
Qwen 论文专题系列第二篇——回到 2023-08 那篇被 LLaMA-2 完全盖过风头的 Qwen-1 技术报告(arXiv:2309.16609),把通义实验室在第一次发版时做的四个关键工程取舍逐个拆开:Untied Embeddings、151K 双语 BPE tokenizer(中文 2× 压缩)、RoPE base 从 1e4 拉到 1e6、Long-context 三件套(NTK-aware + LogN-scaling + Windowed Attention)。两年后回头看,这些「非主流」选择正是 Qwen 主线整套工程哲学的奠基。
![]()
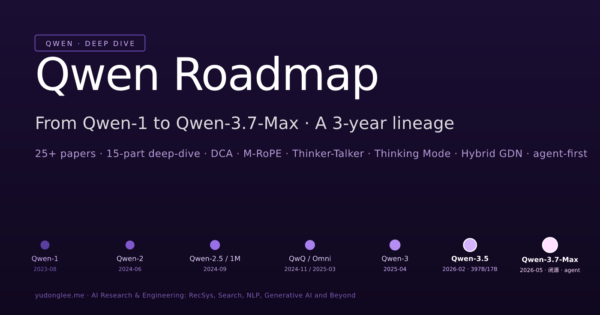
Qwen 论文专题系列序章 —— 把通义实验室 2023-08 → 2026 全部 Qwen 主线 + 6 大专项分支 paper 按「三代主线 + 多模态/Coder/Math/QwQ 分支」梳理成完整脉络,串讲 GQA 全 size 化、Dual Chunk Attention、M-RoPE / TMRoPE、Built-in Thinking Mode、Thinker-Talker 五大核心创新,并对比 Qwen 与 DeepSeek 两条中国开源 LLM 路径。
![]()

DeepSeek-V4 详解(系列收官):1.6T MoE 旗舰(V4-Pro)+ 284B Flash 双模型,1M 上下文,SWE-bench Verified 80.6% 对齐 Claude Opus 4.6。四大创新:(1) CSA+HCA Hybrid Attention 让 1M 上下文 cost 仅 V3.2 的 27%/10%;(2) mHC 用 Birkhoff Polytope 让 100+ layer 信号放大从 3000× 压到 1.6×;(3) Muon 优化器替代 AdamW;(4) FP4 expert 量化训练。32T tokens 训练,估计成本 $14-18M(GPT-5.5 的 1/10)。同时作为 DeepSeek 系列 17 篇文章的总收官。
![]()

DeepSeek-GRM (arXiv:2504.02495) 详解:V4 之前的关键 reward modeling 准备工作。提出 SPCT (Self-Principled Critique Tuning) + Pointwise GRM 架构 + Meta RM 投票,让 reward model 本身具备推理时 scaling 能力。在 RewardBench 上达到 89.6 分(K=32 推理采样),超过 GPT-4o judge 与 Claude-3.5-Sonnet judge。同时简略提及 Prover-V2、R1-0528、OCR 等 V4 prelude 工作。
![]()

DeepSeek-V3.2 (arXiv:2512.02556) 详解:把 W14 NSA 的稀疏注意力思想简化为 DSA (DeepSeek Sparse Attention) 落地到产品级 685B 模型。DSA = Lightning Indexer(小 attention 头 + FP8 快速预筛)+ Fine-grained Token Selection(Top-K=2048 精细 attention)。让 V3.1 → V3.2 在 128K 上下文下推理速度提升 2-3×、显存降 30-40%,API 价格再砍一半。同时简略介绍同期的 DeepSeek-OCR 光学上下文压缩。
![]()

DeepSeekMath-V2 (arXiv:2511.22570) 详解:把 reasoning 从 R1 的 outcome-based RL 推进到 process-aware RL。Generator-Verifier 双 685B 模型对抗式协同——verifier 给 generator 的每一步证明打分,generator 学会自我修正。在 IMO 2025 / CMO 2024 上获金牌、Putnam 2024 拿到 118/120(人类最高分仅 90),是开源数学推理模型第一次明确达到顶尖数学竞赛 gold 水位。
![]()
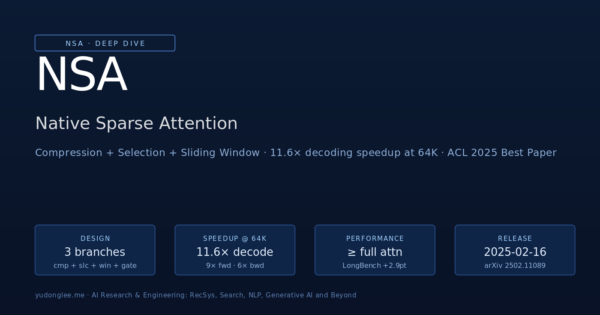
NSA (Native Sparse Attention, arXiv:2502.11089) 详解:ACL 2025 Best Paper。三分支稀疏注意力——Compression(粗粒度块压缩)+ Selection(Top-K 块精细 attention)+ Sliding Window(局部窗口)+ learned gating。Hardware-aligned + Natively trainable 设计让 64K 序列 decoding 速度提升 11.6×,长上下文 benchmark 上反而比 dense full attention 略好。NSA 是 V3.2 / V4 把上下文扩到百万 token 的核心架构。
![]()

DeepSeek-R1 (arXiv:2501.12948) 详解:(1) R1-Zero 用纯 RL 从 V3-Base 训出 reasoning 能力——首次实证证明无需 SFT 的可行性,并观察到 Aha Moment 等元认知行为;(2) R1 用四阶段 pipeline(cold-start SFT → reasoning RL → general SFT → all-scenario RL)输出 production-quality 模型,在 AIME 2024 / MATH-500 / Codeforces 上对齐 OpenAI o1。同时发布 1.5B-70B 的 Distill 系列。引爆 2025-01-27 DeepSeek Moment。
![]()

DeepSeek-V3 (arXiv:2412.19437) 详解:671B 总参 / 37B 激活的 MoE 旗舰,14.8T tokens 预训练,仅用 2.788M H800 GPU hours、558 万美元训练完成,全面对齐 GPT-4o。系统拆解 V3 的五项创新——MLA + DeepSeekMoE + Aux-Loss-Free 架构三件套、Multi-Token Prediction、FP8 混合精度、DualPipe 流水线、Node-Limited Routing——以及它们如何协同支撑 V3 的 cost/performance 曲线。
![]()

Janus(arXiv:2410.13848)与 Janus-Pro(arXiv:2501.17811)详解:把视觉理解与生成的编码路径完全解耦——SigLIP 抽取语义服务理解,VQ tokenizer 离散化像素服务生成。Janus-Pro-7B 在 GenEval 上拿到 80%,超过 DALL-E 3 与 SD3,同时在多模态理解 benchmark 上接近 Qwen2-VL。
![]()

Auxiliary-Loss-Free (arXiv:2408.15664) 详解:用 expert-wise bias + 规则式更新替代传统 auxiliary balance loss,消除干扰梯度对主任务训练的污染。balance 与 specialization 通过 bias 与 affinity 解耦。V3 训练全面采纳。
![]()

ESFT (Expert-Specialized Fine-Tuning, arXiv:2407.01906) 详解:基于 MoE 模型在下游任务上 expert 激活的天然稀疏性,只 fine-tune 任务相关的少数 expert,5-25% 可训练参数即可匹配 Full FT 性能,明显优于 LoRA。
![]()

DeepSeek-Prover V1(arXiv:2405.14333)与 V1.5(arXiv:2408.08152)详解:autoformalization 合成数据 + RLPAF + RMaxTS 蒙特卡洛树搜索,把 7B 模型在 Lean 4 形式化证明 benchmark miniF2F 上推到 63.5%,并为后续 R1 reasoning 训练提供方法论起点。
![]()

DeepSeek-V2(arXiv:2405.04434)详解:首次提出 MLA (Multi-head Latent Attention) 通过低秩 latent 压缩 + decoupled RoPE + matrix absorption 把 KV cache 砍到 MHA 的 1.76%;236B 总参 / 21B 激活的 MoE 实现 5.76× 吞吐于 67B Dense。
![]()

DeepSeek-VL(arXiv:2403.05525)详解:Hybrid Vision Encoder(SigLIP-L + SAM-B 双流编码)+ Real-world 数据策略 + 三阶段训练 pipeline,让 7B 多模态模型在 MMBench 上达到开源 SOTA,同时几乎不退化语言能力。
![]()

DeepSeekMath(arXiv:2402.03300)详解:120B 数学语料 + GRPO 算法 + 三阶段训练管线,7B 模型在 MATH 上接近 GPT-4 当时水位,并定义了后来 R1 系列的 RL 训练范式。
![]()

DeepSeek-Coder(arXiv:2401.14196)详解:从 file-level 升级到 repo-level 训练 + 拓扑排序、FIM 双模混合 (50% PSM + NTP)、16K 长上下文,让 6.7B 模型在 HumanEval / MBPP 上追平 CodeLlama-34B。
![]()

转载本文请注明出处:https://yudonglee.me/deepseekm… Continue Reading →
![]()

转载本文请注明出处:https://yudonglee.me/deepseek-… Continue Reading →
![]()

转载本文请注明出处:https://yudonglee.me/deepseek-… Continue Reading →
![]()