
转载本文请注明出处:https://yudonglee.me/speechllm-explained/ | 作者:yudonglee
📝 本文首发于 2025 年 12 月。最近一次修订于 2026 年 6 月:更新了开源模型对比与评测方法讨论。
2024 年 5 月 OpenAI 发布 GPT-4o,第一次向公众展示了「用语音直接和 LLM 对话、平均响应延迟 320 ms、能听懂叹气和笑声」的真实交互体验。3 个月后法国独立实验室 Kyutai 开源 Moshi,证明这种全双工 voice agent 完全可以用 7B 模型 + 一张 L4 GPU 跑起来——理论延迟 160 ms。同年 9 月清华开源 Mini-Omni,把端到端语音 LLM 的最小可行实现压到 0.5B 参数。这一切共同标志着语音 AI 从「ASR + LLM + TTS 三件套级联」彻底转向「单个 Transformer 处理一切」的新时代。我把这种新范式统称为 Speech LLM。
本文是「语音技术深度系列」的第 14 篇(也是阶段性收官篇)。前 13 篇都聚焦在具体模型(CTC、Whisper、RNN-T、Conformer、SSL、Streaming ASR、TTS 史、VALL-E、CosyVoice 2、F5-TTS、Neural Codec 等),本文把视角拉到最高,做一次顶层综述——把整个语音 AI 朝 LLM 范式合流的趋势做一次梳理。读完你将能回答:
- 什么才算是「Speech LLM」?它和「带 LLM 的 ASR 系统」有什么本质区别?
- 当前 Speech LLM 的三种主流范式(speech-in / speech-out / end-to-end speech-to-speech)各有哪些代表模型?
- 开源 (Qwen2-Audio / Moshi / Mini-Omni / GLM-4-Voice) 与闭源 (GPT-4o / Gemini Live) 之间差距有多大?2026 年开源能否追平?
- 从 2022 年的 Whisper 到 2024 年的 Moshi,整个领域的演进轨迹意味着什么?
1. 什么是 Speech LLM——一个清晰的定义
「Speech LLM」这个词在 2024 年开始流行,但定义混乱。我提出一个简单的三要素判定:
- Token 表示统一:语音信号必须以 token 序列形式与文本共享模型空间(不能是中间层 hidden state)。
- LLM backbone:核心架构是基于 GPT/LLaMA 等通用 LLM,而非传统 encoder-decoder ASR/TTS 模型(哪怕它叫 Transformer)。
- 具备语义理解或生成能力:模型能直接对语音内容做语义推理(如回答问题、对话),不只是逐字转录或合成。
按这个标准筛选——Whisper 不是 Speech LLM(它是 encoder-decoder ASR,只做转录,没有对话能力);VALL-E 是 Speech LLM(codec token + GPT 风格 AR Transformer);CosyVoice 2 是 Speech LLM(Qwen2.5 backbone + 监督语义 token);Moshi 是最纯粹的 Speech LLM(单 Transformer 同时处理音频输入输出)。这个定义把「语音技术 + 深度学习」与「真正的 Speech LLM」清晰区分开。
从能力上看,Speech LLM 比传统语音模型多三件事:(a)跨模态语义理解——能听懂”刚才那个人在嘲笑我吗”这种需要情感+上下文推理的问题;(b)开放对话能力——能基于音频内容用自然语言回答任意问题;(c)风格 / 情感可控生成——能根据指令以”开心 / 严肃 / 模仿某人”的方式说话。这三件事是传统 ASR-LLM-TTS 级联做不到的。
2. 三大范式分类
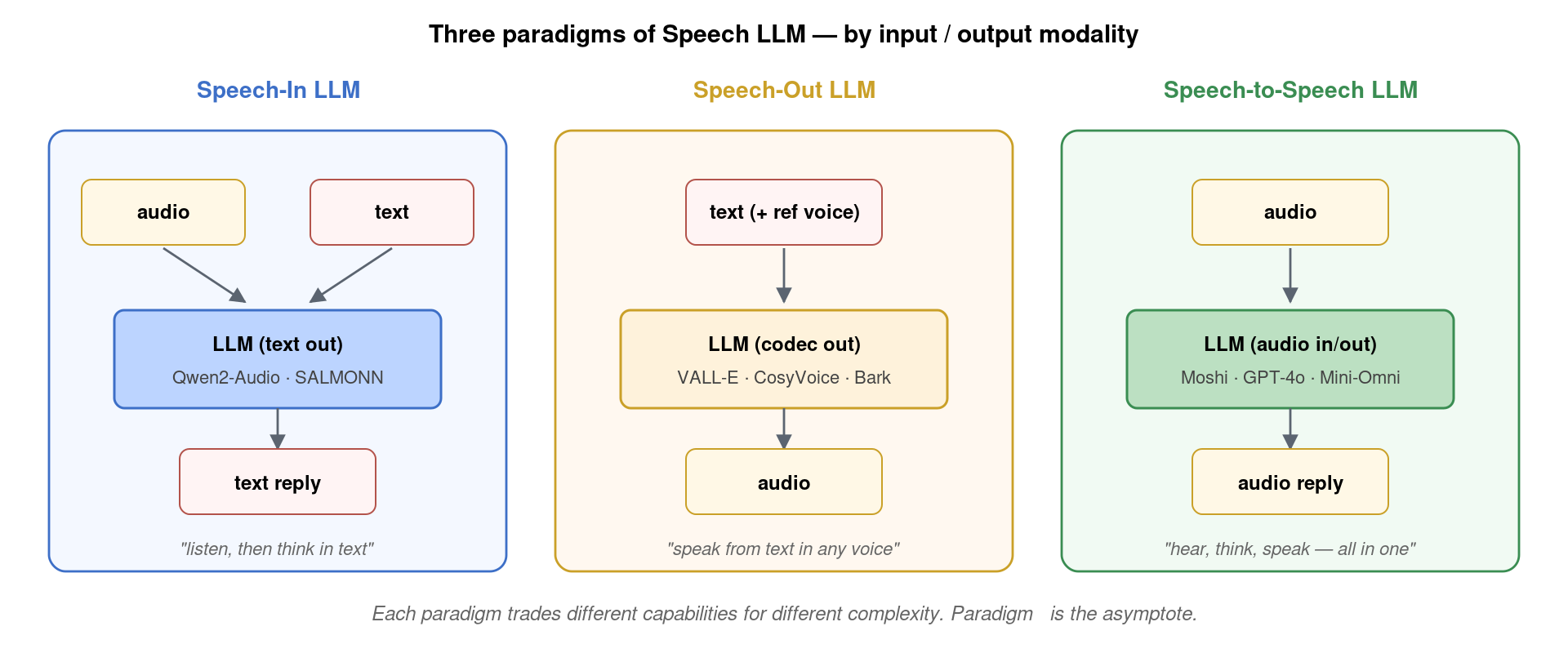
把 Speech LLM 按「输入/输出模态」做分类,得到三种范式:
- Speech-In LLM:输入音频、输出文本——「听完,用文字思考与回答」。代表:Qwen2-Audio、SALMONN、Audio Flamingo、Phi-4-Multimodal。
- Speech-Out LLM:输入文本、输出音频——「用任意声音读出来」。代表:VALL-E、CosyVoice 2、Bark、F5-TTS。
- Speech-to-Speech LLM (end-to-end):输入输出都是音频,中间完全在模型内部完成——「听、想、说一气呵成」。代表:Moshi、Mini-Omni、GLM-4-Voice、LLaMA-Omni、GPT-4o(闭源)。
三种范式不是互相替代,而是解决不同业务场景。Speech-In LLM 适合”语音搜索 / 音频问答 / 会议总结”;Speech-Out LLM 适合”配音 / 有声书 / 虚拟主播”;Speech-to-Speech LLM 适合”实时对话 / 语音 agent”。但从技术演进的角度看,第三种是终极形态——它包含了前两种,且能力上严格更强。这也是 2024 年以来学术界与工业界的研究重心。
3. 范式 ①:Speech-In LLM(让 LLM「听懂」音频)
Speech-In LLM 的核心问题是:怎么让一个为文本训练的 LLM 接受音频输入?主流方案是「audio encoder + adapter + LLM」三件套,其中 audio encoder 通常是 Whisper 或 wav2vec 2.0,adapter 是一个小型 MLP 或 Q-Former 把音频特征映射到 LLM 的 embedding 空间,LLM backbone 直接 fork 现有大模型 (Qwen / LLaMA):
- Qwen2-Audio(阿里 2024-07):Whisper-Large-v3 encoder + MLP adapter + Qwen2-7B LLM。7B 参数,支持 ASR、speech translation、audio QA、SoundCLS 等 16 个任务,是当下中文场景最强 Speech-In LLM 之一。
- SALMONN(清华 / 字节 2024):Whisper encoder + BEATs encoder(处理非语音音频) + Q-Former + Vicuna-13B LLM。最早把”语音+非语音音频” 共同处理的开源工作。
- Audio Flamingo(NVIDIA 2024):基于 ClapClapEncoder + LLaMA-2,主打通用音频理解(不只语音)。
- Phi-4-Multimodal(Microsoft 2025):把语音作为 multimodal Phi 模型的一种输入,用「LoRA on top of LLM」策略让一个 3.8B 模型同时支持文本、图像、语音三种输入。
这种范式的设计哲学是「最小入侵」——不动 LLM 主体,只加一个轻量 audio adapter。优点是:(1)能复用已有 LLM 的全部知识与能力,对话、推理、知识问答全部继承;(2)训练成本低,只需 fine-tune adapter + 部分 LLM 层,几百小时 GPU 即可;(3)架构简单,部署友好。缺点是:输出只能是文本——要发声还得拼一个外部 TTS,回到级联架构。
4. 范式 ②:Speech-Out LLM(让 LLM「说出」音频)
Speech-Out LLM 在前面 VALL-E 详解 与 CosyVoice 2 详解 已经深度讲过,这里只做范式总结:
- 核心架构:Text → AR Transformer LM → audio codec tokens → codec decoder → waveform。AR LM 部分就是一个标准 GPT 模型,词表扩展加上几千到几万个 audio token。
- VALL-E 路线:用无监督 Encodec token,AR + NAR 双模型分别处理 coarse / fine codebook。
- CosyVoice 2 路线:用监督式语义 token + Qwen2.5 backbone + Flow Matching decoder。这是当前的工业事实标准。
这种范式与 Speech-In LLM 完全对偶——前者把”音频 → token”映到 LLM 空间,后者把 LLM 输出的 token 映到”音频”。两条路线的工程难度对称:Speech-In 难在 audio encoder 与 LLM 的语义对齐,Speech-Out 难在 codec 设计与 token 数控制。
5. 范式 ③:End-to-End Speech-to-Speech LLM(终极形态)
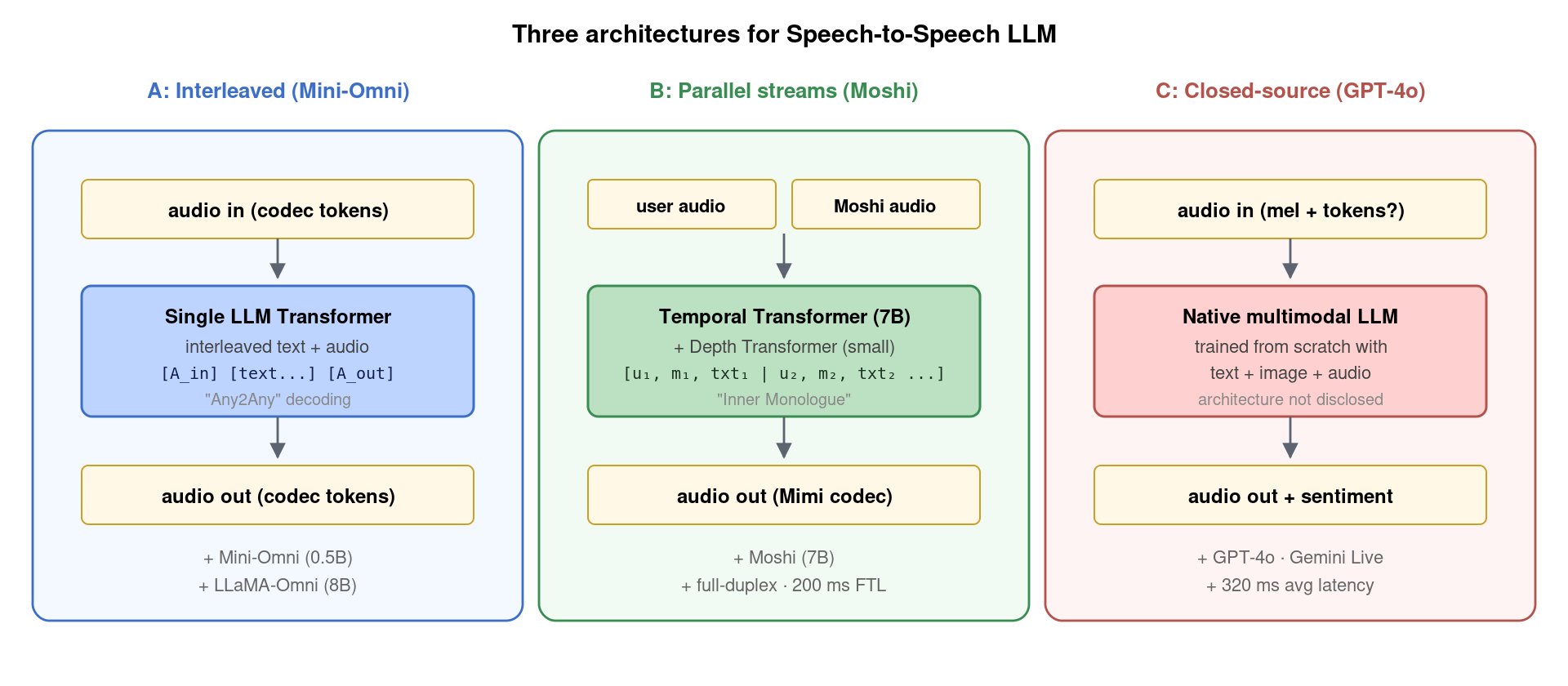
第三种范式是当下最激动人心的方向。它的核心挑战是:怎么让单个 Transformer 同时处理音频输入、文本思考、音频输出,且全双工流式实时?当前主流有三种技术架构:
5.1 Mini-Omni / LLaMA-Omni:Interleaved Token 路线
Mini-Omni(清华 2024-08)与 LLaMA-Omni(中科院 2024-09)走的是「把音频 token 与文本 token 混在同一序列里训练」这条路。具体做法是:
训练序列: [user_audio_tokens] [SEP] [text_response] [SEP] [model_audio_tokens]
这种”interleaved”设计的优雅之处在于:不改 LLM 架构,只扩词表——把 SNAC / Encodec 等 codec 的 audio token 加入原 LLM 词表,让模型学到”在 audio token 之后接 text、text 之后接 audio”的转换规律。Mini-Omni 用 Qwen2-0.5B 实现了第一个完全开源的端到端 voice agent;LLaMA-Omni 升级到 8B,加入”思考-说话同步”机制提升体验。这条路线的最大优势是简单,从一个 NLP 大模型出发只需要几十 GB 数据 fine-tune 即可。
5.2 Moshi:双 Transformer + 并行 Stream 路线
Moshi(Kyutai 2024-09)走了一条更激进的路线:同时建模「用户音频流 + 模型音频流 + 文本流」三条并行序列。它的核心创新:
- 双 Transformer 架构:一个 7B Temporal Transformer 沿时间方向建模主序列,一个小的 Depth Transformer 在每个时间步内建模 Mimi 8 codebook 的并行结构。
- Mimi codec 12.5 Hz:把帧率压到极致,让每秒只生成 100 token,是实现实时的关键。
- Inner Monologue:模型在生成音频 token 之前先生成与之时间对齐的文本 token(隐式 ASR),提升语义质量。
- 全双工对话:模型与用户的音频同时编码到序列中,模型可以”中途打断”用户、用户也可以”打断”模型——这是首个真正的全双工开源 voice agent。
Moshi 的理论延迟 160 ms(80 ms Mimi 帧 + 80 ms 模型 forward),实际在 L4 GPU 上 ~200 ms。这是开源 Speech LLM 第一次在用户体验上接近 GPT-4o。
5.3 GPT-4o / Gemini Live:闭源原生多模态
OpenAI GPT-4o 与 Google Gemini Live 走的是「从零训练原生多模态 LLM」路线——模型从一开始就在 text + image + audio 三种模态上联合预训练,不是把现有 LLM 改造。架构细节未公开,但根据用户体验推测:
- 使用某种 codec(可能类似 Mimi 的低帧率设计);
- 训练数据规模在万亿 token 量级(远超开源),含大量多模态对话数据;
- 模型参数估计 100B+;
- 实际延迟约 320 ms。
GPT-4o 的开放对外能力(情感感知、笑声 / 叹气合成、唱歌、多语种切换)目前仍领先开源约 6-12 个月。但 Moshi、GLM-4-Voice、Step-Audio 等 2024-2025 开源模型正在快速追赶。
把延迟方差、打断、口音补进这张表
上面这张对比表有一个我必须自己点破的局限:目前没有任何主流榜单能把「好不好聊」完整量化。以 VoiceBench 为代表的评测,构造方式决定了它的边界——把文本 benchmark 转成语音输入,考察「听懂并答对」,本质上是回合制问答。而真实语音对话的体验由另一组变量主导:打断与抢话的处理时机(全双工不只是「能同时收发」,是对「现在该不该说话」的实时决策)、延迟的方差而非均值(平均 320 ms 与「偶尔卡两秒」是完全不同的体验)、口音与噪声鲁棒性,以及长对话中的状态保持。这些维度 VoiceBench 基本不覆盖。
所以才会出现分数与口碑的背离:Moshi 开放 demo 后,社区的普遍反馈是「延迟惊艳,但对话内容容易跑偏」——榜单分数既解释不了前半句,也预测不了后半句。我的看法有三条:
- 现阶段语音对话模型的「体验排序」只能靠上手试,榜单只能做能力下限的过滤器,做不了选型的最终依据。
- 打断处理是被低估最严重的指标——它要求模型对对话节奏做毫秒级判断,这是文本 LLM 范式里根本不存在的问题,也最难被离线评测捕捉。
- 在行业级评测补齐之前,对任何「开源已追平 GPT-4o」的论断都应保留态度——追平的是可测的那部分,而用户感知恰恰集中在不可测的那部分。
6. 性能与能力对比
| 模型 | 团队 / 年份 | 参数 | 范式 | 开源 | 关键能力 | FTL |
|---|---|---|---|---|---|---|
| Whisper-Large-v3 | OpenAI 2023 | 1.55 B | ASR (非 Speech LLM) | ✅ | 多语种转录 / 翻译 | — |
| Qwen2-Audio | 阿里 2024-07 | 7 B | ① Speech-In | ✅ | 音频 QA / 翻译 / 16 任务 | — |
| SALMONN | 清华/字节 2024 | 13 B | ① Speech-In | ✅ | 语音 + 通用音频理解 | — |
| Phi-4-Multimodal | Microsoft 2025 | 3.8 B | ① Speech-In | ✅ | 文本 + 图像 + 语音三模态 | — |
| VALL-E 2 | Microsoft 2024 | ~0.3 B | ② Speech-Out | ✗ | zero-shot voice clone | — |
| CosyVoice 2 | 阿里 2024-12 | 0.5 B | ② Speech-Out | ✅ | 中文 SOTA TTS, 流式 | 150 ms |
| Mini-Omni | 清华 2024-08 | 0.5 B | ③ Speech-to-Speech | ✅ | 开源端到端对话 | ~500 ms |
| LLaMA-Omni | 中科院 2024-09 | 8 B | ③ Speech-to-Speech | ✅ | 思考-说话同步 | ~400 ms |
| Moshi | Kyutai 2024-09 | 7 B | ③ Speech-to-Speech | ✅ | 全双工 · Inner Monologue | ~200 ms |
| GLM-4-Voice | 清华 2024-10 | 9 B | ③ Speech-to-Speech | ✅ | 中英双语全双工 | ~300 ms |
| Step-Audio | StepFun 2025 | 130 B | ③ Speech-to-Speech | ✅ | 多语种大模型,对话能力极强 | ~500 ms |
| GPT-4o | OpenAI 2024-05 | ~100 B+ | ③ Speech-to-Speech | ✗ | 情感 / 笑声 / 唱歌 | ~320 ms |
| Gemini Live | Google 2024-08 | 未知 | ③ Speech-to-Speech | ✗ | 视频 + 语音多模态 | ~300 ms |
7. 2022-2025 时间线:从 Whisper 到 Step-Audio
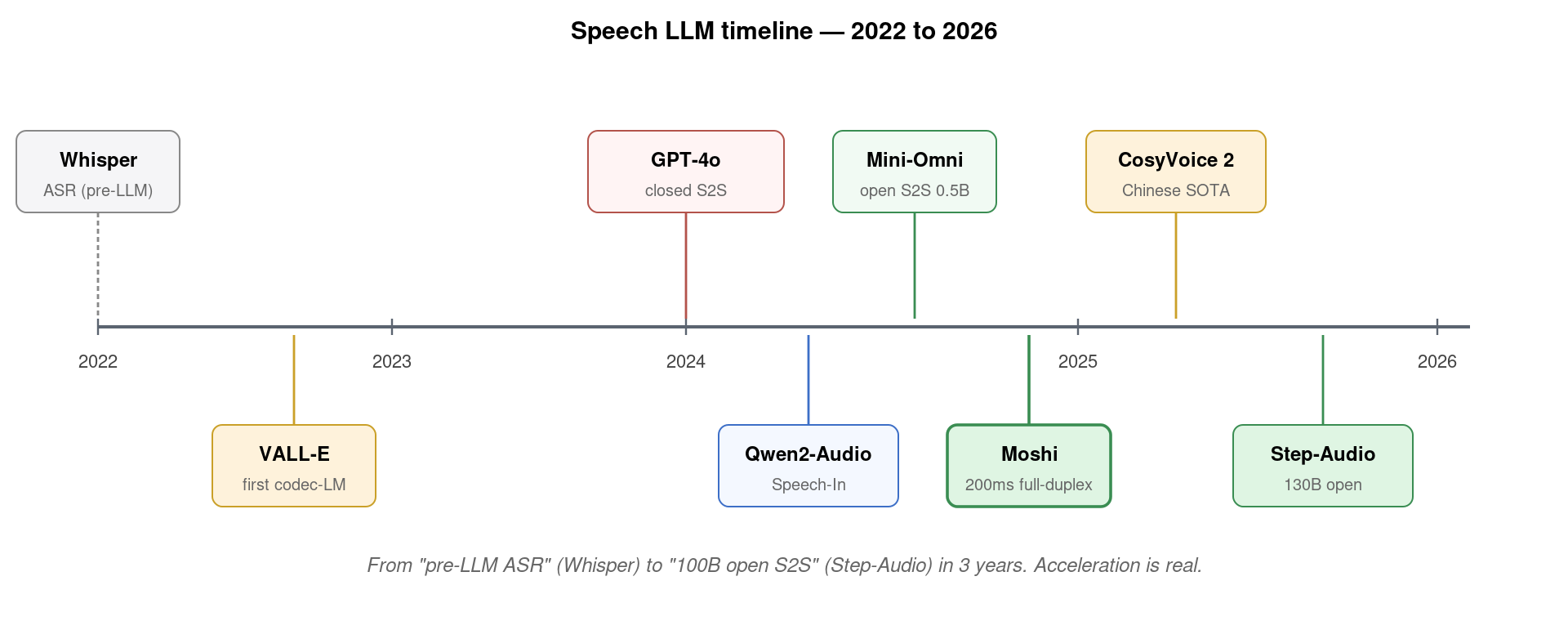
这条时间线浓缩了 3 年发展:2022 年 Whisper 还只是个 ASR 模型,2024 年 GPT-4o 让公众第一次见识端到端语音对话,2024 年下半年 Moshi 等开源模型快速跟进,2025 年 Step-Audio 把开源 Speech LLM 推到 130B 规模——开源生态用 4 个月追平了 GPT-4o 的体验,再用 8 个月超过了它的规模。这种速度在 NLP 大模型领域要 LLaMA 3 才能做到,语音领域更快。
8. 收敛趋势:所有路线终将合流
把三大范式放在一起看,能看到一个清晰的收敛趋势:
- 范式 ① 和 ② 正在被 ③ 吸收。Moshi 内部其实同时承担了 ASR(理解输入)+ LLM(推理)+ TTS(生成)三个任务。理论上一旦端到端语音 LLM 成熟,独立的 Speech-In / Speech-Out 模型会逐渐边缘化。
- 所有路线都用 codec 作为底层。无论 Mini-Omni、Moshi、GPT-4o 都把音频离散化成 token——Neural Codec 是这一切的基础设施。codec 的进步直接决定上层 Speech LLM 的能力上限。
- 所有路线都基于 GPT/LLaMA backbone。Qwen2-Audio fork Qwen2、CosyVoice 2 fork Qwen2.5、Mini-Omni fork Qwen2-0.5B、Moshi 自训 7B Transformer(架构与 LLaMA 同构)。NLP 大模型的所有训练 trick、推理优化、scaling law 都直接迁移到语音——这是范式合流的最深层证据。
- 多模态进一步扩展。Phi-4-Multimodal 把语音 + 图像 + 文本 + 视频统一到一个模型。Gemini Live 已经支持实时摄像头分析 + 语音对话。下一步是统一的”AnyModal LLM”——一个 Transformer 处理所有模态。
这与 Whisper 详解、VALL-E 详解 中我反复强调的「everything is token prediction」哲学完全一致——这条哲学不仅吃掉了 NLP / CV,也正在吃掉语音。语音 AI 不再是一个独立学科,它正在合并进通用多模态 LLM 的主线。
9. 开源 vs 闭源生态对比
| 维度 | 闭源 (GPT-4o, Gemini Live) | 开源 (Moshi, Mini-Omni, GLM-4-Voice) |
|---|---|---|
| 对话能力 | 最强(情感感知、唱歌、复杂推理) | 追赶中,基础对话已可用 |
| 延迟 | ~320 ms | ~200-500 ms (Moshi 最强) |
| 多语种 | 50+ 种,切换自然 | 主要中英,其他在改善 |
| 训练数据 | 未知,估计百万小时多模态 | 10-100 万小时,已公开 |
| 部署成本 | API 调用付费 | 自建服务,可控 |
| 典型用途 | 消费产品 (ChatGPT Voice) | 开发者 SDK、研究、私有部署 |
| 滞后约 | — | 6–12 个月 |
2026 年开源能否完全追平 GPT-4o?我的判断是 能力上能追平,但生态差距会持续——闭源公司有更多用户反馈数据来打磨细节体验(如打断时机、情感识别、唱歌),开源模型在这些”长尾能力”上很难快速赶上。但核心对话能力开源已基本追平,中文场景反而开源 (Step-Audio / GLM-4-Voice) 比闭源更强。
10. 工程化与未来展望
- 低帧率 codec 是基础。Mimi、WavTokenizer 等把帧率压到 12.5 Hz 甚至 25 Hz,是端到端语音 LLM 实时化的硬性前提。没有合适的 codec 就没有实时 Speech LLM。
- scaling law 同样适用。Step-Audio 130B 证明语音 LLM 也遵循 scaling law——更大模型 + 更多数据 = 更好能力。预计 2026 年开源会出现 200-300B 的语音 LLM。
- Inner Monologue / 思考-说话同步。Moshi、LLaMA-Omni 都引入了”先生成隐式文本、再生成对应音频”的机制,提升语义质量。这正在成为 Speech LLM 的标准做法。
- 全双工 + 中途打断。这是 voice agent 用户体验的下一个门槛。Moshi 已经做到,预计 2026 年所有主流 Speech LLM 都会支持。
- 评估缺乏统一 benchmark。当前没有 GLUE/HELM 级别的统一 Speech LLM 评测,VoiceBench 等正在尝试填补,但远不够。预计 2026 年会出现行业公认的标准评测套件。
- 多模态进一步合流。Phi-4、Gemini Live 已经把视觉加进来,下一步是把 robotics action token、code token 都吃进同一个模型——「AnyModal LLM」。语音只是其中一个 channel。
11. 总结:Speech AI 的「ChatGPT 时刻」已经到来
2022 年 11 月 ChatGPT 让公众第一次见识 LLM 的对话能力,引爆了 NLP 大模型的爆发;2024 年 5 月 GPT-4o 让公众第一次见识 Speech LLM 的对话能力,正在引爆语音 AI 的同等爆发。语音技术的”ChatGPT 时刻”已经到来——它的影响会比 NLP 更深远,因为语音是最自然的人机交互界面。
对从业者而言,当下的现实路线选择:
- 需要”听懂音频做问答”——用 Qwen2-Audio 或 Phi-4-Multimodal;
- 需要”用任意声音说出来”——用 CosyVoice 2 或 F5-TTS;
- 需要”端到端实时对话”——用 Moshi(最快)或 GLM-4-Voice(最强中文);
- 需要”商业级稳定+多语种”——用 GPT-4o API 或 Gemini Live;
- 需要”自建 + 极致中文”——用 Step-Audio。
这是我「语音技术深度系列」的第 14 篇,也是这个系列「阶段性收官」的一篇。从 CTC 经典算法到 Whisper 大规模弱监督、从 Conformer backbone 到 SSL 三部曲、从 Streaming ASR 工程化到 TTS 演进史、从 VALL-E codec LM 到 CosyVoice 2 混合架构、从 F5-TTS Flow Matching 到 Neural Codec 底座,再到本文的 Speech LLM 顶层综述——14 篇文章把 2018 年以来端到端语音技术的整张地图完整画了下来。如果你按顺序读完所有 14 篇,你应该已经具备了面向 2026 年的全栈语音 AI 知识框架。
参考资料
- Chu, Y. et al. Qwen2-Audio Technical Report. arXiv:2407.10759, 2024.
- Tang, C. et al. SALMONN: Towards Generic Hearing Abilities for Large Language Models. arXiv:2310.13289, ICLR 2024.
- Microsoft. Phi-4-Multimodal Technical Report. 2025.
- Xie, Z. & Wu, C. Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming. arXiv:2408.16725, 2024.
- Fang, Q. et al. LLaMA-Omni: Seamless Speech Interaction with Large Language Models. arXiv:2409.06666, 2024.
- Défossez, A. et al. Moshi: a speech-text foundation model for real-time dialogue. arXiv:2410.00037, 2024.
- Zeng, A. et al. GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot. arXiv:2412.02612, 2024.
- Step-Audio Team. Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction. arXiv:2502.11946, 2025.
- OpenAI. GPT-4o: Hello GPT-4o. openai.com/hello-gpt-4o, 2024.
- Google DeepMind. Gemini Live. deepmind.google/gemini, 2024.
- Chen, Y. et al. VoiceBench: Benchmarking LLM-Based Voice Assistants. arXiv:2503.14541, 2025.
![]()
2026-01-20 at 9:35 上午
“先生成与音频时间对齐的隐式文本、再生成音频”,等于把 ASR 的语义约束内化进生成过程,难怪 Moshi 语义质量比纯 audio token 好