转载本文请注明出处:https://yudonglee.me/tts-evolution-explained/ | 作者:yudonglee
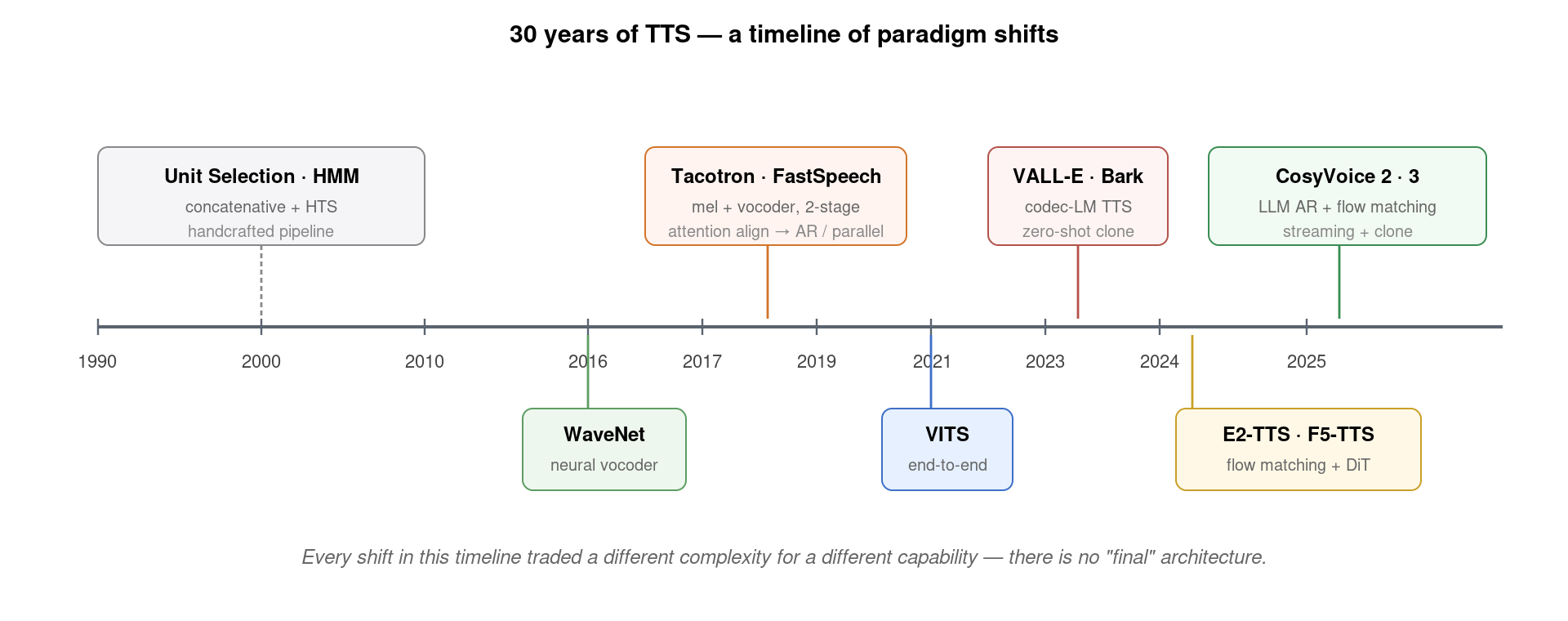
如果说语音识别 (ASR) 在过去十年完成了从 HMM 到 Whisper 的端到端跃迁,那么语音合成 (TTS) 走过的路同样波澜壮阔——而且它的”BERT 时刻”来得更晚、范式更新更剧烈。从 1990 年代的拼接式合成、HMM 参数式合成,到 2016 年 WaveNet 引爆神经声码器、2017 年 Tacotron 开启端到端、2019 年 FastSpeech 并行化、2021 年 VITS 端到端、2023 年 VALL-E 把 TTS 重新定义为「音频 codec 上的语言模型问题」,再到 2024 年 F5-TTS / CosyVoice 2 把 Flow Matching 和 LLM 思路融合——整整 30 年,TTS 经历了至少 5 次范式革命。
本文是我「语音技术深度系列」从 ASR 扩展到 TTS 全栈的开篇,把 30 年技术演进梳理成一条主线,并把每个时代「当时为什么这样做、后来为什么被取代」讲清楚。读完你将能回答:
- 为什么 Tacotron 一出 HMM 就退场了?为什么 FastSpeech 又把 Tacotron 推下王座?
- VALL-E 之后的 TTS 为什么变得越来越像 LLM?Neural Codec 在这场革命中扮演什么角色?
- 2024–2025 年 F5-TTS、CosyVoice 2 这些新模型相比传统 TTS 到底”新”在哪?工业部署该选哪个?
1. 背景:TTS 比 ASR 更难「过关」的根本原因
初看 TTS 和 ASR 是一对镜像问题——前者文本到语音、后者语音到文本,二者似乎只是输入输出反过来。但工程上它们的难度结构完全不同:
- ASR 是「多对一」问题:同一句”hello” 可以有上百种发音变体(口音、音色、语速),但都映射到同一个文本。模型只要学到”对所有这些变体都鲁棒”即可。
- TTS 是「一对多」问题:同一文本”hello”对应无数种合理读法——男声/女声、温柔/严肃、慢/快、有/无情感。模型必须从无数等价正确的输出中选一个具体的——这是生成式建模的难题。
这种「一对多」结构带来了三个根本困难:(1)评估难——没有 WER 这种客观指标,只能用 MOS (Mean Opinion Score) 让人打分;(2)训练目标含糊——直接预测 mel 频谱的 L2 loss 会让模型输出”所有可能音频的平均”,听起来含混发糊;(3)可控性需求高——业务上往往要求指定说话人、情感、语速、停顿,这意味着模型必须把”内容”与”风格”解耦。这三个难点驱动了 TTS 30 年的一连串范式革命。
2. 前神经时代 (1990–2015):拼接 + HMM
1990 年代的 TTS 主要靠 Unit Selection(拼接式合成)——录一个真人几十小时的 phone-level 语音库,合成时从库里挑出最合适的音素片段拼接起来。代表系统是 AT&T 的 NextGen、剑桥的 Festival、微软 SAPI。它的优点是音质接近真人(毕竟是真录音),缺点是每个发音人需要单独录库、合成自然度依赖拼接边界平滑、无法表达训练数据外的情感。
2000 年代后,HMM-based 参数式合成(HTS, 2002)占据主流。它把语音建模成”基频 F0 + 频谱 + 时长”三组参数,用 HMM 建模这些参数随音素的演化。HTS 的优势是模型小(< 10 MB)、可调节性强、能跨说话人插值,缺点是 vocoder 合成的语音明显”机械感”。这套技术的延续到现在仍能在一些嵌入式设备 (TI、Cerence) 看到。
这两种方法的根本局限是:它们都把 TTS 拆成多个独立模块——文本前端、音素时长模型、声学参数模型、声码器——每一步都需要专家手工设计与对齐。直到 2016 年神经网络以颠覆性方式同时改造了其中两个最难的组件。
3. 第一波范式革命:WaveNet 与 Tacotron (2016–2017)
2016 年 9 月,DeepMind 发布 WaveNet,把 vocoder(声码器)这个几十年没本质突破的模块用深度神经网络重写。它的核心是一个 因果空洞卷积自回归模型,逐采样点(16 kHz 即每秒 16,000 次!)预测下一个 16-bit μ-law 编码值。条件输入是 mel 频谱或语言学特征。MOS 一夜之间从 HMM 时代的 3.0 跃升到 4.2,逼近真人 4.55 的上限。代价是它极慢——朴素实现在 GPU 上合成 1 秒音频需要数分钟。
2017 年 3 月,Google 发布 Tacotron,把”文本→mel 频谱”这个最复杂的中间步骤也端到端化。Tacotron 是经典的 attention-based seq2seq:encoder 编码字符序列,decoder 自回归吐 mel 帧,attention 学习字符与 mel 帧的对齐(类似机器翻译里的 cross-attention)。配上 WaveNet 作 vocoder,整个 TTS pipeline 终于变成端到端可训练——再也不用手写发音字典、对齐工具、参数提取器。Tacotron 2 (2018) 把 attention 改成更稳定的 Location-Sensitive Attention 并加上 GMM attention 兜底,MOS 达到 4.53,已经几乎和真人录音听不出区别。
4. FastSpeech 时代 (2019–2020):从慢到快的并行化革命
Tacotron 漂亮但有两大缺陷:(1)自回归推理慢——每帧 mel 需要前一帧输出,无法并行;(2)attention 偶尔崩溃——长句或重复词时 attention 可能跳帧、漏字、重复,工业部署里偶发但致命。
2019 年 5 月,Microsoft 发布 FastSpeech,给出了一个优雅的解决方案:把 attention 替换成显式的 duration predictor——模型预测每个 phoneme 持续多少帧,然后把 phoneme embedding “展开”到 mel 帧数,整个 mel 序列一次性并行生成。推理速度提升 270 倍,且消除了 attention 崩溃问题。FastSpeech 2 (2020) 进一步加入 pitch / energy 预测,让韵律可控。
FastSpeech 范式的代价是需要外部对齐——训练时 duration 标签来自一个预训练的 Tacotron 教师模型(或 MFA、Montreal Forced Aligner)。这一”教师→学生”的两步训练流程在 2020-2022 年一度是工业 TTS 部署的事实标准。NVIDIA NeMo 的 FastPitch、Microsoft 的 FastSpeech 2、字节的 Mockingjay 都是这个家族。
与此同时,vocoder 也在快速进化。2020 年 HiFi-GAN 用 GAN + 多尺度判别器,把 WaveNet 的合成速度从分钟级压到毫秒级,质量却不掉。FastSpeech 2 + HiFi-GAN 成为 2021 年所有开源 TTS 系统的标配组合。
5. VITS (2021):把声学模型与 vocoder 缝成一个
2021 年 KAIST 提出 VITS (Variational Inference with adversarial learning for end-to-end TTS),把这一切彻底统一:不再有 mel 中间表示,文本直接产出波形。VITS 的核心组件是:
- Normalizing Flow:把 latent 分布映射到与文本对齐的潜空间,提供精确对数似然;
- Monotonic Alignment Search (MAS):完全 unsupervised 的对齐机制,训练时自动找到 phoneme→latent 帧对应关系(替代 MFA);
- HiFi-GAN 风格解码器:从 latent 直接生成 16/24 kHz 波形;
- Stochastic Duration Predictor:duration 用 flow 建模,比 FastSpeech 的确定性预测更自然多样。
VITS 在 LJSpeech 上的 MOS 达到 4.43,与真人录音 4.46 几乎持平,且训练只需一阶段,部署只需一个模型(不需要单独 vocoder)。VITS 几乎统治了 2022–2023 年的开源中文 TTS——bert-vits、bert-vits2、GPT-SoVITS(早期版本)都是 VITS 衍生。
6. 范式革命:VALL-E (2023) 把 TTS 重定义为 codec LM 问题
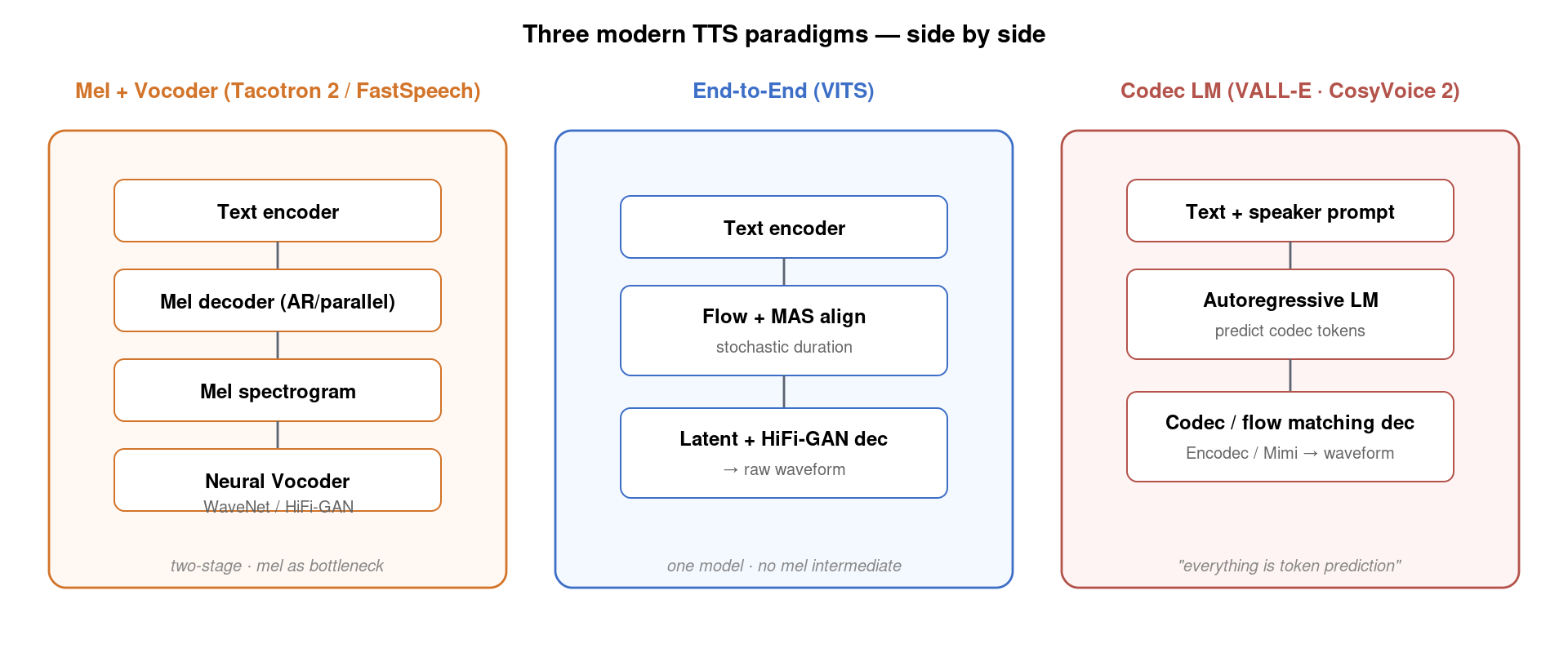
2023 年 1 月 Microsoft 发布 VALL-E,做了一件思路上的”格式塔翻转”:把 TTS 看成 codec token 上的语言建模问题。它的工作流是:
- 用 Meta 开源的 Encodec(神经音频编解码器)把音频离散化成 75 Hz、8-codebook 的 token 序列;
- 训练一个 GPT 风格的 自回归 Transformer,输入是「音色 prompt (3 秒参考音频的 codec) + 目标文本的 phoneme」,输出是目标音频的 codec token;
- Encodec decoder 把 token 重新合成回 24 kHz 波形。
这一架构带来了 TTS 历史上首个真正可用的 zero-shot voice cloning——给 3 秒任何人的语音,就能用那个声音念任意文本,不需要 fine-tune。VALL-E 训练于 60k 小时 LibriLight 数据,是第一个把 TTS 的预训练数据规模推到「语音 LLM 量级」的工作。同年 Suno 开源 Bark,把这套范式做成了多语言+音乐+音效的全能生成模型。
这次范式转换的本质是把 TTS 与 NLP 主线对齐——和 Whisper(语音→文本 LM)、Moshi(语音双向 LM)一样,所有问题都被重新表达为「在某个 token 空间上的自回归预测」。这种统一性让 TTS 直接享受了 LLM 时代的所有工程红利:KV cache、speculative decoding、INT8 量化、分布式训练框架。
7. 2024 新一代:Flow Matching 重新洗牌
codec LM 路线虽然强大,但有两个固有问题:(1)自回归 token-by-token 解码慢,长音频生成动辄数秒延迟;(2)需要外部对齐——VALL-E 必须把 phoneme 作为条件,否则不知道什么时候发哪个音。2024 年中两个新模型用Conditional Flow Matching + Diffusion Transformer (DiT) 把这两个问题一起解决:
- E2-TTS (Microsoft, 2024-06)。架构是 vanilla Transformer + U-Net 跳跃连接。训练任务是「音频填空」——给一段音频中间挖个洞,让模型 inpaint 出来,文本只是另一个条件输入。这种简洁性让 E2-TTS 完全不需要 phoneme 对齐、不需要 duration predictor、不需要 grapheme-to-phoneme 字典——直接吃字符或 BPE 文本就行。但它训练慢、收敛差。
- F5-TTS (上海交大 SWivid, 2024-10)。在 E2-TTS 基础上加 ConvNeXt 文本编码器来改善文本到音频的对齐,加 Sway Sampling(一种 flow step 重要性采样)来改善推理质量。结果是训练快 4 倍、推理快 50%、效果反超。F5-TTS 在 LibriSpeech-PC test-clean 上的 WER 比 VALL-E 低 25%,SECS(说话人相似度)反而更高。代码完全开源,2024 年 10 月开源后 3 个月内 GitHub 拿到 9k+ star,成为 2025 年开源 TTS 最热项目。
Flow Matching 在数学上是 Diffusion 模型的一个简化——直接学连续时间下的速度场 v(x_t, t),用常微分方程 (ODE) 求解器替代 Diffusion 的 SDE。从 1000 步推理压到 16–32 步,质量几乎不掉。这是 2024 年所有「DiT-based」生成模型(图像 Stable Diffusion 3、视频 Sora、语音 F5-TTS)共同的底层引擎。
8. CosyVoice 2 / ChatTTS:中文开源 TTS 的国货之光
2024 年最值得关注的中文开源 TTS 是阿里达摩院的 CosyVoice 2。它的设计哲学融合了 VALL-E 和 F5-TTS 两条路线:
| 阶段 | 组件 | 作用 |
|---|---|---|
| 第一阶段 | Text → Supervised Semantic Tokens | 用 SenseVoice (Alibaba ASR 大模型) 提取的离散语义 token 替代 phoneme,由一个 GPT 风格 LM 自回归生成 |
| 第二阶段 | Tokens → Mel via Flow Matching | 用 Conditional Flow Matching 把语义 token 转成 mel 频谱 |
| 第三阶段 | Mel → Waveform via HiFi-GAN | 标准 vocoder |
这种混合架构兼具 VALL-E 的语义可控性(通过 LM 控制内容、情感、说话人)和 F5-TTS 的音质(通过 flow matching 生成高质量声学特征)。CosyVoice 2 在 SEED-TTS 评测的中文 WER 上比 VALL-E 低 35%,且原生支持流式合成(首包延迟 150 ms)。这是 2024 年中文 TTS 工业部署的事实标准。
2024 年 5 月 ChatTTS 开源时一度成为最火 TTS 项目(GitHub 周涨 18k star),它走的是相对传统的 Tortoise/Bark 路线(codec LM + diffusion 解码器),但对中文对话场景做了精心微调——能生成自然的”嗯”、”啊”、”那个”等口语化标记。这种”垂直域调优”是开源 TTS 区别于商业 (ElevenLabs) 的关键卖点。
9. Neural Audio Codec:现代 TTS 的「分词器」
VALL-E 之后的所有现代 TTS 几乎都基于神经音频编解码器构建——这是 TTS 的”分词器”,地位等同于 BPE 之于 LLM。下面几个 codec 是 2023-2025 年事实标准:
| Codec | 提出方/年份 | 核心特点 | 典型用途 |
|---|---|---|---|
| SoundStream | Google, 2021 | RVQ-VAE, 50 Hz, 3 kbps | 音频压缩先驱 |
| Encodec | Meta, 2022 | RVQ-VAE, 75 Hz, 8 codebook | VALL-E / MusicGen 底座 |
| DAC | Descript, 2023 | 9 codebook, 高保真 | Bark / Riffusion |
| Mimi | Kyutai, 2024 | 12.5 Hz, 8 codebook, 流式 | Moshi 语音 LLM |
| WavTokenizer | 2024 | 单 codebook, 75 Hz | 极简 codec, 利于 LM 训练 |
codec 的核心技术是 RVQ-VAE (Residual Vector Quantization Variational AutoEncoder)——把音频压缩到一个小 latent 序列,每个 latent 用多个独立 codebook 残差量化。这种「多 codebook 残差结构」非常关键——它让 codec token 既足够离散(可被 LM 建模)又足够表达(能恢复高质量音频)。Mimi 把帧率从 SoundStream 的 50 Hz 进一步压到 12.5 Hz,让 token 数量减少 4 倍,是 Moshi 能做到 200 ms 端到端延迟的关键。这一块的进展直接决定了下一代语音 LLM 的速度上限。
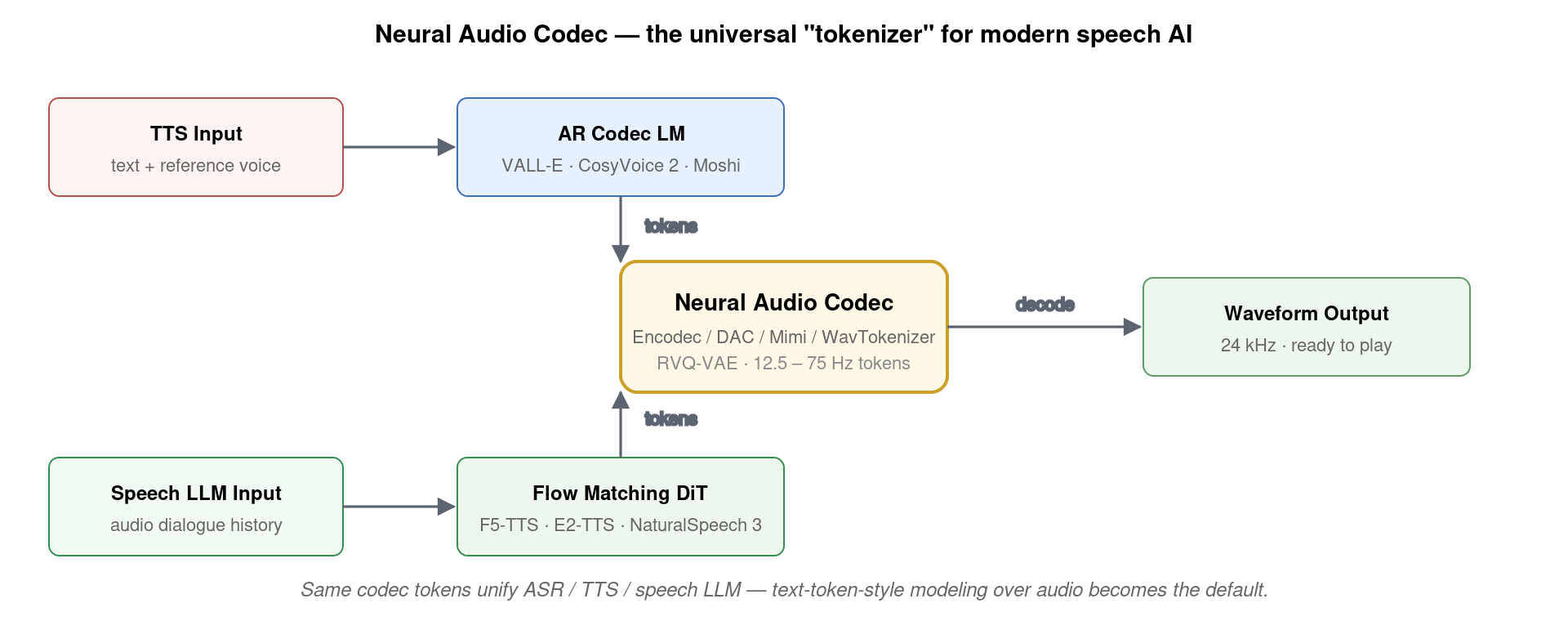
从图 3 可以看到,codec 是当代语音 AI 的「中央枢纽」——上层的 TTS(VALL-E / CosyVoice)、Flow Matching TTS(F5-TTS)、语音 LLM(Moshi)都把 codec token 作为公共表示,下游解码到统一的波形。这一架构有两个深远后果:(1)codec 进步带动整个生态——Encodec → DAC → Mimi 的迭代让所有上层模型自动变好;(2)语音和文本的边界正在消失——audio token 与 text token 在模型眼里只是两个不同的字典,未来「真正的多模态 LLM」很可能就是「拥有统一文本 + 音频 + 视频 token 化方案的单个 Transformer」。这是 2024–2025 年语音 AI 演进的根本驱动力。
对工程师而言,几个主流 TTS 在 HuggingFace 上有现成 API。下面是用 F5-TTS 做 zero-shot 音色克隆的完整代码:
# pip install f5-tts
from f5_tts.api import F5TTS
# 1) 加载模型(首次会从 HuggingFace 下载约 1.5 GB 权重)
tts = F5TTS(model_type="F5-TTS") # 也可用 "E2-TTS"
# 2) 提供参考音频 + 参考文本(决定音色)+ 目标文本(决定内容)
ref_audio = "alice_3sec.wav" # 任意人 3 秒清晰语音
ref_text = "It's a beautiful day to start something new."
target_text = "Hello, this is a zero-shot voice clone of Alice reading my arbitrary text."
# 3) 一次推理 = 一段合成音频
wav, sr, _ = tts.infer(
ref_file=ref_audio,
ref_text=ref_text,
gen_text=target_text,
nfe_step=16, # flow matching 步数:默认 32,16 步速度快质量略降
cfg_strength=2.0, # classifier-free guidance, 控制风格强度
speed=1.0,
)
# 4) 保存
import soundfile as sf
sf.write("alice_clone.wav", wav, sr)
print(f"generated {len(wav)/sr:.2f}s audio with voice cloned from {ref_audio}")
整个流程 3 秒参考音频 → 任意目标文本 → 合成完成,无需 fine-tune、无需音素字典、无需对齐工具。这种 zero-shot 能力 5 年前是科幻。CosyVoice 2 的 API 用法几乎完全一致,只需把 F5TTS 换成 CosyVoice 并指定中文模型。
10. 30 年范式演进的统一视角
| 时代 | 核心思想 | 训练目标 | 典型 MOS | 关键局限 |
|---|---|---|---|---|
| 1990s 拼接 | 录音库选段拼接 | 无 (DSP 启发式) | ~3.5 | 无法泛化新发音人 |
| 2000s HMM | 声学参数 HMM 建模 | 最大似然 | ~3.0 | 机械感重 |
| 2016 WaveNet | 原始波形自回归 | 采样级 CE | ~4.2 | 合成极慢 |
| 2017–18 Tacotron | mel + vocoder 两阶段 | L1/L2 + attention | ~4.5 | attention 偶崩 |
| 2019–20 FastSpeech | 显式 duration + 并行 mel | L1/L2 + duration loss | ~4.4 | 需教师对齐 |
| 2021 VITS | 波形端到端 + flow + MAS | ELBO + adversarial | ~4.4 | 单说话人为主 |
| 2023 VALL-E | codec token LM | cross-entropy (LM) | ~4.3 | AR 推理慢 |
| 2024 F5-TTS | flow matching + DiT | flow matching loss | ~4.4 | 训练数据需求大 |
| 2024 CosyVoice 2 | LM AR + flow matching | CE + FM 混合 | ~4.5 | 架构复杂 |
这张表里有个有意思的规律——MOS 在 4.4–4.5 区间已经几乎触顶,2017 年的 Tacotron 2 与 2024 年的 CosyVoice 2 在朗读式数据上听感差异已经很小。新一代模型的真正进步不在「单句念得多准」,而在四个新维度:zero-shot 音色克隆、长篇韵律一致性、跨语种迁移、可控情感与韵律。如果你的业务只是「文本→单一标准发音人朗读」,2018 年的 Tacotron 2 + HiFi-GAN 仍然完全够用——花高成本上 F5/CosyVoice 是为了那些 Tacotron 解决不了的新能力。
11. 与 ASR 演进史的对应
把 TTS 30 年放在 ASR 30 年旁边看,能看到惊人的范式同步:
| 年代 | ASR | TTS | 共同范式 |
|---|---|---|---|
| 1990–2010 | HMM-GMM + WFST | Unit Selection / HTS | 统计参数模型 |
| 2014–2017 | CTC / Attention seq2seq | WaveNet + Tacotron | 端到端神经网络 |
| 2019–2021 | Conformer + RNN-T | FastSpeech + HiFi-GAN | 并行化 + 专用 backbone |
| 2020–2022 | wav2vec 2.0 / HuBERT / WavLM | VITS / NaturalSpeech | 自监督 + 端到端 |
| 2022–2023 | Whisper (弱监督大模型) | VALL-E / Bark (codec LM) | 大规模 + LM 思路 |
| 2024–2025 | Moshi / GPT-4o (语音 LLM) | F5 / CosyVoice / NaturalSpeech 3 | diffusion + 端到端 |
这种节奏一致并非偶然——ASR 和 TTS 共享同一个底层(Transformer、attention、codec),任何架构创新最多滞后 1-2 年就会跨过去。这意味着语音技术从业者必须把 ASR 与 TTS 当作一对耦合的演进体系来理解,不能只关注一边。
12. 工程化讨论:2025 年怎么选 TTS
给你一份 2025 年的选型决策树:
- 固定单说话人朗读 (有声书、新闻):VITS 或 FastSpeech 2 + HiFi-GAN 就够。10 小时录音、单卡 24 小时训练,效果接近商业。
- zero-shot 多说话人 (虚拟主播、配音、个性化 TTS):F5-TTS(英文场景)或 CosyVoice 2(中文场景)。3 秒参考音频克隆任意人声,不需要 fine-tune。
- 实时 voice agent (对话机器人、客服):CosyVoice 2 流式版(首包延迟 150 ms)。如果接 LLM,结合 LiveKit / Pipecat 的级联架构。
- 端到端语音 LLM (对话生成 + TTS 一体):Moshi,但需要 7B 模型 + 较高 GPU 资源;适合 voice agent 公司而非业务侧直接调用。
- 移动 / 边缘端:bert-vits2 或 GPT-SoVITS 量化版,能在树莓派跑实时;或上 ElevenLabs API。
- 商业 API 兜底:ElevenLabs (英文最强)、Azure Neural Voices (覆盖最广)、OpenAI TTS-1(最便宜)。
13. 总结:30 年的一句话
如果一定要用一句话概括 TTS 30 年:「把人类手工设计的步骤一个一个吃掉,最后只剩一个能被 token 表达、被 LM 建模、被 codec 解码的统一框架」。1990 年的 TTS 系统有 6-8 个独立模块(文本归一化、G2P、duration、F0、频谱、vocoder),2025 年的 TTS 系统只剩 2 个:一个 LM 把文本变成音频 token、一个 codec 把 token 变成波形。这种简化不是巧合——它和 NLP(n-gram → LSTM-LM → Transformer-LM)、CV(HOG + SVM → CNN → ViT → DiT)的范式收敛完全一致,都是「设计精巧的 pipeline 输给可微分的端到端」这一深度学习时代铁律的体现。
参考资料
- van den Oord, A. et al. WaveNet: A Generative Model for Raw Audio. arXiv:1609.03499, 2016.
- Wang, Y. et al. Tacotron: Towards End-to-End Speech Synthesis. arXiv:1703.10135, Interspeech 2017.
- Shen, J. et al. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions (Tacotron 2). ICASSP 2018.
- Ren, Y. et al. FastSpeech: Fast, Robust and Controllable Text to Speech. arXiv:1905.09263, NeurIPS 2019.
- Kim, J. et al. Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech (VITS). arXiv:2106.06103, ICML 2021.
- Wang, C. et al. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers (VALL-E). arXiv:2301.02111, 2023.
- Eskimez, S. et al. E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS. arXiv:2406.18009, 2024.
- Chen, Y. et al. F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. arXiv:2410.06885, 2024.
- Du, Z. et al. CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models. arXiv:2412.10117, 2024.
- Défossez, A. et al. High Fidelity Neural Audio Compression (Encodec). arXiv:2210.13438, 2022.
- Défossez, A. et al. Moshi: a speech-text foundation model for real-time dialogue. arXiv:2410.00037, 2024.(Mimi codec 出处)
- Kong, J. et al. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. NeurIPS 2020.
![]()
2026-01-14 at 5:53 下午
总结的很详细