
转载本文请注明出处:https://yudonglee.me/rnn-transducer-explained/ | 作者:yudonglee
📝 本文首发于 2023 年 8 月。最近一次修订于 2026 年 6 月:补充了语音 LLM 时代 RNN-T 的下游演化、工程实践与延伸阅读内容。
2012 年 Alex Graves 在 arXiv 上发布了一篇标题朴素的论文:Sequence Transduction with Recurrent Neural Networks。它在 CTC 之后给端到端 ASR 提供了第二条路——RNN-Transducer(简称 RNN-T)。这篇论文最初没有引起太大波澜,直到 2017–2019 年 Google、Apple、Amazon 把 RNN-T 推到 Gboard 语音输入、Siri、Alexa 等亿级流量产品上,它才被工业界正式认证为「最适合流式 ASR 的端到端损失函数」。今天 Google 论文里几乎所有「streaming ASR」工作(Conformer-Transducer、Cascaded Encoders、Two-Pass、USM、Universal Speech Model)的核心损失函数都是 RNN-T。
本文目标是把 RNN-T 彻底拆透:从 为什么需要它、三网络架构、T×(U+1) 输出格栅、前向后向 Loss 推导,到 PyTorch 源码实现、现代变体演进,以及工业部署中的实际工程坑。读完你将能回答两个问题:
- RNN-T 相比 CTC 究竟解决了什么?它额外付出的代价是什么?
- 为什么 Google 在能用 Attention seq2seq(如 Whisper)的时代,仍然把 RNN-T 当做生产部署的首选?
1. 背景:CTC 还差在哪
CTC 把端到端 ASR 训练变成了可行的工程问题——通过 blank 符号和多对一映射函数 B,CTC 允许 RNN 在不知道字符级对齐的情况下学到良好的声学模型。但它有三个被广泛诟病的局限:
- 条件独立假设:CTC 假设每个时间步的输出 yt 与其他时间步独立。这意味着 CTC 学到的是一个 纯声学模型——它无法显式利用「说完
i后下一个更可能是am而不是aren't」这种语言学先验,工业部署时还得拼一个外部 N-gram LM 才能拿到合格效果。 - 无法建模输出—输出依赖:发音相同但拼写不同的词(their / there / they’re)CTC 几乎只能靠声学猜测。
- 长度约束 |x| ≥ |y|:CTC 的对齐栅格要求输入帧数不少于输出长度,对中文这种字符密集场景偶尔出问题。
RNN-T 的核心创意是:把语言模型嵌入解码循环,让模型预测下一个 token 时不仅看声学帧,也看自己已经吐出的历史 token。这一改动既保留了 CTC「不需要事先对齐」的训练友好性,又获得了 attention seq2seq「token 间存在显式依赖」的建模能力,同时还保证了流式解码所需的严格单调对齐。简直是「我全都要」。
这里需要解释一句「为什么 CTC 没有内置 LM 是个大问题」。CTC 学到的 P(y_t | x_t) 本质上只能判断「这一帧最像哪个发音单元」。在英文里 their / there / they're 三个词发音完全一致,CTC 的 logit 分布在三者上几乎均匀;要选出对的那个,必须靠外部 LM 做 prefix-beam-search 重打分。这条「声学 CTC + N-gram LM」的级联在 LibriSpeech 上能把 WER 从 ~8% 压到 ~4%——也就是说 有近一半的精度依赖外接组件。这种割裂在长尾领域(医疗、法律、地名)非常麻烦:你得为每个垂直域单独训练 LM 并维护词典。RNN-T 之所以能在 Google 一统手机端 ASR,原因之一就是它的内置 LM 让 「模型本身就够用」,运维成本骤降。
2. 整体架构:三个网络协作
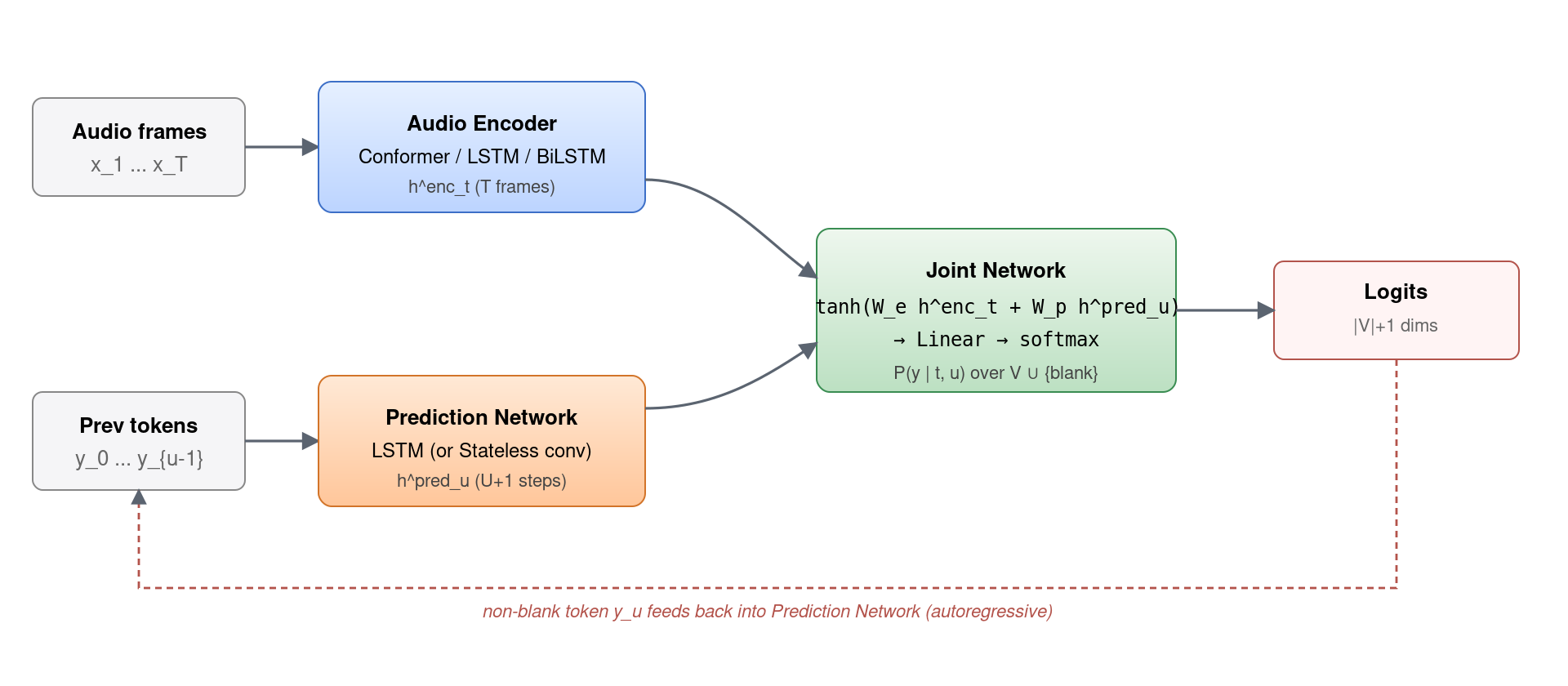
RNN-T 由三个网络组成,分工非常清晰:
- Audio Encoder (声学编码器),对应 CTC 中的 RNN。它把声学特征 x1…xT 编码成同长度的隐藏序列 henct。在 2012 年的原始论文里它是 BiLSTM,在 2020 年后基本被 Conformer 取代。
- Prediction Network (标签预测网络),一个 token-level 的语言模型。给定历史已发射的非 blank token y0…yu-1,它输出隐藏向量 hpredu。注意它只依赖历史 token,不依赖时间步 t,因此整段输入有多少 token 就有多少个 hpred。
- Joint Network,一个浅层 MLP,把声学侧 henct 和标签侧 hpredu 融合,输出在词表 V 加一个 blank 符号上的概率分布 P(y | t, u)。
Joint Network 的标准实现是:
z_{t,u} = W_out · tanh( W_enc · h^enc_t + W_pred · h^pred_u + b )
P(y | t, u) = softmax(z_{t,u}) # shape: (|V| + 1,)
这是「emit-or-blank」决策的核心:在每个二维网格点 (t, u) 上,模型可以选择吐出一个真实 token y(标签游标 u 前进一步),或者吐出 blank(时间游标 t 前进一步)。这一行为定义了 RNN-T 的整个输出空间。
3. 输出空间:T × (U+1) 对齐格栅
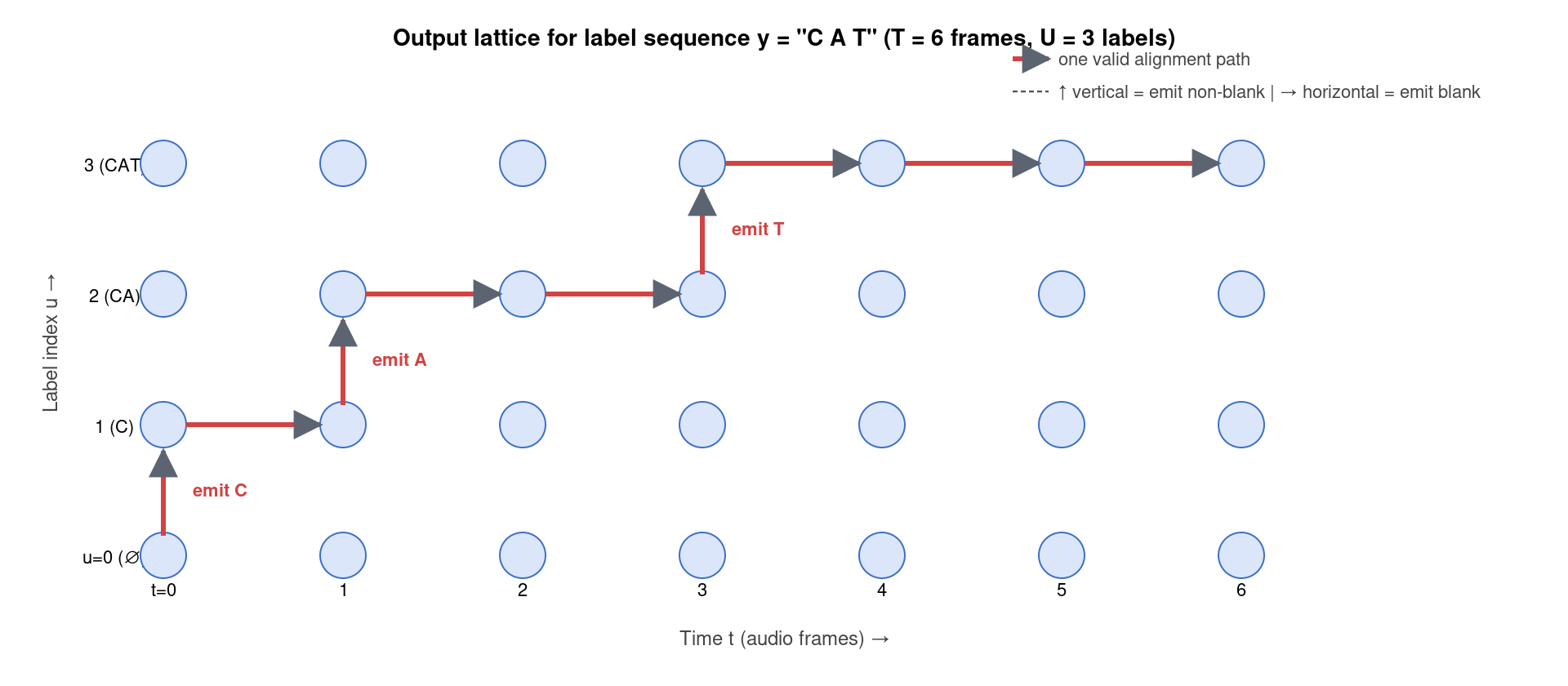
这是 RNN-T 与 CTC 在算法层面最大的差异。CTC 的对齐栅格只有 一个时间维度——每个时间步 t 必须输出某个 token(或 blank),路径只能往右走。RNN-T 引入了 第二个维度:标签游标 u。在每个网格点 (t, u),模型有两个互斥选择:
- 向上走:发射真实 label yu+1,标签游标前进,时间游标不动;
- 向右走:发射 blank,时间游标前进,标签游标不动。
合法路径必须从 (0, 0) 出发、到 (T, U) 终止,且不允许斜走(一次只能在两个维度之一前进)。这意味着 RNN-T 天然支持 一个时间步发射多个 label(连续往上走多步),也允许 多个时间步对应同一个 label(连续往右走多步)——它彻底摆脱了 CTC 「输出长度不超过输入长度」的限制。
路径上每条边的概率就是 Joint Network 在该网格点的输出:向上走时使用 P(yu+1 | t, u),向右走时使用 P(blank | t, u)。整条路径的概率是各步概率的乘积。
4. 损失函数:所有合法路径概率之和
给定输入 x 和目标 label 序列 y = (y1, …, yU),RNN-T loss 与 CTC loss 在哲学上完全一致——marginal likelihood:
P(y | x) = Σ over all valid alignments a: ∏_step P(a_step | t, u)
L_RNNT = -log P(y | x)
由于网格点数是 O(T·U),朴素枚举不可行。我们沿用 HMM/CTC 的前向-后向动态规划。
4.1 前向变量 α(t, u)
定义 α(t, u) 为「从 (0,0) 走到 (t, u) 的所有合法路径的概率之和」。它有两种到达方式——上一步走右(从 (t-1, u) 发射 blank 过来)或上一步走上(从 (t, u-1) 发射 yu 过来),递推关系:
α(t, u) = α(t-1, u) · P(blank | t-1, u)
+ α(t, u-1) · P(y_u | t, u-1)
边界:α(0, 0) = 1,其余 α(0, u≥1) = α(t, u<0) = 0
整条序列的对数似然由终点处的前向概率给出:
log P(y | x) = log [ α(T, U) · P(blank | T, U) ]
4.2 后向变量 β(t, u) 与梯度
对偶地定义 β(t, u),表示「从 (t, u) 出发到达终点的合法路径概率之和」。任意网格点的 α(t, u)·β(t, u) / P(y|x) 表示该点被合法路径经过的概率,这就是 RNN-T 在该点对 logits 求偏导所需的「软对齐权重」。完整推导见原始论文 (Graves 2012) 附录,与 CTC 几乎平行——区别只在 lattice 结构。
这个动态规划的时间复杂度是 O(T·U·|V|),其中 |V| 是词表大小(softmax 维度)。在 LibriSpeech 这种 T≈1500、U≈80、|V|≈5000 的场景下,单个 batch 的中间张量动辄数 GB,这是 RNN-T 训练最大的工程痛点,也是后面 Pruned RNN-T 解决的核心问题。
另外两个不容忽视的数值细节:(1)log-domain 计算。由于路径概率是连乘,朴素实现会立刻下溢,所有递推必须在 log-space 用 log-sum-exp 完成;warp-transducer 把 log-sum-exp 与 softmax 融合到一个 CUDA kernel 里。(2)blank gradient clipping。前向后向给 blank 的梯度容易爆炸(因为 blank 几乎在每个网格点都被多条路径经过),torchaudio 的 rnnt_loss 暴露 clamp 参数专门用于裁剪 blank 梯度,通常设到 1.0 左右;不设的话训练前几个 epoch 容易飞掉。
5. PyTorch 实现:30 行搭一个可训练的 RNN-T
PyTorch 1.10+ 起,torchaudio 内置了 rnnt_loss(封装 HawkAaron 的 warp-transducer CUDA kernel),让我们能直接搭起 RNN-T 而不必手撸前向后向:
import torch
import torch.nn as nn
import torchaudio.functional as F
class RNNTransducer(nn.Module):
def __init__(self, n_vocab: int, d_model: int = 320, blank: int = 0):
super().__init__()
self.blank = blank
self.n_vocab = n_vocab # includes blank
# ---- Audio Encoder ----
# 真实场景一般用 Conformer;为简洁起见用 BiLSTM 示意
self.encoder = nn.LSTM(input_size=80, hidden_size=d_model,
num_layers=4, batch_first=True, bidirectional=True)
self.enc_proj = nn.Linear(d_model * 2, d_model)
# ---- Prediction Network ----
self.embed = nn.Embedding(n_vocab, d_model, padding_idx=blank)
self.predictor = nn.LSTM(input_size=d_model, hidden_size=d_model,
num_layers=1, batch_first=True)
# ---- Joint Network ----
self.joint = nn.Sequential(
nn.Linear(d_model * 2, d_model),
nn.Tanh(),
nn.Linear(d_model, n_vocab),
)
def forward(self, audio_feats, audio_lens, labels, label_lens):
"""
audio_feats : (B, T, 80) mel features
labels : (B, U) token ids, *excluding* the leading blank
"""
# 1) Encode audio
h_enc, _ = self.encoder(audio_feats) # (B, T, 2d)
h_enc = self.enc_proj(h_enc) # (B, T, d)
# 2) Predict labels (autoregressive). 输入加一个 leading blank。
B, U = labels.shape
pred_in = torch.cat([torch.full((B, 1), self.blank,
dtype=torch.long, device=labels.device),
labels], dim=1) # (B, U+1)
emb = self.embed(pred_in) # (B, U+1, d)
h_pred, _ = self.predictor(emb) # (B, U+1, d)
# 3) Joint Network 在每个 (t, u) 点产出 logits
# 4D 广播:(B, T, 1, d) ⊕ (B, 1, U+1, d) → (B, T, U+1, 2d)
joint_in = torch.cat([
h_enc.unsqueeze(2).expand(-1, -1, U + 1, -1),
h_pred.unsqueeze(1).expand(-1, h_enc.size(1), -1, -1),
], dim=-1)
logits = self.joint(joint_in) # (B, T, U+1, n_vocab)
# 4) RNN-T Loss(内部走前向后向 + 反传)
loss = F.rnnt_loss(
logits=logits,
targets=labels.int(),
logit_lengths=audio_lens.int(),
target_lengths=label_lens.int(),
blank=self.blank, reduction="mean",
)
return loss
三个细节很重要:
- Prediction 输入要补 leading blank。预测网络的第 u 步在「已经发射了前 u 个 label」的条件下预测第 u+1 个。因此输入序列长度是 U+1,第 0 步以 blank 起手。
- 4D logits 张量。Joint Network 必须对每个 (t, u) 组合都算一次 softmax 输入,张量形状是
(B, T, U+1, |V|)。这是 RNN-T 内存巨兽的根本原因——对 32 GB 显存的 V100,FP32 下 T=1500, U=80, V=5000, B=8 就要 38 GB。FP16 或 BF16 是必选项。 - blank id 推荐用 0。warp-transducer / torchaudio 默认假设 blank=0;如果你词表把它放在末尾,要显式传
blank=n_vocab-1。
6. 解码:Beam Search 的「时间—标签双轴」遍历
RNN-T 的解码不像 CTC 那么直观。CTC 解码在 T 维上自左向右走,每一步做 argmax 或 beam search 即可。RNN-T 因为有 (t, u) 二维状态,解码循环要这样组织:
def greedy_decode(model, h_enc, max_symbols_per_frame: int = 5):
"""h_enc: (T, d) 编码器输出。返回 token id 列表。"""
blank = model.blank
device = h_enc.device
prev = torch.tensor([[blank]], device=device)
h_pred, state = model.predictor(model.embed(prev)) # (1,1,d)
hyp = []
for t in range(h_enc.size(0)):
# 在 t 帧内允许连续发射至多 K 个非 blank token
for _ in range(max_symbols_per_frame):
joint_in = torch.cat([h_enc[t:t+1].unsqueeze(0),
h_pred[:, -1:]], dim=-1)
logits = model.joint(joint_in).squeeze() # (n_vocab,)
tok = logits.argmax().item()
if tok == blank:
break # 切到下一帧
# 发射非 blank → prediction net 推进一步
hyp.append(tok)
tok_t = torch.tensor([[tok]], device=device)
emb = model.embed(tok_t)
h_pred, state = model.predictor(emb, state)
return hyp
核心循环是「外层时间步 t,内层每帧允许发射多个非 blank token 直到模型选择 blank」。这与 CTC 的「每帧只能输出一个 token」形成对比,也是 RNN-T 能高效处理「短音频对应长文本」(如中文密集字符)的根本原因。Beam search 版本只需把 argmax 换成维护 top-B 假设的优先队列,并按对数概率合并相同前缀的 hypothesis(在 stateless decoder 下尤其重要——状态相同的 hypothesis 可以合并 softmax)。
7. 模型变体:从 RNN-T 到 Conformer-Transducer-Stateless-Pruned
2017 年以后,工业界对 RNN-T 做了一连串改造。下表汇总了几个关键变体:
| 变体 | 提出方/年份 | 改动 | 动机 |
|---|---|---|---|
| Conformer-T | Google, 2020 | Encoder 由 LSTM 换成 Conformer | 把 CTC/Whisper 时代主流 backbone 接进来,WER 直接砍半 |
| Stateless Decoder | Variani et al., 2020 | Prediction Net 改为 2-gram 卷积,无 RNN 状态 | 显著加快 beam search(状态相同可合并),效果几乎不掉 |
| FastEmit | Yu et al., 2021 | 对 forward-backward 梯度加 非 blank 偏置 正则 | 逼模型更早 emit token,降低流式延迟 |
| HAT | Variani et al., 2020 | 把 blank 与 token 概率 解耦,token 部分用纯 LM | 方便与外部 LM rescore,提升小语种 / 罕见词 |
| Pruned RNN-T | k2 team (Daniel Povey et al.), 2022 | 先用 trivial joint 找出每个 t 的 active label 范围,仅在范围内算完整 joint | 训练显存从 O(T·U·V) 降至 O(T·B·V),省 5–10× |
| TDT (Token-and-Duration) | Xu et al., 2023 | 同时预测 token 和它持续的帧数 (duration) | 解码时一次跳多帧,推理快 2–3×,且对齐更准 |
「Pruned Stateless Conformer-Transducer」如今已是 k2/icefall 默认推荐的 SOTA 配方,在 LibriSpeech test-other 上能取得 4% 以下的 WER,并且 支持原生流式。值得一提的是,这一组合是 2022 年由 Daniel Povey(Kaldi 之父)领衔的 k2 团队提出的——Kaldi 时代的 HMM-DNN 大师们最终用 Pruned-RNN-T 拥抱了端到端范式,这条路线本身就是 ASR 工业界 20 年技术演进的缩影。
另一个值得关注的趋势是 NVIDIA NeMo 的 TDT 与 Suno Bark / OpenAI gpt-4o 时代的「LLM + 语音 codec + transducer」混合架构——transducer loss 在生成式语音模型里依然是「保证单调对齐」的关键组件,证明这套机制远未过时。
8. RNN-T vs CTC vs Attention Seq2Seq 三路线终极对比
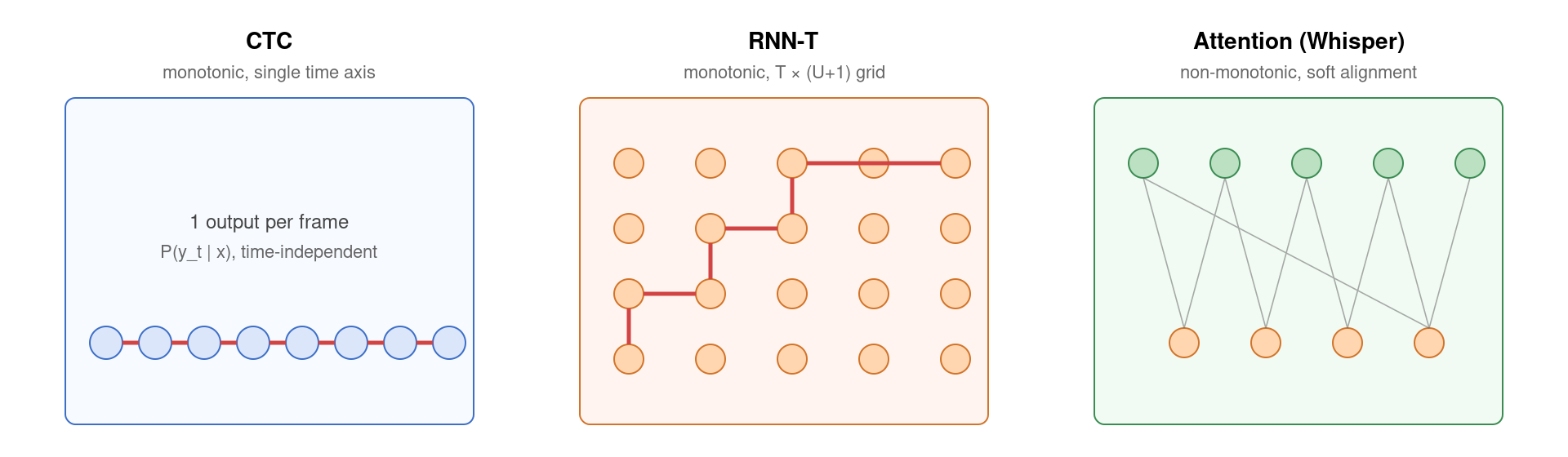
三种范式各自取舍:
| 维度 | CTC | RNN-T | Attention seq2seq |
|---|---|---|---|
| 对齐方式 | 单调,|y|≤|x| | 单调,无长度约束 | 非单调(cross-attn 任意对应) |
| 输出依赖 | 条件独立 | autoregressive(前一 token) | autoregressive(全 token) |
| 内置语言模型 | 无 | 有(Prediction Net) | 有(解码器自身) |
| 训练复杂度 | O(T·V) | O(T·U·V) 较高 | O(T·U)(attention) |
| 流式天然性 | ★★★(无依赖) | ★★★ (autoregressive only) | ★ 需 chunk + 状态管理 |
| 幻觉风险 | 低 | 中 | 高(无单调约束) |
| 典型代表 | DeepSpeech, Wav2Letter | Google Gboard, Siri, Alexa | LAS, Whisper |
Whisper / Attention seq2seq 在「精度上限 + 翻译能力 + 多任务统一」上无可替代——但当业务硬指标是「首字延迟 < 300 ms 且 endpoint 误检率 < 1%」时,非 RNN-T 莫属。这也是 Google 把 Whisper-like 模型作为 server-side fallback、把 RNN-T 部署到手机端 (Gboard) 的根本原因。
把后续补丁当原论文的勘误表来读
回看这一节列出的坑,我有一个可能有点反直觉的建议:对要上线 RNN-T 的工程师来说,FastEmit、Pruned RNN-T 这批「补丁文献」比 Graves 2012 的原论文更值得逐行精读。原因在于,每一篇补丁恰好暴露了原始设计在规模化之后才显形的一处缺陷,而这些缺陷在原论文的实验设置里根本看不出来。
FastEmit 的存在本身就是一份诊断书:RNN-T 的 loss 对「什么时候 emit」完全不施加约束,所有合法对齐在似然上等价,于是模型在流式训练中自然学会「攒够上下文再吐字」——这是 loss 的数学性质决定的系统性行为,不是调参失误。同样,Pruned RNN-T 说明 O(T·U·V) 的 joint 张量在 2012 年的小词表实验里无关痛痒,换成 BPE 词表加长音频之后立刻变成第一瓶颈,k2 团队给出的剪枝方案本质上是承认「完整格栅大部分区域的梯度贡献趋近于零」。HAT 把 blank 与 token 概率解耦,则是在回应 Prediction Net 作为内置 LM 太弱、外接 LM 又难以干净融合这个老问题。
所以我认为正确的精读顺序是:先用原论文搞懂 T×(U+1) 格栅这个核心抽象,然后把 FastEmit(延迟)、Pruned RNN-T(显存)、HAT(外接 LM)当作三份「事故报告」对照着读——原论文告诉你这套机制为什么对,补丁文献告诉你它在生产里会从哪里先坏。后者才是你上线前真正要背下来的部分。
9. 工业落地的几个坑
- 显存爆炸。基础实现下 RNN-T 单步显存远超 CTC。解决方案:(a) FP16/BF16 训练;(b) Pruned RNN-T 把 joint 计算限制在 active label 邻域;(c) fused_log_softmax + recompute,把 logits 与 log-softmax 融合,省一半中间张量;(d) gradient checkpointing。
- emit 延迟。RNN-T 在流式训练时会学到「能拖就拖,反正最后吐出来就行」,导致首字延迟劣化。FastEmit 在 loss 上加
λ · log P(non-blank)项强制前置发射,是工业部署标配。 - endpoint 检测。RNN-T 没有显式的「句子结束」token,需要靠 silence 段连续 blank 比例 + 后处理超时来判定。Google 经典做法是把 EOS token 当作普通 token 训练。
- 外接 LM。RNN-T 的 Prediction Net 是一个非常弱的 LM(参数量小、只在训练数据上见过 transcript)。生产部署一般要 shallow fusion 一个 N-gram 或 NN LM 来提升专有名词识别。HAT 因为把 blank 解耦了,更友好地支持 LM rescore。
- 训练不稳定。Joint Network 初始化、warm-up 步数、blank token 的初始 logit 偏置都会显著影响收敛——经验上 blank logit 初始化时减去 1.0~2.0 有助于避免「全发 blank」的退化解。
10. 总结
RNN-T 看起来只是「在 CTC 上加了个语言模型」,但它带来的算法红利是质变的:同一个网络同时承担声学和语言建模,且在不放弃流式的前提下做到了这一点。它在算法美感上不如 attention seq2seq 那么「一揽子」,但工程实操上却是当今 低延迟 语音识别的事实标准。当你下次用 Gboard 语音输入、和 Siri 对话、给 Alexa 下指令时,背后跑的极有可能就是某个 Pruned-Stateless-Conformer-Transducer 变种。
参考资料
- Graves, A. Sequence Transduction with Recurrent Neural Networks. arXiv:1211.3711, 2012.
- Graves, A., Mohamed, A. R., & Hinton, G. Speech Recognition with Deep Recurrent Neural Networks. ICASSP 2013.
- Sainath, T. et al. A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency. ICASSP 2020.
- Yu, J. et al. FastEmit: Low-latency Streaming ASR with Sequence-level Emission Regularization. ICASSP 2021.
- Kuang, F. et al. Pruned RNN-T for Fast, Memory-Efficient ASR Training. arXiv:2206.13236, 2022.
- Variani, E. et al. Hybrid Autoregressive Transducer (HAT). ICASSP 2020.
- Xu, H. et al. Efficient Sequence Transduction by Jointly Predicting Tokens and Durations (TDT). ICML 2023.
- k2-fsa / icefall:github.com/k2-fsa/icefall(Pruned-Stateless-Conformer-Transducer 参考实现)
- torchaudio RNNTLoss 文档:pytorch.org/audio
![]()
2023-11-22 at 4:31 下午
赞,写的非常清晰
2023-12-17 at 6:59 下午
那行很有意思——同时预测 token 和它持续的帧数,解码时一次跳多帧。这等于把 RNN-T 的”向右走 blank”压缩成”直接预测要走几格”。想问 TDT 和 CTC 的本质区别还剩多少?感觉 TDT 在向”显式建模 duration”靠拢,有点回到 HMM 时代 duration model 的味道。