转载本文请注明出处:https://yudonglee.me/whisper-explained/ | 作者:yudonglee
📝 本文首发于 2024 年 11 月。最近一次修订于 2026 年 6 月:更新了部署生态对比与工程实践章节。
2022 年 9 月,OpenAI 发布了 Whisper——一个用 68 万小时弱监督音频训练的通用语音识别模型。它把语音识别(ASR)、语音翻译、语种识别和语音活动检测 (VAD) 用同一个 encoder-decoder Transformer 解决,并以接近人类水平的鲁棒性在 zero-shot 场景下吊打了大量「精雕细琢」的传统 pipeline 系统。
本文是一篇彻底的技术拆解:从 整体架构、音频预处理、Multitask 训练范式,到 PyTorch 源码逐段精读 和 性能 / 生态对比,并配 SVG 原理图、参数表与可运行代码。读完你将能回答两个问题:
- Whisper 为什么能 work——它和 CTC、RNN-T 这些经典 ASR 路线在算法上有哪些根本差异?
- 如果让你把 Whisper 部署到真实业务,应该选
large-v3、turbo、distil-whisper还是faster-whisper?为什么?
1. 背景:Whisper 解决了什么问题
传统 ASR 系统通常包含三个相对独立的模块——声学模型 (Acoustic Model)、发音词典 (Lexicon)、语言模型 (Language Model)——再通过 WFST 解码图把它们串起来。这条路线工程性强、可控性高,但对 领域漂移 (domain shift)、口音、背景噪声 极其敏感,每进入一个新场景都需要重新对齐声学单元、重训发音字典、重打 N-gram LM。
2018 年前后,CTC(参见我之前的 CTC 系列三篇)与 RNN-Transducer 把声学和对齐统一进神经网络,端到端方案逐渐统治了学术 benchmark。但这些模型仍然依赖人工精标的有监督数据 (LibriSpeech 1k 小时、AISHELL 1k 小时等),规模上限低、跨域能力弱。
Whisper 走了第三条路:大规模弱监督 (Large-Scale Weak Supervision)。OpenAI 从互联网抓取了 680,000 小时 多语种音频和对应文本——其中 65% 是英语音频+英语文本,18% 是非英语音频+英语翻译,17% 是非英语音频+对应语种文本,覆盖 99 种语言(98 种非英语 + 英语)。所有数据用启发式规则清洗,剔除机器生成的字幕、严重不对齐的转录,再用一个统一的 sequence-to-sequence Transformer,把多种任务编码成 token 序列共同训练。
这种「数据规模 × 任务多样性 × 弱监督」的组合,让 Whisper 在 零样本 (zero-shot) 场景下首次达到甚至超过专门微调过的有监督模型——例如在 LibriSpeech test-other 上无需任何微调就能取得 3.91% 的 WER。
对比一下三种路线的本质差异,能帮助理解 Whisper 的取舍:
| 路线 | 损失函数 | 对齐方式 | 语言模型 | 数据需求 | 典型代表 |
|---|---|---|---|---|---|
| HMM-DNN 混合 | 交叉熵 + LF-MMI | 显式 (GMM-HMM Viterbi) | 外部 n-gram + WFST | 千小时精标 | Kaldi nnet3 |
| CTC | CTC loss (前向后向) | 所有可行对齐求和 | 可选外接 | 千小时精标 | DeepSpeech |
| RNN-Transducer | RNN-T loss | 联合网络隐式对齐 | 内部 prediction net | 千小时精标 | Google streaming ASR |
| Attention Seq2Seq | 交叉熵 (teacher forcing) | cross-attention 隐式 | 解码器自带 | 百~千小时 | LAS, Whisper |
Whisper 选了第四条 attention seq2seq 路线,并把数据规模从「百~千小时精标」推到「十万小时弱标」。这条路在 2017 年 LAS 时期被认为不如 CTC/RNN-T 稳——长音频容易丢字、容易幻觉。Whisper 用三个工程招式把它救了回来:(1)30 秒固定窗口避免任意长序列对齐崩溃;(2)特殊的 timestamp token 把对齐信息纳入解码本身;(3)温度回退 + 压缩比阈值在推理期兜底幻觉。这三招值得 ASR 工程师细细体会。
2. 整体架构总览
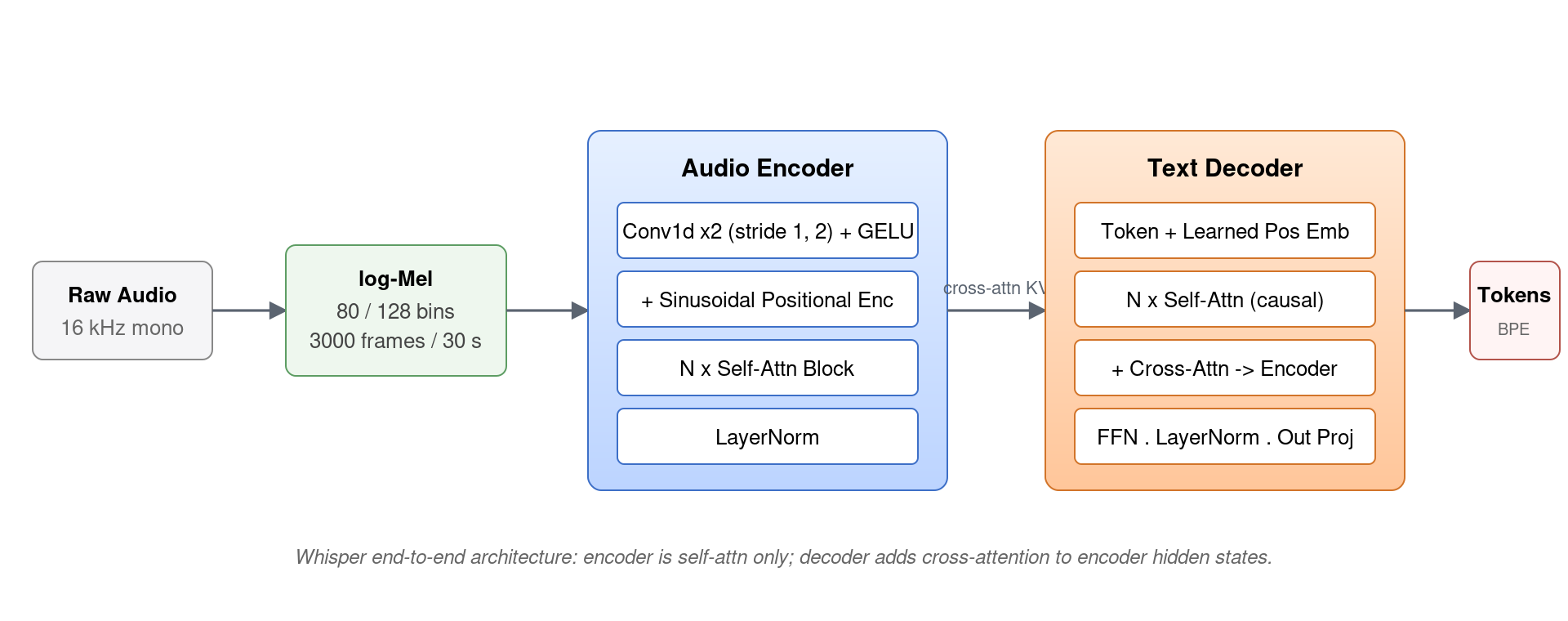
从图 1 可以看到 Whisper 的设计非常「Transformer 教科书」:没有 CTC 损失、没有 Transducer、没有外部语言模型。它就是一个标准的 encoder-decoder Transformer,编码器只用 self-attention 处理声学序列,解码器用 self-attention + cross-attention 自回归生成文本 token。所有多任务都通过特殊 token 在解码器输入端「装配」。
这种极简设计的代价是 30 秒固定上下文——任何更长的音频必须用 sliding window 切分;好处是模型实现极简、可移植性极强(whisper.cpp 项目能用纯 C++ 跑在树莓派上正是因为架构无任何花哨结构)。
3. 输入预处理:从 raw audio 到 log-Mel 频谱
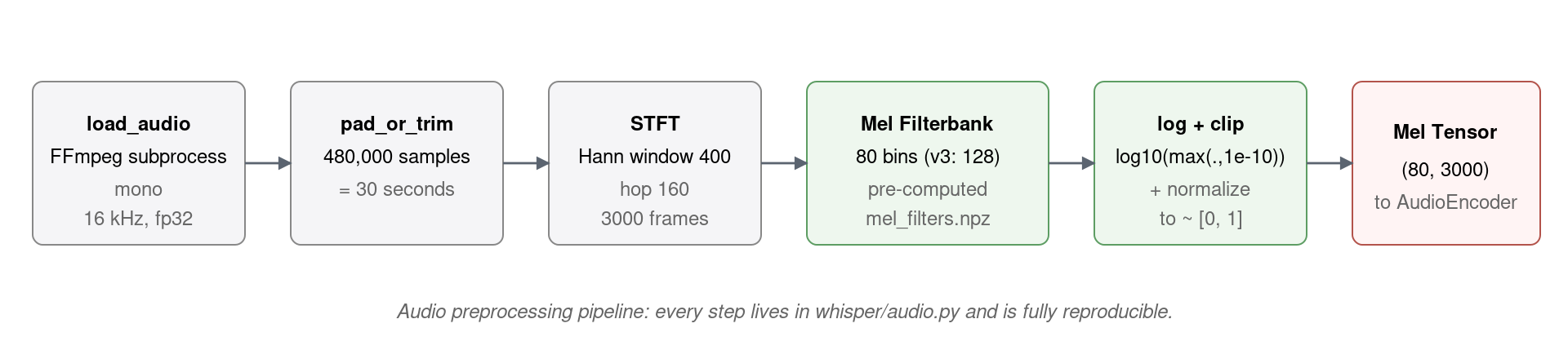
Whisper 的预处理可以一字不差地写下来——它就是一套硬编码常量。下表是所有关键超参数(出自 whisper/audio.py):
| 常量 | 取值 | 物理含义 |
|---|---|---|
SAMPLE_RATE |
16000 | 统一重采样到 16 kHz |
N_FFT |
400 | STFT 窗长 (25 ms) |
HOP_LENGTH |
160 | STFT 步长 (10 ms) |
CHUNK_LENGTH |
30 | 单次输入秒数 |
N_SAMPLES |
480000 | = 30 × 16000 |
N_FRAMES |
3000 | = 30 × 100 (10 ms 一帧) |
N_MELS |
80 / 128 | large-v3 升级至 128 |
FRAMES_PER_SECOND |
100 | STFT 后帧率 |
TOKENS_PER_SECOND |
50 | Encoder 第二层 stride=2 后 |
N_SAMPLES_PER_TOKEN |
320 | = HOP_LENGTH × 2,即 20 ms |
核心函数 log_mel_spectrogram 的简化实现等价于:
import torch
import torch.nn.functional as F
SAMPLE_RATE = 16000
N_FFT = 400
HOP_LENGTH = 160
N_MELS = 80 # large-v3 用 128
# Whisper 把 librosa 生成的 mel filterbank 序列化到 assets/mel_filters.npz
# 这里直接用 torchaudio 重算,结果数值上一致。
import torchaudio
MEL_FB = torchaudio.functional.melscale_fbanks(
n_freqs=N_FFT // 2 + 1, f_min=0.0, f_max=SAMPLE_RATE / 2,
n_mels=N_MELS, sample_rate=SAMPLE_RATE, mel_scale="slaney", norm="slaney",
).T # shape: (n_mels, n_freqs)
def log_mel_spectrogram(audio: torch.Tensor) -> torch.Tensor:
"""audio: 1-D float tensor, shape (n_samples,) → (n_mels, n_frames)"""
window = torch.hann_window(N_FFT, device=audio.device)
stft = torch.stft(audio, N_FFT, HOP_LENGTH,
window=window, return_complex=True)
magnitudes = stft[..., :-1].abs() ** 2 # 丢掉最后一帧 → 3000
mel_spec = MEL_FB.to(audio.device) @ magnitudes # (n_mels, n_frames)
log_spec = torch.clamp(mel_spec, min=1e-10).log10()
log_spec = torch.maximum(log_spec, log_spec.max() - 8.0) # dynamic range clip
log_spec = (log_spec + 4.0) / 4.0 # rescale to ~[0,1]
return log_spec
三个细节值得注意:
- 丢掉最后一帧。原始 STFT 输出 3001 帧(30 s 含起始帧),Whisper 取前 3000 帧,恰好对应
N_FRAMES = CHUNK_LENGTH × FRAMES_PER_SECOND。 - 动态范围裁剪到 80 dB(
log_spec.max() - 8),既防止极小数值塌缩,也使训练分布稳定。 - 线性归一化到大约 [0, 1],没有做按帧 mean/var 归一化——这是 Whisper 与许多传统系统的差异之一,因为大数据可以让模型自己学到鲁棒的统计特性。
为什么选 log-Mel 而不是直接喂 waveform 或老牌 MFCC?三个原因:(1)Mel 滤波器组在感知上更接近人耳,对低频精细、高频粗糙的分布更适合语音;(2)取对数把幅度的乘性变化(音量、距离麦克风远近)转成加性,模型对响度更鲁棒;(3)MFCC 的 DCT 步骤反而丢信息,在深度学习时代 conv/attention 自己能学到比 DCT 系数更好的特征,所以 Whisper 跳过了 DCT 直接用 Mel filterbank。这种「让神经网络做特征提取,但保留一个有物理意义的中间表示」的折衷已经成为现代 ASR/音频建模的事实标准。
4. Audio Encoder:从频谱到声学表示
Encoder 的任务是把 (80, 3000) 的 log-Mel 映射成一段固定长度的连续表示 (1500, d_model)。它由「双卷积下采样 + 正弦位置编码 + N 层 self-attention block」组成。Encoder 内部没有 cross-attention,结构更像 ViT 的纯 self-attention 栈。
import torch
import torch.nn as nn
def sinusoids(length: int, channels: int, max_timescale: float = 10000.0):
"""Whisper 风格的正弦位置编码(与 Vaswani 等价但写法略简)。"""
assert channels % 2 == 0
log_ts_increment = torch.log(torch.tensor(max_timescale)) / (channels // 2 - 1)
inv_ts = torch.exp(-log_ts_increment * torch.arange(channels // 2))
scaled = torch.arange(length)[:, None] * inv_ts[None, :]
return torch.cat([torch.sin(scaled), torch.cos(scaled)], dim=1) # (length, channels)
class AudioEncoder(nn.Module):
def __init__(self, n_mels: int, n_ctx: int, d_model: int,
n_heads: int, n_layers: int):
super().__init__()
# 两层 1D 卷积,第二层 stride=2 → 3000 frames 下采样到 1500
self.conv1 = nn.Conv1d(n_mels, d_model, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(d_model, d_model, kernel_size=3, stride=2, padding=1)
# 注册为 buffer,不参与训练
self.register_buffer("positional_embedding", sinusoids(n_ctx, d_model))
self.blocks = nn.ModuleList([
ResidualAttentionBlock(d_model, n_heads) for _ in range(n_layers)
])
self.ln_post = nn.LayerNorm(d_model)
def forward(self, x: torch.Tensor): # x: (batch, n_mels, n_frames)
x = nn.functional.gelu(self.conv1(x))
x = nn.functional.gelu(self.conv2(x)) # (B, d_model, n_ctx)
x = x.permute(0, 2, 1) # (B, n_ctx, d_model)
x = x + self.positional_embedding # 加位置编码
for block in self.blocks:
x = block(x)
return self.ln_post(x) # (B, n_ctx=1500, d_model)
注意两个工程细节:
- 位置编码用正弦而不是学习式——这让 encoder 在变长输入下也能外推(虽然 Whisper 在训练时固定 30 s)。解码器则用学习式位置编码,因为文本侧需要更精细的局部依赖建模。
- 下采样靠 conv2 的 stride=2,所以 encoder 输出帧率是 50 fps,即每 20 ms 一个声学 token——这也是
N_SAMPLES_PER_TOKEN=320的由来。
5. ResidualAttentionBlock:encoder/decoder 公用积木
encoder 和 decoder 共享同一个 ResidualAttentionBlock 实现,区别仅在于解码器侧 cross_attention=True:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, n_heads: int):
super().__init__()
self.n_heads = n_heads
self.query = nn.Linear(d_model, d_model)
self.key = nn.Linear(d_model, d_model, bias=False)
self.value = nn.Linear(d_model, d_model)
self.out = nn.Linear(d_model, d_model)
def forward(self, x, xa=None, mask=None, kv_cache=None):
q = self.query(x)
if xa is None: # self-attention
k, v = self.key(x), self.value(x)
else: # cross-attention
k, v = self.key(xa), self.value(xa)
return self._sdpa(q, k, v, mask)
def _sdpa(self, q, k, v, mask):
B, T, C = q.shape
H, D = self.n_heads, C // self.n_heads
q = q.view(B, T, H, D).transpose(1, 2)
k = k.view(B, -1, H, D).transpose(1, 2)
v = v.view(B, -1, H, D).transpose(1, 2)
# 推荐用 torch.nn.functional.scaled_dot_product_attention,自动走 FlashAttention
out = nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=mask)
return self.out(out.transpose(1, 2).reshape(B, T, C))
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_heads: int, cross_attention: bool = False):
super().__init__()
self.attn_ln = nn.LayerNorm(d_model)
self.attn = MultiHeadAttention(d_model, n_heads)
self.cross_attn_ln = nn.LayerNorm(d_model) if cross_attention else None
self.cross_attn = MultiHeadAttention(d_model, n_heads) if cross_attention else None
n_mlp = d_model * 4
self.mlp_ln = nn.LayerNorm(d_model)
self.mlp = nn.Sequential(
nn.Linear(d_model, n_mlp), nn.GELU(), nn.Linear(n_mlp, d_model)
)
def forward(self, x, xa=None, mask=None):
x = x + self.attn(self.attn_ln(x), mask=mask)
if self.cross_attn is not None:
x = x + self.cross_attn(self.cross_attn_ln(x), xa=xa)
x = x + self.mlp(self.mlp_ln(x))
return x
三点观察:(1)采用 Pre-LayerNorm 结构,训练更稳;(2)MLP 4× 扩展,遵循 Vaswani 原始比例;(3)key 投影 bias=False,这是 GPT-2 等 OpenAI 内部模型的一贯做法,节省参数且对效果无影响。
6. Text Decoder & Multitask Token 格式
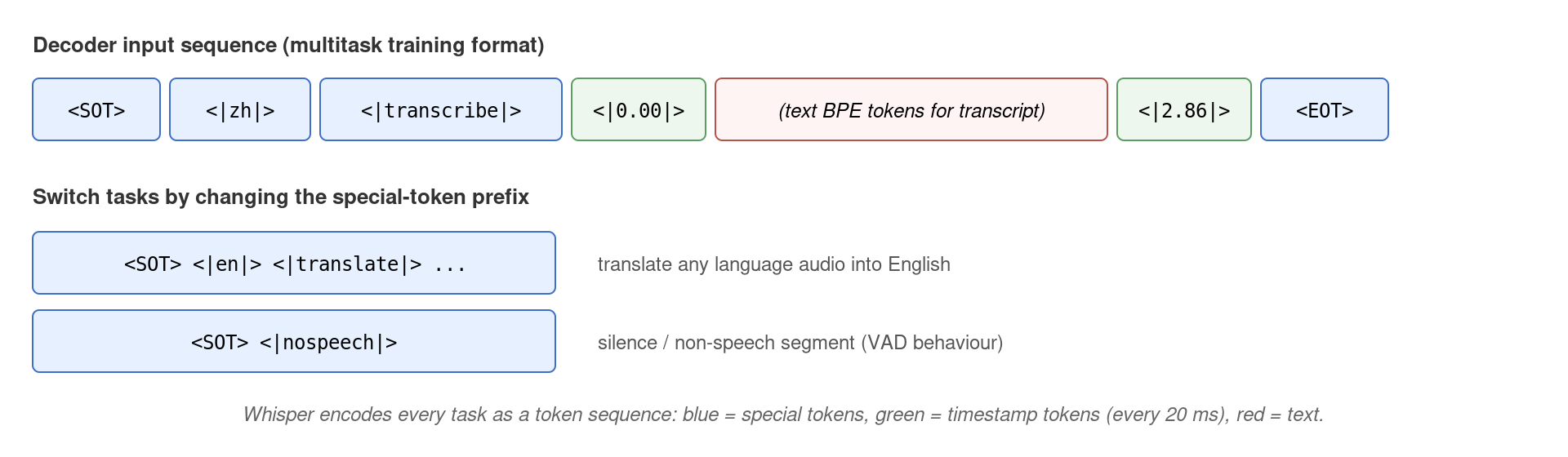
这是 Whisper 最优雅的设计——用同一个解码器,靠输入端 prompt 切换任务。关键 special token 包括:
| Token | 作用 |
|---|---|
<|startoftranscript|> |
解码起点 |
<|en|> / <|zh|> / ... |
99 个语种 token |
<|transcribe|> / <|translate|> |
转录 or 翻译 |
<|notimestamps|> |
不输出时间戳 |
<|0.00|> … <|30.00|> |
1501 个时间戳 token,步长 0.02 s |
<|nospeech|> |
静音段(VAD) |
<|endoftranscript|> |
解码结束 |
Tokenizer 采用 OpenAI tiktoken(GPT-2 的多语言 BPE 扩展),多语言版词表大小 n_vocab=51865(large-v3 因新增广东话 token 增至 51866),其中前 50,257 为继承自 GPT-2 的文本 BPE token,其余为多任务 special token + 1501 个时间戳 token。
解码器实现与编码器对偶,唯一新增的是 因果掩码:
class TextDecoder(nn.Module):
def __init__(self, n_vocab, n_ctx, d_model, n_heads, n_layers):
super().__init__()
self.token_embedding = nn.Embedding(n_vocab, d_model)
self.positional_embedding = nn.Parameter(torch.empty(n_ctx, d_model))
self.blocks = nn.ModuleList([
ResidualAttentionBlock(d_model, n_heads, cross_attention=True)
for _ in range(n_layers)
])
self.ln = nn.LayerNorm(d_model)
mask = torch.empty(n_ctx, n_ctx).fill_(float("-inf")).triu_(1)
self.register_buffer("mask", mask, persistent=False)
def forward(self, tokens, audio_features, kv_cache=None):
offset = next(iter(kv_cache.values())).shape[1] if kv_cache else 0
x = self.token_embedding(tokens) \
+ self.positional_embedding[offset:offset + tokens.shape[-1]]
for block in self.blocks:
x = block(x, xa=audio_features, mask=self.mask)
x = self.ln(x)
# 共享 token embedding 的转置作为输出投影,是 GPT-2 的 trick
logits = x @ self.token_embedding.weight.T
return logits
注意最后一行——Whisper 沿用了 GPT-2 的 weight tying,把 token embedding 矩阵的转置直接作为输出层 logits 投影。这一节省了 n_vocab × d_model 个参数,并被证明对小词表语言模型有正则化效果。
7. 模型变体维度表
Whisper 一共开源了 9 个 checkpoint(4 个英文版 + 5 个多语言版 + turbo),它们共享同一个 ModelDimensions 数据类,只是数值不同:
| Size | Params | Audio / Text Layers | Audio / Text Width | Heads | VRAM | Relative speed |
|---|---|---|---|---|---|---|
| tiny | 39 M | 4 / 4 | 384 / 384 | 6 | ~1 GB | ~10× |
| base | 74 M | 6 / 6 | 512 / 512 | 8 | ~1 GB | ~7× |
| small | 244 M | 12 / 12 | 768 / 768 | 12 | ~2 GB | ~4× |
| medium | 769 M | 24 / 24 | 1024 / 1024 | 16 | ~5 GB | ~2× |
| large / large-v2 / large-v3 | 1550 M | 32 / 32 | 1280 / 1280 | 20 | ~10 GB | 1× |
| turbo (large-v3-turbo) | 798 M | 32 / 4 | 1280 / 1280 | 20 | ~6 GB | ~8× |
Turbo 的窍门极为巧妙——保留完整 32 层 encoder,把 decoder 砍到 4 层。由于 Whisper 推理瓶颈在于自回归解码,砍 decoder 直接把延迟降到八分之一,而 WER 损失极小(在多数语种上 < 0.3 个 WER)。这与 distil-whisper 的思路一致,但 distil-whisper 用了知识蒸馏 + SpecAugment 数据增强,而 turbo 是直接 fine-tune 的产物。
large-v2(2022-12)与 large-v3(2023-11)的差异主要在 训练数据规模:v3 在 100 万小时弱标注音频 + 400 万小时 v2 伪标注音频上重训了 2 个 epoch,多语种 WER 平均下降 10%–20%。结构上 v3 仅有两处改动:Mel bins 由 80 升至 128、新增广东话 token。
8. 解码策略:温度回退与时间戳预测
Whisper 的解码绝非简单 beam search。在 whisper/decoding.py 与 transcribe.py 中,OpenAI 设计了一套温度回退 (temperature fallback) 启发式(默认参数取自官方实现 transcribe.py):
- 从
temperature=0.0(默认 beam_size=5)开始解码; - 计算结果的 zlib 压缩比,若 >
compression_ratio_threshold(默认2.4)视为陷入重复退化; - 计算 token 平均 log-prob,若 <
logprob_threshold(默认-1.0)视为低质量; - 命中以上任一条件,将温度按
(0.0, 0.2, 0.4, 0.6, 0.8, 1.0)序列递增后重新解码; - 若
<|nospeech|>概率 >no_speech_threshold(默认0.6)且平均 log-prob 仍低于阈值,则该段输出空文本。
这套回退机制是 Whisper 抗幻觉的关键工程手段——纯神经语言模型在静音段或低 SNR 时极易「编造」流畅但虚假的内容,温度回退用统计指标兜底。
时间戳预测则被建模成普通 token 预测:1500 个 <|t.tt|> 时间戳 token 与文本 token 共享词表。模型在自回归过程中自然学到「文本 token 之间插入时间戳 token」的格式。后处理时把相邻时间戳 token 转成 segment 边界即可。词级时间戳进一步通过分析 cross-attention 矩阵 + DTW (Dynamic Time Warping) 提取,详见 timing.py。
词级对齐的核心思想是:cross-attention 中某个文本 token 对哪些 audio frame 投放的权重最大,这些 frame 的时间就是该词的发音区间。具体步骤是——(1)从 decoder 的指定层 (alignment_heads) 抽出 cross-attention 矩阵 A,形状 (n_text, n_audio=1500);(2)对每个文本 token 求其 attention 概率分布;(3)在 token-frame 二维栅格上跑 DTW,找出单调对齐路径;(4)路径的转折点即为词边界,乘以 20 ms 还原为秒。这一方法不需要额外训练对齐器,是 Whisper 「Token + 时间戳一体」设计的副产品。
另一个常被忽略的工程细节是 SuppressTokens:解码器维护一份「禁止生成」的 token 列表,包括所有 special token、所有时间戳 token(在 without_timestamps=True 模式下)、以及一些可能引发 hallucination 的标记(如 <|nospeech|>)。这套机制通过在 logits 上加 -inf 实现,避免了贪心/beam search 走偏。
9. 性能数据
大模型在 Hugging Face Open ASR Leaderboard 上的官方结果如下(数字均为 WER%,越低越好):
| 数据集 | large-v3 WER% | 说明 |
|---|---|---|
| Mean (8 datasets) | 7.44 | 综合平均 |
| LibriSpeech clean | 2.01 | 朗读,理想信道 |
| LibriSpeech other | 3.91 | 较高难度 |
| SPGISpeech | 2.94 | 金融电话会议 |
| GigaSpeech | 10.02 | YouTube/Podcast |
| Earnings22 | 11.29 | 多口音财报 |
| AMI | 15.95 | 会议远场 |
RTFx(real-time factor)方面,large-v3 在 A100 上能达到 ~145×——即 1 秒钟可处理 145 秒音频,已经满足绝大多数离线场景。
10. 一段可运行的端到端 PyTorch 代码
下面 20 行代码即可完成「读音频 → 提 mel → 编码 → 解码」全链路(依赖官方 openai-whisper 包):
import whisper
# 1. 加载模型(首次会自动下载到 ~/.cache/whisper/)
model = whisper.load_model("turbo") # tiny | base | small | medium | large-v3 | turbo
# 2. 加载音频并 pad/trim 到 30 s
audio = whisper.load_audio("sample.mp3")
audio = whisper.pad_or_trim(audio)
# 3. 计算 log-Mel 频谱(注意 large-v3 / turbo 需 n_mels=128)
mel = whisper.log_mel_spectrogram(audio, n_mels=model.dims.n_mels).to(model.device)
# 4. 自动识别语种
_, probs = model.detect_language(mel)
detected = max(probs, key=probs.get)
print(f"detected language: {detected}")
# 5. 解码(默认 beam=5、温度回退到 1.0)
options = whisper.DecodingOptions(language=detected, task="transcribe",
without_timestamps=False)
result = whisper.decode(model, mel, options)
print(result.text)
若要处理任意长度音频并自动切窗,直接调用高层 API:
result = model.transcribe("long_audio.wav",
verbose=False,
word_timestamps=True,
condition_on_previous_text=False)
for seg in result["segments"]:
print(f"[{seg['start']:.2f} → {seg['end']:.2f}] {seg['text']}")
关闭 condition_on_previous_text 是一个实战 tip——它能在长音频里 显著降低幻觉传播,代价是上下文连贯性略下降。OpenAI 在 transformers pipeline 中也把它的默认值改为了 False。
部署栈各就各位:先校准口径,再下结论
上面那张生态对比表我建议不要直接照搬数字做决策。这四条部署路线在我看来定位其实非常清楚:faster-whisper 是 CTranslate2 对推理图的重写,INT8/FP16 量化加上更紧凑的内存布局,是「云端生产部署」的默认答案;whisper.cpp 解决的是「没有 Python、没有 CUDA」的环境问题,它的价值在可移植性而非绝对速度;WhisperX 的高倍数加速主要来自 VAD 预切分之后的 batch 并行,本质是吞吐优化,单条音频的延迟并不会同比例下降;HF transformers 则胜在生态接口和 fine-tune 链路,把它当推理引擎用并不是它的长项。
更值得警惕的是社区 benchmark 的口径差异。读任何一份「加速 N 倍」的报告之前,我认为至少要追问三件事:
- 基线是谁——对比对象是原版 openai-whisper 的 FP32,还是同框架自身的 FP16?前者得出的倍数天然好看;
- 有没有 batch——batch 推理对吞吐型离线任务有意义,但对实时字幕这种单流低延迟场景,batch 带来的倍数基本不可兑现;
- 量化是否连着 WER 一起报——只报速度不报精度的 INT8 数字,等于只给了半张成绩单。
我的判断是:先固定自己业务的硬件型号、延迟预算和音频形态,再去找口径一致的对比数据;顺序反过来,就很容易被一个与你场景无关的「70×」带偏选型。
11. Whisper 生态对比
| 实现 | 核心技术 | 速度 (vs openai-whisper) | 显存 | 适用场景 |
|---|---|---|---|---|
openai/whisper |
纯 PyTorch 参考实现 | 1× | 原始 | 研究、复现论文 |
large-v3-turbo |
decoder 由 32 层缩至 4 层 | ~8× | ~6 GB | 对延迟敏感的转录 |
| faster-whisper | CTranslate2 + INT8/FP16 | 4–5× | ↓ 50% | 生产部署,CPU 也能跑 |
| distil-whisper | 知识蒸馏,2 层 decoder | ~6× | ↓ 50% | 英语为主,延迟极敏感 |
| WhisperX | + 强制对齐 + 说话人分离 | ~70×(batch + VAD 切分) | 中 | 需要词级时间戳/diarization |
| whisper.cpp | 纯 C/C++ + GGML 量化 | 设备依赖 | 极低 | iOS / Android / 边缘 |
实战取舍建议:
- 云端长音频离线转录:
faster-whisper large-v3+ INT8,性价比最高。 - 实时字幕:
turbo或distil-large-v3,配合 streaming chunking。 - 多说话人会议:
WhisperX+ pyannote diarization。 - 手机端离线:
whisper.cpp+ Q5_0 量化,base即可在 iPhone 上实时跑。 - 翻译任务:必须用
large/large-v2/large-v3——turbo 没有训练翻译任务,对--task translate会回退到原语种。
12. 已知局限与工程坑
- 幻觉 (Hallucination):弱监督本质决定了 Whisper 会「补全」它认为合理的文本。在静音、低 SNR、纯背景音乐段尤为明显。缓解:温度回退 +
no_speech_threshold调高 + 用 VAD 预切。 - 重复循环:解码进入死循环输出同一段。缓解:开启
compression_ratio_threshold、调高temperature上限。 - 30 秒上下文上限:跨窗口的代词指代、专有名词一致性需要后处理。
condition_on_previous_text=True可缓解但会传播幻觉。 - 低资源语言:训练数据<1k 小时的语言(如部分非洲语言)WER 仍很高,需 fine-tune。
- 说话人无关:模型不提供 diarization,需要 WhisperX 或外部模块。
- 实时性:原生 Whisper 不是流式模型;要做 streaming 需要外部 VAD + 滑窗投票(whisper-streaming 等项目即是这一思路)。
13. 总结
Whisper 的成功本质上不是「某个网络结构有多新」——它的 encoder/decoder Transformer 是 2017 年就有的标准设计——而是 大规模弱监督数据 + 多任务 token 统一 这两条工程哲学的胜利。它把传统 ASR 系统里需要 5–6 个独立模块的能力(声学建模、语言建模、解码器、翻译、VAD、语种识别)压缩进 一个 自回归模型,并通过特殊 token 在 prompt 层组合任务。这种「Everything is a Token Prediction Problem」的思路,与今天的 LLM-as-Universal-Interface 路线在精神上完全一致。
对工程师而言,Whisper 提供了一份「无脑也能 work」的 ASR 基线:换个模型 size、加一个 prompt,即可应对绝大多数语音转文本场景。当你需要进一步压榨延迟或服务边缘设备时,turbo / faster-whisper / distil-whisper / whisper.cpp 这套生态已经把工程化路径铺好——这也是为什么发布三年后,Whisper 依然是开源 ASR 领域事实上的 de facto standard。
如果你对 Whisper 的训练细节、对齐机制、词级时间戳推导感兴趣,建议精读论文附录 D;如果你想动手 fine-tune,HuggingFace 提供了完整 教程,5 小时标注数据即可让 WER 在垂直领域下降 30%+。
参考资料
- Radford et al., Robust Speech Recognition via Large-Scale Weak Supervision, arXiv:2212.04356, 2022.
- OpenAI Whisper 官方代码与 Model Card:github.com/openai/whisper
- Hugging Face whisper-large-v3 模型页与评测结果
- SYSTRAN, faster-whisper(CTranslate2 加速)
- HuggingFace, distil-whisper(蒸馏版)
- Gandhi et al., Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling, 2023.
- OpenAI Whisper DeepWiki:deepwiki.com/openai/whisper
![]()
2024-12-14 at 5:29 下午
感谢分享,总结的很详细