
转载本文请注明出处:https://yudonglee.me/conformer-explained/ | 作者:yudonglee
📝 本文首发于 2024 年 12 月。最近一次修订于 2026 年 6 月:更新了变体对比与工程实践建议。
2020 年 5 月,Google Brain 在 Interspeech 上发表了 Conformer: Convolution-augmented Transformer for Speech Recognition。这篇论文做了一件看似简单的事——把卷积模块塞进 Transformer block 里。但就是这一改动,让 ASR backbone 从此进入「Conformer 时代」:时至今日,WeNet、ESPnet、NeMo、SpeechBrain、k2/icefall 五大开源工具包默认编码器全部是 Conformer 或其直系后代,工业部署的流式 ASR 几乎清一色 Conformer-Transducer。
本文是 CTC 系列 → Whisper Explained → RNN-T Explained 这条语音线索的第 6 篇。前几篇讲的是 ASR 的损失函数与整体范式,本文聚焦在编码器 backbone——Conformer 内部到底怎么把卷积和注意力缝合起来,为什么这种结构能在 LibriSpeech 上把 1k 小时数据训出 2.1% 的 WER(仅 118M 参数,无需外部 LM)。读完你将能回答:
- 纯 Transformer 在 ASR 上输给 Conformer 的根本原因是什么?
- Macaron-style FFN、相对位置编码、深度可分离卷积——三个看似独立的设计为什么必须同时出现才有效?
- 2022 年后涌现的 Squeezeformer / Branchformer / Zipformer 又分别改进了 Conformer 的哪个弱点?
1. 背景:为什么纯 Transformer 在 ASR 上不够
2017 年 Transformer 横空出世,先后统治了机器翻译、文本生成、图像分类。但在 ASR 这个看似 NLP 近亲的领域,纯 Transformer 编码器的表现却始终略输于 LSTM-CTC 和 LSTM-Transducer。原因要从语音信号的双尺度结构说起:
- 局部特征:单音素 (phoneme) 的发音持续约 50–150 ms,对应大约 5–15 个 10 ms 帧。要识别一个 /sh/ 音,模型必须捕捉到「这一小段窗内的共振峰分布」——这是典型的短窗局部模式,正是 CNN 擅长的。
- 全局依赖:要消除「
their / there / they're」这类同音异义,模型需要利用句子层级的语义和韵律上下文,而这种长距离依赖正是 self-attention 的强项。
纯 CNN(如 Jasper、QuartzNet)能高效捕捉局部模式,但堆很多层才能聚合远距离信息,参数效率低;纯 Transformer 反过来——长距离捕捉力满分,但每个 token 都通过 attention 直接访问全局,反而对局部相邻帧的精细差异不够敏感,在低资源场景容易过拟合。Conformer 的核心洞见就是:这两种结构没必要二选一,把它们装到同一个 block 里并行使用即可。
这个直觉今天看似平淡,但 2020 年是个重要分水岭——在此之前 ASR 学术界主流认为「编码器要么纯 conv、要么纯 attention,混搭只是工程权宜」。Conformer 的论文做了非常完整的 ablation:单独去掉 conv module、去掉 macaron、把 conv 移到 attention 之前、用 ReLU 换 Swish、用绝对位置代替相对位置——每一项都带来 0.3–0.7 个 WER 退化,证明这些设计是互相耦合不可拆的最优解。这种「每个组件都不新、但组合达到 SOTA」的工程范式,后来被 Vision Transformer 衍生品 (Swin、ConvNeXt) 反复借鉴。
论文的对照实验数据很有说服力。在 LibriSpeech test-other 上:
| 架构 | 参数量 | test-clean WER | test-other WER |
|---|---|---|---|
| QuartzNet (纯 CNN) | 19M | 3.9% | 11.3% |
| Transformer (LAS) | 270M | 2.6% | 5.7% |
| ContextNet-L (CNN+SE) | 112M | 2.1% | 4.6% |
| Conformer-S | 10M | 2.7% | 6.3% |
| Conformer-M | 30M | 2.3% | 5.0% |
| Conformer-L | 118M | 2.1% | 4.3% |
结论很直接:Conformer 仅用 30M 参数就追平了 270M 的纯 Transformer,118M 的 L 版直接拿到 SOTA。「convolution + attention」这条路被这篇论文一锤定音。
2. Conformer Block 总览
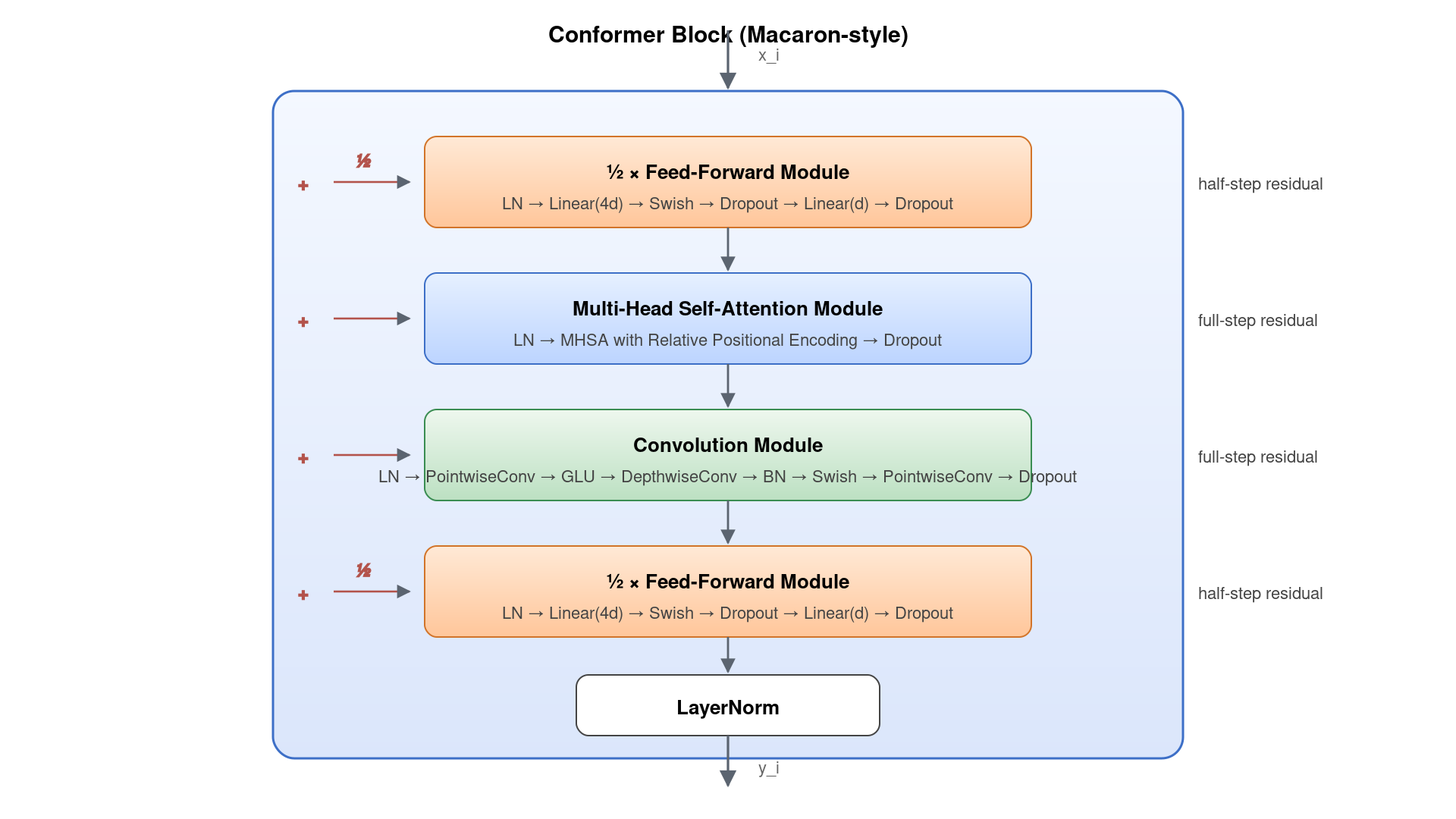
整个 block 由 4 个子模块 + 1 个 LayerNorm 串成,对应公式:
x̃_i = x_i + ½ · FFN(x_i) # 半步残差
x'_i = x̃_i + MHSA(x̃_i) # 全步残差
x''_i = x'_i + Conv(x'_i) # 全步残差
y_i = LayerNorm( x''_i + ½ · FFN(x''_i) ) # 半步残差 + 末端 LN
三个值得展开的设计:
- Macaron-style 双 FFN。Vanilla Transformer block 只在 attention 之后挂一个 FFN,Conformer 把 FFN 对半切放在 attention/conv 的两侧,每个贡献 ½ 的残差。这一设计借鉴自 NeurIPS 2019 的 Macaron Networks(Lu et al.),其理论解释是「在 ODE 离散化的视角下,标准 Transformer 是 Lie-Trotter 一阶近似,而 Macaron 是 Strang 二阶近似」,更准、更稳。论文 ablation 显示去掉 Macaron 结构(改回单 FFN)会让 test-other WER 退化约 0.5。
- Convolution Module 在 attention 之后。论文消融实验比较过 conv→MHSA 和 MHSA→conv 两种顺序,后者更好。直觉是:MHSA 先做粗粒度全局聚合,conv 再在邻域内 refine 局部模式——和 ResNet 里 「先 self-attn 后 conv」的 ViT 变体思路一脉相承。
- Pre-Norm 而非 Post-Norm。每个子模块的输入先过 LayerNorm 再进入主体计算,这是 GPT-2 / Vision Transformer 之后被验证为更稳定的训练范式。Conformer 选 Pre-Norm 让深网络(17 层 L 版)训练时不需要 warm-up tricks。
3. Multi-Head Self-Attention 模块
Conformer 的 MHSA 与原始 Transformer 的最大区别是用相对位置编码替代了绝对位置编码。绝对编码(sin/cos 或 learned)对位置 5 和位置 6 给出固定的编码值;相对编码则编码「i 和 j 之间相隔 k 步」这一关系本身。在 ASR 中输入帧数随音频长度变化,绝对编码会让模型在训练时见过的序列长度之外泛化变差,相对编码则天然鲁棒。
Conformer 沿用了 Transformer-XL (Dai et al., 2019) 的正弦相对位置编码方案:
def relative_positional_encoding(seq_len: int, d_model: int):
"""Transformer-XL 风格的相对位置正弦编码。"""
import torch, math
pos = torch.arange(seq_len - 1, -seq_len, -1, dtype=torch.float) # 2*seq_len - 1
inv_freq = torch.exp(torch.arange(0, d_model, 2).float() *
-(math.log(10000.0) / d_model))
sinusoid = pos.unsqueeze(1) * inv_freq.unsqueeze(0)
pe = torch.cat([sinusoid.sin(), sinusoid.cos()], dim=-1) # (2L-1, d)
return pe
attention 分数里则插入一个由位置编码经过线性投影后的项 R,使得 attention(i, j) = qi·kj + qi·R(j−i) + u·kj + v·R(j−i)。这就是相对位置编码的本质——把「内容相关性」和「位置相关性」解耦为四项,前两项与 query 有关、后两项与 query 无关。WeNet/ESPnet 等开源实现都直接复用了这一公式。
4. Convolution Module:Conformer 的灵魂
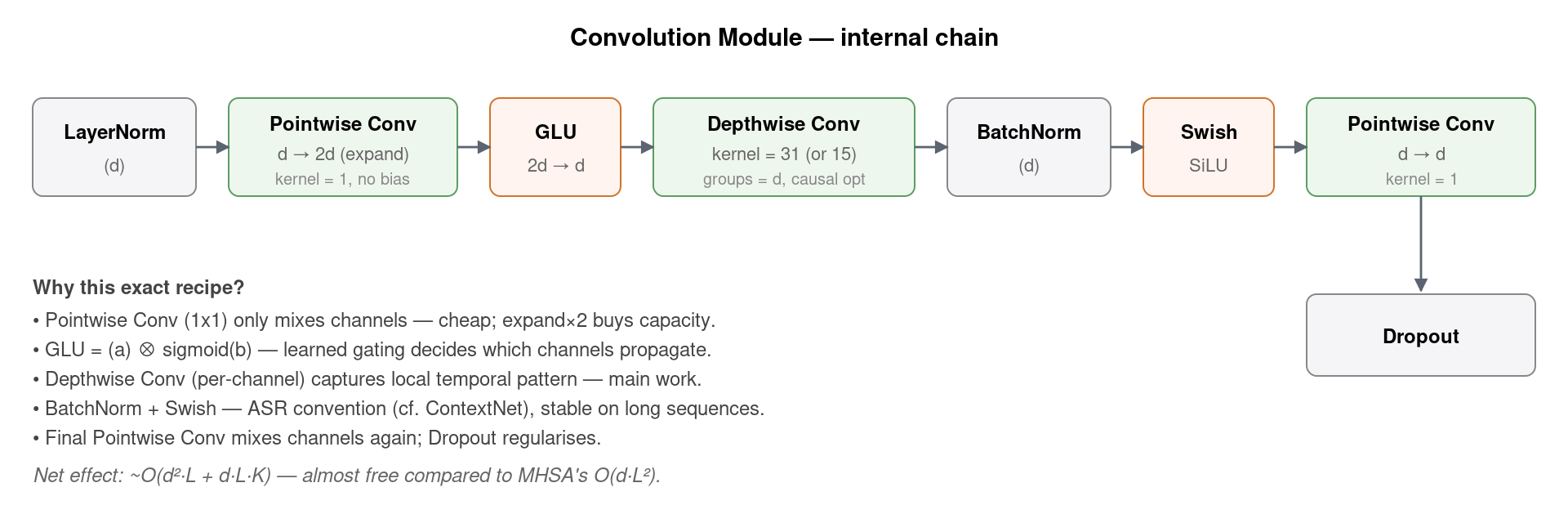
这是 Conformer 与所有「Transformer + 朴素 conv」 工作(如 Convolutional Transformer for ASR)的根本区别。它没有简单地堆一个标准 1D 卷积,而是整套移植了 ContextNet / MobileNet 的「深度可分离卷积 + GLU 门控」配方,让每个 conv module 的参数量保持在 O(d²) 级别(pointwise 主导),同时在感受野上覆盖 31 帧(约 310 ms)的局部上下文。
GLU (Gated Linear Unit) 是这里的另一个关键细节。它把 pointwise conv 的输出沿通道维度对半切,前半段作为「内容」、后半段经过 sigmoid 作为「门」,逐元素相乘后输出。这种学到的硬性门控,让模型可以选择性地保留某些通道、压制另一些,论文 ablation 显示用 ReLU 替代 GLU 会带来约 0.4 WER 退化。
5. PyTorch 实现:一个完整可训练的 Conformer Block
import torch
import torch.nn as nn
import torch.nn.functional as F
class FeedForwardModule(nn.Module):
def __init__(self, d_model, expansion=4, dropout=0.1):
super().__init__()
self.ln = nn.LayerNorm(d_model)
self.lin1 = nn.Linear(d_model, d_model * expansion)
self.swish = nn.SiLU() # Swish == SiLU
self.drop1 = nn.Dropout(dropout)
self.lin2 = nn.Linear(d_model * expansion, d_model)
self.drop2 = nn.Dropout(dropout)
def forward(self, x):
x = self.ln(x)
x = self.swish(self.lin1(x))
x = self.drop1(x)
x = self.lin2(x)
return self.drop2(x)
class ConvolutionModule(nn.Module):
def __init__(self, d_model, kernel_size=31, dropout=0.1):
super().__init__()
assert (kernel_size - 1) % 2 == 0, "kernel must be odd for SAME padding"
self.ln = nn.LayerNorm(d_model)
self.pw_conv1 = nn.Conv1d(d_model, 2 * d_model, kernel_size=1)
# GLU 在通道维切半 → 输出 d_model 通道
self.dw_conv = nn.Conv1d(d_model, d_model, kernel_size=kernel_size,
padding=(kernel_size - 1) // 2, groups=d_model)
self.bn = nn.BatchNorm1d(d_model)
self.swish = nn.SiLU()
self.pw_conv2 = nn.Conv1d(d_model, d_model, kernel_size=1)
self.dropout = nn.Dropout(dropout)
def forward(self, x): # x: (B, L, d)
x = self.ln(x).transpose(1, 2) # (B, d, L)
x = self.pw_conv1(x) # (B, 2d, L)
x = F.glu(x, dim=1) # (B, d, L) - 通道维 GLU
x = self.dw_conv(x)
x = self.swish(self.bn(x))
x = self.pw_conv2(x)
x = self.dropout(x)
return x.transpose(1, 2) # (B, L, d)
class MHSAModule(nn.Module):
def __init__(self, d_model, n_heads, dropout=0.1):
super().__init__()
self.ln = nn.LayerNorm(d_model)
# 实战中要换成相对位置编码版 MHA,这里用 PyTorch 内置做示意
self.attn = nn.MultiheadAttention(d_model, n_heads,
dropout=dropout, batch_first=True)
self.drop = nn.Dropout(dropout)
def forward(self, x, mask=None):
x = self.ln(x)
out, _ = self.attn(x, x, x, attn_mask=mask, need_weights=False)
return self.drop(out)
class ConformerBlock(nn.Module):
def __init__(self, d_model=256, n_heads=4, conv_kernel=31, ff_expansion=4,
dropout=0.1):
super().__init__()
self.ffn1 = FeedForwardModule(d_model, ff_expansion, dropout)
self.mhsa = MHSAModule(d_model, n_heads, dropout)
self.conv = ConvolutionModule(d_model, conv_kernel, dropout)
self.ffn2 = FeedForwardModule(d_model, ff_expansion, dropout)
self.ln = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
x = x + 0.5 * self.ffn1(x) # macaron half-step
x = x + self.mhsa(x, mask) # full-step
x = x + self.conv(x) # full-step
x = x + 0.5 * self.ffn2(x) # macaron half-step
return self.ln(x)
把 17 个这样的 block 堆叠,再前置一个 Conv2D-subsampling stem(4× 下采样,类似 Whisper 的 conv1/conv2),就构成完整的 Conformer-L 编码器(118M 参数)。配上 RNN-T 解码器就是 Google 把 RNN-T 推到 Gboard 的那个生产模型;配上 CTC + Attention 解码就是 WeNet/ESPnet 的标准配方。
实现层面有几个值得注意的细节:(1)GLU 在 conv module 里用的是「通道维」GLU 而不是序列维——把 (B, 2d, L) 沿 d 维切两半相乘,得到 (B, d, L)。这与文本里 ConvSeq2Seq 沿序列维 GLU 的用法相反,初学者很容易写反。(2)DepthwiseConv 的 groups=d_model,意味着每个通道独立卷积、互不混合,参数量从 d²·K 降到 d·K,大 kernel 才能负担得起。(3)对相对位置编码的工程实现,PyTorch 内置 nn.MultiheadAttention 不支持相对位置,生产代码需要自己实现——参考 WeNet 的 RelPositionMultiHeadedAttention,要点是 attention 分数计算时把 q 与 R 的乘积(位置贡献)单独算出来再相加,并用 relative_shift 把绝对偏移转成相对索引。这一段代码不长(约 50 行),但调试 BUG 的概率很高,强烈建议直接 fork 现成实现 而不是从零写。
6. 三种官方配置 S/M/L
原始论文给出 10M / 30M / 118M 三种配置,参数选择有非常清晰的规律:
| Model | Encoder Layers | Encoder Dim | Attn Heads | Conv Kernel | Params |
|---|---|---|---|---|---|
| Conformer (S) | 16 | 144 | 4 | 32 | 10.3 M |
| Conformer (M) | 16 | 256 | 4 | 32 | 30.7 M |
| Conformer (L) | 17 | 512 | 8 | 32 | 118.8 M |
三档配置层数几乎不变(16–17 层),主要靠放宽 hidden dim来扩容。这与 NLP 里大模型靠堆深度的路线很不同——ASR 的输入序列长(1500 frames),堆太多层 attention 会让 O(L²) 显存爆炸,因此宁愿把每层做厚。这也是后来 Squeezeformer 和 Zipformer 都从「下采样」这个方向继续优化的根本原因。
7. Conformer 变体演进(2022–2024)
Conformer 发布后两年间陆续涌现出一批改进,每个变体瞄准的痛点都不同:
| 模型 | 提出方/年份 | 核心改动 | 解决的问题 |
|---|---|---|---|
| Squeezeformer | UC Berkeley, 2022 | U-Net 风格的时间下采样 + 中部 squeezing | 降低 attention 序列长度,节省计算 |
| Branchformer | CMU, 2022 | conv 与 attention 并联(不再串联) | 显式建模 local/global 两条路 |
| E-Branchformer | CMU, 2023 | 用 conv 增强 branch 合并机制 | 稳定训练 + 提升精度 |
| Zipformer | k2 team, 2023 | 多尺度下采样 (U-Net 拓展) + BiasNorm + ScaledAdam | 速度提升 50%+,超越 Conformer-L |
其中 Zipformer 是 近两年 SOTA 的有力竞争者——k2 / icefall 默认配方在 LibriSpeech 上能用约 65M 参数取得 2.0/4.4 WER,比 118M 的 Conformer-L 更小更快。但时至今日,工业部署上仍以 Conformer 为主流,主要原因是Conformer 生态最成熟:所有主流推理引擎 (Triton + onnxruntime, NeMo, sherpa-onnx) 对 Conformer 的导出和量化都有现成路径,而 Zipformer 的多尺度结构在部署侧仍需较多手工工程。
另一条值得关注的支线是「Conformer + Transducer + LLM rescoring」的混合架构,在 NVIDIA NeMo 与 Microsoft Azure Speech 的最新模型中广泛采用——Conformer 编码、RNN-T 解码、再用一个 BERT 风格的 LM 对 N-best 做重打分。这套组合在 Open ASR Leaderboard 上已多次拿到 SOTA。
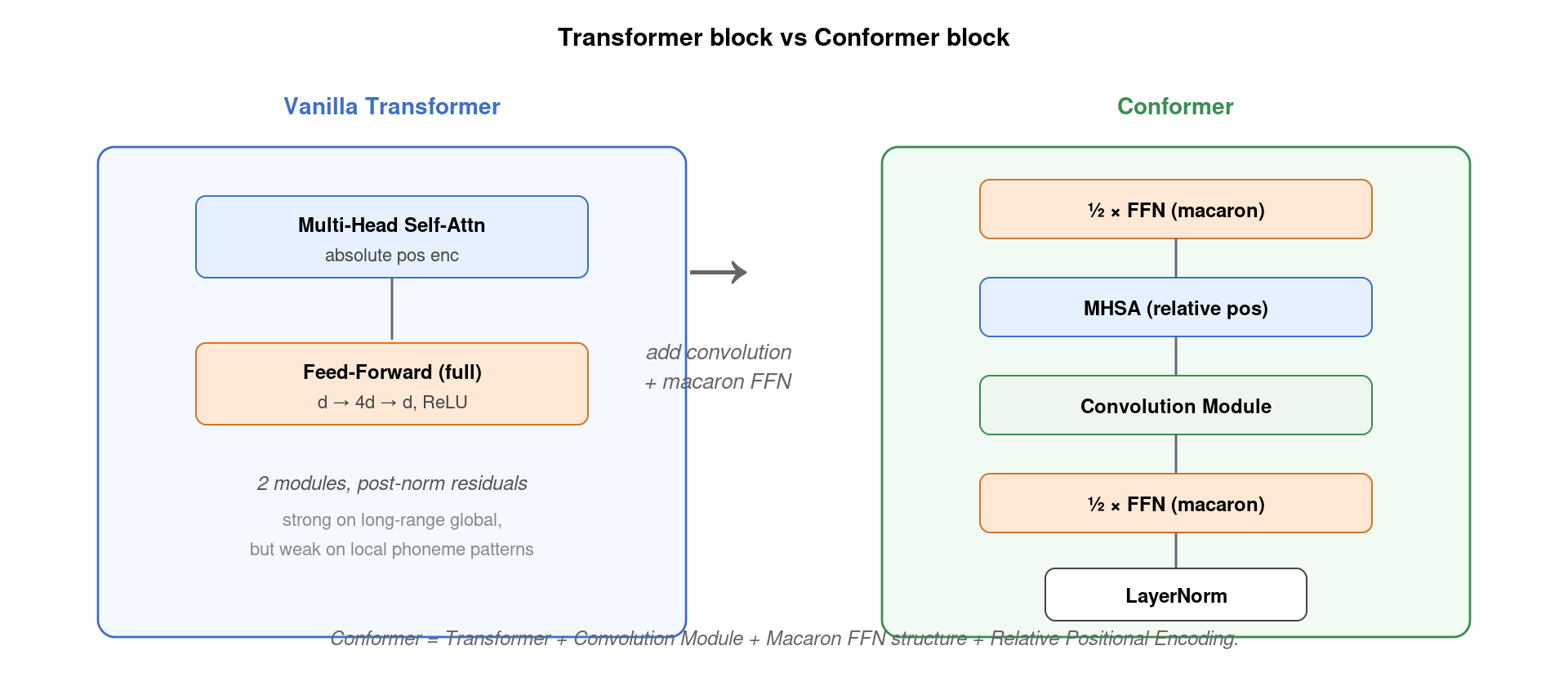
8. 与 Whisper、RNN-T 的关系
三种架构的定位非常清晰,互不替代:
| 维度 | Whisper (Transformer) | Conformer | RNN-T (任意 encoder) |
|---|---|---|---|
| 编码器 | 纯 Transformer (sin pos) | Macaron + MHSA + Conv | 常用 Conformer / LSTM |
| 损失 | Cross-entropy (autoregressive) | CTC / RNN-T / Attention 皆可 | RNN-T loss |
| 训练数据 | 680k 小时弱监督 | ~960 小时 (LibriSpeech) | 千~万小时精标 |
| 主要场景 | 多语种离线 / 翻译 | backbone 砖块 | 低延迟流式 |
| 典型部署 | GPU 云服务 | 嵌入到上面两种 | 手机端流式 |
实际上 Google 内部的 USM (Universal Speech Model)、NVIDIA NeMo 的 Parakeet、Meta 的 SeamlessM4T、阿里 SenseVoice 等大模型,编码器几乎都是 Conformer 或其变体,只是损失函数、训练数据、解码策略不同。Whisper 是个例外——OpenAI 坚持用纯 Transformer,理由是 大规模数据下编码器结构差异被「数据洗掉」了,论文最终在 680k 小时数据加持下没看到 Conformer 比 Transformer 显著更好。这是 ASR 领域「scale beats inductive bias」的一个有意思反例。
后继者投票:哪些设计活了下来
判断一个架构里什么是真正的有效成分,我习惯的办法不是看原论文的 ablation,而是看后继者集体保留了什么、抛弃了什么——Branchformer、E-Branchformer 和 Zipformer 的公开结果恰好构成了这样一次「投票」。被全票保留的,是「卷积管局部、注意力管全局」这条混合建模主张,以及 Macaron 式的多 FFN 布局,没有任何一个有竞争力的后继者退回纯 attention 编码器。被修正的至少有两处:其一,MHSA 与 conv 必须串联这个设定被 Branchformer 系证伪——并联两条分支再做增强合并,E-Branchformer 在 LibriSpeech 等公开 benchmark 上拿到了不低于 Conformer 的成绩;其二,「全程恒定帧率算 attention」被 Zipformer 否定,它用 U-Net 式的中段下采样证明编码器中间层并不需要 50 fps 的时间分辨率,这直接换来了更小参数量下的更优 WER。
那么新项目还要不要直接用 Conformer?我的判断分两种情况:如果你的训练和部署都在 k2/icefall 体系内,Zipformer 已经是更优默认值,没必要恋旧;但如果你依赖 WeNet、ESPnet、NeMo 的成熟导出链路,或者下游是 ONNX/Triton/sherpa-onnx 这类对算子有要求的推理栈,Conformer 仍然是摩擦最小的选择。换句话说,今天的 Conformer 不再是精度上限,但依然是工程下限最稳的那块砖——选它不会赢,也很难输。
9. 工程化的几个实战要点
- 下采样 stem 是性价比最高的优化。Conformer 内部 attention 的 O(L²) 显存对长音频极其不友好。标准做法是在编码器入口加一个 4× 时间下采样(两层 Conv2D stride=2),把 100 fps 的 mel 帧率压到 25 fps——既缩短序列、又给编码器更高语义的初始特征。WeNet 的实测:加 stem 后训练 throughput 提升 ~3×、WER 几乎不变。
- BatchNorm 在长序列里的坑。Conv Module 用 BN 而非 LN,在小 batch 或长音频下 BN 统计可能不稳。NeMo 把 BN 换成 LayerNorm(变体「LayerNorm Conformer」)的实验显示效果接近,但稳定性更好。生产部署若 batch 不稳,建议改 LN。
- Conv kernel 选 31 还是 15。原始论文用 31(对应 ~310 ms 感受野),WeNet 默认 15。kernel 越大局部上下文越长但参数和计算成本线性增加。流式场景常用 15 配合 chunked attention,离线场景一般用 31。
- 流式版本要做 causal conv。Conv 默认是双向(中心 padding),流式部署时必须改成「左 padding 全部、右 padding=0」的因果卷积,否则会引入未来信息泄露。WeNet 提供了
causal=True开关。 - 训练显存的另一个大头是 4× FFN 扩展。Macaron 双 FFN 意味着每个 block 有两个
d → 4d → d投影。L 版下 d=512,单 block 的 FFN MLP 就是 8.4M 参数 × 17 层 = 143M——比 attention 还重。压力大时可以把 expansion 从 4 降到 3,参数省 25%、WER 退化 <0.2。 - 训练超参。Conformer 默认配方 = Adam (β₁=0.9, β₂=0.98),Noam learning rate schedule(10k warmup steps,peak lr = 0.05/√d),label smoothing 0.1。这套配置是从 Transformer 时代继承下来的,对 Conformer 同样适用。SpecAugment 是必不可少的——时间 mask 比例 0.05、频率 mask 2 个 27 维窗口,能让 test-other WER 多降 0.5–1.0。如果你的训练数据 < 1000 小时,再加 Stochastic Depth(随机丢 block,保留概率 0.9)能进一步缓解过拟合,icefall 的 Zipformer 把这条放进了默认配方。
10. 总结
Conformer 的伟大不在于发明了什么新东西——Macaron 来自 NeurIPS 2019,相对位置编码来自 Transformer-XL,深度可分离卷积来自 MobileNet,GLU 来自 2017 年的 ConvSeq2Seq——而在于把这四个看似无关的好主意精确组装到一起,并证明它们的组合在 ASR 上严格优于各自独立使用。这是工程审美的胜利:每个组件都不复杂,但选哪四个、怎么排顺序、谁先谁后,需要大量的 ablation 实验来支撑。
对今天的 ASR 工程师而言,Conformer 提供了一个「不会出错的默认选择」:拿来当 encoder,CTC、RNN-T、Attention 三种 loss 任选;拿来做 fine-tune,从 LibriSpeech 预训练权重出发,5 小时标注数据就能在垂直域得到合格效果。当你需要把模型搬到端侧时,Conformer 的 GLU + 深度可分离卷积结构对 INT8 量化天然友好;当你需要把模型升级到 SOTA 时,Zipformer / E-Branchformer 的现成开源实现可以无缝替换。
把这篇与博主之前的 CTC 系列、Whisper Explained、RNN-T Explained 放在一起,端到端 ASR 的「损失函数(CTC/RNN-T/Attention)+ 编码器 backbone(Transformer/Conformer)+ 大规模训练(Whisper)」三件套就齐了。下一篇我会继续在这条线上写 Wav2Vec 2.0 / HuBERT / WavLM 三部曲,把语音 自监督预训练 这一与 Whisper 平行的路线也讲透。
参考资料
- Gulati, A. et al. Conformer: Convolution-augmented Transformer for Speech Recognition. arXiv:2005.08100, Interspeech 2020.
- Dai, Z. et al. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. ACL 2019.(相对位置编码)
- Lu, Y. et al. Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View. NeurIPS 2019 ML & Physical Sciences workshop.(Macaron 理论解释)
- Han, W. et al. ContextNet: Improving Convolutional Neural Networks for ASR with Global Context. Interspeech 2020.(GLU + 深度可分离卷积的 ASR 应用先驱)
- Kim, S. et al. Squeezeformer: An Efficient Transformer for Automatic Speech Recognition. NeurIPS 2022.
- Peng, Y. et al. Branchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding. ICML 2022.
- Kim, K. et al. E-Branchformer: Branchformer with Enhanced Merging for Speech Recognition. SLT 2022.
- Yao, Z. et al. Zipformer: A Faster and Better Encoder for Automatic Speech Recognition. arXiv:2310.11230, ICLR 2024.
- k2 / icefall:github.com/k2-fsa/icefall(Conformer / Zipformer 参考实现)
- WeNet:github.com/wenet-e2e/wenet(流式 Conformer 工业级实现)
![]()
2025-01-14 at 5:32 下午
写的不错,期待出一个tts的系列