转载本文请注明出处:https://yudonglee.me/voiceagent-explained/ | 作者:yudonglee
📝 本文首发于 2025 年 12 月。最近一次修订于 2026 年 6 月:更新了框架对比与成本测算内容。
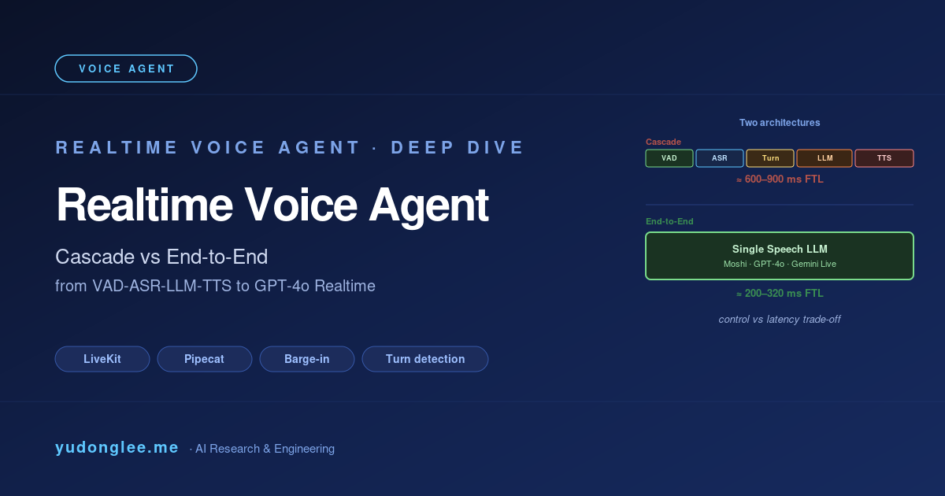
2024 年下半年是 Realtime Voice Agent 真正进入主流的元年——OpenAI 在 10 月开放 Realtime API、Google 推出 Gemini Live、字节火山引擎与阿里通义都跟进了同类产品。一夜之间「用语音和 AI 自然对话」从产品 demo 变成了真实的商业能力。但要在生产环境跑起来一个 voice agent,工程上的坑远比看起来多:怎么把首字延迟压到 500 ms 以下?用户中途打断怎么办?模型还没说完用户就抢着说话怎么办?要不要走端到端 Speech LLM 还是经典 VAD+ASR+LLM+TTS 级联?这些问题没有标准答案——每个业务场景都有自己的最优解。
本文是「语音技术深度系列」的第 15 篇,紧接 Speech LLM 综述,从工程视角彻底拆透 voice agent 的两种主流架构。读完你将能回答:
- 经典 VAD+ASR+LLM+TTS 五件套架构每个组件的延迟、错误率、可用开源选择?
- Turn detection(判定用户说完了)为什么这么难?2024 后的”语义 turn detection”模型是怎么 work 的?
- 用户中途打断(barge-in)这件看似简单的事,为什么会让经典级联架构崩溃?
- GPT-4o Realtime API、Moshi 全双工模型对比经典级联,分别有什么优势和代价?
- 2026 年做一个生产级 voice agent,应该选 LiveKit Agents / Pipecat / Vapi / Retell 还是自建?
1. 背景:voice agent 在 2024-2025 的爆发
「voice agent」这个词在 2024 年开始爆红。它的定义比”语音助手 (voice assistant)” 更具体——指的是能用自然语音双向对话、且能执行工具调用 / 完成业务流程的 AI 系统。代表场景包括:
- AI 客服:保险 / 银行 / 电信公司的电话外呼或接听 (Retell、Vapi);
- 语音 copilot:医生口述病历、开发者口述代码意图 (OpenAI Whisper + GPT-4 集成);
- 虚拟伴侣 / 情感 agent:Character.AI Voice、Pi (Inflection);
- 实时翻译 agent:阿里通义听悟、字节同传 4.0;
- 多模态硬件:Rabbit R1、Friend.com 项链、AI Pin。
这些场景都有一个共同的”用户体验门槛”:首字延迟 (First Token Latency, FTL) ≤ 500 ms、轮次切换 (turn-taking) 自然、能中途打断。Voice Agent 的全部工程挑战就是怎么在保证业务能力 (LLM 推理 + 工具调用 + 知识检索) 的同时,把这三个用户体验指标做到位。
2. 经典架构:VAD + ASR + LLM + TTS 五件套
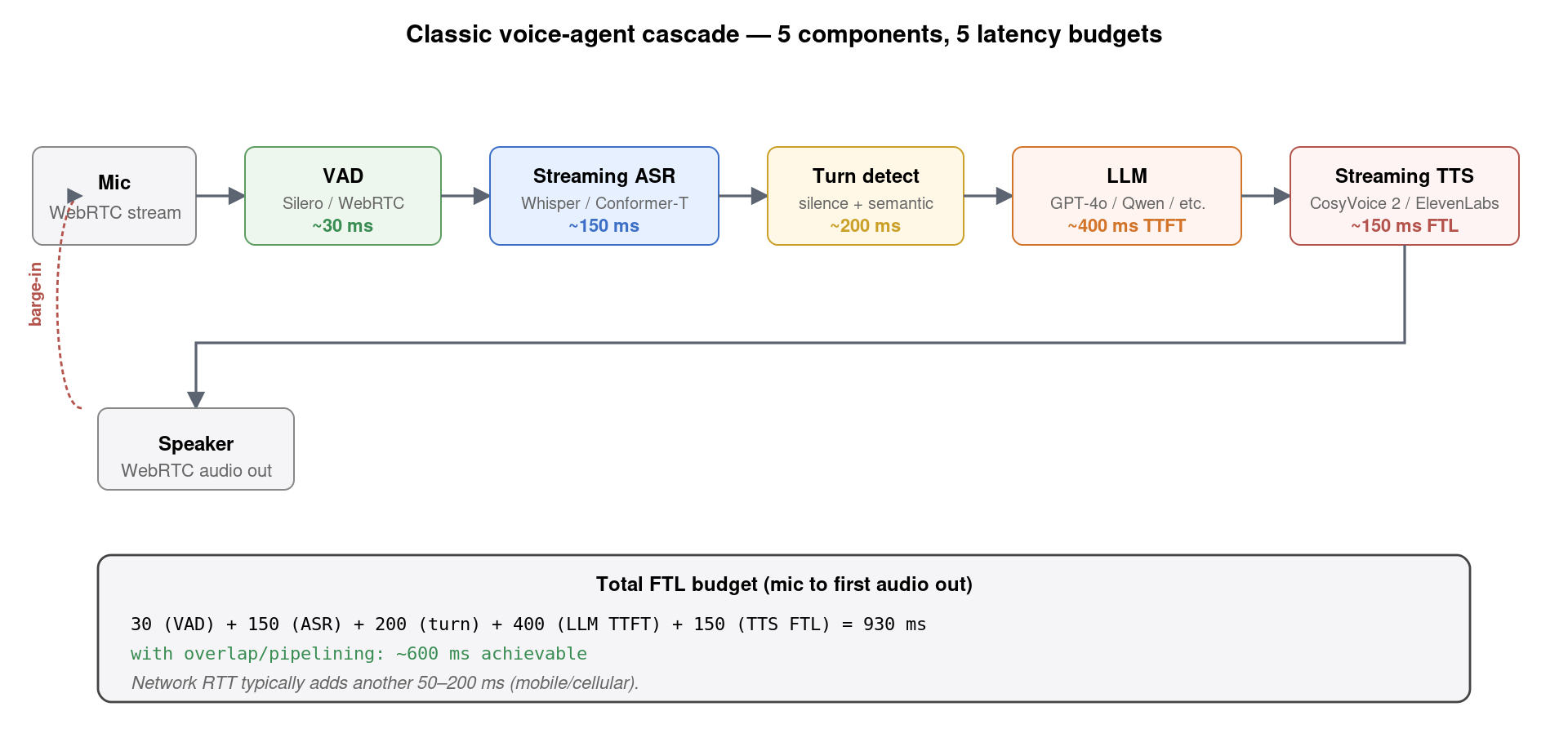
经典 voice agent 由五个独立模块串成一条数据流:
- VAD (Voice Activity Detection):从麦克风流中识别”用户在说话”。Silero VAD 是 2024 后事实标准——CPU 友好、误检率 < 1%、决策延迟 ~30 ms。WebRTC 自带的 VAD 太老不推荐。
- Streaming ASR:把语音流转成 partial text。可选 streaming Conformer-Transducer(WeNet / icefall)、faster-whisper 流式版、或商业 API (Deepgram、Azure、阿里 Paraformer)。FTL 80-200 ms。
- Turn Detection:判定”用户说完了一句话,该 LLM 接话了”。这看似简单实则极难——纯静音阈值会被自然停顿误判,必须结合语义。后面单独展开。
- LLM:吃 ASR 输出的文本,配合 system prompt、对话历史、工具定义等,吐出回复文本。Time-To-First-Token (TTFT) 是关键指标——GPT-4o ~400 ms、GPT-4o mini ~200 ms、Qwen-Turbo ~150 ms。
- Streaming TTS:把 LLM 流式 token 转成流式音频。CosyVoice 2 / F5-TTS / ElevenLabs Streaming,FTL ~150 ms。
整体首字延迟预算 = 30 (VAD) + 150 (ASR) + 200 (turn) + 400 (LLM TTFT) + 150 (TTS FTL) = 930 ms。这是串行执行下的理论上限。通过 pipelining(LLM 还在生成时 TTS 就开始合成、用户还在说话时 ASR 就在转录)实际能压到 ~600 ms。这是经典级联架构的物理极限——再加上 50-200 ms 网络 RTT,跨网用户体验约 700-800 ms FTL。
3. Turn Detection:被严重低估的难题
「用户说完了吗?」这件事看似简单——等用户停顿超过某阈值(比如 500 ms 静音)就触发。但这种纯 silence-based 方法在真实对话中错误百出:
- 用户说”今天天气…嗯…好像不错”——中间的”嗯”本是思考停顿,会被错误地判为说完,LLM 提前接话。
- 用户说”我想订一张…”——后面要等数秒才说完地名,但阈值短就抢话、阈值长又反应慢。
- 用户说”明天上午”——意图未完,但语调和停顿都像句末。
2024 后行业开始用语义 turn detection model——专门训练一个小型 BERT 或 Transformer,输入是当前的 partial ASR text,输出是「这句话是否结束」的二分类概率。LiveKit Agents 在 2024 年发布的 livekit-turn-detector-v0.2 模型只有 30M 参数,CPU 上推理 10 ms,准确率 95%+。Pipecat 也集成了类似机制。把 turn detection 从纯阈值升级为「semantic + 时长 + VAD 三路融合」是 2024 voice agent 工程的最大进步之一。
4. Interruption / Barge-in:经典架构的阿喀琉斯之踵
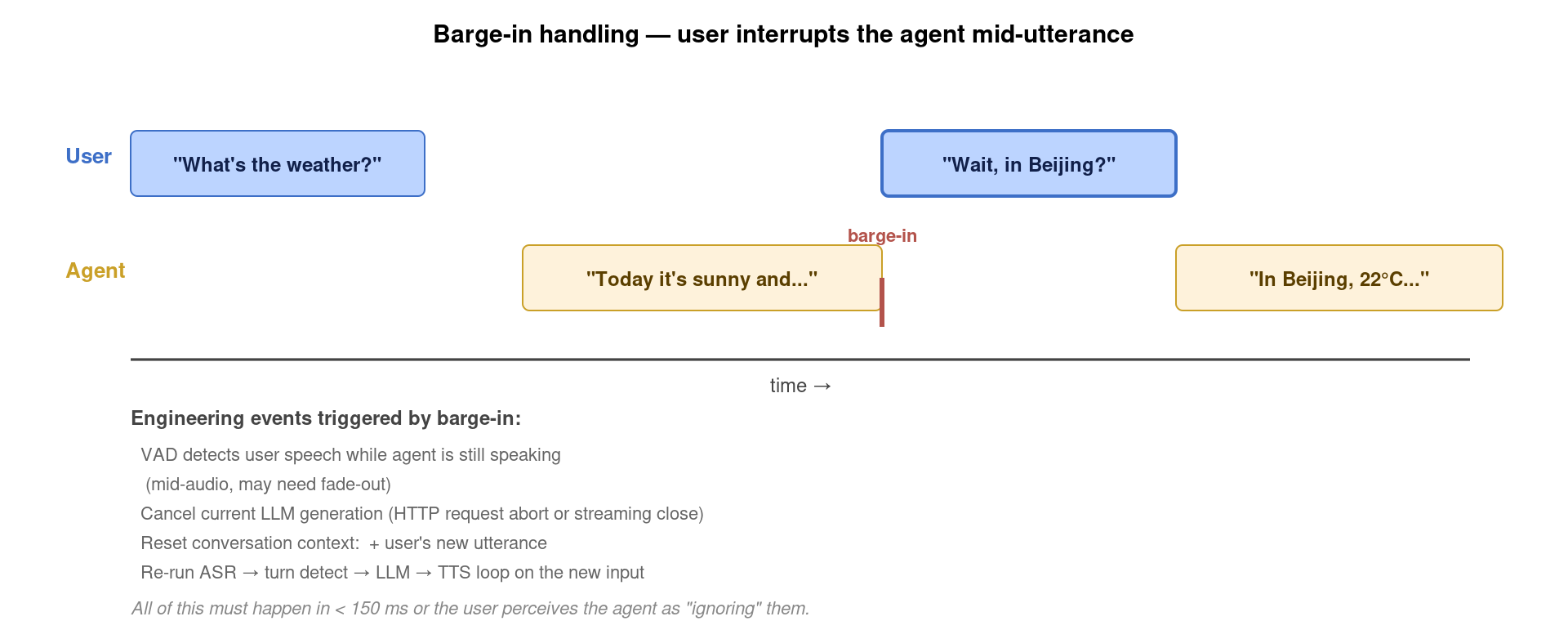
用户中途打断 (barge-in) 是 voice agent 体验的核心区分点——支持得好就像真人对话,支持得差就是”机器人感”满满的旧式 IVR。经典级联架构里处理 barge-in 需要协调 5 个独立组件的取消与状态恢复,工程复杂度极高:
- VAD 在 agent 还在说话时检测到用户开口;
- 立刻 cancel 当前 TTS 流(已经播出的音频要不要 fade-out?技术上要无缝切断);
- cancel 当前 LLM 流式生成(HTTP request abort 或 close streaming connection);
- 对话历史里要 append “agent 说到一半被打断” + “用户新发言”两条记录——这一步影响后续 LLM 上下文连贯性;
- 重新跑一遍 ASR → turn detect → LLM → TTS 全流程。
这一系列动作必须在 150 ms 内完成,否则用户会感觉”它没在听我说话”。LiveKit Agents、Pipecat、Vapi 等框架的核心价值正是把这些复杂的事件协调封装成简单 API——你写业务逻辑、它管 barge-in。这也是为什么 2024 年以来自建 voice agent 几乎都基于这几个框架而非从零做。
5. WebRTC:被忽略的工程基础
所有真实的 voice agent 都跑在 WebRTC 之上——它处理麦克风采集、回声消除、噪声抑制、丢包重传、jitter buffer 等”音频通信难题”。自己做这些事是工程灾难,但用 WebRTC 也有几个陷阱:
- 编解码选择。Opus 是 WebRTC 默认,6-32 kbps 可配。voice agent 推荐 16 kbps,对模型输入质量足够、带宽友好。
- 回声消除 (AEC)。如果 speaker 与 mic 在同一设备(如手机、笔记本扬声器+内置麦),agent 的输出音频会被 mic 捕捉到、再喂给 ASR,造成”agent 回路打断自己”。WebRTC 内置的 AEC 必须打开。
- jitter buffer。网络抖动会让音频包乱序到达。WebRTC 默认 jitter buffer 缓冲 20-100 ms,过大会增加端到端延迟。voice agent 建议设到 40 ms 左右平衡。
- connection quality 自适应。手机网络下,丢包率高时要降低音频质量保流畅。LiveKit 的 SDK 自动做这件事;自建系统要做 RTCP 监听 + 动态调整。
这些细节是 voice agent 工程的「下半身」——能不能做对决定稳定性,而不是显眼的”延迟数字”。但稳定性才是用户能不能持续使用的根本。
6. 端到端 Realtime API:经典架构的替代方案
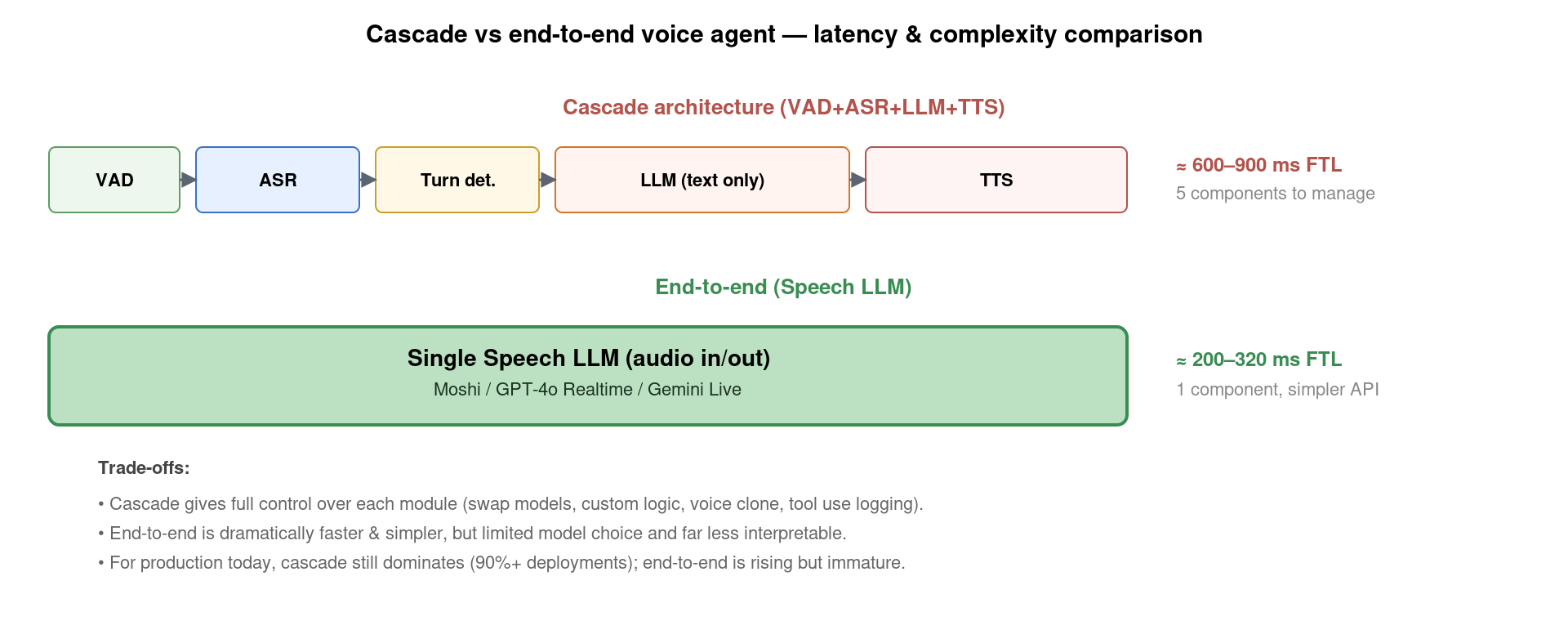
2024 年 10 月 OpenAI 发布 Realtime API——单一 WebSocket 接口直接吃 audio in、吐 audio out,内部由 GPT-4o 多模态模型完成 ASR / LLM / TTS 全流程。同时 Google Gemini Live、Kyutai Moshi 等开源端到端语音 LLM 也提供类似 API。这种端到端方案相比经典级联的优势:
- 延迟显著降低:从 600-900 ms 压到 200-320 ms(GPT-4o 平均 320 ms、Moshi 200 ms);
- 架构极简:1 个 API 替代 5 个组件,barge-in / turn detection 由模型内部处理,开发者不用管;
- 跨模态语义保留:经典 ASR 会把”语气、笑声、叹气”丢掉,端到端模型保留这些信号,LLM 能”听懂情感”;
- 表达力更强:端到端模型能输出唱歌、笑声、各种风格,TTS 模块永远做不到。
但它也有明显代价:
- 可控性差:你不能换 LLM 模型、不能用自家 voice clone、不能精细 log 中间状态;
- 价格昂贵:GPT-4o Realtime API 每分钟 ~$0.18,是 GPT-4o 文本 API 的 10 倍;
- 工具调用支持弱:Realtime API 虽支持 function calling 但模式不如纯文本成熟;
- 调试复杂:黑盒系统,出错难定位。
当下的现实是:85% 的生产 voice agent 仍跑在经典级联架构上——业务对可控性、价格、模型选择的需求超过对延迟的极致追求。端到端 Realtime 主要用在「需要表达情感 / 跨模态推理」的高价值场景,如情感陪伴、虚拟主播。
7. Moshi 全双工:经典与端到端之外的第三条路
Moshi 提供了一个有意思的中间方案——它同时承担”端到端能力 + 开源可控”两个属性。具体优势:
- 全双工架构(用户和模型可以同时说话、互相打断,不需要工程层处理 turn detection);
- 理论延迟 160 ms,实测 200 ms,超过 GPT-4o;
- 开源 + 自部署 + 7B 参数,能在单 L4 GPU 跑起来;
- 能识别用户的笑声、叹气、思考停顿(端到端模型的优势);
- 但工具调用、长上下文记忆等”agent 能力”还很弱,距离 GPT-4o 体验有差距。
Moshi 路线的意义是证明开源端到端 voice agent 在技术上可行——它让自建团队不必依赖 GPT-4o API 也能做出”接近真人对话”的体验。预计 2026 年会有更多类似 Moshi 的开源全双工模型涌现 (GLM-4-Voice、Step-Audio 已经走在这条路上)。
8. 主流 voice agent 框架对比
| 框架 | 开源 | 核心定位 | 典型用户 | 价格 (per minute) |
|---|---|---|---|---|
| LiveKit Agents | ✅ | WebRTC + voice agent SDK | 自建 voice agent 的工程团队 | 自部署免费 / 云版 ~$0.005 |
| Pipecat | ✅ | Python pipeline framework | 研究 / 原型开发 | 免费 |
| Vapi | ✗ | 商业 voice agent SaaS | 不想自建的中小团队 | ~$0.05 + 模型成本 |
| Retell | ✗ | 商业,主打电话外呼 | AI 客服 / 销售 | ~$0.07-0.10 |
| OpenAI Realtime API | ✗ | 端到端 API | 追求最低延迟体验的产品 | $0.06 input / $0.24 output (audio) |
| Daily Bots | ✅ | WebRTC + pipeline,类 LiveKit | 需要现成 voice agent infra | ~$0.01 |
选型建议:
- 想自建、要可控性 → LiveKit Agents(事实标准,社区活跃);
- 需要快速原型 → Pipecat(Python 友好);
- 不想自建但要稳定 → Vapi 或 Retell;
- 追求极致延迟和表达力 → OpenAI Realtime API,但准备好烧钱;
- 追求开源端到端 → Moshi 自部署,但能力还有差距。
9. 真实部署的几个深水坑
- 用户说话太快或太慢。Turn detection 模型通常在”中等语速”训练,应对极快语速(如吵架时)或极慢(如老人)容易出错。生产建议:暴露给业务方一个 turn-detection sensitivity 滑杆。
- 背景音乐 / 多人对话。VAD 会把背景音乐识别为语音、把第二人发言混入用户输入。对策:用 speaker separation(pyannote.audio)做前置处理,或用专门的”agent only listens to one speaker”模型。
- LLM 的”思考时间”。LLM 第一个 token 出来前的几百 ms 用户感觉”系统死了”。生产做法:在等待时插入“嗯…”、”let me think” 等”思考填充音”——CosyVoice 2 可以直接生成这些。这是大幅提升体验感的小技巧。
- 语音克隆的稳定性。客户希望”用某个特定人的声音”做 agent。3 秒克隆质量不够稳——同一段文本不同次生成可能音色漂移。生产建议:用 10-30 秒 prompt 或 fine-tune 一个固定 speaker model。
- 工具调用的延迟泄露。如果 LLM 要调一个外部 API(如查询数据库),这部分延迟会让用户感觉 agent 卡了。对策:在工具调用前先让 agent 说一句”我帮你查一下”,再异步执行;或用 streaming function calling 边查边说。
- 成本控制。一个完整 voice agent 通话每分钟成本结构:ASR ~$0.005 + LLM ~$0.02 + TTS ~$0.01 + WebRTC infra ~$0.005 = $0.04/min。如果用 Realtime API 直接是 $0.18/min。商业部署时要做好按分钟数监控与预算告警。
- 多语种切换。用户说一句中文一句英文、agent 该用哪个声音回?经典级联需要在 ASR 后做语种识别 + TTS 切换 voice,端到端模型自动处理但效果不稳。生产建议:先固定单语种,多语种是仍未完全解决的难题。
10. 2026 路线选型决策树
给你一份 2026 年生产 voice agent 选型决策:
- AI 电话客服 / 销售外呼(中文 / 英文,可控性强):LiveKit Agents + CosyVoice 2 (TTS) + Whisper / Paraformer (ASR) + GPT-4o-mini / Qwen-Turbo (LLM)。FTL ~600 ms,成本 ~$0.05/min。这是 90% 中文 AI 客服的事实标准。
- 情感陪伴 agent(要听懂笑声叹气、能唱歌):OpenAI Realtime API 或 Moshi 自部署。FTL ~250 ms,成本高但体验最好。
- 实时翻译 agent(同传场景):Whisper-Large-v3 + GPT-4o + ElevenLabs TTS,端到端 cascade。延迟可接受 1-2 s。
- 医疗 / 法律垂直域(专业词汇 / 强可控):垂直 fine-tune Whisper + 私有 LLM + 固定 TTS speaker。可控性 > 体验。
- 消费级 voice agent app(C 端产品):用 Realtime API 或商业 SaaS (Vapi / Retell)。开发速度 > 成本。
- 多模态 agent(同时看摄像头 + 听语音):Gemini Live API。
- 极致私有化部署(不能用 SaaS):LiveKit Agents 自部署 + 全开源组件栈。
11. 总结:voice agent 已经过了「能不能」阶段
2024 年之前的 voice agent 大多停留在”能不能做出来“的阶段——首字延迟 2-3 秒、不支持 barge-in、Turn detection 经常出错。2024 年中 OpenAI Realtime API、Moshi、LiveKit Agents 等同时成熟,让”能做出来 + 体验接近真人” 在工程上变得可行。2026 年的核心问题已经转向「怎么做得更便宜、更可控、更适合自己的业务」。
对从业者,2026 年做 voice agent 的最重要建议:
- 除非你做底层框架,否则不要自己造轮子——LiveKit Agents / Pipecat 已经把 VAD / WebRTC / barge-in / turn detection 这些坑全填了。
- 端到端 Realtime API 是高端选择,不是必选——除非业务确实需要情感识别、笑声合成,否则经典级联架构成本低 4-5 倍。
- turn detection 是 voice agent 体验的隐形分水岭——花时间用 livekit-turn-detector 或 Pipecat 内置 SmartTurn,体验提升立竿见影。
- 必须监控成本——voice agent 是按分钟计费的”吞金兽”,做好实时统计与告警。
- 2026 年这一切还会继续快速演化——开源端到端模型(Moshi、GLM-4-Voice)会继续追平 GPT-4o,框架会进一步降低门槛。保持关注 LiveKit、Kyutai、阿里 FunAudioLLM 等团队的发布。
这是我「语音技术深度系列」的第 15 篇,也是真正的系列收官篇。从 CTC、Whisper、RNN-T、Conformer、SSL、Streaming ASR 等 ASR 经典/前沿,到 TTS 史、VALL-E、CosyVoice 2、F5-TTS、Neural Codec 等 TTS 全栈,再到 Speech LLM 综述 与本文 Voice Agent 工程实战,15 篇完整覆盖端到端语音 AI 的算法、模型、架构、部署四个维度。如果你按顺序读完,应该已经具备 2026 年从业的全栈语音 AI 能力框架。
参考资料
- LiveKit Agents 文档与开源仓库:github.com/livekit/agents
- Pipecat 文档:docs.pipecat.ai
- Vapi 文档:docs.vapi.ai
- OpenAI Realtime API:platform.openai.com/docs/guides/realtime
- Google Gemini Live:ai.google.dev/gemini-api/docs/live
- Kyutai Moshi:github.com/kyutai-labs/moshi
- Silero VAD:github.com/snakers4/silero-vad
- WebRTC 标准:webrtc.org
- LiveKit turn-detector 模型:huggingface.co/livekit/turn-detector
![]()
2026-02-02 at 11:41 上午
“2026 年 85% 的生产 voice agent 仍跑在经典级联架构上”——这个 85% 的数字哪来的?