转载本文请注明出处:https://yudonglee.me/f5tts-explained/ | 作者:yudonglee
📝 本文首发于 2025 年 11 月。最近一次修订于 2026 年 6 月:更新了三路线对比与实操建议。
2024 年 6 月,微软在 arXiv 公开 E2-TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS。论文的题目直白到让人发笑——「令人尴尬的简单」。它真的简单:一个 vanilla Transformer + 一个「音频填空」训练任务,没有 phoneme alignment、没有 duration predictor、没有 grapheme-to-phoneme 字典、没有 codec quantizer。直接吃字符级文本,输出 mel 频谱,端到端、一次推理完成。4 个月后,上海交大 SWivid 团队在此基础上推出 F5-TTS——给 E2 加了 ConvNeXt 文本编码器与 Sway Sampling 推理技巧,训练快 4 倍、推理快 50%、效果反超 VALL-E。F5-TTS 开源后 3 个月 GitHub 拿到 9k star,是 2024–2025 年最热门的英文开源 TTS。
本文是「语音技术深度系列」TTS 主线第 4 篇,紧接 CosyVoice 2 详解。前两篇我讲了「LM AR + Flow Matching 混合」(CosyVoice 2)和「纯 codec LM」(VALL-E)两条路;本文聚焦第三条路:纯 Flow Matching。读完你将能回答:
- Flow Matching 在数学上跟 Diffusion 是什么关系?为什么 F5-TTS 能用 16 步就达到 Diffusion 1000 步的效果?
- E2-TTS「不需要 phoneme/duration」是怎么做到的?模型怎么知道哪个字应该读多久?
- F5-TTS 在 E2 基础上加的 ConvNeXt + Sway Sampling 各自解决了什么问题?
- 三种 TTS 路线(VALL-E / CosyVoice 2 / F5-TTS)我该选哪个?
1. 背景:为什么需要”第三条路”
到 2024 年中,TTS 主流路线已经基本定型:
- VALL-E 路线(纯 codec LM):Encodec + AR/NAR Transformer。优点:zero-shot 克隆能力强;缺点:codec 信息损失大,需要 phoneme 对齐,推理慢。
- CosyVoice 路线(LM AR + Flow Matching 混合):监督式语义 token + Qwen LM + Flow Matching decoder。优点:内容/音色解耦清晰,支持流式;缺点:架构复杂,三阶段管道工程量大。
这两条路有一个共同的”隐性税”:都需要某种形式的”中间符号”——VALL-E 用 phoneme + codec token,CosyVoice 用 phoneme + 监督式语义 token。这些中间符号意味着额外的工程负担:要维护 G2P (Grapheme-to-Phoneme) 字典处理新词、要训练 codec 模型、要保证 token 与文本对齐质量。对开源社区的小团队来说,这些都是不小的门槛。
E2-TTS 的设计哲学是“全部消去”——既然 Transformer 足够强、训练数据足够多,那能否让模型自己学到所有这些映射?文本直接喂字符、不告诉模型每个字符多长、不告诉它该用什么 phoneme,让 Transformer 在大数据驱动下自己悟。这听起来很激进,但 NLP 已经验证过同样思路(BPE 词表 + LLM 端到端预测,根本不需要词性标注/句法树/外部 KG),那为什么 TTS 不可以?
2024 年 E2-TTS 把这个激进想法落地,结果真的 work——MOS 4.4,与 NaturalSpeech 3、VALL-E 等显式架构持平。F5-TTS 把它做到 SOTA,证明“暴力简洁”反而是 TTS 终极解。这是一次教科书级的”Bitter Lesson” 印证(Rich Sutton, 2019)——人工设计的归纳偏置在足够大的算力和数据面前迟早会被取代。
2. Conditional Flow Matching:Diffusion 的”简化版”

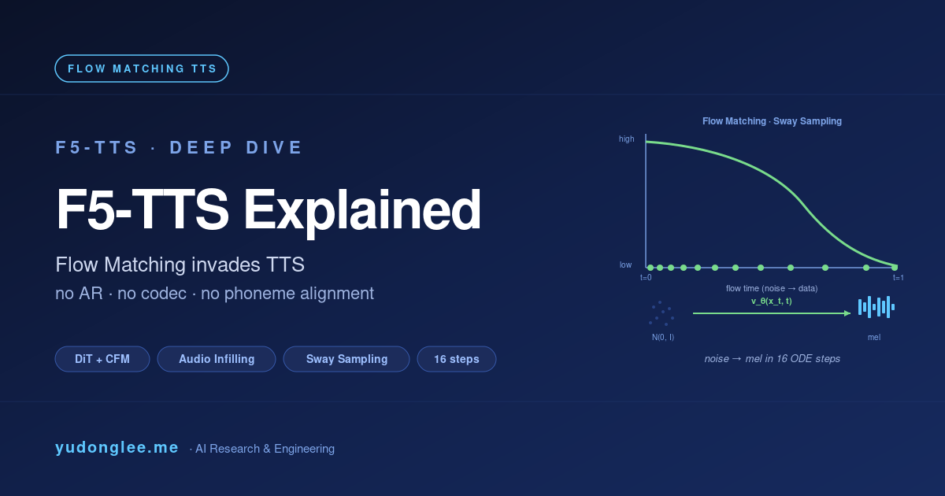
Flow Matching (FM) 是 2023 年 Yaron Lipman 等人在 ICLR 提出的生成式建模新框架。它的数学非常优雅:不学”如何 denoise”,而是直接学”从噪声到数据的速度场”。
具体来说,FM 把数据分布 pdata 与先验噪声分布 p0(x) = N(0, I) 之间用一条简单的直线路径连接:
x_t = (1 - t) · x_0 + t · x_1, t ∈ [0, 1]
其中 x_0 ~ N(0, I)(噪声), x_1 ~ p_data(真实样本)
对应的速度场(这条直线的瞬时方向)是:
v(x_t, t) = x_1 - x_0 (直接是终点减起点,常数!)
训练时,模型学一个神经网络 vθ(x_t, t) 来拟合这个速度场,loss 就是 MSE:
L_FM = E_{t, x_0, x_1} ‖v_θ(x_t, t) - (x_1 - x_0)‖²
推理时,从随机噪声 x0 ~ N(0, I) 出发,用 ODE 求解器(最简单是 Euler 方法)沿速度场积分到 x1:
x_{t+Δt} = x_t + Δt · v_θ(x_t, t)
这套数学相比 Diffusion 的优势是路径完全确定、不引入随机性——Diffusion 的 reverse SDE 需要小步长来稳定数值积分,FM 的直线路径允许大步长。实测 FM 在图像、视频、音频生成上都能用 16–32 步达到 Diffusion 1000 步的质量,这是 Stable Diffusion 3、Sora、F5-TTS 共同选择 Flow Matching 的根本原因。
FM 的「Conditional」版本是给速度场加条件输入——TTS 里条件就是文本与参考音频。CFM 的训练目标变成:
L_CFM = E ‖v_θ(x_t, t, text, ref) - (x_1 - x_0)‖²
整套范式直接落到 TTS 上,就是 E2-TTS 与 F5-TTS。
3. E2-TTS:把 TTS 当”音频填空”做
E2-TTS 的训练任务被设计成音频填空 (audio infilling)。具体做法是:
- 训练数据:每个样本是一段 (text, audio) 对,audio 已经预转成 mel 频谱 m;
- 把 text 用字符级 padding 撑到 mel 同长度——比如文本”hello”有 5 个字符,对应的 mel 有 100 帧,就把每个字符复制成填充符号 padding 到 100 长度,例如
h h h h ... e e e ... ... <pad> <pad>。这是 E2-TTS 最关键的”哲学跳跃”:不再用 phoneme/duration,让模型自己学到字符到 mel 帧的对齐; - 随机 mask mel 的某段连续区间(典型 70%),把”被 mask 区间的 mel”作为模型的预测目标;
- 训练目标:vθ 输入是 (noisy mel, mask, padded text, t),输出是速度场。loss 仅在 masked 区间计算。
这种设计的妙处在于:训练样本是高度灵活的——同一段音频可以 mask 任意位置、任意长度,相当于对每个真实音频生成无数虚拟训练样本。这是大数据时代典型的 self-supervised 训练范式。推理时只需把”参考音频部分”当成”未被 mask”,把”目标合成段”当成”完全 masked”,模型自动 inpaint 出对应内容。
架构上 E2-TTS 是非常 vanilla 的 Transformer + U-Net 风格跳跃连接——24 层、1024 hidden、16 heads。U-Net 跳跃连接让低层局部特征能直接传到高层、缓解长序列预测的细节损失。没有 cross-attention、没有 RNN、没有 codec、没有 alignment,简单到极致。
但 E2-TTS 也有明显问题:训练收敛极慢,作者论文里报告需要 800k 步才能勉强可用,并且对长文本/复杂韵律的处理稳定性差——经常出现合成音频中间漏字、字符对应错位的问题。原因在于「让 Transformer 自己学字符与 mel 帧对齐」这件事其实非常难,字符 padding 后的序列局部结构(同字符连续多帧)需要大量数据才能从随机初始化中学到。这正是 F5-TTS 改进的切入点:用 ConvNeXt 提前消化文本结构,让 DiT 专注于声学生成。
4. F5-TTS:E2 的精致改良
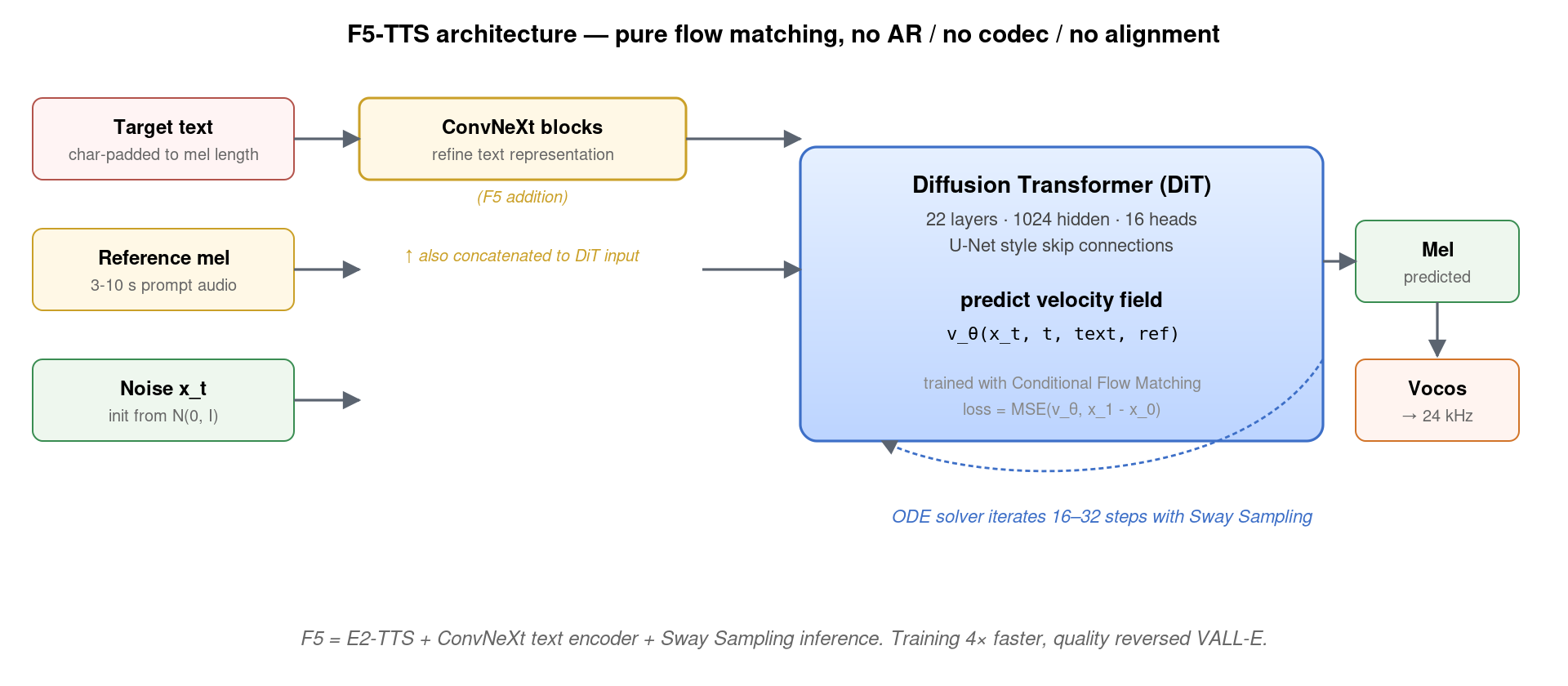
F5-TTS 在 E2-TTS 基础上做了两个看似小、实际效果显著的改动:
4.1 ConvNeXt 文本编码器
E2-TTS 把字符级 padding 文本直接喂给 DiT,让 DiT 自己学文本表示。F5-TTS 在 DiT 之前先用一个独立的 ConvNeXt 栈处理 padded 文本——4 层 ConvNeXt blocks(受 ConvNeXt CVPR 2022 启发的 1D 卷积块,每块含 depthwise conv + layernorm + GELU + pointwise conv),把字符序列预处理成更结构化的表示,再送进 DiT。
为什么这个改动有效?原因在于字符 padding 后的序列局部结构很强——同一字符的连续重复块往往跨数十帧,相邻字符的边界有明显跳变。ConvNeXt 的局部感受野非常适合捕捉这种”块状”模式,比直接用 DiT 自己学(每个 token 都需要走全局 attention)效率高得多。F5 论文实测:加入 ConvNeXt 后训练收敛速度提升 ~4 倍,WER 降低 ~30%。
4.2 Sway Sampling
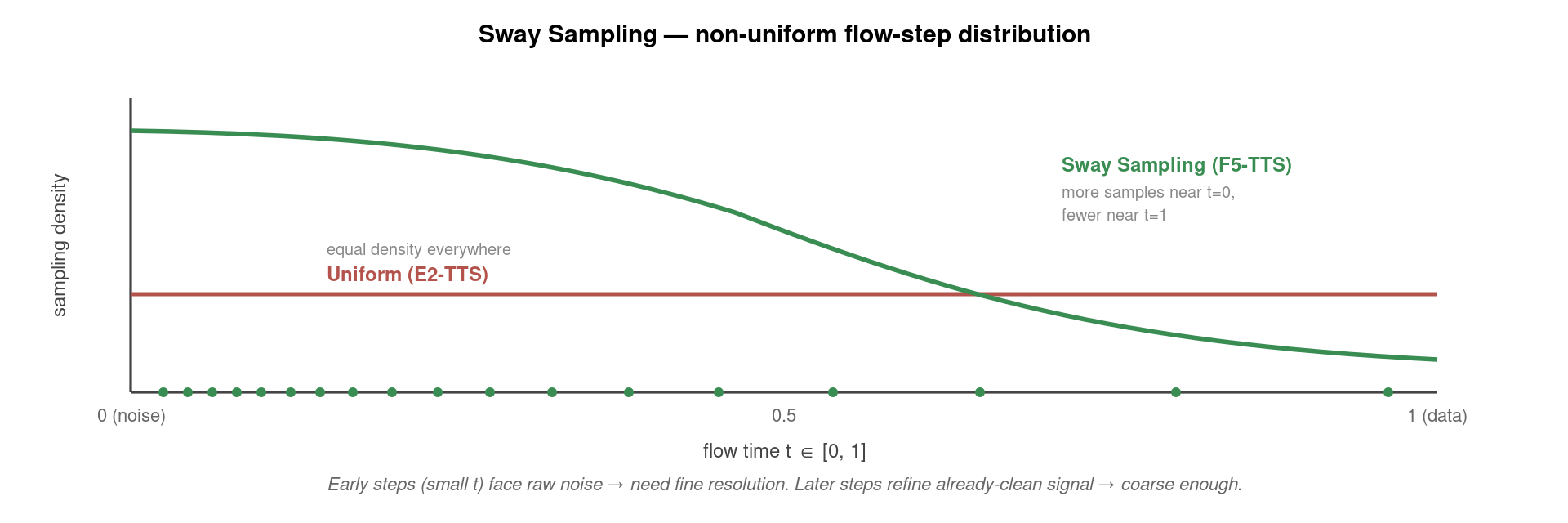
Sway Sampling 是 F5-TTS 在推理阶段(不是训练)的创新。它注意到一个事实:Flow Matching 的 ODE 求解步并不需要均匀分布在 [0, 1] 之间。早期步骤(t 接近 0)处理的是高度噪声化的样本,路径方向变化大,需要小步长精细控制;晚期步骤(t 接近 1)处理的是已经较干净的样本,路径方向稳定,可以大步长跳过。
具体实现是一个简单的 reparameterization:把均匀分布的 t_i 通过一个 sigmoid-like 函数 swap 成偏向 0 的非均匀分布:
def sway_sampling_t(num_steps: int, coef: float = -1.0):
"""生成 Sway Sampling 时间步序列。
coef < 0 → 偏向 t=0 (噪声端) 更多采样
coef = 0 → 均匀采样
coef > 0 → 偏向 t=1 更多采样(实测效果差)
"""
import torch
t = torch.linspace(0, 1, num_steps + 1)
# F5-TTS 默认 coef=-1.0,相当于 t' = t + coef * (cos(pi*t/2) - 1 + t)
t_sway = t + coef * (torch.cos(torch.pi * t / 2) - 1 + t)
return t_sway
F5 论文实测:在 16 步推理下,Sway Sampling 比均匀采样 SECS(说话人相似度)提升 0.05、WER 降低 ~15%。更妙的是这个 trick 与训练完全无关——任何 flow-matching-based 模型(包括 NaturalSpeech 3、E2-TTS 自身)都可以直接套用,无需重训。这种”训练时常规、推理时聪明“的优化范式在 2024-2025 年生成式模型领域非常流行(cf. Stable Diffusion 的 DPMSolver++、Sora 的 rectified flow)。
5. 推理流程:5 行代码完成 zero-shot 克隆
F5-TTS 在 HuggingFace 开源完整权重与 pipeline。基本用法极简:
# pip install f5-tts
from f5_tts.api import F5TTS
import soundfile as sf
# 1) 加载模型(首次会从 HuggingFace 下载约 1.4 GB 权重)
tts = F5TTS(model_type="F5-TTS") # 也可以用 "E2-TTS"
# 2) 准备参考音频 + 对应文本
ref_audio = "alice_5sec.wav" # 任意人 3-10 秒清晰语音
ref_text = "It's a beautiful day to start something new today."
gen_text = "Hello, this is a zero-shot voice clone using F5-TTS. " \
"Notice the natural rhythm and intonation."
# 3) 一次推理 = 一段合成音频
wav, sr, _ = tts.infer(
ref_file=ref_audio,
ref_text=ref_text,
gen_text=gen_text,
nfe_step=16, # ODE 步数,16 是 F5 默认 (E2-TTS 默认 32)
cfg_strength=2.0, # classifier-free guidance, 控制音色强度 (1=弱 / 3=强)
sway_sampling_coef=-1.0, # Sway sampling 系数,-1 是默认
speed=1.0, # 语速控制
)
# 4) 保存
sf.write("alice_clone.wav", wav, sr)
print(f"generated {len(wav)/sr:.2f}s audio from {ref_audio}")
整个流程 16 步 ODE 求解,RTX 4090 上推理 10 秒音频约 1-2 秒。无需 phoneme 字典、无需对齐工具、无需 fine-tune——拿来就用。这种简洁性是 F5-TTS 能在开源社区疯传的关键。
F5-TTS API 还有一个隐藏技巧:“speed” 参数可以直接控制语速,且不依赖韵律重训。原理是在 ODE 求解前先把 reference mel 与 noise mel 的长度按 speed 缩放——比如 speed=1.5 就让生成 mel 比”naturally implied” 短 50%。这种”直接操作 latent 时间维”的能力是 Flow Matching 路线独有的另一个免费红利,VALL-E/CosyVoice 都做不到(前者 AR 解码长度由 EOS 决定、后者由语义 token 决定,都不能直接外部干预)。
6. 性能对比表
| 模型 | 训练数据 | 参数量 | WER (LibriSpeech-PC test-clean) ↓ | Speaker Sim ↑ | 推理步数 | RTX 4090 RTF |
|---|---|---|---|---|---|---|
| YourTTS (2022) | ~600 h | 87 M | 7.7 | 0.34 | — | 0.05 |
| VALL-E (2023) | 60k h | ~300 M | 5.9 | 0.58 | AR 8T + NAR 7 | ~0.5 |
| NaturalSpeech 3 (2024) | 60k h | 500 M | 5.6 | 0.63 | 30 (diffusion) | ~0.4 |
| VALL-E 2 (2024) | 60k h | ~300 M | 1.5* | 0.66 | AR + NAR | ~0.4 |
| E2-TTS (2024-06) | 100k h | ~330 M | 2.95 | 0.69 | 32 (FM) | ~0.15 |
| F5-TTS (2024-10) | 100k h | ~330 M | 2.42 | 0.66 | 16 (FM + Sway) | ~0.08 |
| CosyVoice 2 (2024-12) | 170k h | ~600 M | 2.4 | 0.65 | AR + 15 (FM) | ~0.07 (流式) |
| ElevenLabs Multilingual v2 | 未公开 | 未公开 | ~2.0 | ~0.70 | — | ~0.15 |
这张表很清楚说明 F5-TTS 在 2024 年的位置:WER 与 VALL-E 2 接近(少一个数量级训练),Speaker Sim 与 NaturalSpeech 3 持平,但推理速度远快于所有 AR 路线。它的核心优势是「SOTA 质量 + 简洁架构 + 极快推理」三件全包。劣势是非流式——一次推理才能出全部音频。这是它与 CosyVoice 2 最大的工程差距。
7. 三种 TTS 路线的终极对比
| 维度 | VALL-E 路线 | CosyVoice 2 路线 | F5-TTS 路线 |
|---|---|---|---|
| 核心范式 | Codec LM (AR+NAR) | LM AR + Flow Matching 混合 | 纯 Flow Matching + DiT |
| 需要 phoneme 字典 | 是 | 是(可选) | 否 |
| 需要 duration predictor | 否(隐含在 AR 中) | 否 | 否(字符 padding) |
| 需要 codec 模型 | 是 (Encodec) | 是(自研监督 token) | 否(直生 mel) |
| 架构复杂度 | 中(两 Transformer) | 高(三阶段) | 低(单 DiT) |
| 训练复杂度 | 中 | 高 | 低(单阶段端到端) |
| 推理速度 | 慢 (AR + NAR) | 快 (流式) | 极快 (16 步) |
| 流式支持 | 否 | 原生 150ms | 否(非流式架构) |
| 中文表现 | 差 | SOTA | 中(需 fine-tune) |
| 英文表现 | 好 | 好 | SOTA |
| 开发上手难度 | 高 | 中 | 极低 |
当下的实操建议:
- 英文 zero-shot demo / 配音 / 短文本朗读 → F5-TTS,简洁、速度、质量三平衡。
- 中文 voice agent / 客服 / 流式对话 → CosyVoice 2,原生流式 + 中文 SOTA。
- 多语种统一服务 → CosyVoice 2,覆盖中英日韩。
- 学术研究 codec LM 范式 → 看 VALL-E 论文,但生产部署千万别用。
- 企业 SaaS / 极致稳定性 → ElevenLabs API(黑盒但稳)。
8. 工程化的几个深水坑
- F5-TTS 不支持流式。架构限制——CFM 必须从噪声出发一次性 ODE 求解全部 mel 帧,无法增量输出。如果业务需要流式,要么改用 CosyVoice 2,要么自己改造架构(已经有研究尝试 Streaming F5-TTS,但还在实验阶段)。
- nfe_step 与质量的权衡。默认 16 步质量与 32 步差距很小,但降到 8 步会明显塌缩(mel 出现 artifact)。生产环境建议保持 16 步、用 Sway Sampling 默认 coef=-1。
- CFG strength 调优。默认 2.0 适合大多数场景。提到 3.0 音色相似度更强但说话节奏可能僵硬;降到 1.0 节奏自然但音色相似度下降。这是个针对每个参考音色都要单独调的超参。
- 中文 fine-tune 的坑。F5-TTS 官方权重主要训于英文。中文用户常报告 vocab 不覆盖中文字符的问题。社区已有 F5-TTS-Chinese 等 fine-tune 版本,但效果还不如 CosyVoice 2 原生中文。
- vocos vocoder 部署。F5-TTS 默认用 Vocos(基于 ConvNeXt 的 mel→waveform vocoder),比 HiFi-GAN 更快、量化友好。生产部署直接用 ONNX 导出即可。
- 显存占用。F5-TTS 完整 pipeline 加载约 1.5 GB GPU 显存,比 VALL-E (3 GB) 和 CosyVoice 2 (3 GB) 都低。在 T4 / A10 这种入门 GPU 上能跑多路并发,性价比很高。
9. 总结:Bitter Lesson 在 TTS 的胜利
F5-TTS 的成功是 Rich Sutton 2019 年「The Bitter Lesson」的又一次教科书印证——当算力和数据足够多时,通用方法终将打败精心设计的归纳偏置。VALL-E 引入 codec 解决离散化问题、CosyVoice 引入监督 token 解决对齐问题、NaturalSpeech 3 引入 FACodec 解耦四种属性——这些都是”聪明的归纳偏置”。F5-TTS 反其道而行之:所有归纳偏置都不要,让模型在 10 万小时数据驱动下自己悟出文本→mel 的映射。结果不仅 work,还更快、更简洁、效果更好。
这条路线的下一站很可能是把 F5-TTS 扩到 1B+ 参数 + 1M+ 小时数据——届时它在 zero-shot 上的能力可能彻底超越所有竞品。2025 年 CosyVoice 3 已经在做类似的 scaling,F5-TTS 团队和 Microsoft NaturalSpeech 团队也在同步推进。「纯 Flow Matching + DiT」很可能成为 未来两三年 TTS 的统治范式,就像 Transformer 在 2017 年统治 NLP 一样。
把这篇放到我之前的 TTS 演进史、VALL-E、CosyVoice 2 系列里看,你应该已经能完整理解 2023 年以来现代 TTS 的整张地图——VALL-E 开创 codec LM、CosyVoice 走混合架构、F5-TTS 走纯 Flow Matching,三条路并存且各有最佳应用场景。没有”哪一条注定胜出”,只有”哪一条更适合你的业务”。下一篇 TTS 系列文章我打算写 《Neural Audio Codec 详解:Encodec / SoundStream / DAC / Mimi》——把现代 TTS 与 ASR 共同的”分词器底座”彻底拆透,把这一段语音技术深度系列收个尾。
参考资料
- Chen, Y. et al. F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. arXiv:2410.06885, 2024.
- Eskimez, S. et al. E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS. arXiv:2406.18009, 2024.
- Lipman, Y. et al. Flow Matching for Generative Modeling. arXiv:2210.02747, ICLR 2023.
- Peebles, W. & Xie, S. Scalable Diffusion Models with Transformers (DiT). ICCV 2023.
- Liu, Z. et al. A ConvNet for the 2020s (ConvNeXt). CVPR 2022.
- Ho, J. & Salimans, T. Classifier-Free Diffusion Guidance. NeurIPS 2021 workshop.
- Siuzdak, H. Vocos: Closing the gap between time-domain and Fourier-based neural vocoders. ICLR 2024.
- Ju, Z. et al. NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models. arXiv:2403.03100, 2024.
- F5-TTS 官方仓库:github.com/SWivid/F5-TTS
- F5-TTS demo 页:swivid.github.io/F5-TTS
![]()
2025-12-10 at 5:23 下午
已有研究尝试 Streaming F5-TTS 但还在实验阶段”——能给两个具体的 repo/paper 链接吗?纯 FM 做流式(chunked ODE / 滑窗 inpainting)是个很有意思的方向