
转载本文请注明出处:https://yudonglee.me/ssl-speech-explained/ | 作者:yudonglee
📝 本文首发于 2025 年 3 月。最近一次修订于 2026 年 6 月:更新了与 Whisper 路线的选型对比。
NLP 在 2018 年通过 BERT 把「大规模无监督预训练 + 小规模监督微调」这条范式做成了,语音领域却晚了整整两年。直到 2020 年 6 月 Meta AI 发布 wav2vec 2.0,语音 ASR 才第一次有了「能用 10 分钟标注数据微调出可用模型」的工具。此后短短一年半内,HuBERT (Meta, 2021) 把训练目标从对比学习简化为掩码预测,WavLM (Microsoft, 2021) 把模型从 ASR 专用扩展到「全栈语音任务」——这三个模型构成了语音自监督学习 (Self-Supervised Learning, SSL) 的「三部曲」,2020–2024 年所有开源语音基础模型几乎都建立在它们的范式之上。
本文是 CTC 系列 → Whisper → RNN-T → Conformer 这条语音线索的第 7 篇,主题转向「不用标注数据怎么学语音特征」。读完你将能回答:
- 为什么把 BERT 的 masked LM 直接搬到语音不 work?wav2vec 2.0 用了什么聪明设计绕过这个困难?
- HuBERT 看似只是把对比损失换成了交叉熵,为什么这一改让训练快了一倍、效果还更好?
- WavLM 为什么把目标从「单纯 ASR 特征」扩展到「全栈语音任务」?这种取舍对工业部署有什么影响?
1. 背景:为什么 ASR 需要自监督预训练
2020 年前后,主流 ASR 数据集的规模有一个尴尬的瓶颈:英文最大的 LibriSpeech 也只有 960 小时精标数据;中文 AISHELL 系列约 1k 小时;其他语种更少。深度模型动辄上亿参数,靠这点数据是不够的——LSTM-CTC 时代要靠数据增强(SpecAugment)+ 外接 N-gram LM 才能勉强 work。
与此同时,未标注音频几乎免费:YouTube、Podcast、Common Voice、LibriVox 全部公开,单一项目就有数万小时。SSL 的核心命题就是:能不能从这些无标注音频中学到通用的语音表示,让下游任务(ASR / 说话人识别 / 情感分析)的标注成本降一个数量级?
NLP 那边 BERT 已经给出了答案——掩码语言建模 (Masked LM)。把句子 15% 的 token 随机 mask,让模型预测被遮的 token,模型就能学到上下文语义。但把这套搬到语音直接撞墙:
- 语音是连续信号,没有天然的「离散 token」可以预测。直接预测原始波形或 mel 频谱意味着回归任务,loss 平面平坦、收敛极慢。
- 语音帧的语义冗余度极高。相邻 20 ms 的 mel 帧几乎一模一样,BERT 风格的随机 token 预测根本学不到东西——模型只要插值相邻帧就能拿到很低的 loss。
- 没有「字典」。NLP 有 50k 词表,预测就是 50k-way 分类;语音的「单元」是什么?音素?字符?BPE?没人能事先决定。
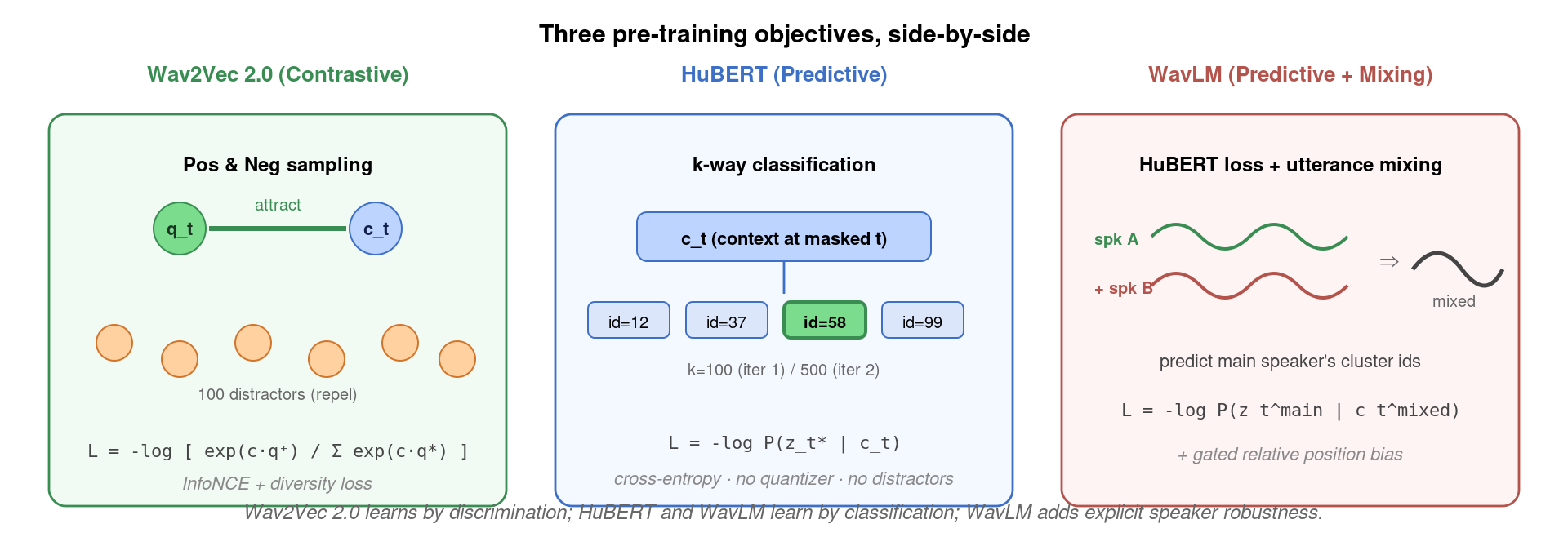
三个模型给了三种风格迥异的解法:wav2vec 2.0 用「学到的离散单元 + 对比损失」,HuBERT 用「离线 k-means 伪标签 + 交叉熵」,WavLM 在 HuBERT 之上加「话语混合 + 门控相对位置偏置」。下面逐一拆解。
2. Wav2Vec 2.0:把 BERT 思路带进语音
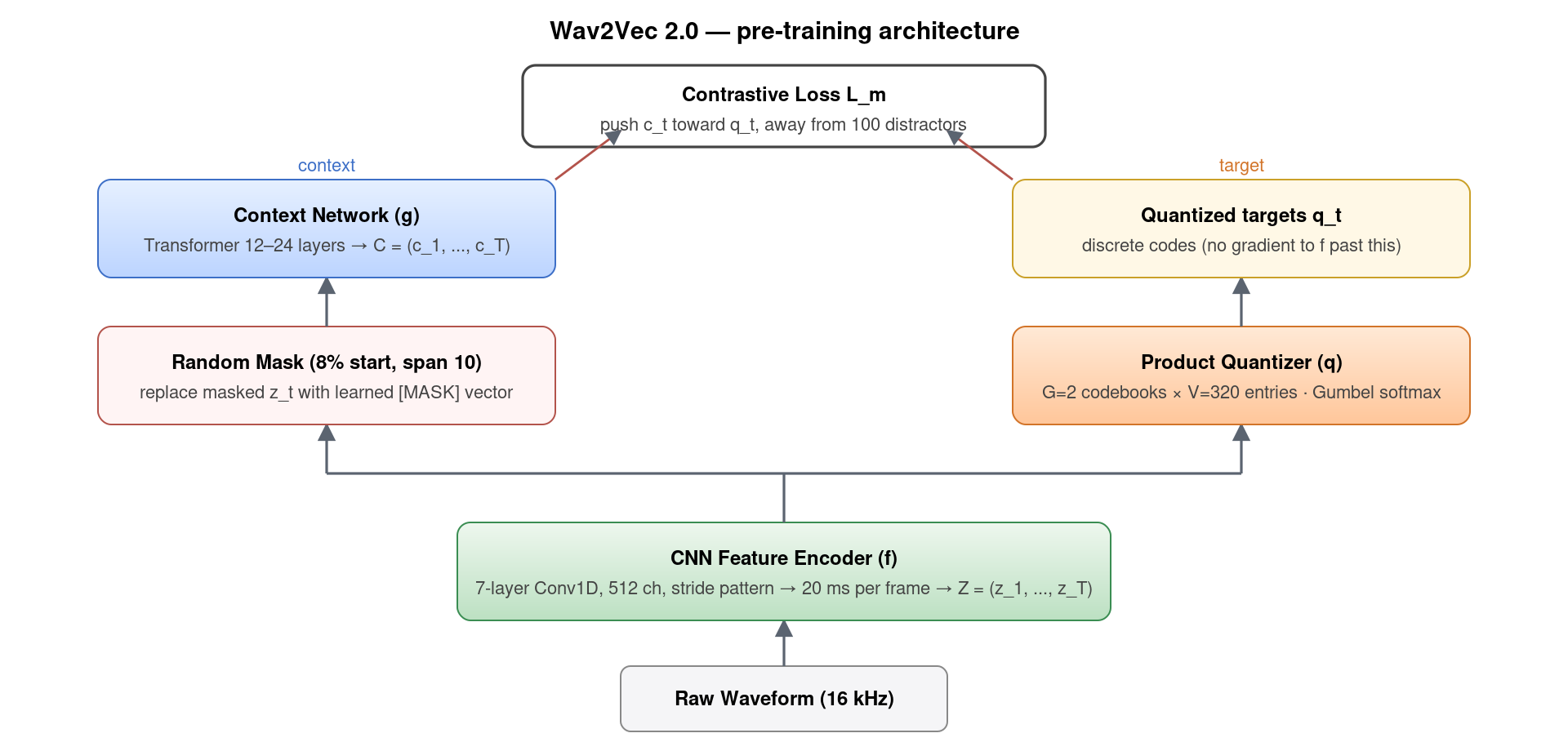
Wav2Vec 2.0 由 4 个组件组成(如图 1),训练时同时维护两条信息流:
- CNN Feature Encoder f:7 层 1D 卷积(512 通道),步长配置使每 20 ms 输出一个潜在表示 zt。这是从波形到隐向量的”分词器”,注意它没有任何 mel 频谱预处理——直接吃 16 kHz 原始波形,让网络自学滤波器组。
- Mask + Context Network g:随机选 8% 的时间步起点,每个起点之后 10 帧全部 mask(用学到的 [MASK] 向量替换),剩余帧不动;然后整个序列过 12–24 层 Transformer,得到上下文表示 ct。这一支是 BERT 风格的「填空」分支。
- Product Quantizer q:把 zt(未 mask 的原始 CNN 输出)量化成离散 codes。具体做法是「2 个 codebook × 320 个 entry」,每个 z 在每个 codebook 中选一个 entry,拼成 (320×320 = 102,400) 个可能的离散单元。选择过程用 Gumbel-Softmax 实现——既能像 argmax 一样输出 one-hot,又对参数可导。这一支负责生成「目标 token」。
- Contrastive Loss:对每个被 mask 的位置 t,模型必须让上下文 ct 与正确的 qt 相似度高,与从同一句子其他位置采的 100 个 distractors 相似度低。再加一个 diversity loss 鼓励 codebook 均匀使用(防止退化解:所有 z 都映射到同一个 code)。
这个设计巧妙的地方在于「边训练边学字典」——量化器自己学的离散单元就是 BERT 风格预测的目标,不需要事先指定音素/字符。整个模型自洽。在 LibriSpeech LV-60k(53k 小时无标注)上预训练后,BASE (95M) / LARGE (317M) 仅用 10 分钟标注数据微调就能在 test-other 上做到约 8% WER。换 100 小时标注,LARGE 直接到 3.9%,接近完全监督学习的水平。这是 ASR 历史上第一次实现了「数据效率提升 100 倍」的范式。
3. HuBERT:把对比损失换成预测损失
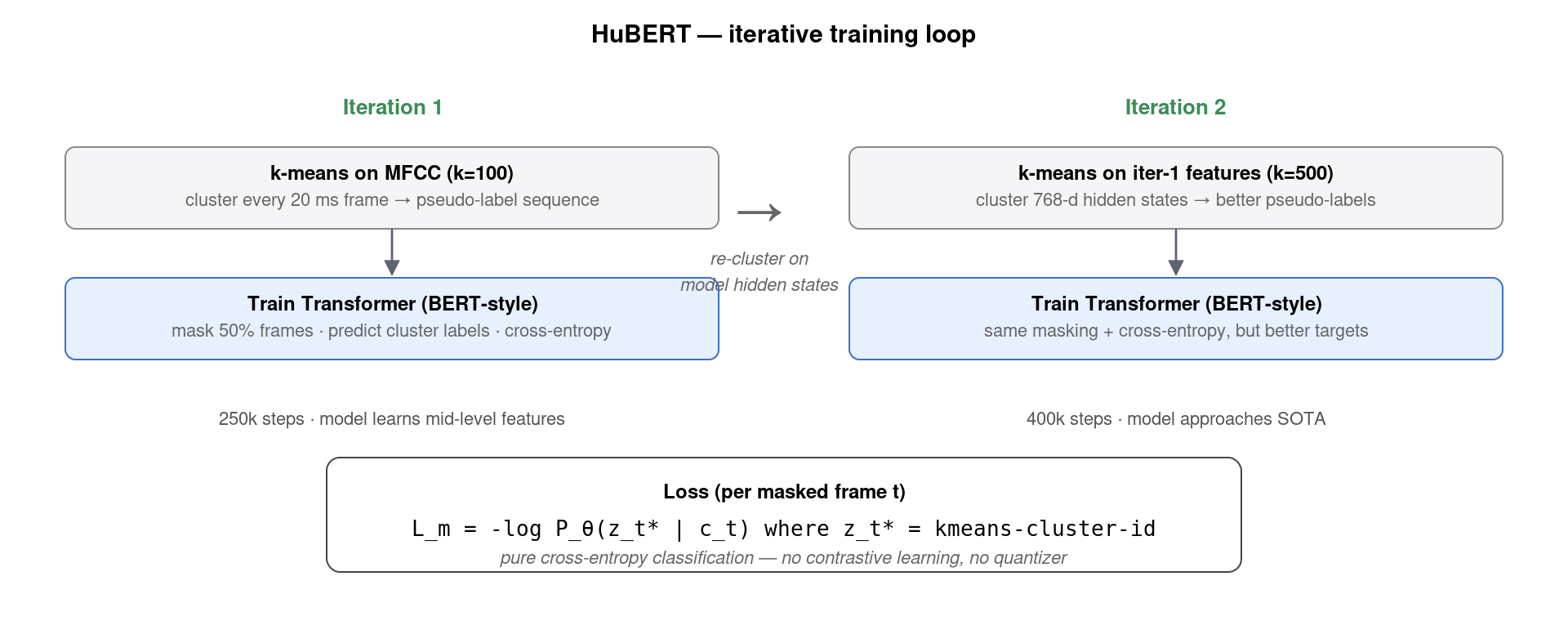
2021 年 6 月 Meta 发布的 HuBERT 提出了一个看似「降级」的设计:不再学量化器、不再用对比损失,改用离线 k-means + 标准交叉熵。整个训练循环分两次迭代:
- Iteration 1:先抽 MFCC 特征(39 维),跑 k-means (k=100) 把每个 20 ms 帧映射到一个 cluster ID。这就构成了「伪标签序列」。Transformer 模型以 BERT 风格训练——把 50% 的帧 mask 掉,预测这些位置的 cluster ID。损失是普通的交叉熵。训 250k 步。
- Iteration 2:用 iter-1 模型对训练数据再跑一遍,把 768 维中间层 hidden state 拿出来,再跑一次 k-means(这次 k=500,因为模型特征更精细)。新的 cluster ID 作为更好的伪标签,从头训练(或继续训练)一个新模型。训 400k 步。
为什么这个看似笨拙的做法能 work?三个原因:
- k-means 自带「单元发现」能力。MFCC 上的 k-means cluster 与音素并非一一对应,但确实捕捉到了类似的声学子结构——元音 cluster 集中在前部,爆破音、摩擦音各自成簇。HuBERT 论文做过分析,iter-1 学到的 100 个 cluster 与音素的归一化互信息约 0.42,已经是可用信号。
- 迭代细化。iter-2 的 cluster 基于 iter-1 模型的深层特征,这些特征已经隐含了 phonetic 信息,于是 cluster 质量大幅提升(互信息约 0.66)。这种「self-distillation via clustering」与 DINO(视觉 SSL)的思路异曲同工。
- 预测 vs 对比。Wav2Vec 2.0 的 InfoNCE 损失需要 sample 100 个 distractors,每个 mask 位置都要算 101-way softmax;HuBERT 直接对 k-way (k=100 或 500) 做交叉熵,无需采样、无需 distractor 设计、训练快 ~30%。论文实验显示在相同数据和算力下,HuBERT-LARGE 在 test-other 上比 wav2vec 2.0-LARGE 低约 0.5 个 WER。
HuBERT 的另一个贡献是把模型规模推到了 X-LARGE(1B 参数,48 层)。在 60k 小时 Libri-light 上预训练后,仅用 LibriSpeech 100h 微调,X-LARGE 就能在 test-other 上做到 3.5% WER——这已经接近 Whisper 用 680k 小时数据训出的效果。
4. WavLM:从 ASR 专用走向「全栈语音」
Wav2Vec 2.0 与 HuBERT 都是「ASR-centric」的——下游任务实验主要看语音识别 WER。但语音处理不只有 ASR:说话人识别 (Speaker Verification, SV)、说话人分离 (Speaker Separation)、说话人日志 (Speaker Diarization)、情感识别 (Emotion Recognition)、语种识别 (Language ID)、关键词检测都是真实需求。同一个预训练表示能否同时支持这些下游?
2021 年底 Microsoft 发布 WavLM,目标正是「full-stack speech foundation model」。它基于 HuBERT 框架,做了两个关键改动:
- Gated Relative Position Bias。原 HuBERT 用绝对位置编码,对长音频泛化差;WavLM 把 attention 分数中的位置项改为带 sigmoid 门控的相对偏置:
score = q·k + sigmoid(W·q) · bias(j-i)。门控由 query 决定,让模型可以按需调节位置信息的权重——这对说话人分离这类「位置无关」任务尤其有用。 - Utterance Mixing。训练时把两段不同说话人的音频以随机比例混合(信噪比 5–20 dB 之间),目标是让模型预测主说话人的 cluster 序列。这种「人造鸡尾酒会」让 WavLM 学到说话人不变性 (speaker-invariant) 和稳健性,下游 SV/Diarization 任务受益巨大。
WavLM 没有自己单独设计预训练目标,仍用 HuBERT 的 k-means + 交叉熵。但加上这两个改动,它一举刷新了 SUPERB benchmark 14 个语音任务中 10 项的 SOTA,包括 ASR、SV、SD、SF、KS、IC 等。SUPERB 是 INTERSPEECH 2021 提出的「语音届 GLUE」,专门评估自监督模型的通用性。WavLM-LARGE (316M) 至今仍是该榜单的常青树。
下表对比三个模型的核心差异:
| 维度 | Wav2Vec 2.0 | HuBERT | WavLM |
|---|---|---|---|
| 团队 / 年份 | Meta AI, 2020-06 | Meta AI, 2021-06 | Microsoft, 2021-10 |
| 预训练目标 | Contrastive (InfoNCE) | Masked Cross-Entropy | Masked CE + 话语混合 |
| 「字典」来源 | 在线学习的量化器 (Gumbel-softmax) | 离线 k-means 伪标签 | 同 HuBERT |
| 位置编码 | Conv-based relative | Conv-based relative | 门控相对位置偏置 |
| 核心创新点 | 开创 SSL for speech | 大幅简化训练流程 | 支持非 ASR 任务 |
| BASE 参数量 | 95M | 95M | 95M |
| LARGE 参数量 | 317M | 317M | 316M |
| X-LARGE | — | 1B (48 层) | — |
| 典型 SUPERB 排名 | 中游 | 上游 | 第一梯队 |
5. PyTorch 使用:transformers 一行调用
三个模型在 Hugging Face transformers 中都有官方实现。下面演示用 WavLM-Large 抽取语音表征用于下游任务:
import torch
import torchaudio
from transformers import WavLMModel, Wav2Vec2FeatureExtractor
device = "cuda" if torch.cuda.is_available() else "cpu"
ckpt = "microsoft/wavlm-large"
# 1) 加载特征提取器和模型(首次会下载约 1.2 GB 权重)
processor = Wav2Vec2FeatureExtractor.from_pretrained(ckpt)
model = WavLMModel.from_pretrained(ckpt).to(device).eval()
# 2) 读音频并重采样到 16 kHz
waveform, sr = torchaudio.load("sample.wav")
if sr != 16000:
waveform = torchaudio.functional.resample(waveform, sr, 16000)
audio = waveform.mean(0) # 转单通道 shape: (N,)
# 3) 预处理(z-score 归一化)
inputs = processor(audio, sampling_rate=16000, return_tensors="pt").to(device)
# 4) 前向:拿所有层的隐藏状态
with torch.no_grad():
out = model(**inputs, output_hidden_states=True)
# 5) 下游使用:
# - hidden_states 是 25 个 Tensor (1 conv stem + 24 transformer 层),
# 每个 shape = (1, T, 1024)
# - 通用做法是「加权和」,权重作为下游任务的可学参数
all_hidden = torch.stack(out.hidden_states, dim=0) # (25, 1, T, 1024)
weights = torch.softmax(torch.randn(25, requires_grad=True), dim=0) # 学习参数
fused = (weights[:, None, None, None] * all_hidden).sum(0) # (1, T, 1024)
print(fused.shape, "features per 20 ms frame")
这是 SUPERB 评测的标准做法——冻结 SSL 模型,只学一个线性的「层加权」+ 下游小头。中下层学到的是声学特征(适合发音/口音相关任务),上层学到的是语义特征(适合 ASR/翻译),加权方案让下游自动选择最合适的层。WavLM-Large 各下游任务的「最佳层」分布大致是:ASR 用第 22–24 层,SV 用第 6–10 层,SD 用第 12–18 层。
实际微调成 ASR 模型时,transformers 内置了 Wav2Vec2ForCTC / HubertForCTC / WavLMForCTC 三个对偶类,套路完全一致:
import torch
from transformers import (Wav2Vec2FeatureExtractor, Wav2Vec2CTCTokenizer,
Wav2Vec2Processor, WavLMForCTC)
# 1) 词表 + tokenizer:把字符映射到 id(必须包含 [PAD] 和 [UNK])
vocab = {c: i for i, c in enumerate("|abcdefghijklmnopqrstuvwxyz'")}
vocab["[UNK]"] = len(vocab)
vocab["[PAD]"] = len(vocab)
tokenizer = Wav2Vec2CTCTokenizer(vocab_dict=vocab, unk_token="[UNK]",
pad_token="[PAD]", word_delimiter_token="|")
fe = Wav2Vec2FeatureExtractor(sampling_rate=16000, do_normalize=True)
processor = Wav2Vec2Processor(feature_extractor=fe, tokenizer=tokenizer)
# 2) 加载预训练 SSL 模型 + 随机初始化的 CTC head
model = WavLMForCTC.from_pretrained(
"microsoft/wavlm-large",
vocab_size=len(vocab),
pad_token_id=processor.tokenizer.pad_token_id,
ctc_loss_reduction="mean",
)
# 关键技巧:冻结 CNN feature encoder,前 10k 步不更新
model.freeze_feature_encoder()
# 3) 训练循环(伪代码)
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-5)
for batch in dataloader:
inputs = processor(batch["audio"], sampling_rate=16000,
return_tensors="pt", padding=True)
labels = processor.tokenizer(batch["text"], return_tensors="pt",
padding=True).input_ids
labels[labels == processor.tokenizer.pad_token_id] = -100 # CTC ignore index
out = model(**inputs, labels=labels) # 自动算 CTC loss
out.loss.backward()
optimizer.step(); optimizer.zero_grad()
这套流程用 100 小时领域数据(医疗、法律、客服)一般 1–2 个 epoch 就能收敛,A100 GPU 上 ~6 小时跑完。fine-tune 之后的模型大小与 backbone 完全一致(CTC head 极小),可直接走 ONNX 量化部署链路。
6. 性能数据:SUPERB 与 LibriSpeech
| 模型 | 参数 | SUPERB Score | ASR (Libri 100h fine-tune) test-clean / test-other WER |
|---|---|---|---|
| wav2vec 2.0 BASE | 95 M | 770 | 6.1 / 13.3 |
| wav2vec 2.0 LARGE | 317 M | 912 | 3.0 / 7.1 |
| HuBERT BASE | 95 M | 793 | 6.3 / 13.2 |
| HuBERT LARGE | 317 M | 965 | 2.6 / 6.0 |
| HuBERT X-LARGE | 964 M | 998 | 2.3 / 5.0 |
| WavLM BASE+ | 95 M | 923 | 5.7 / 10.8 |
| WavLM LARGE | 316 M | 1145 | 2.1 / 4.0 |
这张表里 SUPERB Score 是 14 个语音任务的加权综合得分(越高越好)。可以清晰看到从 wav2vec 2.0 到 WavLM 的纯进步——同样 95M 参数下 WavLM BASE+ 比 wav2vec 2.0 BASE 高 153 分;316M 的 WavLM LARGE 比 1B 的 HuBERT X-LARGE 还要高,凭借的就是 Utterance Mixing 在非 ASR 任务上的优势。
7. 多语种 / 大规模变体
| 模型 | 提出方/年份 | 核心改动 |
|---|---|---|
| XLS-R | Meta, 2021 | wav2vec 2.0 范式 + 128 种语言, 436k 小时数据, 最大 2B 参数 |
| MMS | Meta, 2023 | 覆盖 1100+ 种语言,含罕见语种 |
| USM | Google, 2023 | 2B 参数 + BEST-RQ 损失 + 12M 小时无监督音频;Gemini/YouTube 字幕的底座 |
| BEST-RQ | Google, 2022 | 用随机投影+ k-means 替代 HuBERT 的迭代聚类——一次性、无需 iter |
| Data2Vec 2.0 | Meta, 2022 | 把 SSL 范式统一到「预测自己学到的连续表示」,支持 speech / vision / text |
2024 年以来的趋势是 BEST-RQ 路线胜出——它用一个固定的随机投影矩阵 + k-means 把音频帧映射到离散 ID,连「特征提取 → 聚类」这一步都不要了。Google USM、Universal Speech Model 全部基于 BEST-RQ;NVIDIA NeMo 的 Parakeet 系列也在转向这一范式。原因很简单:随机投影稳定可复现,HuBERT 的迭代聚类对超参数(k 值、k-means 初始化)非常敏感,工业训练里偶尔会发散。
8. 与 Whisper 的关系:两条平行路线
把 SSL 三部曲放到我之前写过的 Whisper 旁边看,能清晰看到 2020–2024 年端到端语音建模有两条平行的”大规模数据”路线:
| 维度 | SSL 路线 (wav2vec 2.0 / HuBERT / WavLM) | 弱监督路线 (Whisper) |
|---|---|---|
| 预训练数据 | 无标注音频 (60k+ 小时) | 音频 + 转录文本对 (680k 小时) |
| 训练目标 | 掩码预测 / 对比学习 | cross-entropy on transcript tokens |
| 下游使用 | 需要 ASR fine-tune (任意量级标注) | 开箱即用 |
| 多任务 | 需为每任务训独立 head | 通过 special token 切换 |
| 多语种 | 需 XLS-R / MMS | 原生支持 99 种 |
| 典型用法 | backbone + 自定义下游 | 直接调用 API |
简而言之,Whisper 是「拿来就用」的工具,SSL 三部曲是「可塑性的原料」。在垂直域 ASR(医疗、法律、电话客服)下,从 HuBERT/WavLM 出发用 100 小时领域数据 fine-tune,效果往往优于直接用 Whisper-Large——因为后者训练数据被通用域稀释了。这也是 2024 年后很多企业内部 ASR 仍以 SSL 微调为主的根本原因。
那到底什么时候该选 SSL 微调,什么时候直接用 Whisper?
把两条路线的对比落到决策上,公开文献和社区经验的共识其实相当清晰。SSL 微调占优的场景:低资源语言(XLS-R 论文在 CommonVoice 低资源语种上对监督基线的优势巨大)、与预训练分布差异大的垂直域(电话信道、工业噪声、儿童语音)、以及非 ASR 的语音任务(说话人、情感——SUPERB 榜单上 WavLM 至今是这些任务的默认起点)。Whisper 占优的场景:开箱即用、带标点大小写的可读转写、多语言混说、以及你没有足够标注数据做微调的一切情况。
容易被忽略的是成本结构差异:SSL 路线的真实成本不在预训练权重(免费),而在你自己的标注数据和微调 infra——没有几十小时以上的域内标注,wav2vec 2.0 微调很难比 Whisper zero-shot 强;而 Whisper 自己的微调生态(HuggingFace 上大量 whisper-finetune 案例)也已经成熟,进一步压缩了 SSL 路线的适用区间。所以我的判断是:今天的默认起点是 Whisper(或商用 API),SSL 编码器只在”有域内数据 + 域差异大 + 或任务根本不是转写”这个交集里才值得投入。这个交集不大,但落在里面的团队,SSL 至今没有替代品。
9. 工程化的几个实战要点
- fine-tune 时学习率分层。Transformer 部分用 1e-5,CTC head 用 1e-4。SSL 模型的特征已经很强,过大的 lr 会迅速破坏预训练表示。fairseq 与
transformers都内置了 layer-wise lr decay。 - 前 10k 步冻结 CNN feature encoder。CNN 部分学到的是低层声学滤波器,与下游任务无关,反传梯度反而引入噪声。原始 wav2vec 2.0 论文就是这么做的。
- 量化部署很麻烦。SSL 模型的特征向量分布尺度跨度大,朴素 INT8 量化会掉 1–2 个 WER。生产环境一般用「encoder INT8、attention FP16 混合精度」。fairseq 的 ONNX 导出脚本对 wav2vec 2.0 比较成熟,HuBERT/WavLM 需要自己手工修改算子映射。
- SUPERB 评估的层加权权重要正则化。直接 softmax 学权重容易塌缩到单一层,加上熵正则(- λ·H(weights),λ=0.01)能让权重分布更均匀。
- 话语混合数据增强可单独移植。WavLM 的 Utterance Mixing 不依赖任何 WavLM 特定结构,可以作为通用数据增强加到 Wav2Vec 2.0 / HuBERT 的 fine-tune 流程里——经验上能给 SV/SD 任务带来 1–2 个百分点的提升。
10. 总结
Wav2Vec 2.0 / HuBERT / WavLM 三部曲完成了语音领域的一次「BERT 化」——把 NLP 的预训练 + 微调范式成功移植到了语音上,让下游任务的标注成本下降一个数量级。三者构成了清晰的演进脉络:Wav2Vec 2.0 开辟了路(对比 + 量化);HuBERT 把路修平了(k-means + 交叉熵,训练大幅简化);WavLM 把路延展到全栈语音(话语混合 + 门控位置偏置)。今天的开源工具链(torchaudio、fairseq、ESPnet、NeMo、transformers)对这三个模型都有一流支持,是任何垂直域语音项目的”零号选择”。
把这篇与 Whisper Explained 并读,你应能看清 2020 年以来端到端语音的整张地图:Whisper 代表「大规模弱监督」路线,Wav2Vec 2.0/HuBERT/WavLM 代表「大规模自监督」路线。两条路在 2024 年开始合流——Google USM 和 Meta SeamlessM4T 把”自监督预训练 → 弱监督微调”做成了新的标准范式,参数量从百兆推到几十亿。
参考资料
- Baevski, A. et al. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv:2006.11477, NeurIPS 2020.
- Hsu, W.-N. et al. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. arXiv:2106.07447, IEEE/ACM TASLP 2021.
- Chen, S. et al. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing. arXiv:2110.13900, IEEE JSTSP 2022.
- Yang, S. et al. SUPERB: Speech Processing Universal PERformance Benchmark. Interspeech 2021.
- Babu, A. et al. XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale. arXiv:2111.09296, 2021.
- Zhang, Y. et al. Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages. arXiv:2303.01037, 2023.
- Chiu, C.-C. et al. Self-supervised Learning with Random-projection Quantizer for Speech Recognition (BEST-RQ). ICML 2022.
- HuggingFace transformers:WavLM / HuBERT / wav2vec 2.0 文档
- fairseq 官方实现:github.com/facebookresearch/fairseq
- Babu, A. et al. XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale. arXiv:2111.09296, 2021.
![]()
2025-06-14 at 5:34 下午
解读很详尽,写的不错