意 Transformer 都能享受 KV cache 压缩
- Hardware-centric MLA 分析(arXiv:2506.02523):从硬件 IO bandwidth 角度分析 MLA 的极限优势
- 多家开源团队尝试复刻:但目前还没有团队公开成功在 70B+ 规模重现 MLA 的优势——这反映了 MLA 工程细节(特别是 decoupled RoPE 与 matrix absorption 的协同)的实现门槛
可以说 MLA 是 DeepSeek 系列里学术原创性最高的架构创新——DeepSeekMoE 是已有思路的精细化,GRPO 是 PPO 的简化,而 MLA 是真正”业界第一次实现”的新机制。
写在最后
DeepSeek-V2 是 DeepSeek 系列里架构含金量最高的一篇 paper。它做对了三件事:
- 首次提出 MLA:用低秩 latent 压缩 + decoupled RoPE 解耦 + matrix absorption 吸收,把 KV cache 砍到 MHA 的 1.76%,同时保持模型质量
- 首次把 DeepSeekMoE 放大到 200B+ 规模:验证了 fine-grained + shared expert 设计在大模型上的稳定性,为 V3 / V4 铺路
- 建立了”大总参 + 小激活 + 压缩 cache”的经济推理范式:236B 模型推理吞吐 5.76× 于 67B Dense,重新定义了”开源大模型”的成本曲线
这三件事的影响远超 V2 本身——V3 / V4 都建立在这套架构基础上,整个 2024-2026 年的开源 MoE 模型设计选择也大量参考了 V2 的方法论。
下一篇 W8 我们详解 DeepSeek-Prover 系列(arXiv:2405.14333),这是 DeepSeek 在形式化数学证明方向的探索——把 LLM 与 Lean / Coq 等定理证明器结合,把数学推理从”自然语言 CoT”推向”机器可验证的形式化证明”。这是 R1 之前 DeepSeek 在 reasoning 主线上的另一条平行探索,为后来的 reasoning-as-search 路线提供了思路。
参考资料
- DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, arXiv:2405.04434, 2024.
- DeepSeek-V2 GitHub repository:
- Su et al., RoFormer: Enhanced Transformer with Rotary Position Embedding (RoPE), arXiv:2104.09864, 2021.
- Shazeer, Fast Transformer Decoding: One Write-Head is All You Need (MQA), arXiv:1911.02150, 2019.
- Ainslie et al., GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, arXiv:2305.13245, 2023.
- Peng et al., Towards Economical Inference: Enabling DeepSeek’s Multi-Head Latent Attention in Any Transformer-based LLMs (TransMLA), arXiv:2502.14837, 2025.
- Eryk Banatt, Understanding Multi-Head Latent Attention, blog post, 2024.
- Dai et al., DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, arXiv:2401.06066, 2024.
![]()
2026-03-17 at 6:40 下午
位置信息被压成所有 head 共享的一份 d_r=64 小向量,那不同 head 想”以不同方式利用位置”(比如有的 head 关注近距离、有的关注远距离)的能力是不是被削弱了?