转载本文请注明出处:https://yudonglee.me/streaming-asr-explained/ | 作者:yudonglee
📝 本文首发于 2025 年 8 月。最近一次修订于 2026 年 6 月:更新了端到端语音 LLM 路线对比与工程实践内容。
2024 年是流式 ASR 的「文艺复兴」之年——OpenAI 发布 Realtime API、Google 推出 Gemini Live、Kyutai 开源 Moshi(端到端语音 LLM,理论延迟仅 160 ms)。Voice Agent 一夜之间从科幻变成产品形态,而支撑这一切的根基依然是低延迟流式语音识别:必须在用户讲话的当下就把字一个一个吐出来,否则后面的 LLM、TTS、对话系统都失去意义。
本文是 CTC 系列 → Whisper → RNN-T → Conformer → SSL 三部曲 这条语音线索的第 8 篇,从工程视角彻底拆透「怎么把一个为离线设计的 ASR 模型改成可流式」。读完你将能回答:
- 把一个 Conformer-Transducer 改成流式,需要动哪些模块?分别有什么代价?
- Whisper / Conformer / RNN-T 三种架构在流式部署上的取舍是什么?什么场景该选谁?
- Moshi / GPT-4o Realtime 这类端到端语音 LLM 的「200 ms 延迟」是怎么算出来的?流式 ASR 在里面扮演什么角色?
1. 背景:流式 ASR 究竟有多难
「流式 ASR」最朴素的定义是:用户说话的同时,模型实时输出文字,不必等用户说完整句。这听起来似乎只是把离线模型加个 partial output 接口,但工程上要解决三个互相耦合的问题:
- 算法延迟 (Algorithmic Latency)。模型为了产出某一帧的预测,需要等多久的「未来」音频?严格因果模型 = 0;带 1 秒 look-ahead = 1000 ms。
- 计算延迟 (Computation Latency)。算这一帧需要多少 wall-clock 时间?取决于模型大小、硬件、批处理策略。两者之和是用户感知到的「首字延迟」(First Token Latency)。
- 端点检测 (Endpointing)。怎么判断「用户说完了」,从而让对话系统进入 LLM 思考阶段?早了截断、晚了反应慢,体验差异巨大。
工业界对 voice agent 的体验门槛是首字延迟 < 500 ms、端点延迟 < 300 ms。Moshi 这类端到端语音 LLM 把整链路压到 200 ms 以内才算「自然对话」。下面我们逐层拆解,看哪些模块在阻碍我们达到这个目标。
2. 流式三大「天敌」
把一个为 LibriSpeech 离线训练的 Conformer-Transducer 拿到流式环境跑,会立刻撞上三个结构性障碍:
- 双向 Self-Attention。Encoder 中每帧 attention 默认看全序列,未来帧也算在里面。意味着模型必须等整段音频才能算出第一帧的输出——算法延迟 = 音频总长。
- 双向卷积。Conformer 的 Convolution Module 用中心 padding(kernel=31 时 padding=15),意味着算 t 时刻输出要用到 t+15 帧的未来——算法延迟 = 15 帧 × 10 ms = 150 ms 一层;17 层叠加最坏可达 2.5 s。
- BatchNorm。Conv Module 内的 BN 统计依赖整段序列,流式时无法稳定计算 mean/var——会导致输出分布漂移。
三个问题各有对应解法:把 self-attention 改成chunked attention,把双向卷积改成causal/streaming conv,把 BatchNorm 换成LayerNorm。这三个改造每一个单独都能让模型跑起来,但一起做才能把延迟和精度同时压到可用区间——它们是耦合优化,不是独立选择。
更微妙的是,RNN-T 和 CTC 这两种损失函数天然适合流式——CTC 每帧独立输出、RNN-T 严格单调对齐,二者都不依赖未来 token。而 attention-based seq2seq(如 Whisper、LAS)的解码器是非单调的,cross-attention 可以任意跳到未来 encoder 帧,根本不存在「流式解码」的自然语义。这也是为什么工业流式 ASR 几乎全是「Conformer encoder + RNN-T decoder」的组合——损失函数侧已经自带流式属性,只需要把 encoder 改造成 chunk-aware。
3. Chunked Attention:把序列切块、各看各的未来
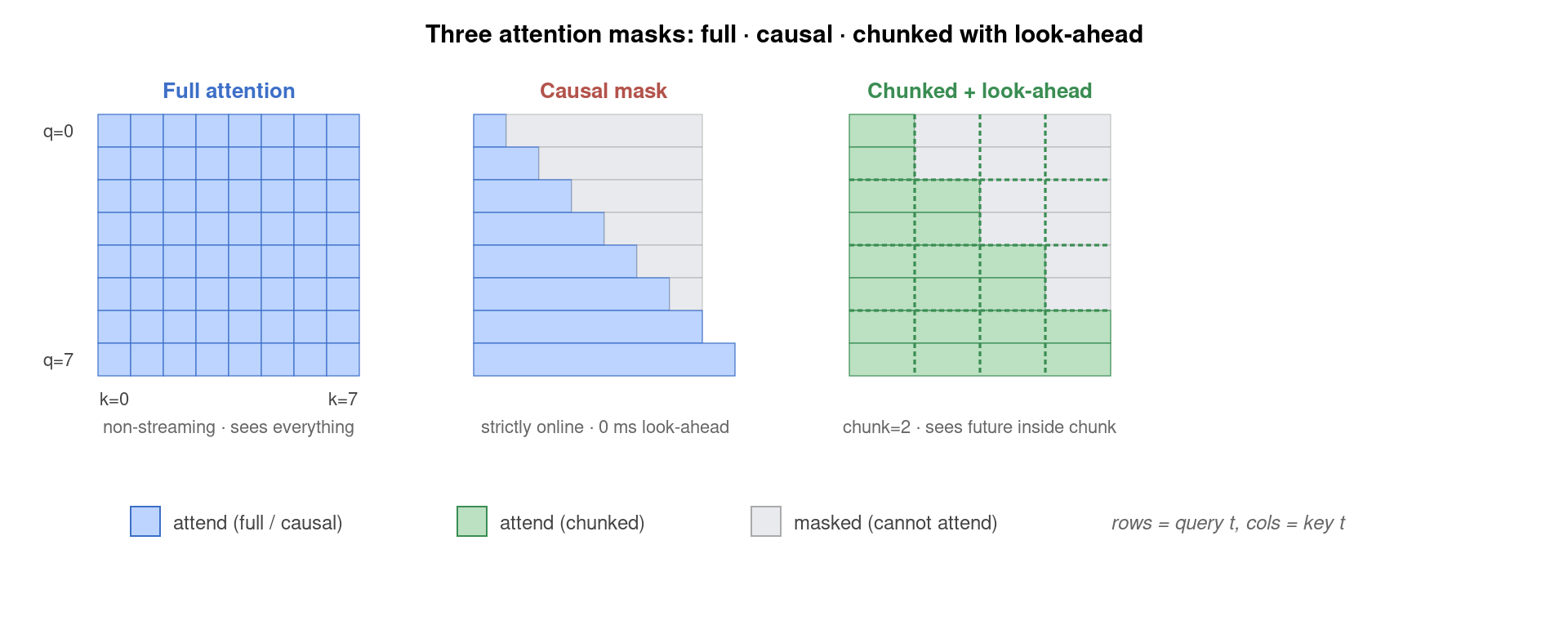
Chunked attention 是把 self-attention 的「全序列查看」限制成「当前 chunk 内自由 + 历史 chunk 完整 + 未来 chunk 屏蔽」。chunk 大小 C 是延迟与精度的核心权衡——C=4 帧 (40 ms) 几乎无延迟但精度差,C=160 帧 (1.6 s) 接近离线效果但延迟大。WeNet 的 U2 与 U2++ 框架定义了一个聪明的解法:
Dynamic Chunk Training——训练时每个 batch 从一个均匀分布里采一个 chunk size(比如 [1, max_chunk]),让同一个模型同时学到所有 chunk 尺寸的能力。推理时按业务延迟需求选不同的 C:实时字幕用 C=8(80 ms 延迟),离线转录用 C=∞。一份模型权重,多档延迟可调。这是 WeNet 在工业界大规模流行的关键工程武器。
import torch
def chunked_attention_mask(T: int, chunk_size: int, history: int = -1) -> torch.Tensor:
"""生成 chunked-attention 的布尔 mask。
True = 允许 attend;False = 屏蔽。
Args:
T : 序列总长(帧数)
chunk_size : 当前 chunk 大小
history : 可见的历史 chunk 数;-1 表示无限(看所有过去)
Returns: shape (T, T) 的布尔矩阵
"""
# 每个位置 i 所属的 chunk id
chunk_id = torch.arange(T) // chunk_size # (T,)
qid, kid = chunk_id.unsqueeze(1), chunk_id.unsqueeze(0) # (T,1), (1,T)
can_attend = kid <= qid # 未来 chunk 屏蔽
if history >= 0:
can_attend &= (qid - kid) <= history # 限制历史长度
return can_attend
# 用法示例:8 帧序列、chunk=2、看 1 个历史 chunk
mask = chunked_attention_mask(T=8, chunk_size=2, history=1)
# 在 attention 内部:scores.masked_fill_(~mask, float("-inf"))
4. Causal Convolution + LayerNorm:消除卷积侧延迟
Conformer 的 Convolution Module 默认使用 中心 padding 的 depthwise conv(kernel=31, padding=15),对每一帧都依赖两侧各 15 帧上下文。流式部署有两个改造方案:
- 纯因果卷积 (Causal Conv)。把 padding 从 `(15, 15)` 改成 `(30, 0)`——左侧 padding 全部加在前面,右侧不允许 padding。算 t 时刻输出只用到 [t-30, t] 帧。算法延迟 = 0,但精度会掉。
- Chunk-aware Conv (Dynamic Chunk Convolution)。让卷积也按 chunk 切——chunk 内允许双向,跨 chunk 屏蔽。这与 chunked attention 行为对齐,是 WeNet U2++ 的默认做法。论文实测显示比纯因果卷积 WER 低约 0.5。
import torch.nn as nn
class CausalConvModule(nn.Module):
"""流式版 Conformer Convolution Module。
把 BatchNorm 换成 LayerNorm,DepthwiseConv 改为左侧全 padding。
"""
def __init__(self, d_model: int, kernel_size: int = 15):
super().__init__()
self.ln = nn.LayerNorm(d_model)
self.pw1 = nn.Conv1d(d_model, 2 * d_model, kernel_size=1)
# 关键:左 padding = kernel - 1,右 padding = 0 → 因果
self.dw = nn.Conv1d(d_model, d_model, kernel_size,
padding=0, groups=d_model)
self.pad_left = kernel_size - 1
self.norm = nn.LayerNorm(d_model) # 替换 BatchNorm
self.act = nn.SiLU()
self.pw2 = nn.Conv1d(d_model, d_model, kernel_size=1)
def forward(self, x, cache: torch.Tensor = None):
"""x: (B, L, d). cache: 上一次输出末尾的 pad_left 帧, 用于跨 batch 续推。"""
x = self.ln(x).transpose(1, 2) # (B, d, L)
x = nn.functional.glu(self.pw1(x), dim=1) # (B, d, L)
if cache is None:
cache = torch.zeros(x.size(0), x.size(1), self.pad_left,
device=x.device, dtype=x.dtype)
x_padded = torch.cat([cache, x], dim=2) # 拼接历史 → (B, d, pad+L)
new_cache = x_padded[:, :, -self.pad_left:] # 保留末尾给下次
x = self.dw(x_padded) # (B, d, L)
x = x.transpose(1, 2) # back to (B, L, d)
x = self.act(self.norm(x))
x = self.pw2(x.transpose(1, 2)).transpose(1, 2)
return x, new_cache
BatchNorm 替换为 LayerNorm 是流式部署里另一个常被忽略的细节。BN 在训练时累计的均值/方差是整段序列的统计,推理时这些统计在流式 chunk 上不可用,模型输出分布会漂移。LayerNorm 沿特征维归一化,与序列长度无关,是流式天然友好的选择。NeMo 与 k2/icefall 都把 Conformer 的 Conv Module BN 默认换成了 LN(变体「LN-Conformer」)。
5. KV Cache:流式推理的内存帮手
chunked attention 在训练时是 O(L²) 计算量,但推理时每来一个新 chunk 都从头算所有过去 attention 就太浪费了——前面 chunk 的 key/value 不会变,可以缓存。KV Cache 的核心思想是:
class StreamingMHA(nn.Module):
"""简化版流式 multi-head attention,支持 KV cache。"""
def __init__(self, d_model, n_heads):
super().__init__()
self.h = n_heads
self.qkv = nn.Linear(d_model, 3 * d_model, bias=False)
self.out = nn.Linear(d_model, d_model)
def forward(self, x, k_cache=None, v_cache=None, max_history=128):
"""x: (B, chunk, d). k_cache/v_cache: 上次保留的历史 K/V。"""
B, T, C = x.shape; D = C // self.h
q, k, v = self.qkv(x).chunk(3, dim=-1) # 每个 (B, T, C)
# 拼接历史 K/V
if k_cache is not None:
k = torch.cat([k_cache, k], dim=1)
v = torch.cat([v_cache, v], dim=1)
# 限制历史长度,丢掉过老的
k = k[:, -max_history:]
v = v[:, -max_history:]
q = q.view(B, T, self.h, D).transpose(1, 2) # (B, h, T, D)
k_h = k.view(B, -1, self.h, D).transpose(1, 2)
v_h = v.view(B, -1, self.h, D).transpose(1, 2)
out = nn.functional.scaled_dot_product_attention(q, k_h, v_h)
out = self.out(out.transpose(1, 2).reshape(B, T, C))
return out, k, v # 返回新 cache
有了 KV cache,每个 chunk 的增量计算量从 O(L²) 降到 O(C·L_max)——C 是 chunk 大小(<10)、L_max 是历史上限。在 L_max=128 帧 (1.28 s) 设定下,单 chunk 推理延迟在 A10 GPU 上能压到 5 ms 量级。这一点对 voice agent 体验至关重要。
实战中还有一个被严重低估的优化:把 KV cache 维护在 CPU 端,每个 chunk 临时上传 GPU。在多路并发(如客服中心 1000 路同时通话)场景下,把所有路的 cache 都常驻 GPU 显存会迅速爆 OOM;放在 CPU 内存里则单路只占几 MB,瓶颈反而落在 PCIe 上行带宽。sherpa-onnx 在 GPU 推理服务里专门优化了这一路径,实测 1000 路并发下显存占用比朴素实现降 8 倍。
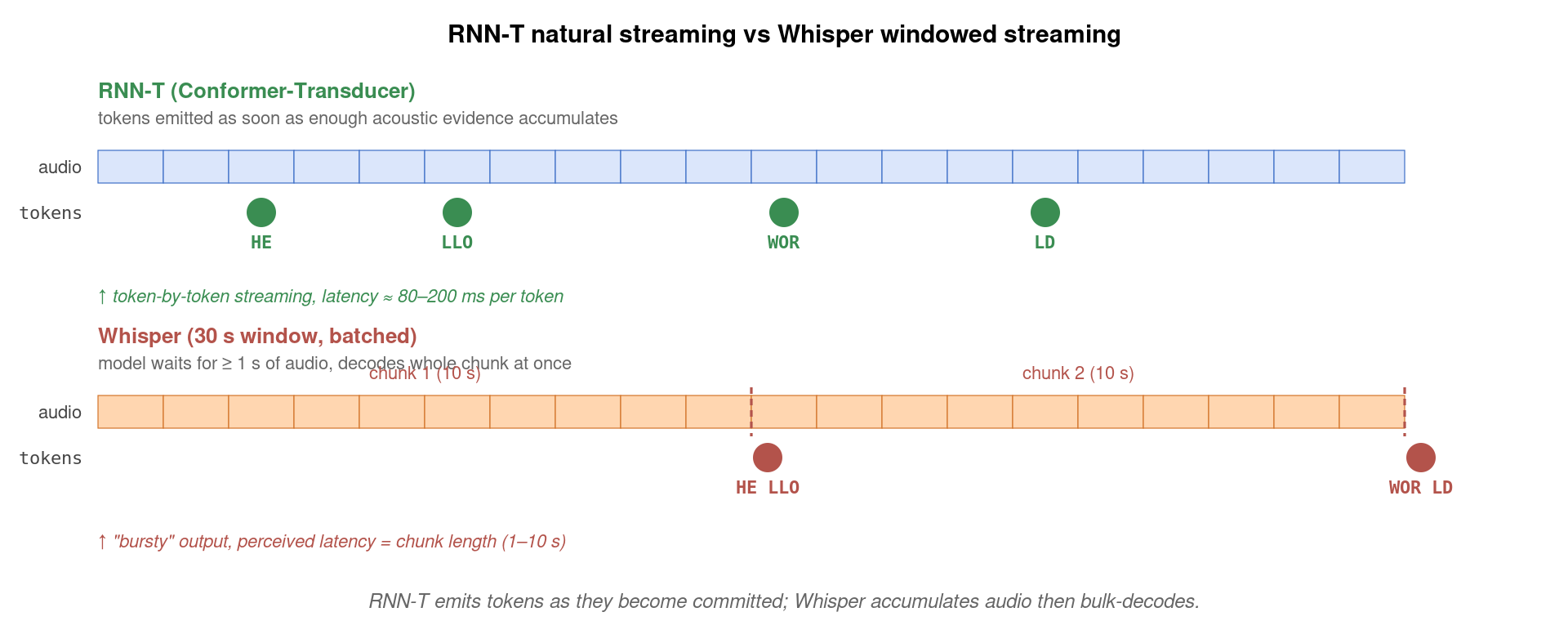
6. Whisper 的流式化:把非流式模型「包装」成流式
Whisper 训练时是 30 秒固定窗口 + 双向 attention,本质上是非流式架构。但工业界仍然有大量将 Whisper 部署成实时字幕的需求,主要靠下面三种工程包装:
| 方案 | 核心思路 | 延迟 | 典型实现 |
|---|---|---|---|
| 滑窗 + 部分提交 | 每 1–3 秒推理一次,覆盖式输出,保留前面已确认部分 | 1–3 s | whisper-streaming |
| VAD 切片 + 整段推理 | 用 Silero VAD 检测说话段,每个段独立解码 | ~段长 + 500 ms | WhisperX / faster-whisper-server |
| LocalAgreement | 多次滑窗推理后投票,重叠区域一致的部分提交 | 1–2 s | WhisperLiveKit |
这些都属于「外部 chunking + 内部完整推理」策略——模型本身不动,靠把音频切片实现「假流式」。代价是延迟下限约 1 s,达不到 voice agent 的 200 ms 体验。要做到真正的低延迟,必须在模型架构层面支持流式,这就是为什么 Google / Apple / Kyutai 在 voice agent 场景没有采用 Whisper,而是自研流式架构。
7. 流式 ASR 工业架构:VAD + Encoder + Decoder + Endpoint
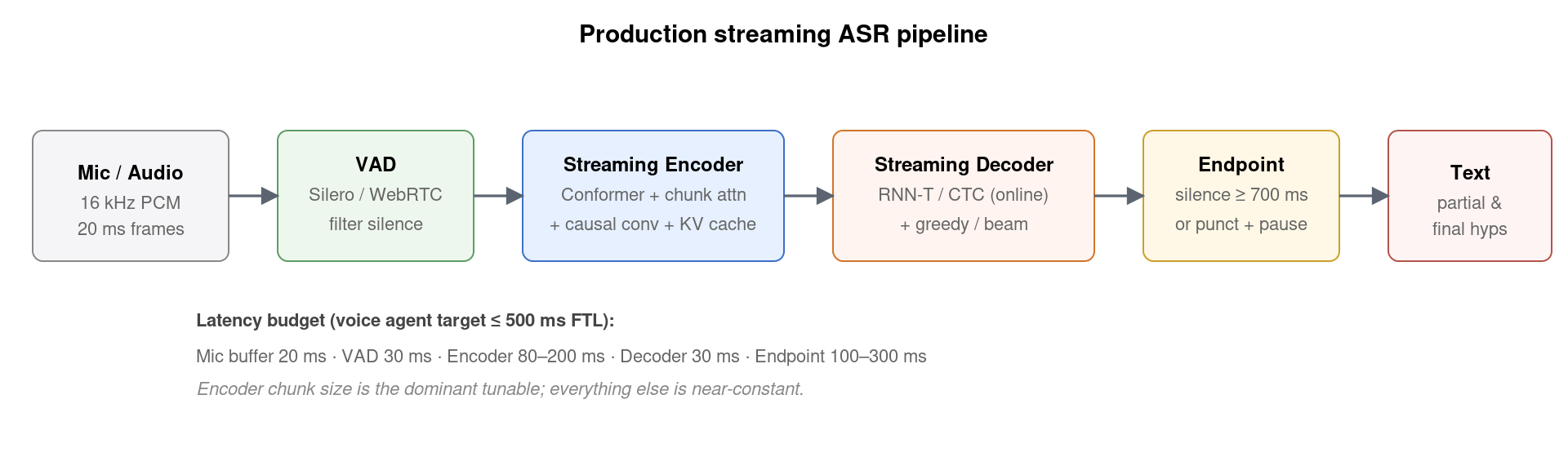
典型生产架构由 5 个模块串成(图 2)。每个模块对延迟的贡献:
- Mic buffer:硬件最小一次 20 ms(系统层 WebRTC 标准)。
- VAD (Voice Activity Detection):典型 30 ms 决策延迟。Silero VAD 几乎是 2024 后的事实标准——开源、CPU 友好、误检率 < 1%。WebRTC 自带 VAD 太老不推荐。
- Streaming Encoder:取决于 chunk size。chunk=80 ms 时编码延迟约 80–120 ms。
- Streaming Decoder:RNN-T greedy < 10 ms / chunk;CTC beam search 略高。
- Endpoint detection:根据连续 N 帧 blank/silence 判定句末,典型阈值 700 ms。这是个独立的策略层,可以基于 VAD、RNN-T blank 比例、或专门训练的小模型来做。
8. 性能指标与对比
| 方案 | 模型 | 算法延迟 | FTL (RTX 3090) | WER (Libri test-other) |
|---|---|---|---|---|
| Whisper offline | large-v3 (1.55B) | 30 s | ~30 s | 3.9 |
| WhisperLiveKit | large-v3 + chunked | ~2 s | ~2.5 s | 4.5 |
| WeNet U2++ (chunk 16) | Conformer-Transducer (100M) | 320 ms | ~120 ms | 5.5 |
| WeNet U2++ (chunk 4) | 同上 | 80 ms | ~50 ms | 6.3 |
| icefall Zipformer-Streaming | Zipformer-T (70M) | 320 ms | ~80 ms | 4.4 |
| Moshi (end-to-end) | 7B Temporal Transformer + Mimi codec | 160 ms | ~200 ms | — |
这张表清晰说明了流式 ASR 的三重权衡——延迟、精度、模型大小相互掣肘。Voice agent 业务通常选 chunk 320 ms 档:综合 WER ~4.5、FTL ~100 ms、模型 ~70M 可在 CPU/GPU 边缘端部署。Whisper 这类大模型只在「精度第一、延迟次要」的离线转录场景才划算。
chunk 大小的选择有一条经验规律:把它设为「最短词的发音时长」的 2 倍左右。中文常见单字发音 150–250 ms,两个字组合(如「打开」「停止」)约 400 ms,因此中文 voice agent 取 chunk=320–480 ms 几乎都能 work;英文最短词如 “no”、”yes”、”OK” 也是 200–300 ms,同样适用。chunk 过小(< 80 ms)模型来不及形成稳定上下文,WER 退化超过 1;chunk 过大(> 800 ms)会让首字延迟超过用户感知阈值,对话体验明显迟钝。
9. 2024–2025 业界:从级联到端到端
2024 年最重要的范式转变是端到端语音 LLM 的崛起。OpenAI 的 GPT-4o Realtime API、Google 的 Gemini Live、Kyutai 的开源 Moshi——它们把 ASR、LLM、TTS 三个传统级联模块融合到单个自回归模型,输入是音频 token,输出也是音频 token。这种架构的延迟下限不再受级联累加约束,理论上只受 codec 帧大小限制。
以 Moshi 为例,其全双工延迟拆解:
- Mimi codec 帧大小:80 ms(12.5 Hz token rate)。
- 声学到 token 延迟:80 ms(模型 forward)。
- 理论总延迟:160 ms;实际 L4 GPU 上约 200 ms。
这种架构里,「流式 ASR」不再是独立模块——它被吸纳进语音 LLM 的输入端,与文本 token 共享同一个 Transformer。Moshi 的 “Inner Monologue” 设计让模型先预测时间对齐的文本 token、再预测 Mimi 音频 token,相当于把 ASR 隐式做在前几个 token 上。这是端到端语音建模的最新范式,但对单纯流式 ASR 场景仍然 overkill——大多数业务还是会选「VAD + Conformer-T + 端点」这套经典架构,因为它在 CPU 上就能跑、可控性高、调优工具链成熟。
另一个值得关注的趋势是「半流式」体验设计。OpenAI Realtime API 实际上不是严格 200 ms 端到端流式——它内部用了 server-side VAD 切片 + 流式 ASR + LLM 生成首 token 的延迟优化组合,对外暴露的「response.audio.delta」事件平均触发延迟约 320 ms(OpenAI 自己公布的数据)。Gemini Live 类似。这告诉我们:真正的端到端流式语音模型仍属研究前沿,主流产品依然是「经过精细工程优化的级联架构」。理解流式 ASR 各个组件的延迟贡献,比追求端到端语音 LLM 更有工业实用价值。
10. 工程化的几个深水坑
- 训练-推理不一致。dynamic chunk 训练时随机采样 chunk size,但推理时往往固定一档。如果训练时 chunk size 分布没覆盖到推理用的那档,会有 0.3–0.8 WER 退化。把推理目标 chunk 加进训练采样分布是必要的工程动作。
- SpecAugment 与 chunk mask 冲突。SpecAugment 的时间 mask 段如果跨越多个 chunk 边界,会让模型学到「跨 chunk 引用」的错误模式。WeNet 的做法是把 SpecAugment 改成 chunk-aware 版本——mask 严格在单个 chunk 内。
- KV cache 内存爆炸。设 max_history 太大(> 256 帧)单流就要几十 MB,1000 路并发就爆。生产部署常把历史上限设为 96–128 帧(即 1 s 上下文),实测精度下降 < 0.2 WER 但 GPU 显存利用率从 95% 降到 30%。
- Endpoint 与 LLM 触发的耦合。在 voice agent 里,端点过早触发 = LLM 在用户没说完就开始想;过晚 = 反应迟钝。LiveKit Agents 和 Pipecat 这类框架引入了「turn detection model」——专门训练一个小 BERT 判断语义上是否说完,比纯静音阈值聪明得多。这是 2024 年后 voice agent 工程的新标准做法。
- partial vs final。流式系统要同时输出「partial hypothesis」(每来一帧就刷新当前最佳推断)和「final hypothesis」(端点检测后的最终结果)。前端 UI 通常订阅 partial 做实时滚动字幕、订阅 final 触发下游动作。两路输出的格式约定、字符闪烁优化都需要专门设计——直接把每次 partial 全文重画会导致 UI 抖动严重。
11. 总结
流式 ASR 的本质是把一个为「全局信息」设计的网络,逼着它在只看局部时也能做出合理预测。Chunked attention 让 self-attention 看的更少;causal conv 让卷积只用过去;KV cache 让推理省一半算力;LayerNorm 替代 BatchNorm 让流式统计稳定——这些技术互相耦合,缺一不可。WeNet U2++ 的 dynamic chunk training 把这些组合优雅地统一到「一份权重多档延迟」的范式里,是当下工业 ASR 部署最成熟的方案。
对工程师而言,当下的现实路线选择大致这样:
- 实时字幕 / 同传场景:WhisperLiveKit (large-v3) 精度高、调优少;延迟 1–2 s 可接受。
- 语音助手 / 客服机器人:WeNet / icefall + Conformer-Transducer-Streaming,CPU 也能跑,FTL ~100 ms。
- 对话式 AI Agent:要么 ASR + LLM + TTS 经典三件套(用 Silero VAD + Streaming Conformer),要么端到端语音 LLM(Moshi / GPT-4o Realtime)。
- 移动端 / 边缘:whisper.cpp 或 sherpa-onnx 把上述模型量化部署。
把这篇放在我之前 Whisper / RNN-T / Conformer / SSL 三部曲 一起读,你应该已经能从「算法 → backbone → 训练范式 → 工程部署」四个维度,完整理解当下端到端 ASR 的整张地图。
参考资料
- Yao, Z. et al. WeNet: Production Oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit. arXiv:2102.01547, Interspeech 2021.
- Zhang, B. et al. WeNet 2.0: More Productive End-to-End Speech Recognition Toolkit. arXiv:2203.15455, Interspeech 2022.
- Wu, D. et al. U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition. arXiv:2106.05642, 2021.
- Défossez, A. et al. Moshi: a speech-text foundation model for real-time dialogue. arXiv:2410.00037, 2024.
- Sainath, T. et al. A Streaming On-device End-to-end Model Surpassing Server-side Conventional Model Quality and Latency. ICASSP 2020.
- Macháček, D. et al. Turning Whisper into Real-Time Transcription System. arXiv:2307.14743, 2023.(whisper-streaming)
- k2-fsa / icefall:github.com/k2-fsa/icefall (Zipformer-Streaming 参考实现)
- Silero VAD:github.com/snakers4/silero-vad
- WhisperLiveKit:github.com/QuentinFuxa/WhisperLiveKit
- LiveKit Agents:github.com/livekit/agents (turn detection model)
![]()
2025-10-14 at 5:51 下午
感谢分享