转载本文请注明出处:https://yudonglee.me/valle-explained/ | 作者:yudonglee
📝 本文首发于 2025 年 9 月。最近一次修订于 2026 年 6 月:更新了与 CosyVoice 2 / F5-TTS 的对比结论与部署建议。
2023 年 1 月 5 日,微软亚洲研究院在 arXiv 挂出 Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers。论文的项目代号 VALL-E——一个把语音合成(TTS)重新表达为 codec token 上的语言模型问题的工作。它带来了 TTS 历史上第一次真正可用的 zero-shot voice cloning:给 3 秒任何人的语音,模型就能用那个声音念任意文本,不需要 fine-tune、不需要说话人嵌入、不需要参考数据库。整个 TTS 领域因此被推入「把 TTS 当 LLM 做」的新时代。两年后 CosyVoice 2、F5-TTS、NaturalSpeech 3 等几乎所有当代 SOTA 模型都建立在 VALL-E 开创的范式上。
本文是我「语音技术深度系列」TTS 主线的第 2 篇(紧接 TTS 三十年技术演进史)。读完你将能回答:
- 为什么 VALL-E 之前 30 年的 TTS 系统都做不到 zero-shot 克隆?这背后到底缺了什么?
- Encodec 把音频离散化的具体方法是什么?为什么必须是「多 codebook 残差量化」而不能用单一 codebook?
- VALL-E 为什么需要 AR + NAR 两个模型?只用一个 AR 不行吗?
- VALL-E、VALL-E 2、CosyVoice 2、F5-TTS 该怎么选?工业部署的取舍是什么?
1. 背景:VALL-E 之前 TTS 为什么不能 zero-shot 克隆
2022 年之前的 TTS 主流是 Tacotron 2、FastSpeech 2、VITS 这条「mel + vocoder」路线。要支持新说话人音色,必须做这两件事之一:
- Multi-speaker fine-tune。在预训练模型上加几分钟到几十小时的目标说话人数据,做监督微调。需要数小时数据 + 几小时训练 + 一份专属 checkpoint——成本高,无法面向”任意路人”。
- Speaker Embedding。用一个独立的说话人编码器(如 X-vector、d-vector、ECAPA-TDNN)从参考音频抽出一个固定向量,作为 TTS 的条件输入。但这种 256/512 维向量只能编码”音色”,无法编码”说话风格、节奏、情感”。生成出来的语音”音色像但说话方式不像”,听感僵硬。
问题的根本在于:这些方法把音色当成一个”标签”,而不是一个可学习的”上下文”。它们假设音色与内容可以完全解耦——但人类说话并非如此,同一句话不同人说出来,差异不仅在音色,还在停顿、重音、韵律。要捕捉这些只有”音频本身”才能完整表达。
VALL-E 的洞见正在于此:与其让模型学”音色”这个抽象向量,不如直接把 3 秒参考音频作为 prompt 喂给模型,让模型在生成时不断”参考”这段音频的实际声学特征。这恰好是 LLM 在 in-context learning 中已经验证过的能力——GPT-3 给几个例子就能做新任务,VALL-E 给 3 秒参考音频就能克隆新音色。这是把 NLP 的 in-context learning 移植到 TTS 的一次格式塔翻转。但要实现它,必须解决一个前提问题:音频怎么变成可被 LM 建模的离散 token?
2. Encodec:把音频离散化的「分词器」
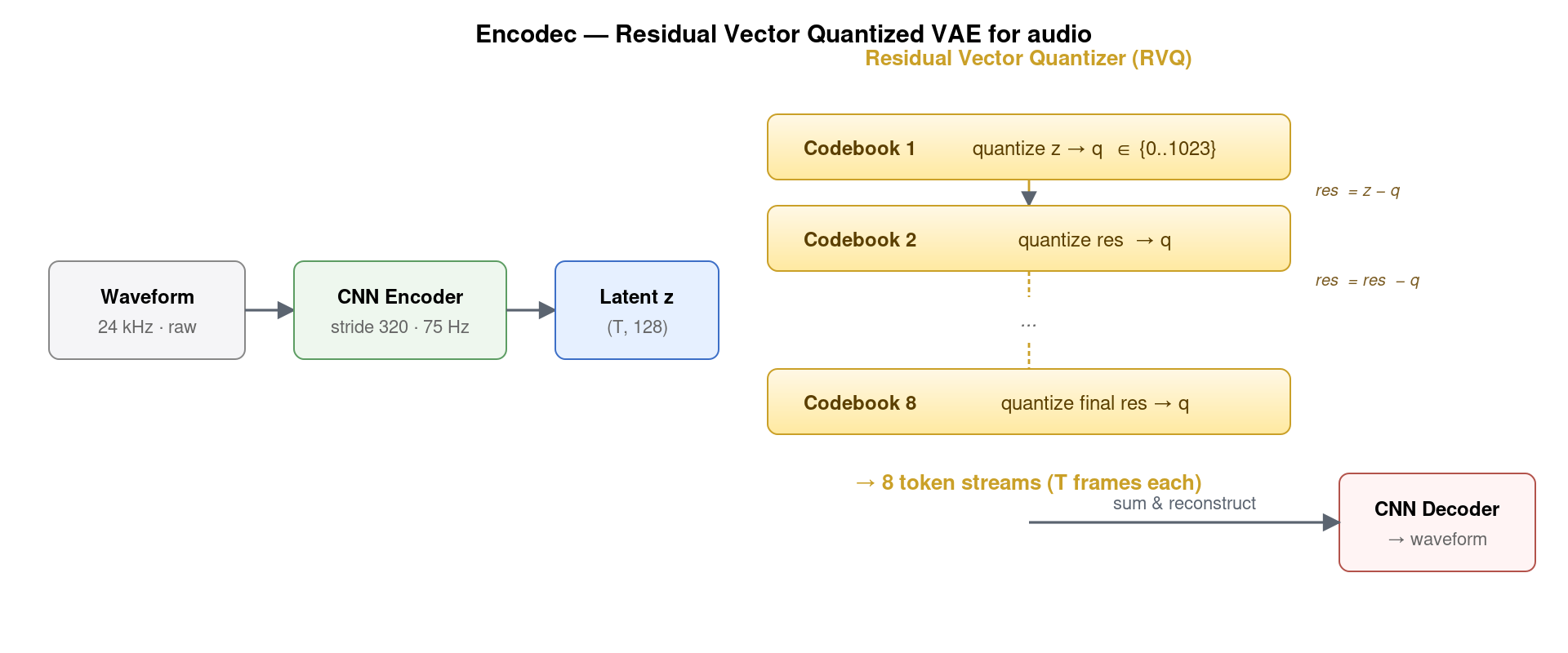
Encodec 是 Meta 2022 年发布的 神经音频编解码器,它是 VALL-E 唯一的依赖。本质上是一个 RVQ-VAE (Residual Vector Quantized Variational AutoEncoder),由三部分组成:
- CNN Encoder。SEANet 风格的 1D 卷积栈,把 24 kHz 原始波形以 320× 时间下采样得到 75 Hz 的潜在表示 z ∈ ℝT×128。
- Residual Vector Quantizer (RVQ)。这是最关键的组件。每帧的 128 维潜在向量不是用单一 codebook 量化到一个 token,而是经过 8 层级联:第 1 层 codebook (1024 entries) 量化整体,得到余差 res₁ = z − q̂₁;第 2 层 codebook 量化余差,得到 res₂ = res₁ − q̂₂;以此类推。最终输出 8 个 token 流,每流都是 1024-way 离散索引。
- CNN Decoder。把 8 个 codebook 的 embedding 求和重建潜在向量,再上采样回 24 kHz 波形。
为什么必须是 多 codebook 而不是单一 codebook?算一笔账:要把 128 维实数向量量化到 1 个 token,理论上需要 e128 量级的 codebook 才能保证重建质量——根本不可能。RVQ 用 8 个 1024-codebook,能表达 10248 ≈ 1024 种组合,等效信息容量 80 bit / 帧,足以重建 6 kbps 高保真音频。这种”多 codebook 残差结构”是 Encodec、SoundStream、DAC、Mimi 等所有现代 neural codec 的核心范式,它的发明几乎和 BERT 一样重要——让”音频→离散 token”这件事第一次变得高质量可行。
对于 VALL-E 来说,Encodec 把一段 T 秒 24 kHz 的音频变成了一个 (75T, 8) 的二维 token 矩阵——75T 是时间长度、8 是 codebook 数量。每个 entry 是 0–1023 的整数。这就是 LLM 的”输入”了。
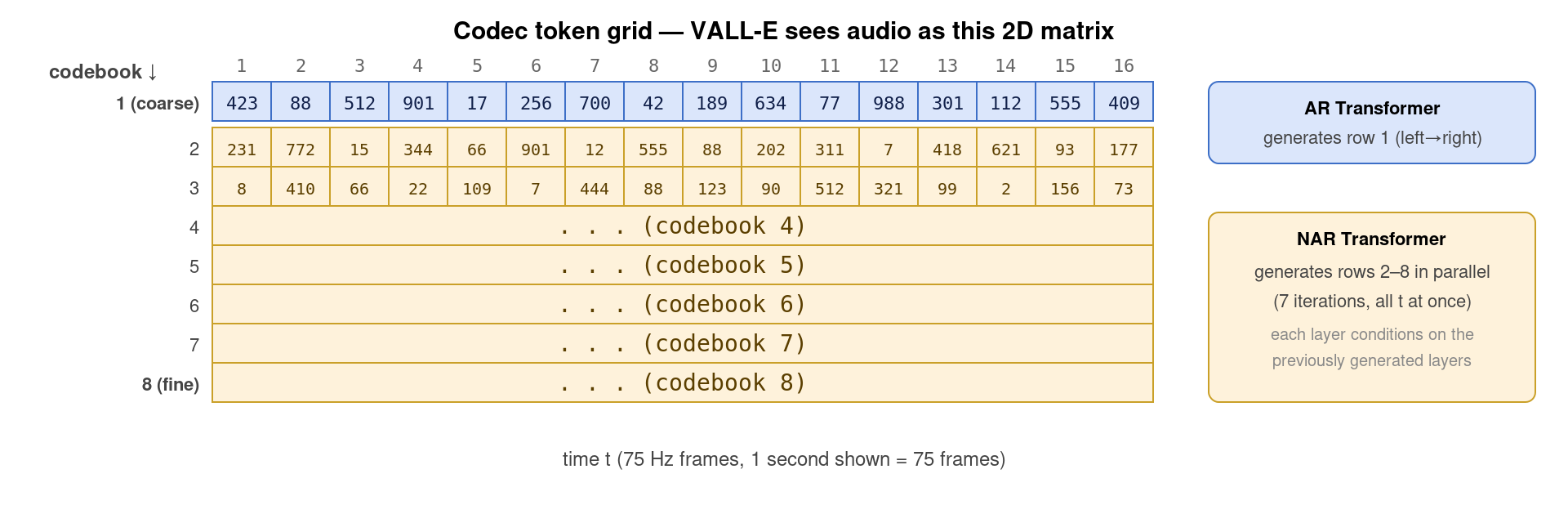
上图直观展示了 VALL-E”看到”的音频是什么样子——一个 8 行 × N 列的整数矩阵。第一行(蓝色)是”coarse” codebook 1,由 AR Transformer 自回归生成;下面 7 行(黄色)是”fine” codebook 2–8,由 NAR Transformer 迭代式并行生成。整张矩阵被 Encodec 解码器还原成 24 kHz 波形。把音频建模成「这样一张稀疏的整数表格」——这就是 VALL-E 范式革命的全部核心。
3. VALL-E 整体架构:AR + NAR 双模型
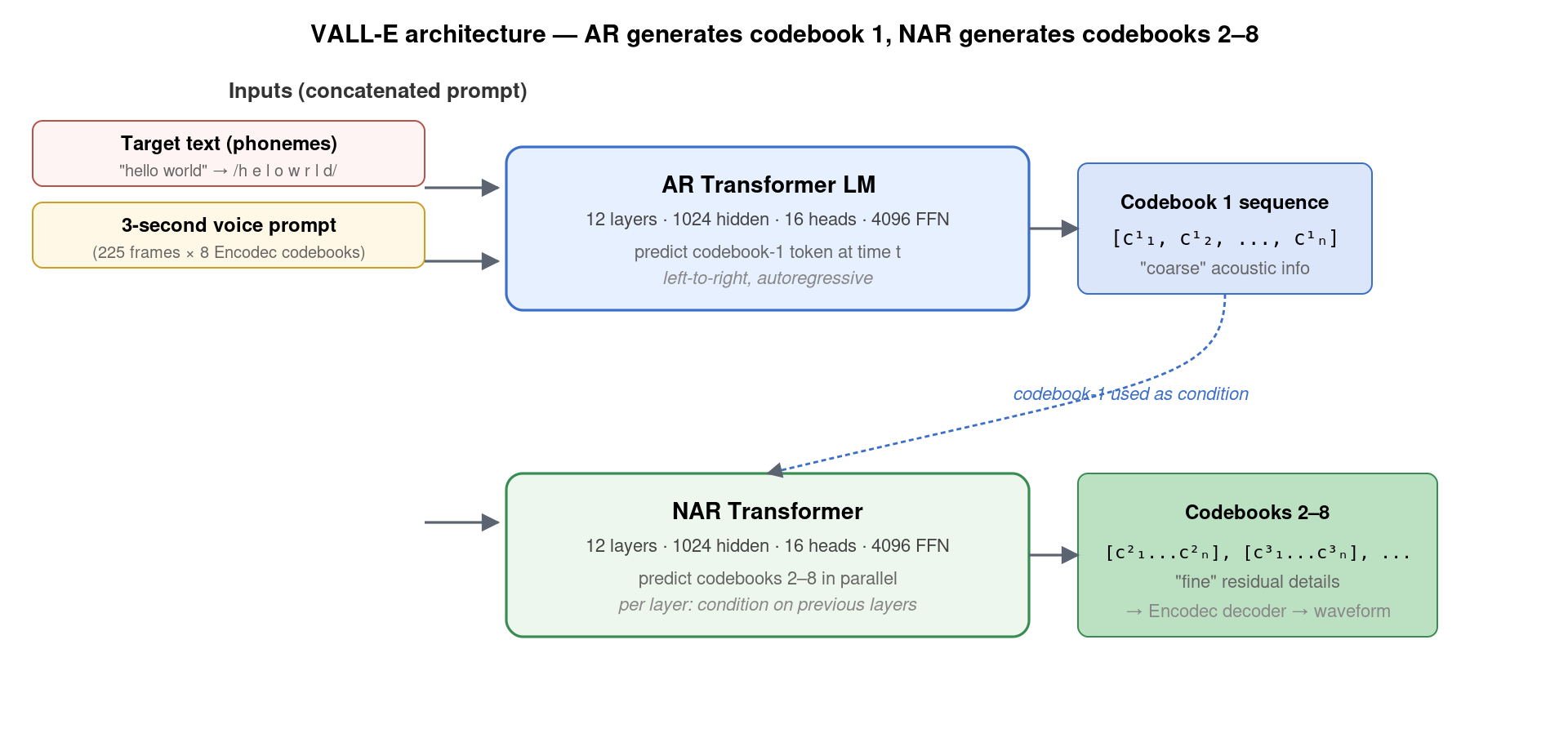
VALL-E 是两个独立的 Transformer 模型组成的复合系统:
- AR (Autoregressive) Transformer。处理 codebook 1——粗粒度的声学骨架信息(pitch、energy、phoneme identity)。它是标准的 GPT 风格:12 层 / 1024 hidden / 16 头 / 4096 FFN。输入是 [phoneme 序列 + 3 秒参考音频的 codebook-1 token],自回归地输出目标音频的 codebook-1 token 序列。每个时间步只预测一个 token,token 间有严格因果依赖。
- NAR (Non-Autoregressive) Transformer。处理 codebook 2–8——细粒度的残差细节。它的输入是 [phoneme + 参考音频全部 codebook + 已生成的 codebook 1],输出剩余 7 层 codebook。所有时间步并行预测、所有 codebook 层迭代预测:预测 codebook 2 时条件化于 codebook 1;预测 codebook 3 时条件化于 codebook 1+2;以此类推。架构尺寸与 AR 一致。
为什么要分两个模型?两个原因:
- 速度:8 个 codebook × T 帧 = 8T 个 token,如果全部 AR 生成,对一段 5 秒音频就要 3000 步自回归解码。把后 7 层改成并行 NAR,解码步数从 3000 步降到 ~400 步,速度提升 7-8 倍。
- 建模分工:codebook 1 决定”说什么、像谁”,是语义+音色的载体;codebook 2-8 是残差细节,对生成顺序不敏感。分开建模让 AR 专注于复杂的语义建模、NAR 专注于声学细节填充——各司其职。这也是为什么 VALL-E 把 codebook 1 称作 “coarse codes”、后续称作 “fine codes” 的原因。
4. AR 模型细节:语言模型范式的胜利
AR 模型的训练目标和 GPT 完全一样——给定历史 token,预测下一个 token 的概率分布,最小化交叉熵:
p(C¹ | text, prompt) = ∏ p(c¹ₜ | text, prompt, c¹<t)
L_AR = -Σₜ log p(c¹ₜ | text, prompt, c¹<t)
训练时输入序列拼接成:
[text phonemes] [SEP] [prompt codebook-1 tokens] [SEP] [target codebook-1 tokens]
模型只在 target 段计算 loss。关键 trick 是 prompt 段也作为 context 输入——这让模型在 in-context learning 中学到了”参考前面 prompt 的音色去生成后面”。3 秒参考音频在 75 Hz 编码下是 225 个 token,加上 phoneme 通常 200-400 个 token,总 prompt 长度约 600 token,远小于现代 LLM 的 8k 上下文,对训练完全无压力。
5. NAR 模型细节:迭代式细节填充
NAR 模型并不是真正”一次性”输出所有 codebook——而是逐层迭代:
for k in range(2, 9):
Cᵏ = NAR(text, prompt, C¹, C², ..., C^(k-1), layer_emb=k)
每次输入”已生成的所有低层 codebook”,并加一个可学习的 layer_embedding 告诉模型当前要预测哪一层。所有时间步同时预测(”非自回归”指的是时间维度)。这种设计在速度和质量之间找到了优雅平衡——8 次迭代远少于 AR 的 8T 步,但每次迭代都能利用 lower-codebook 的丰富信息做条件,质量不掉。
实际推理代码框架大致如下:
import torch
@torch.no_grad()
def vall_e_inference(ar_model, nar_model, encodec,
phoneme_ids, prompt_audio,
temperature: float = 1.0, top_k: int = 50):
"""
phoneme_ids : (L_text,) 目标文本的音素 id 序列
prompt_audio: (T_p,) 3 秒参考音频 (24 kHz)
"""
# 1) 把 prompt 音频编码到 8-codebook token: (T_p, 8)
prompt_codes = encodec.encode(prompt_audio) # 等价 75 Hz token
# 2) AR: 自回归生成 codebook 1
context = torch.cat([
phoneme_ids,
torch.tensor([SEP_ID]),
prompt_codes[:, 0], # 仅取 codebook-1
torch.tensor([SEP_ID]),
])
generated_c1 = []
for _ in range(MAX_LENGTH):
logits = ar_model(context)[-1] # (vocab=1025,)
# top-k + temperature 采样
probs = torch.softmax(logits / temperature, dim=-1)
topk_vals, topk_idx = probs.topk(top_k)
next_token = topk_idx[torch.multinomial(topk_vals, 1)]
if next_token == EOS_ID: break
generated_c1.append(next_token)
context = torch.cat([context, next_token.unsqueeze(0)])
C1 = torch.stack(generated_c1) # (T_out,)
# 3) NAR: 逐层并行生成 codebook 2-8
Ck_all = [C1]
for k in range(1, 8): # 7 iterations
# 输入: phoneme + prompt 全部 8 codebook + 已生成的 Ck_all
# 输出: 该层的 T_out 个并行预测
Ck = nar_model(phoneme_ids, prompt_codes,
Ck_all, layer_idx=k) # (T_out,)
Ck_all.append(Ck)
final_codes = torch.stack(Ck_all, dim=1) # (T_out, 8)
# 4) Encodec 解码到 24 kHz 波形
waveform = encodec.decode(final_codes)
return waveform
6. 训练数据与规模
VALL-E 训练数据来自 LibriLight——一个 60,000 小时英语有声书数据集,超过 7,000 个 unique speaker。这比当时最大的精标 ASR 数据集 LibriSpeech (960 小时) 大 60 倍。LibriLight 本身是无标注的,VALL-E 用一个预训练 ASR 模型给所有音频转出 pseudo-phoneme 标签——典型的”用 ASR 给 TTS 造标签“的弱监督策略,与 Whisper 用 Web 字幕训练异曲同工。
训练规模一览:
| 组件 | 架构 | 参数量 | 训练步数 (估) |
|---|---|---|---|
| Encodec (预训练) | SEANet + RVQ-VAE | ~14 M | —(Meta 已开源权重) |
| VALL-E AR | 12-layer Transformer | ~150 M | 800k steps, ~16 V100 GPU 周 |
| VALL-E NAR | 12-layer Transformer | ~150 M | 同上 |
| 合计 | ~300 M |
300M 参数量在 LLM 圈是”婴儿级”,但在当时 TTS 领域已经远超 Tacotron 2 (~30 M)、FastSpeech 2 (~25 M)、VITS (~30 M) 一个数量级——VALL-E 第一次把 TTS 模型规模推到 LLM 量级,证明了 scaling law 在 TTS 上同样成立。
7. 性能数据
| 模型 | 训练数据 | WER (LibriSpeech test-clean) | Speaker Similarity (SECS) | MOS |
|---|---|---|---|---|
| YourTTS (2022) | ~600 h | 7.7 | 0.34 | 3.45 |
| Tortoise TTS (2022) | ~30k h | 6.5 | 0.42 | 3.85 |
| VALL-E (2023) | 60k h | 5.9 | 0.58 | 4.20 |
| NaturalSpeech 3 (2024) | 60k h | 5.6 | 0.63 | 4.30 |
| VALL-E 2 (2024) | 60k h | 1.5* | 0.66 | 4.50 |
| F5-TTS (2024) | 100k h | 2.4 | 0.66 | 4.40 |
| CosyVoice 2 (2024) | 170k h 多语种 | 2.4 | 0.65 | 4.50 |
*VALL-E 2 的 WER 在 librispeech-pc test-clean 上是 1.5,对应人类水平。
VALL-E 的核心突破不在 MOS(与 Tortoise 接近)而在 Speaker Similarity——SECS 从前作的 0.34/0.42 跃升到 0.58,意味着克隆出来的语音被分类器认为”是同一个说话人”的概率几乎翻倍。这是 zero-shot voice cloning 时代真正到来的标志。
8. 已知局限与改进方向
VALL-E 原版有几个被广泛诟病的问题:
- 采样不稳定。AR 采样靠 top-k + temperature,偶尔会跳音素、漏字、加入幻觉词。论文测试显示 LibriSpeech test-clean WER 5.9,但在更复杂的 in-the-wild 语料上 WER 可超过 10。VALL-E 2 用分组 token 采样 + 重复感知采样把 WER 压到 1.5。
- codec 信息损失。Encodec 75 Hz × 8 codebook 编码音频在听感上 OK 但损失高频细节,导致 VALL-E 生成的语音听感略”沙哑”。NaturalSpeech 3 改用更高保真的 FACodec(一种解耦内容/音色/韵律的 codec),生成质量提升明显。
- 韵律控制弱。VALL-E 完全依赖 3 秒 prompt 隐式传递韵律,没有显式的 duration / pitch 控制。后续 NaturalSpeech 3、CosyVoice 2 都加了 explicit prosody token。
- 推理慢。AR 部分每秒音频要生成 75 步,对 10 秒输出就是 750 步,单卡 RTX 3090 上推理需要 ~3 秒。F5-TTS 用 Flow Matching 把这部分压到 16-32 步,速度提升 20-50 倍。
- 仅英语。原版 VALL-E 只训了英文。VALL-E X (2023-03) 把它扩展到多语种 + 跨语种克隆。
9. VALL-E 家族:从 X 到 R 到 2
| 变体 | 提出方/年份 | 关键改动 |
|---|---|---|
| VALL-E X | Microsoft, 2023-03 | 多语种 + 跨语种克隆(中文 prompt 念英文目标) |
| VALL-E R | 2024, ICLR rejected | 用单调对齐约束 (monotonic alignment) 解决 AR 不稳定 |
| VALL-E 2 | Microsoft, 2024-06 | 分组 token 采样 + 重复感知采样,首次声称达到 human parity |
| NaturalSpeech 3 | Microsoft, 2024-03 | FACodec(解耦 content / prosody / timbre / acoustic 4 个属性)+ factorized diffusion |
10. 与 CosyVoice 2 / F5-TTS 的对比
| 维度 | VALL-E | CosyVoice 2 | F5-TTS |
|---|---|---|---|
| 核心范式 | 纯 codec LM (AR+NAR) | LM AR + Flow Matching | 纯 Flow Matching + DiT |
| codec | Encodec (75Hz, 8层) | SenseVoice 监督 semantic token | 不需要 codec(直接生成 mel) |
| 是否需要 phoneme | 是(必需) | 是(可选) | 否(吃 BPE/字符) |
| 推理速度 | 慢 (AR + NAR 两阶段) | 快 (流式) | 极快 (16-32 步) |
| 训练复杂度 | 高(两模型同时训) | 高(多阶段) | 低(单阶段端到端) |
| 音色克隆质量 | ★★★★ | ★★★★★ | ★★★★★ |
| 韵律自然度 | ★★★ | ★★★★★ | ★★★★ |
| 语种支持 | 仅英文 | 原生多语种 | 需 fine-tune |
| 开源情况 | 非官方实现 | 完整开源 | 完整开源 |
实操建议:
- 学术研究、想理解 codec LM 范式 → 看 VALL-E 论文 + 第三方实现(lifeiteng/vall-e、ecker/vall-e)
- 中文 voice agent 生产部署 → CosyVoice 2,原生流式 + 中文最强
- 英文 zero-shot 克隆 demo → F5-TTS,最快上手、效果最好
- 商业级稳定输出 → ElevenLabs API(黑盒但稳定,可视为 VALL-E 2 的工业化版本)
一个不太中听的提醒:VALL-E 是”论文影响力”与”可用性”分离的典型
写到这里必须说一个容易被忽略的事实:微软从未放出 VALL-E 的官方权重和推理代码(以语音克隆滥用风险为由),今天你能跑到的都是社区非官方复现(如 Amphion、VALL-E X 开源实现)。从社区的公开 demo 和 issue 反馈看,复现版与论文 demo 页的差距相当明显——这正是 AR codec LM 路线的固有缺陷在缺少微软规模训练数据时被放大:对 prompt 音质极其敏感、长句容易出现重复/跳词(AR 解码没有显式时长约束)、WER 随文本长度劣化。
所以我的选型判断很直接:今天已经没有理由再从 VALL-E 路线起步。它的历史地位是把”TTS = codec token 语言模型”这个范式打开,但工程上它已被两条路线超越——要 zero-shot 克隆质量,CosyVoice 2 的监督式语义 token 更稳;要训练和推理的简洁性,F5-TTS 的 flow matching 不需要 AR 解码的所有补丁。VALL-E 2 论文宣称的 “human parity” 也要谨慎读:那是 LibriSpeech / VCTK 特定测试集上的相似度与自然度评分,不等于任意场景的克隆质量。读 VALL-E 的正确姿势是把它当成理解 codec LM 范式的教科书,而不是部署候选。
11. 工程化与伦理
VALL-E 的工程化部署有几个独特挑战:
- 两模型部署。AR + NAR 是两个独立 checkpoint,需要 sequential pipeline 调度。生产实现常用一个 Triton inference server 同时挂载两模型,通过 KV cache + speculative decoding 优化 AR 部分。
- codec 量化部署。Encodec 本身就是模型,包含 encoder + RVQ + decoder。INT8 量化后大小约 4 MB,CPU 上可以毫秒级推理,不是瓶颈。
- 音频 token 词表统一。8 个 codebook 共享 1024 词表 → 8K 总词表大小,相比 LLM 的 30K-100K 词表小很多,AR 模型词表头部很轻。
更严肃的问题是伦理风险。3 秒克隆任何人声打开了大规模 deepfake 滥用的潘多拉魔盒——电信诈骗、政治造谣、亲属冒充。微软至今没有公开 VALL-E 的官方权重与 API,理由正是”出于负责任 AI 的考虑”。开源社区有几个仿制实现(GitHub: lifeiteng/vall-e、ecker/vall-e),效果远不如论文报告。F5-TTS、CosyVoice 2 等完整开源的模型实际承担了”民用 VALL-E”的角色——它们在权重发布时都附带了 watermarking 和使用条款,但执行力极弱。这是当代 TTS 工程师必须认真对待的伦理责任。
12. 总结
VALL-E 的真正贡献不是”做出了更好听的 TTS”——单纯听感它和 Tortoise TTS 差距不大。它的贡献在范式翻转:把 TTS 从”声学建模 + 文本到声学映射“这个 30 年沿用的视角,重定义为「在音频 codec token 空间上做 in-context learning 的语言模型问题」。这一重定义带来三个连锁革命:(1)zero-shot 音色克隆变得可行;(2)TTS 享受所有 LLM 时代的工程红利(KV cache、speculative decoding、INT8、Flash Attention);(3)语音 / 文本 / 视觉的 token 化空间正在快速统一,下一代多模态 LLM 完全可能是同一个 Transformer 处理 audio + text + image token。Moshi 已经在做这件事。
VALL-E 与我之前写过的 Whisper 形成一组完美对偶——Whisper 是「语音 → token → 文本」(弱监督编码器),VALL-E 是「文本 → token → 语音」(弱监督解码器)。两者的训练数据、模型规模、范式哲学几乎一模一样,只是输入输出对调。把它们与 Wav2Vec/HuBERT/WavLM(自监督预训练)、Streaming ASR(部署架构)一起读,你应该能感受到 2020–2025 年语音 AI 已经完成了一次完整的范式重组——所有方向都在向「audio = token sequence」 这一统一空间收敛。下一篇我会继续在 TTS 主线上写 《Neural Audio Codec 详解》,把 Encodec / DAC / Mimi / WavTokenizer 这些”现代 TTS 的分词器”彻底拆透——它们是这场范式革命的真正底座。
参考资料
- Wang, C. et al. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers (VALL-E). arXiv:2301.02111, 2023.
- Zhang, Z. et al. Speak Foreign Languages with Your Own Voice: Cross-Lingual Neural Codec Language Modeling (VALL-E X). arXiv:2303.03926, 2023.
- Chen, S. et al. VALL-E 2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers. arXiv:2406.05370, 2024.
- Défossez, A. et al. High Fidelity Neural Audio Compression (Encodec). arXiv:2210.13438, 2022.
- Ju, Z. et al. NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models. arXiv:2403.03100, 2024.
- Han, B. et al. VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment. arXiv:2406.07855, 2024.
- Borsos, Z. et al. AudioLM: a Language Modeling Approach to Audio Generation. arXiv:2209.03143, 2022.(codec LM 的更早探索)
- 非官方实现:lifeiteng/vall-e、enhuiz/vall-e
- Encodec 官方实现:facebookresearch/encodec
- Amphion(含 VALL-E 非官方复现): github.com/open-mmlab/Amphion
![]()
2025-10-17 at 5:12 下午
读完立刻去试了 F5-TTS 的 demo,确实 16 步出声、效果惊人。