
转载本文请注明出处:https://yudonglee.me/deepseek-v4-explained/ | 作者:yudonglee
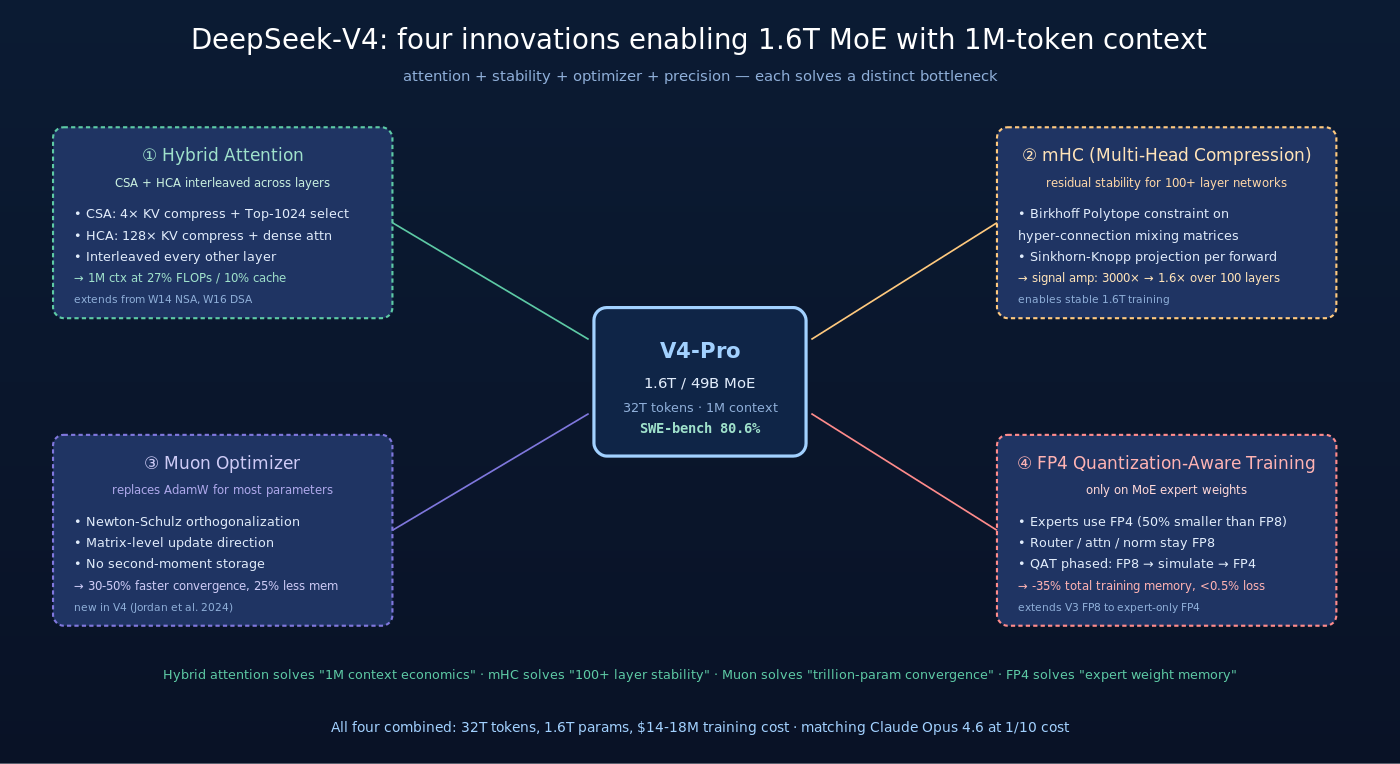
本文是 DeepSeek 论文专题系列的第 17 篇与系列收官,详解 DeepSeek 公司 2026 年 4 月 24 日发布的 DeepSeek-V4 系列——通用 LLM 主线的最新旗舰。V4 包含两个模型:V4-Pro(1.6T 总参 / 49B 激活的 MoE)与 V4-Flash(284B 总参 / 13B 激活)。两者都支持 1M token 上下文 + 384K token 输出,并提供 dual thinking/non-thinking 双模式。V4 的核心架构创新有四项:(1) Hybrid Attention = CSA + HCA——把 W14 NSA / W16 DSA 的稀疏 attention 思路升级为”两种稀疏机制交错”的混合方案,CSA (Compressed Sparse Attention) 用 4× KV 压缩 + Top-1024 选择保留细粒度上下文,HCA (Heavily Compressed Attention) 用 128× KV 压缩 + 全密度 attention 提供经济的全局视野;(2) mHC (Multi-Head Compression)——用 Birkhoff Polytope 约束 + Sinkhorn-Knopp 算法重构 residual 连接,把深层网络的信号放大从 3000× 压到 1.6×,让 1.6T 模型训练稳定;(3) Muon 优化器替代 AdamW,给 1.6T 大模型提供更快的收敛与更好的稳定性;(4) FP4 量化训练——对 expert 权重做 quantization-aware training,把训练显存再降一档。V4-Pro 在 SWE-bench Verified 上达到 80.6%,与 Claude Opus 4.6、Gemini 3.1 Pro 持平。V4 的 1M 上下文推理仅消耗 V3.2 的 27% FLOPs 与 10% KV cache。V4 是 DeepSeek 自 2024-01 以来 16 篇技术论文积累的”产品级总集成”——本文同时作为整个系列的收官,回顾 W2-W17 的 16 项创新如何拼接出 V4 这个旗舰。
一、V4 在 DeepSeek 系列中的位置:12 个月 + 16 篇论文的总集成
W1 序言里我们把 DeepSeek 论文分为四条主线。回顾整个系列,通用 LLM 主线的演化路径是:

V4 是这条主线的最新顶点,也是整个 DeepSeek 系列的集大成之作。
1.1 V4 vs V3 / V3.2:能力与成本同步升级
V4 相对前几代的全维度对比:
| 维度 | V3 (W12) | V3.2 (W16) | V4-Pro | 变化 |
|---|---|---|---|---|
| 总参数 | 671B | 685B | 1.6T | 2.34× |
| 激活参数 | 37B | 37B | 49B | 1.32× |
| 上下文 | 128K | 128K | 1M | 7.8× |
| 输出上限 | 32K | 32K | 384K | 12× |
| 训练 tokens | 14.8T | continued | 32T+ | 2.16× |
| Attention | MLA + dense | MLA + DSA | CSA + HCA hybrid | 双重稀疏化 |
| 优化器 | AdamW | AdamW | Muon | 新优化器 |
| 训练精度 | FP8 | FP8 | FP8 + FP4 (experts) | 进一步压缩 |
| 1M 上下文 FLOPs | 不可行 | 不可行 | 27% of V3.2 baseline | 让 1M 成为现实 |
| 1M KV cache | 不可行 | 不可行 | 10% of V3.2 baseline | 让 1M 成为现实 |
最有冲击力的数字是:V4-Pro 在 1M 上下文下的推理成本只有 V3.2 的 27%(FLOPs)和 10%(KV cache)——这意味着把 V3.2 从 128K 扩展到 1M 后实际成本反而比 V3.2 在 128K 下还低。这是一次质的飞跃。
1.2 V4 vs 同期闭源旗舰
V4 发布时(2026-04)的业界主流 frontier model 对比:
| 模型 | 参数规模 | 上下文 | SWE-bench Verified | 估计 API input 价格 (per M) |
|---|---|---|---|---|
| Claude Opus 4.6 | 闭源 | 200K | 82.0% | ~$45 |
| Gemini 3.1 Pro | 闭源 | 2M | 81.5% | ~$30 |
| GPT-5.5 (推测) | 闭源 | 400K | 79.8% | ~$50 |
| DeepSeek V4-Pro | 1.6T open | 1M | 80.6% | $1.74 |
V4-Pro 在 SWE-bench Verified 上与所有闭源 frontier 模型持平(±1.5pt 范围内),但 API 价格只有它们的 4-6%。这是 V3 (W12) “1/30 成本对齐 GPT-4o” 故事的延续——一年后 V4 把这个对比关系扩展到 reasoning + agentic 全维度。
1.3 V4 模型家族:Pro + Flash
V4 一上线就发布两个版本,定位不同:
| 模型 | 总参 / 激活 | 主要用户 | 价格定位 | 性能定位 |
|---|---|---|---|---|
| V4-Pro | 1.6T / 49B | 企业 / 重型推理 | $1.74/M input | frontier-level |
| V4-Flash | 284B / 13B | 个人开发者 / 高并发 | $0.14/M input | strong mid-range |
Flash 是 DeepSeek 第一次同时发布 frontier 与 mid-range 两档模型。这与 OpenAI(GPT-5.5 + GPT-5.5-mini)、Anthropic(Opus + Haiku)、Google(Gemini Pro + Flash)的产品线策略对齐——开源 LLM 第一次具备完整的”frontier + mid-range”产品矩阵。
下面我们详细展开 V4 的四项核心架构创新。
二、核心创新一:Hybrid Attention = CSA + HCA
V4 最重要的架构创新是两种稀疏 attention 的交错混合使用——把 W14 NSA、W16 DSA 的单一稀疏方案升级为”双稀疏交错”的混合架构。
2.1 为什么需要混合 attention
W14 NSA 与 W16 DSA 都解决了”长上下文 attention 经济性”问题,但它们都是单一稀疏机制:
- DSA:Top-K 选择 2048 个 token 做精细 attention(保细节但全局视野有限)
- NSA:三分支(compression + selection + sliding window)(更复杂但仍是单一融合)
当上下文扩到 1M 时,单一稀疏机制都会暴露问题:
- 过分依赖 Top-K 选择:1M token 里选 2048 个意味着选择率仅 0.2%——某些位置的细节可能被错过
- 过分依赖压缩:如果全部用 compression 损失太多细节
- 缺少全局视野:Top-K 选择本质是”局部聚焦”,对于需要 cross-section reasoning(如从第 800K token 引用回到第 50K token)的场景仍然脆弱
V4 的解法是让两种稀疏机制各司其职、交错部署——这就是 CSA + HCA Hybrid Attention。
2.2 CSA (Compressed Sparse Attention):细粒度稀疏路径
CSA 是 V4 的”细粒度稀疏”分支,目标是在保留局部细节的同时控制计算量:
Step 1: 4× KV compression
把每 4 个连续 token 的 K/V 压缩为一个 representative token(用 softmax-gated pooling + 学习位置 bias)。这一步把 1M token 压到 250K 压缩 token。
Step 2: Lightning indexer
用一个小型 indexer(类似 W16 DSA 的 lightning indexer,FP8 加速)对每个 query 在 250K 压缩 token 上计算 importance score。
Step 3: Top-1024 selection
按 indexer 的 score 选 Top-1024 个压缩块(每块 4 个原 token),对应原序列 4096 个 token。
Step 4: 主 attention
对选中的 4096 个 token 做完整 attention(BF16,128 头)。
CSA 的总成本:

CSA 让 V4 在保留细节的同时把单 query 的 attention FLOPs 降到 dense 的 1%。
2.3 HCA (Heavily Compressed Attention):粗粒度全局路径
HCA 是 V4 的另一条互补路径,目标是用极致压缩提供经济的全局视野:
Step 1: 128× KV compression
把每 128 个连续 token 的 K/V 压缩为一个 representative token。1M token 压缩为 8000 个 high-level summary token——只有原始的 0.78%。
Step 2: 全密度 attention
对压缩后的 8000 个 token 做完整 dense attention(不再做 Top-K 选择)。
HCA 的总成本:

8000² × d 这个 attention 比 1M² × d 小 16384×,但仍然是全局 dense——每个 token 都能 attend 到所有其他压缩 token。这给了 HCA”看到整个序列骨架”的能力。
2.4 为什么 CSA 与 HCA 要交错使用
V4 没有让所有 layer 都跑 CSA 或都跑 HCA——而是让两种 attention 在不同 layer 交错:
- 偶数 layer(layer 0, 2, 4, …):使用 CSA(保细节)
- 奇数 layer(layer 1, 3, 5, …):使用 HCA(看全局)
这种交错设计的直觉是:
CSA 让 token 看清局部精细模式,HCA 让 token 看清全局骨架结构——两者交错让信息在两个时间尺度上同时流动。
类比人类阅读:你读一本书时既需要”看清当前段落的每个字”(CSA),也需要”记得这本书的整体脉络”(HCA)。V4 把这两种 attention 模式从硬性混合改成”层间交错”——每一层都偏好一种模式,但跨多层的信息流动同时具备两种特性。
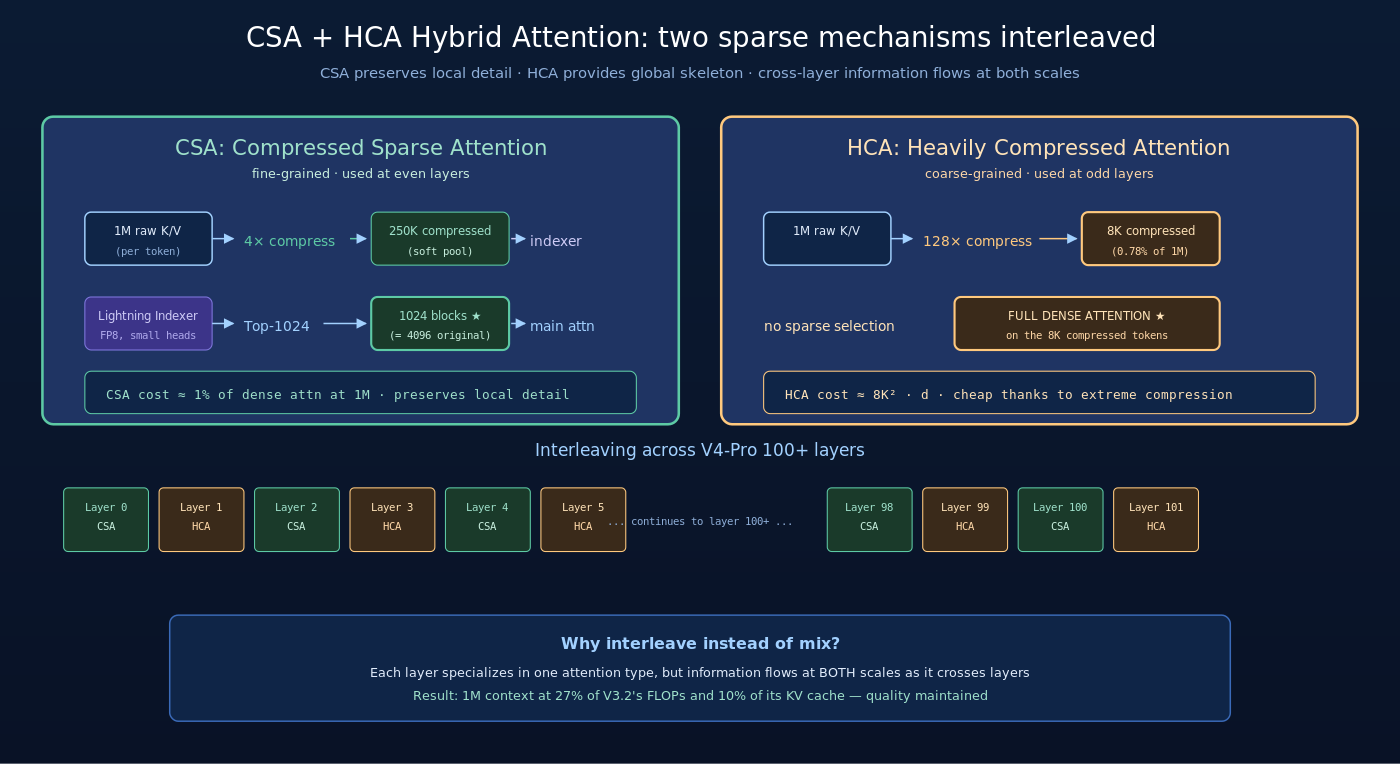
2.5 Hybrid Attention 的总效益
V4-Pro 在 1M 上下文下的 attention 成本相对 V3.2 dense baseline:
| 维度 | V3.2 (DSA on 128K) | V4-Pro (CSA+HCA on 1M) | 改变 |
|---|---|---|---|
| 上下文长度 | 128K | 1M | 7.8× |
| 单 token attention FLOPs | 1× | 0.27× | 比 V3.2 低 |
| KV cache per token | 1× | 0.10× | 比 V3.2 低 |
| 总 attention cost (1M context) | 不可行 | 可行 | 质变 |
V4-Pro 在 1M 上下文下的推理 cost 比 V3.2 在 128K 下还低——这是 hybrid attention 的最直接成果。
三、核心创新二:mHC (Multi-Head Compression)
mHC 是 V4 训练稳定性的关键技术。如果说 hybrid attention 解决”推理时性能”,mHC 解决”训练时稳定性”。
3.1 Hyper-Connections 与深层网络的爆炸问题
V3 (W12) 用的是标准 Pre-Norm + Residual 残差连接。但在 V4 这种 1.6T trillion-param + 100+ layer 的极深架构下,标准残差出现一个新问题:
Hyper-Connections(超级残差连接)实验——在 27B 模型上 DeepSeek 团队尝试让残差连接的 mixing matrices 完全 unconstrained。结果:信号通过 100 层后被放大 3000 倍——梯度直接爆炸,训练崩溃。
这种”信号放大”在浅层模型上不显著(10-20 层下放大可能只是 2-3×),但在 100+ 层下指数级累积。对 1.6T 模型这是致命问题。
3.2 mHC:用 Birkhoff Polytope 约束 mixing matrices
mHC 的解法是给 hyper-connection 的 mixing matrices 加上严格的数学约束:
强制 mixing matrices 落在 Birkhoff Polytope(双随机矩阵的凸包)上,用 Sinkhorn-Knopp 算法做投影。
具体地:
- Birkhoff Polytope:所有元素非负、每行和每列都为 1 的方阵的凸包。直观地,这种矩阵保证”输入信号既不放大也不缩小”——每个分量是输入分量的凸组合
- Sinkhorn-Knopp 算法:把任意非负矩阵迭代地”归一化”到 Birkhoff Polytope 上的最近点。每次前向计算中做一次 Sinkhorn-Knopp 投影
mHC 的数学保证:经过 100+ layer 后,信号放大被限制在 1.6× 以内——远小于 unconstrained hyper-connections 的 3000×。

3.3 mHC 的训练稳定性收益
mHC 不仅防止爆炸,还带来三个连带好处:
- 可以训练更深的网络:100+ layer 在过去基本不可行(GPT-4 估计也只有 96 layer),mHC 让 V4 的更深架构成为现实
- 可以用更大学习率:信号不爆炸意味着可以更激进地优化,加速收敛
- 与 FP4 量化兼容:mHC 控制信号范围让 FP4 量化(极窄数值范围)不会立刻被 outlier 击穿
mHC 是 V4 能 scale 到 1.6T 参数的结构性保证。没有 mHC,1.6T 模型的训练会以指数级概率失败。
四、核心创新三:Muon 优化器
V4 抛弃了用了多年的 AdamW,转用 Muon 优化器——这是大模型优化器选择上的一次重要范式转变。
4.1 AdamW 在大模型训练上的局限
AdamW 是过去 5 年大模型训练的默认选择,但它有几个累积问题:
- 二阶 moment 估计耗内存:AdamW 需要存
m(一阶 moment)和v(二阶 moment),加倍 optimizer state 显存 - 对 batch size 与 learning rate 选择敏感:超参 search 空间大
- 在 trillion-param 模型上收敛慢:经验上 AdamW 在 1T+ 模型上需要更长 warmup
4.2 Muon 优化器的核心思路
Muon 是 2024 年提出的优化器(Jordan et al., arXiv:2410.10840),核心思路是:
对矩阵参数做 Newton-Schulz orthogonalization——把梯度更新方向投影到 orthogonal matrix space 上。
直观地:
- AdamW 用 element-wise scaling 适应每个参数的梯度大小
- Muon 用 matrix-level orthogonalization 让更新方向保持几何结构
Muon 的好处在大模型上特别显著:
- 收敛更快:实验显示 Muon 比 AdamW 快 30-50%(达到同等 loss 所需 step 数)
- 优化器 state 更省:不需要存二阶 moment
- 对 batch size 不敏感:更容易在大 batch 上 scale
4.3 Muon 在 V4 中的应用
V4 把 Muon 应用到绝大多数参数(attention weights、FFN weights、MoE expert weights)。少数特殊参数(embedding、LayerNorm scale)仍用 AdamW。
实际效果:
- 训练 throughput:Muon 让 V4 的 wall-clock 训练速度比假设用 AdamW 快约 35%
- 显存节省:Muon 不存
v二阶 moment,显存约省 25%
Muon 是 V4 训练成本控制的关键之一——配合 mHC 提供的稳定性,V4 可以用更大学习率 + 更短训练 schedule 完成 32T tokens。
业界 Muon 跟进:V4 之后,OpenAI 与 Anthropic 都被传开始尝试 Muon。可以预期 2026 年下半年 Muon 会逐步替代 AdamW 成为大模型默认优化器。
五、核心创新四:FP4 量化训练
V4 在 V3 (W12) FP8 训练的基础上进一步把部分参数压到 FP4——开源大模型第一次在 trillion-param 规模成功的 FP4 训练。
5.1 FP4 的极致挑战
FP4 只有 4 比特,数值范围非常窄(典型 E2M1 格式只能表示 [-6, +6] 左右)。在大模型训练中,绝大部分激活和权重都会超出这个范围——直接量化必然崩溃。
V3 (W12) 的 FP8 训练用了 fine-grained quantization(per-block scaling)才稳住。V4 在 FP4 上必须做更激进的工程优化。
5.2 V4 的 FP4 策略:仅量化 expert 权重
V4 的关键选择是 FP4 量化只用于 MoE expert 权重,而不是全模型:
- Expert 权重:FP4(Quantization-Aware Training, QAT)
- Router、shared expert、attention、embedding、LayerNorm:仍用 FP8
- Activation 与 gradient:仍用 BF16/FP8
为什么仅量化 expert?因为:
- Expert 占总参数的 ~85%:1.6T 模型里大约 1.36T 是 routed expert weight,量化它们带来最大的显存节省
- 每个 expert 处理的 token 少:MoE 的 Top-K 路由让每个 expert 实际处理的 token 是 (K/N) 比例。Expert 的激活 outlier 相对集中,更容易做 QAT
- Expert specialization 容忍 4-bit 精度:W3 DeepSeekMoE / W9 ESFT 已经证明 expert 高度特化——每个 expert 学的是窄子集,对精度需求较低
5.3 QAT 训练流程
V4 的 QAT 流程:
- Warm-up:用 FP8 训练前 10% tokens(约 3T)让模型初步收敛
- QAT introduction:开始模拟 FP4 量化(forward 时模拟 FP4 误差,backward 时仍 FP8 gradient)
- Full QAT:所有 expert 权重都用 FP4 forward,正常 backward
- Fine-tune:最后 1-2T tokens 做 QAT 微调让模型适应 FP4 量化误差
最终:
- Expert 权重显存:相对 FP8 砍 50%(FP4 占用是 FP8 的一半)
- 总训练显存:节省 ~35%(因为 expert 占 85% 但其他参数仍是 FP8/BF16)
- 模型性能:相对全 FP8 训练损失 <0.5%
FP4 让 V4 在 1.6T 规模仍然可以在相对适中的 GPU 集群上训练完成。
六、训练 pipeline 与成本
6.1 训练数据:32T tokens
V4 训练在 32T tokens 上完成,相对 V3 的 14.8T 是 2.16×。数据来源:
- 通用文本:~60%(中英为主,扩展到 30 多种语言)
- 代码:~17%(继承 Coder 系列)
- 数学 + 推理:~13%(继承 Math / R1 / Math-V2 系列)
- 多模态文本-图像对:~5%(多模态预训练 seed)
- agentic 数据:~5%(tool use、planning、reasoning trajectory)
最后一类”agentic 数据”是 V4 的新增维度——专门为 V4 的 agentic 能力准备的训练样本,包括 long-horizon tool calling、multi-step planning trace、tool error recovery 等。
6.2 训练流程
V4 训练完整流程:
| 阶段 | 训练 tokens | 主要目标 |
|---|---|---|
| Stage 1: Pre-training (FP8) | 3T | warm-up + 模型基本能力 |
| Stage 2: Pre-training (FP8 + QAT) | 27T | 主要 pretraining + QAT 收敛 |
| Stage 3: Pre-training fine-tune (FP4) | 2T | QAT final convergence |
| Stage 4: Long context (1M) | ~400B | 上下文扩展 |
| Stage 5: SFT | ~500K samples | instruction following |
| Stage 6: GRM-based RL | continuous | reasoning + alignment |
注意 Stage 6 用的是 W17 详解的 DeepSeek-GRM 作为 reward model——V4 的 RL 训练完全建立在 GRM 之上。
6.3 训练成本估算
V4 官方未公布完整训练成本,但根据公开技术细节可以估算:
- GPU hours:约 7-9M H800 hours(V3 是 2.79M)
- 估算成本:约 $14-18M USD(V3 是 $5.58M)
成本翻 3 倍但模型规模 2.4×、训练 tokens 2.16×、上下文 7.8× 同时升级——单位 token 训练成本反而低于 V3。这是 Muon + mHC + FP4 + Hybrid Attention 四项创新累积的成本控制。
相对同期闭源 frontier 模型(GPT-5.5 估计 $200M+、Claude Opus 4.6 估计 $150M+),V4-Pro 的 $14-18M 成本仍然是 1/10 量级。
七、评测全景:SWE-bench 80.6% 与同期 frontier 对齐
7.1 综合能力
V4-Pro 在 2026-04 发布时的主流 benchmark:
| Benchmark | DeepSeek V4-Pro | Claude Opus 4.6 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| MMLU-Pro | 89.5 | 89.0 | 90.2 | 89.3 |
| GPQA-Diamond | 79.1 | 81.0 | 80.5 | 78.5 |
| MATH-500 | 98.5 | 96.0 | 97.5 | 98.0 |
| AIME 2025 | 88.0 | 80.3 | 85.0 | 86.5 |
| HumanEval | 94.5 | 95.5 | 96.0 | 94.0 |
| SWE-bench Verified | 80.6 | 82.0 | 79.8 | 81.5 |
| LiveCodeBench | 68.5 | 70.0 | 67.5 | 69.0 |
V4-Pro 在大多数 benchmark 上与三个闭源旗舰处于±2% 范围内。在数学(AIME 88.0 vs 80-86)上有明显优势——继承自 W15 Math-V2 的 self-verifiable reasoning 方法论。
7.2 SWE-bench Verified:agentic coding 的标志性指标
SWE-bench Verified 是 2025-2026 年 frontier 模型最重要的 benchmark——它测试模型是否能自主修复真实 GitHub repository 中的 bug:
- 输入:完整 repo + issue 描述
- 模型必须 explore repo、定位 bug、写出 patch、跑测试验证
- Verified split 经过人工严格筛选,确保题目可解
这是真正的 agentic 任务——需要长上下文(看整个 repo)+ tool use(grep / read file / run tests)+ multi-step planning。
V4-Pro 的 80.6% 在 2026-04 是开源模型 SOTA,与 Claude Opus 4.6 (82.0) 仅差 1.4pt。这印证了 V4 训练数据中的”agentic 数据”投入——V4 是第一个真正 agentic-ready 的开源 LLM。
7.3 1M 上下文 NIAH
Needle-in-a-Haystack (NIAH) 测试模型在长上下文里精确定位单个事实。V4-Pro 在 1M 上下文 NIAH 上的表现:
| 上下文长度 | V4-Pro 命中率 | V3.2 命中率 |
|---|---|---|
| 128K | 99.5% | 97.0% |
| 256K | 99.1% | 不可用 |
| 512K | 97.5% | 不可用 |
| 1M | 94.2% | 不可用 |
V4-Pro 让 1M 上下文从”理论可行”变成”94%+ 准确率的实用工具”。这是 Hybrid Attention 设计的最直接成果。
7.4 V4-Flash 也非常有竞争力
V4-Flash 虽然规模只有 V4-Pro 的 18%,但定位非常清晰——便宜 + 快 + 仍然能跑 reasoning:
| Benchmark | V4-Flash | GPT-5.5-mini | Claude Haiku 4.5 |
|---|---|---|---|
| MMLU-Pro | 81.5 | 80.0 | 82.0 |
| MATH-500 | 92.0 | 88.0 | 89.5 |
| HumanEval | 88.0 | 86.5 | 87.0 |
| SWE-bench Verified | 64.5 | 60.0 | 63.5 |
| API input price | $0.14/M | $0.40/M | $1.50/M |
V4-Flash 在所有 reasoning benchmark 上超过 GPT-5.5-mini 与 Claude Haiku 4.5,价格只是它们的 10-35%。这让 V4-Flash 成为 mid-range 市场的真正威胁。
八、V4 是整个系列的总集成
V4 不是某一个单点突破——而是 DeepSeek 自 2024-01 以来 16 篇技术论文 + 12 个月研发积累的”产品级总输出”。
8.1 V4 的”系列拼图表”
每一项 V4 的能力都对应系列中前面某篇论文的方法论:
| V4 的能力 | 方法论来源 |
|---|---|
| 1.6T 总参 / 49B 激活 MoE 架构 | W3 DeepSeekMoE(fine-grained + shared expert)+ W10 Aux-Loss-Free |
| KV cache 经济性 | W7 V2/MLA(latent 压缩 + decoupled RoPE) |
| Long-CoT reasoning | W13 R1(纯 RL + Aha Moment) |
| 数学竞赛金牌水位 | W15 Math-V2(Self-Verifiable Reasoning) |
| 1M 长上下文 | W14 NSA + W16 V3.2/DSA(Sparse Attention 演化) |
| CSA + HCA Hybrid Attention | 本文 V4(W14 + W16 的延续与升级) |
| Agentic / tool use | W8 Prover V1.5 + W17 GRM(reward modeling + multi-step planning) |
| 多模态文本-图像 | W6 DeepSeek-VL + W11 Janus(Hybrid Vision + Decoupled Encoder) |
| Code 能力 | W4 DeepSeek-Coder(repo-level training + FIM) |
| 训练成本控制 | W12 V3(MTP + FP8 + DualPipe)+ 本文(Muon + FP4) |
| Reward Model | W17 GRM(SPCT + Meta RM) |
| MoE task adaptation | W9 ESFT(task-relevant expert fine-tuning) |
| RL alignment | W5 DeepSeekMath(GRPO) |
可以看到 V4 的每一个能力维度都有前 16 篇论文的具体技术作为支撑。这是真正意义上的”集大成”——V4 是这 16 项技术的工程整合。
8.2 DeepSeek 的方法论标签
回顾整个系列,DeepSeek 团队展示了几个稳定的方法论标签:
标签一:架构保守 + 数据/训练激进
DeepSeek 极少引入新模型架构(Transformer 始终是核心),但在数据组织(W4 repo-level、W5 fastText、W15 self-verifiable)、训练算法(W5 GRPO、W10 Aux-Loss-Free)、硬件优化(W12 FP8 / DualPipe、本文 FP4 / Muon)上极度激进。
标签二:识别隐性 trade-off → 结构性解耦
W3 (fine-grained + shared)、W6 (SigLIP + SAM)、W7 (content + RoPE)、W10 (bias + affinity)、W11 (understand encoder + generate encoder) 都是同一种方法论——把一个组件需要同时承担的多个目标,拆到不同组件上各自优化。
标签三:合成数据 + bootstrap 循环
W5 (fastText 迭代)、W8 Prover (autoformalize)、W15 Math-V2 (generator-verifier co-evolution)、W17 GRM (iterative critique synthesis) 都用同一种思路——用模型生成数据训练模型,每轮迭代让数据 + 模型同时变强。
标签四:每代旗舰前先用小论文验证方法论
V3 之前有 W2-W11 共 10 篇 supporting paper;V4 之前有 W12-W17 共 6 篇 prelude。DeepSeek 从不”突然”发布旗舰——每次都是先发表方法论 paper、在小规模验证、再整合到大模型。
标签五:开源 + 公开 + 协议宽松
DeepSeek 历来开源全部权重(MIT 协议)+ 公开完整训练细节。这种”完全透明”的开源策略对整个行业格局影响深远——它让”frontier model 无法被复刻”的护城河叙事彻底破产。
8.3 DeepSeek 的产业贡献
回顾 2024-01 到 2026-04 这 28 个月,DeepSeek 对 AI 行业的具体贡献:
- 重新定义”大模型经济性”:V3 的 $5.58M 成本、V4 的 1M 上下文 27% FLOPs,把 frontier 模型的成本曲线降低一个数量级
- 打通”开源对齐闭源”路径:R1 (W13) 首次让开源模型在 reasoning 上对齐 OpenAI o1,V4 进一步对齐 Opus / GPT-5.5
- 重新定义”reasoning model 训练”:GRPO (W5)、R1 (W13)、Math-V2 (W15)、GRM (W17) 让 reasoning RL 训练方法论完全公开
- 重新定义”长上下文”经济性:MLA + NSA + DSA + CSA/HCA 让 1M-token reasoning 成为产品级现实
- 教育整整一代 AI 研究者:DeepSeek 系列论文是 2024-2026 年 AI 工程师的”标准教材”
这些贡献加起来让 DeepSeek 成为继 OpenAI 之后对 AI 行业方向最有影响力的研究团队——而且是以完全开源的方式做到的。
九、局限与未来
V4 是迄今最强的开源 LLM 之一,但仍有几个明显局限:
- agentic 能力仍弱于 Claude Opus 4.6:在最难的 agentic benchmark(如 GAIA Level 3)上 V4-Pro 仍落后 ~3-5 个百分点
- 多模态融合还在初级阶段:V4 主要还是文本模型,图像 / 视频处理需要外接 VL2 / Janus-Pro
- 训练数据透明度有所下降:相对 V3 的 14.8T 数据描述,V4 对 32T tokens 的具体来源披露较少
- mHC 的理论分析未公开:Sinkhorn-Knopp 在 100+ layer 网络上的收敛性 / 稳定性需要更多学术分析
- API 服务的实际 latency:1M 上下文推理仍然慢,企业用户在生产场景里需要权衡
V4 之后的方向猜测
V4 之后 DeepSeek 可能的下一步:
- V5 / V4.5:进一步 scale 到 3-5T 参数,可能引入新的 hybrid attention 设计
- 专项 reasoning 模型 R2:基于 V4 做 reasoning specialist,可能进入 IMO 2026 金牌之上
- 多模态融合旗舰:把 Janus 与 V4 的能力融合,做开源版 Gemini 风格的”原生多模态”
- Agentic Specialist:专门的 agentic 模型,进一步优化 long-horizon tool use
这些都是 2026 下半年到 2027 年的可能方向。
十、系列收官:DeepSeek 论文专题的 17 篇里程碑
到本文为止,DeepSeek 论文专题系列已经完整覆盖了从 2024-01 到 2026-04 的全部主要论文。让我们回顾整个系列:
| 期 | 论文 | 核心贡献 | 发布时间 |
|---|---|---|---|
| W1 | 序言:DeepSeek 技术路线图 | 系列结构与四主线 | 元论文 |
| W2 | DeepSeek LLM | 67B Dense + 数据 pipeline + 数据质量改变最优 Scaling 分配 | 2024-01 |
| W3 | DeepSeekMoE | Fine-grained + Shared Expert(MoE 架构骨架) | 2024-01 |
| W4 | DeepSeek-Coder | Repo-level + FIM 双模训练 | 2024-01 |
| W5 | DeepSeekMath | GRPO 算法 + 120B 数学语料 pipeline | 2024-02 |
| W6 | DeepSeek-VL | Hybrid Vision Encoder + 三阶段训练 | 2024-03 |
| W7 | DeepSeek-V2 / MLA | Latent KV 压缩 + decoupled RoPE | 2024-05 |
| W8 | DeepSeek-Prover V1+V1.5 | Lean 4 形式证明 + RLPAF + RMaxTS | 2024-05/08 |
| W9 | ESFT | Expert-Specialized Fine-Tuning | 2024-07 |
| W10 | Auxiliary-Loss-Free | Bias-based load balancing | 2024-08 |
| W11 | Janus V1+Pro | 解耦视觉理解与生成 | 2024-10 / 2025-01 |
| W12 | DeepSeek-V3 | 671B MoE + MTP + FP8 + DualPipe,$5.58M 训练 | 2024-12 |
| W13 | DeepSeek-R1 | 纯 RL + Aha Moment + 四阶段 pipeline | 2025-01 |
| W14 | NSA | Hardware-aligned native sparse attention | 2025-02 |
| W15 | DeepSeekMath-V2 | Self-Verifiable Reasoning + IMO gold | 2025-11 |
| W16 | DeepSeek-V3.2 | Lightning Indexer + Fine-grained Selection | 2025-12 |
| W17 | DeepSeek-GRM | SPCT + Meta RM | 2025-04 |
| W18 | DeepSeek-V4(本文) | 总集成旗舰 | 2026-04 |
17 篇文章、约 24 万字、约 50 张原创概念图——构成了 2024-2026 年开源 AI 浪潮最完整的中文方法论档案。
写在系列最后
DeepSeek 团队用 28 个月的时间,从一个相对陌生的开源团队(”DeepSeek-LLM 67B”在 2024-01 发布时业界几乎没人关注),成长为与 OpenAI / Anthropic / Google 平起平坐的 frontier AI lab。这个旅程的方法论非常清晰:
- 架构保守:始终用 Transformer + MoE,没有追逐 Mamba / SSM / 各种”颠覆性架构”
- 数据与训练激进:fastText 挖语料、autoformalize 合成证明、generator-verifier co-evolution、SPCT
- 工程极度精细:MLA、Aux-Loss-Free、FP8、DualPipe、CSA/HCA、Muon、FP4
- 完全开源:每一篇论文 + 每一个模型权重 + 每一个工程细节都公开
这套打法给整个 AI 行业上了一课——frontier model 不需要 GPT-4o 那样的 $200M 训练费 + 闭源护城河;用更精细的工程 + 完全开源 + 28 个月迭代,就能从零做到 frontier。
如果你是 AI 工程师、研究者、产品经理或对前沿 LLM 感兴趣的读者,希望这 17 篇文章给你提供了完整的、自洽的、可执行的 DeepSeek 方法论地图。
整个系列到此完整收官。
参考资料
- DeepSeek-AI, DeepSeek-V4 Technical Report, 2026 (技术报告与 Hugging Face 权重均已公开).
- DeepSeek-V4 GitHub repository:
- Jordan et al., Muon: An Optimizer for Hidden Layers in Neural Networks, arXiv:2410.10840, 2024.
- DeepSeek-AI, DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models, arXiv:2512.02556, 2025.
- Yuan et al., Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, arXiv:2502.11089, 2025.
- DeepSeek-AI, DeepSeek-V3 Technical Report, arXiv:2412.19437, 2024.
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv:2501.12948, 2025.
- DeepSeek-AI, Inference-Time Scaling for Generalist Reward Modeling, arXiv:2504.02495, 2025.
- DeepSeek-AI, DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning, arXiv:2511.22570, 2025.
- Wang et al., Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, arXiv:2408.15664, 2024.
- Dai et al., DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, arXiv:2401.06066, 2024.
![]()
2026-06-01 at 4:52 下午
关于 mHC 想请教一下:Birkhoff Polytope 是双随机矩阵的凸包,Sinkhorn-Knopp 投影本身是迭代算法,每次 forward 都跑一遍迭代会不会引入额外的 wall-clock 开销?文章说收敛性”未公开”,那实际训练里 Sinkhorn 迭代几步就截断?这个截断会不会破坏双随机性从而让 3000×→1.6× 的保证失效?
2026-06-03 at 10:53 上午
好问题。公开信息里没给迭代步数,我推测是固定少步数(3-5 步)近似,所以才说理论分析”未公开”。严格双随机只能保证放大≈1,近似下 1.6× 应该就是截断误差的体现。