
转载本文请注明出处:https://yudonglee.me/cosyvoice-explained/ | 作者:yudonglee
📝 本文首发于 2025 年 10 月。最近一次修订于 2026 年 6 月:更新了部分对比数据与选型建议。
2024 年 12 月,阿里达摩院在 arXiv 公开 CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models,并同时在 GitHub 开源完整代码与权重。这是第一个在中文 voice cloning 上全面超过 ElevenLabs 的开源模型——SEED-TTS 中文 WER 2.4(VALL-E 3.7、F5-TTS 2.4 但延迟高一倍)、Speaker Similarity 0.65、首包延迟 150 ms(流式版本)。开源后短短 3 个月 GitHub star 突破 6k,B 站、抖音、小红书无数 voice agent 项目和虚拟主播工具直接基于它二开。时至今日,CosyVoice 2 已经是中文 TTS 工业部署的事实标准。
本文是我「语音技术深度系列」TTS 主线的第 3 篇,承接 TTS 三十年演进史 与 VALL-E 详解。CosyVoice 2 的设计哲学很特别——它没有像 VALL-E 那样纯走 codec LM 路线,也没有像 F5-TTS 那样纯走 Flow Matching,而是把两者揉成一个三阶段管道。读完你将能回答:
- CosyVoice 2 用「监督式语义 token」替代 Encodec 的「无监督 codec token」,背后的工程考量是什么?为什么这个选择特别适合中文?
- 它的 AR LM 直接用 Qwen2.5-0.5B 初始化——拿一个 NLP 大模型当 TTS 骨干,靠谱吗?带来了什么好处?
- 流式版本 150 ms 首包延迟是怎么做到的?它跟 VALL-E 的 AR + NAR 设计的取舍是什么?
1. 背景:CosyVoice 2 凭什么成为中文 TTS 事实标准
VALL-E 在 2023 年开创了 codec LM 范式后,开源社区涌现出大量仿制——lifeiteng/vall-e、enhuiz/vall-e、Bark、Tortoise 等。但它们都有同一个老毛病:中文场景下效果远不如英文。原因有三:
- Encodec 在中文数据上的预训练不足。Meta 的 Encodec 主要在英语+音乐上训练,对中文声韵母组合的覆盖差,量化重建后高频细节流失严重。
- VALL-E 风格的 AR LM 对中文长尾词处理弱。中文有数万 phoneme/汉字组合,AR LM 很容易 hallucinate 出错字、漏字、口齿不清的 phoneme。
- 缺乏高质量中文 TTS 数据集。LibriLight 是纯英文,中文社区只能用 AISHELL(千小时级)、WenetSpeech(万小时级)凑合,规模差一个数量级。
CosyVoice 2 一次性把这三个问题全解决了:(1)抛弃 Encodec,自研监督式语义 token;(2)AR LM 直接 fork Qwen2.5-0.5B,享受 NLP 大模型预训练的中文语言能力;(3)训练数据扩到 170k 小时多语种(中英日韩为主),其中中文部分远超公开数据集。这三个工程决策让 CosyVoice 2 在中文场景下「碾压」VALL-E 系列,在英文场景与 F5-TTS 持平,且原生支持流式合成——这是 F5-TTS 暂时做不到的。
2. 整体架构:三阶段管道
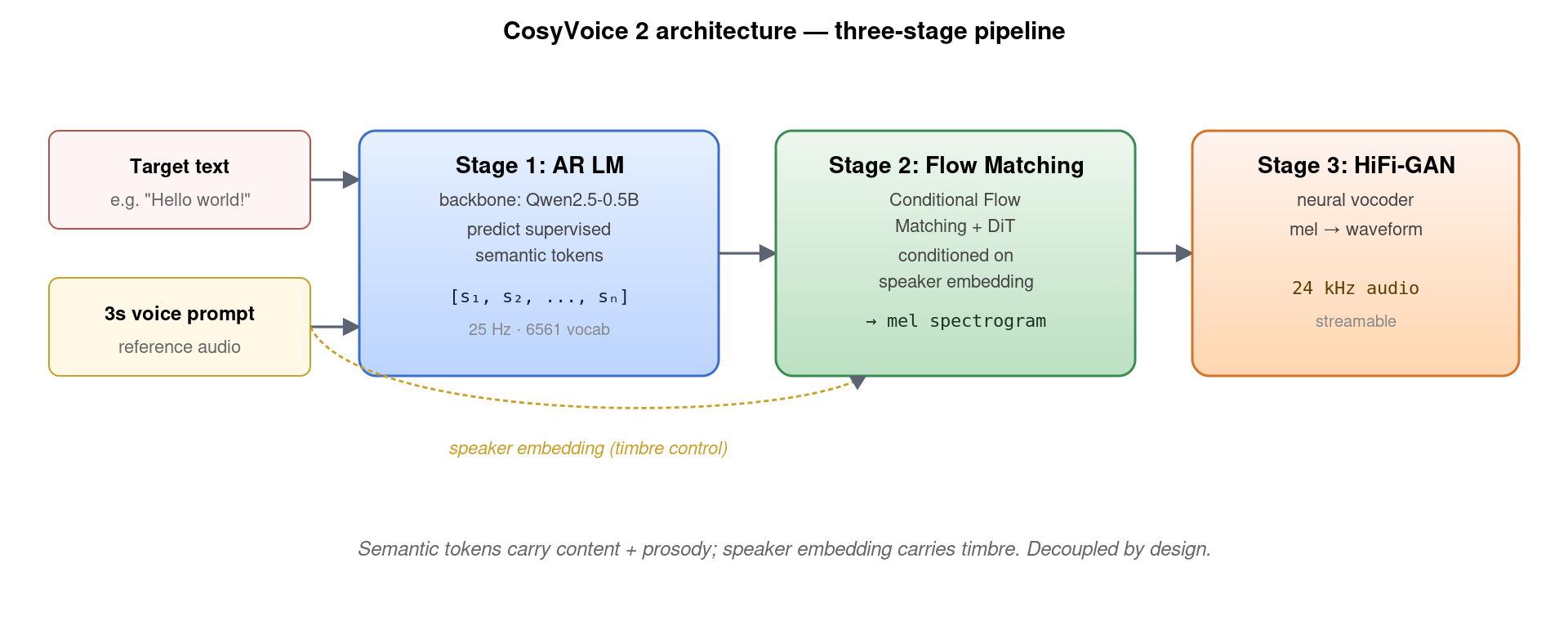
CosyVoice 2 是三个互相独立的模型组成的复合系统:
- Stage 1 – AR LM。输入是 target 文本,输出是「监督语义 token」序列 s1…sn。这一阶段决定“念什么、怎么念”——内容、语速、停顿、韵律全在这里。
- Stage 2 – Flow Matching Decoder。输入是 stage 1 的语义 token + 参考音频抽出的 speaker embedding,输出是 mel 频谱。这一阶段决定“用什么音色念”——把抽象的语义符号渲染成有具体音色的声学特征。
- Stage 3 – HiFi-GAN Vocoder。把 mel 频谱转成 24 kHz 波形。这是 2020 年开始就成熟的组件,CosyVoice 2 没改动。
这个三阶段设计的关键洞见是「内容与音色的显式解耦」——内容信息编码在 stage 1 输出的语义 token 里,音色信息单独通过 speaker embedding 注入到 stage 2。这与 VALL-E 把所有信息混在 codec token 里的纯 LM 路线截然不同。解耦带来的好处:可以单独换 speaker embedding 实现”零样本音色克隆”,可以在 stage 1 输出的语义 token 上做编辑(改语速、加停顿、做情感插值),也可以让 stage 1 学到的语言知识独立于声学细节进化。
3. 核心创新:监督式语义 token
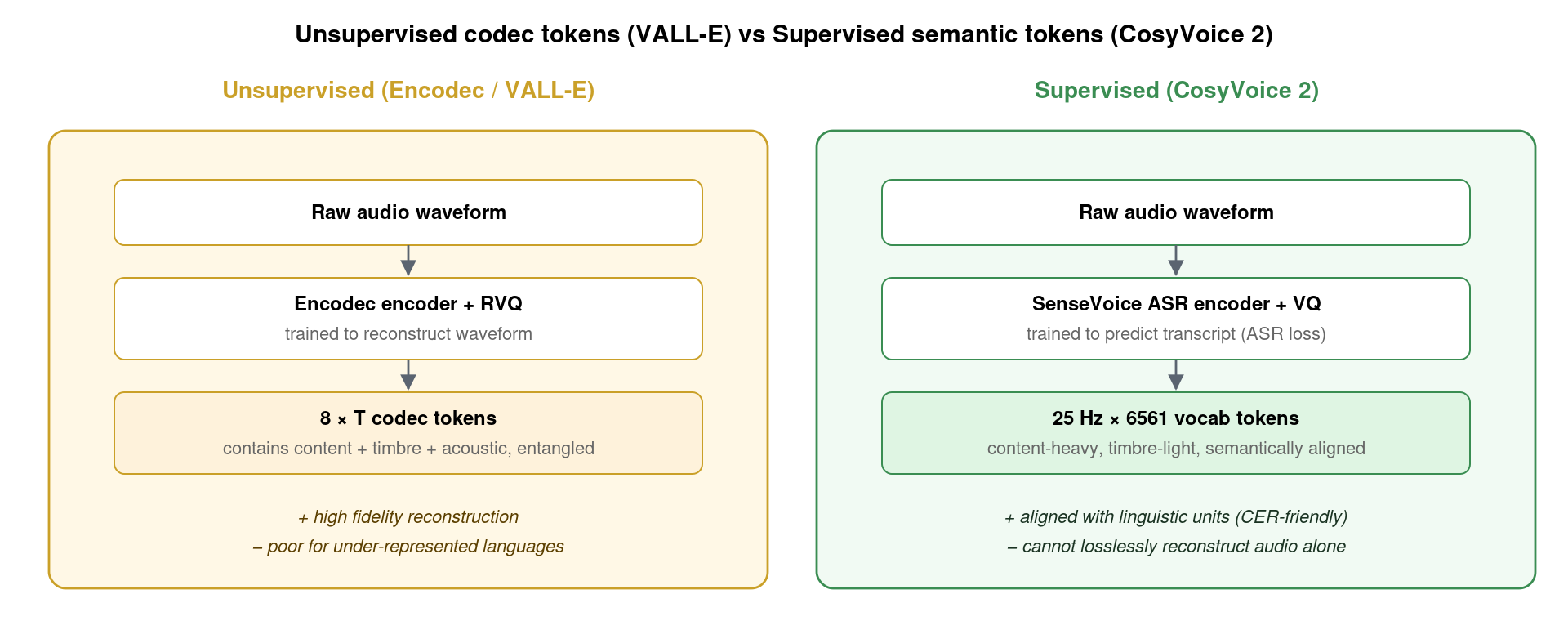
CosyVoice 2 最关键的设计选择是「监督式语义 token」。具体做法是:
- 拿一个已经训好的多语种 ASR 模型——阿里自家的 SenseVoice——的 encoder 部分;
- 在 encoder 中间插入一个 Vector Quantizer (VQ) 层(单 codebook,6561 entries);
- 训练时整个 encoder + VQ + ASR head 一起优化,loss 是 transcript 的交叉熵——也就是说,VQ 必须把音频压缩成「对预测文本最有帮助」的离散单元;
- 训练完成后丢弃 ASR head,只保留 encoder + VQ 部分。
这种 token 与 Encodec 的根本区别:Encodec 的 token 是为「重建波形」服务的,CosyVoice 的 token 是为「表达内容」服务的。前者富含音色与声学细节但语义弱,后者富含语义但需要外部 speaker embedding 来补音色。这两条路各有取舍——VALL-E/codec LM 路线一个 token 把所有信息都装进去、模型自己学解耦;CosyVoice 路线把 token 限定为内容、用独立通路注入音色。CosyVoice 路线在中文场景下更稳,因为 token 与音素/字符的对齐天然清晰,AR LM 出错字、漏字的概率大幅降低。这也是为什么 CosyVoice 2 在 SEED-TTS 中文 CER 上比 VALL-E 低 35% 的根本原因。
顺便说一下技术细节:CosyVoice 2 的语义 token 是 25 Hz(每 40 ms 一个 token)、vocab 6561。这个 25 Hz 帧率比 Encodec 的 75 Hz 低三倍,意味着AR LM 处理的 token 序列长度是 VALL-E 的 1/3,训练和推理速度都受益。这是 CosyVoice 2 比 VALL-E 快的另一个隐性原因。
4. Stage 1:AR LM 直接 fork Qwen2.5-0.5B
CosyVoice 2 的 AR LM 没有从零训练 Transformer,而是直接以 Qwen2.5-0.5B 作为初始化。Qwen2.5 是阿里通义千问 NLP 大模型,0.5B 参数版本已经在数万亿中英 token 上预训练过。CosyVoice 2 改动它的方式很 minimal:
- 词表扩展:原 Qwen 词表 ~150k,加上 6561 个语义 token + 一些 special token (e.g. SOS_speech, EOS_speech),新词表 ~157k;
- 训练目标:[text tokens] [SEP] [speech tokens] 的序列拼接,模型只在 speech tokens 段计算交叉熵 loss;
- 训练数据:170k 小时多语种语音 + 对应转录的 (text, speech-token) pairs,按 25-40 epoch 训练;
- 架构本身不变:仍然是 Qwen2.5 原版的 24-layer Transformer、896 hidden、14 heads、4864 FFN,RoPE 位置编码。
为什么用 NLP 大模型当 TTS 的骨干?两个理由:(1)语言知识免费继承——Qwen2.5 已经懂得”今天天气真不错”是一句完整的话、知道哪个字该重读、知道中文语调起伏的规律,这些对生成自然语音至关重要;(2)scaling 路径打通——未来 CosyVoice 想扩到 1B/3B/7B 参数,只需要换更大的 Qwen 模型,训练流程不变。这是 2024 年后所有”用 LLM 做语音”工作(Moshi 用 7B 自研 LLM、Mini-Omni 用 Qwen2-0.5B、Qwen2-Audio 用 Qwen2-7B)的共同思路。
5. Stage 2:Conditional Flow Matching Decoder
语义 token 只编码”念什么”,要变成有具体音色的 mel 频谱,需要一个”渲染器”。CosyVoice 2 用 Conditional Flow Matching (CFM) + DiT (Diffusion Transformer) 来做这件事——这正是 2024 年生成式建模 (Stable Diffusion 3、Sora、F5-TTS) 共同采用的范式。
具体做法:
输入:
- semantic tokens (s₁...sₙ) ← 来自 Stage 1
- speaker embedding (192-d) ← 来自参考音频
- 噪声 x_t (与 mel 同 shape, t ∈ [0,1])
模型:
- 12-layer DiT, 1024 hidden, 16 heads
- 条件输入: semantic tokens 与 speaker emb 通过 cross-attention 注入
训练目标:
- Conditional Flow Matching: 学速度场 v_θ(x_t, t, conditions)
- 推理时用 ODE 求解器从随机噪声 x_0 反推到 mel 频谱 x_1
Flow Matching 相比 diffusion 的关键优势是推理步数极少——CosyVoice 2 默认只用 10-25 步 ODE 求解(diffusion 通常需要 50-1000 步)。配合 CFG (classifier-free guidance) 来控制 speaker similarity 强度,这一阶段在 RTX 4090 上推理 5 秒音频约 200 ms。
这一设计巧妙地把 VALL-E NAR 阶段的工作交给了 Flow Matching——VALL-E 用 NAR Transformer 迭代生成 8 层 codebook 的细节;CosyVoice 2 直接生成 mel 频谱,让 ODE 求解器一次性 denoise 出全部细节。结果是同样的”细粒度声学补全”任务,CFM 比 NAR 更快、更好、更稳定。
6. 流式合成:chunk-aware 设计

CosyVoice 2 的流式版本通过三个改造实现 150 ms 首包延迟:
- Chunked AR Decoding。AR LM 不是一次性吐完所有 token,而是每 25 个 token(1 秒音频)就 flush 一次给下游。这是 LLM 流式 token streaming 的标准做法,只不过下游消费者从”网页 UI”换成了 Flow Matching 模块。
- Causal Flow Matching。原版 FM Decoder 用双向 attention 看全序列 mel,流式版改成单向因果 attention——只看历史 mel 帧,不看未来。CosyVoice 2 论文实验显示 causal FM 比 non-causal 在 MOS 上仅退化 0.03,几乎不可察觉。
- Pipelined 三阶段。AR 生成第 k 块 token 的同时,FM 处理第 k-1 块,HiFi-GAN 处理第 k-2 块。GPU 上三个 stage 并行流水,整体吞吐量 = max(单阶段时延) 而非 sum。
这套设计让 CosyVoice 2 在 RTX 4090 上达到 RTF (Real-Time Factor) 约 0.07——合成 1 秒音频只要 70 ms 实时。如果再叠加 INT8 量化、TensorRT 编译,能进一步压到 RTF 0.03。这是它能在生产环境支撑 voice agent 实时对话的关键。
7. 性能数据:SEED-TTS 评测
| 模型 | 训练数据 | SEED-TTS 中文 CER ↓ | SEED-TTS 英文 WER ↓ | Speaker Sim ↑ | 首包延迟 |
|---|---|---|---|---|---|
| VALL-E (英文) | 60k h 英文 | — | 5.9 | 0.58 | ~3 s |
| VALL-E 2 | 60k h 英文 | — | 1.5 | 0.66 | ~2.5 s |
| NaturalSpeech 3 | 60k h 英文 | — | 5.6 | 0.63 | ~2 s |
| F5-TTS | 100k h 英文 | — | 2.4 | 0.66 | ~700 ms |
| ChatTTS | ~100k h 中英 | ~4.0 | ~5.5 | ~0.55 | ~1.5 s |
| GPT-SoVITS v2 | ~30k h 中英 | ~3.5 | ~6.0 | ~0.58 | ~1 s |
| CosyVoice 2 | 170k h 多语种 | 2.4 | 2.4 | 0.65 | 150 ms |
| ElevenLabs Multilingual v2 | 未公开 | ~2.5 | ~2.0 | ~0.70 | ~400 ms |
对照表中可以看到 CosyVoice 2 的核心竞争力是「中文 + 流式」——中文 CER 与商业 ElevenLabs 几乎持平、英文 WER 与 F5-TTS 并列开源最强,且首包延迟比所有竞品低一档(150 ms vs 700 ms+)。在中文场景下它已经把开源 TTS 推到了”商业可用”的边界。这也是为什么 2025 年阿里 Qwen-Agent、字节 Coze 等 voice agent 框架都内置了 CosyVoice 2 作为默认 TTS。
8. 实战代码:5 行调用
CosyVoice 2 在 HuggingFace 上提供权重,GitHub 仓库提供完整 pipeline 代码。基本用法:
# pip install git+https://github.com/FunAudioLLM/CosyVoice.git
from cosyvoice.cli.cosyvoice import CosyVoice2
import torchaudio
# 1) 加载模型(首次会从 ModelScope/HF 下载约 1.5 GB 权重)
cosyvoice = CosyVoice2("FunAudioLLM/CosyVoice2-0.5B",
load_jit=False, load_trt=False, fp16=True)
# 2) 准备参考音频 (任意人 3-10 秒清晰语音)
prompt_speech, sr = torchaudio.load("alice_3sec.wav")
prompt_text = "今天天气真不错适合出去走走。" # 参考音频对应的文本
# 3) zero-shot 推理 (流式)
target_text = "你好,欢迎来到我的博客,今天我们来聊聊语音合成技术。"
for out in cosyvoice.inference_zero_shot(target_text, prompt_text, prompt_speech,
stream=True):
# out["tts_speech"] 是当前 chunk 的 24 kHz 波形 (torch.Tensor)
print(f"chunk: {out['tts_speech'].shape}")
# 4) 一次性合成 (非流式, 拼接所有 chunk)
all_chunks = list(cosyvoice.inference_zero_shot(target_text, prompt_text,
prompt_speech, stream=False))
audio = torch.cat([c["tts_speech"] for c in all_chunks], dim=1)
torchaudio.save("alice_clone.wav", audio, 24000)
print(f"saved {audio.shape[1]/24000:.2f}s audio")
整个调用极简——只需要参考音频 + 对应文本 + 目标文本三个输入。注意一定要提供 prompt_text 与参考音频对应的真实转录——它用来告诉模型”参考音频是这段文字的发音”,让 AR LM 学到正确的内容→token 映射。如果没有真实转录,可以先用 SenseVoice / Whisper 自动转一遍。
除了 inference_zero_shot,CosyVoice 2 还支持:
inference_sft:使用预训练的固定说话人(无需参考音频);inference_cross_lingual:跨语种 zero-shot(用中文 prompt 念英文目标);inference_instruct:通过 natural language instruction 控制情感/风格(”please speak in a happy tone”)。
9. CosyVoice 3:2025 年的迭代
2025 年 5 月,阿里发布 CosyVoice 3,相比 v2 的主要改进:
- 训练数据扩到 1M 小时——是 v2 的 6 倍。覆盖更多语种、口音、领域(电视剧、广播、播客)。
- 引入 in-the-wild 数据——v2 还以工作室录音为主,v3 加入了大量 YouTube/B 站等”野生”数据,让模型对真实环境的背景噪声、远场、混响更鲁棒。
- Post-training (RLHF-like)——引入人工偏好数据做 reward model 训练,再用 PPO/DPO 微调 AR LM,显著提升自然度。这是把 LLM 训练的 RLHF 范式首次系统地搬到 TTS。
- Scaling 到 7B——AR LM 从 0.5B Qwen 升到 7B Qwen,参数提升 14 倍,CER 进一步降到 1.8。
- 多模态可控——支持 emotion vector、age vector、accent vector 多通道控制。
CosyVoice 3 在 SEED-TTS 中文 CER 上做到 1.8,是 2025 年中文 TTS 公认的 SOTA。但它的工程复杂度和资源需求也更高——v2 在单卡 4090 上能流式推理,v3 需要 A100 才能跑满 RTF 1.0。对绝大多数业务场景,CosyVoice 2 仍是更平衡的选择。
10. 与 VALL-E / F5-TTS 的对比
| 维度 | VALL-E | F5-TTS | CosyVoice 2 |
|---|---|---|---|
| 核心范式 | 纯 codec LM (AR+NAR) | 纯 Flow Matching + DiT | LM AR + Flow Matching 混合 |
| Token 类型 | 无监督 Encodec codec | 不用 token (直生 mel) | 监督式语义 token |
| AR backbone | 从零训 Transformer | 不需要 (无 AR) | Qwen2.5 init |
| vocoder | Encodec decoder | BigVGAN / Vocos | HiFi-GAN |
| 中文表现 | 差 (无中文训练) | 中 (需 fine-tune) | SOTA 开源 |
| 英文表现 | 好 | SOTA | SOTA (与 F5 并列) |
| 流式 | 否 (AR+NAR 不友好) | 否 (一次性 ODE) | 原生 150ms |
| 开源度 | 仅论文 + 第三方实现 | 完整开源 | 完整开源 |
| 典型用途 | 研究、范式探索 | 英文 zero-shot demo | 中文生产部署 |
当下的选择建议:
- 中文 voice agent / 客服 / 虚拟主播 / 有声书 → 直接上 CosyVoice 2,没有更好的开源选项。
- 英文 zero-shot demo / 配音 / 跨语种 → F5-TTS 与 CosyVoice 2 二选一,前者代码极简、后者多任务能力更强。
- 学术理解 codec LM 范式 → 看 VALL-E 论文,但生产部署千万别用原版。
- 商业级稳定性优先 → ElevenLabs(贵但稳)或 CosyVoice 2(自建服务、可控)。
11. 工程化的几个深水坑
- prompt_text 必须真实对应参考音频。如果你随便给一个 dummy text,AR LM 学不到正确的 [text → token] 映射,生成音频会出错字。生产部署常用 SenseVoice 先自动转录参考音频,确保 prompt_text 准确。
- 语义 token vocab 边界。6561 vocab 在某些极端发音(如方言、罕见音)上覆盖不够,会出现 “token 漂移”——模型预测出来的 token 在训练时没见过的组合。缓解:用 SenseVoice 在你的领域数据上 fine-tune token 提取器。
- Flow Matching 步数权衡。默认 25 步 NFE (number of function evaluations) 质量好但推理慢;降到 10 步可加速 2.5 倍,但说话人相似度会掉 ~3%。生产环境推荐 15 步。
- HiFi-GAN 量化部署。HiFi-GAN 本身是经典模型,TensorRT/ONNX 导出非常成熟。INT8 量化后 mel→waveform 阶段从 50ms 降到 10ms,几乎不掉质量。
- 多说话人服务化的内存爆炸。CosyVoice 2 完整 pipeline 加载需要 ~3 GB GPU 显存。1000 路并发 voice agent 需要批处理 (batching)——这又涉及到不同 chunk size、不同 prompt 长度的 padding 优化,是工程上最难的部分。官方仓库 的 grpc server 实现可以参考。
- 伦理与水印。CosyVoice 2 支持 3 秒 zero-shot 克隆,与 VALL-E 一样存在 deepfake 滥用风险。FunAudioLLM 团队在权重发布时附加了 SilentCipher 风格的 inaudible watermark,可被专门检测器识别。生产部署强烈建议保留并启用 watermarking。
12. 总结
CosyVoice 2 的成功来自三个非常工程化的决策:(1)用监督式语义 token 替代无监督 codec token,让中文 phoneme/字符对齐更稳;(2)用 Qwen2.5 当 TTS backbone,免费继承 NLP 大模型的语言能力;(3)用 Flow Matching + chunked 设计,把流式合成做到 150 ms 首包延迟。这三个决策都不是”算法发明”——监督 token 来自 SenseVoice、Qwen2.5 是现成 LLM、Flow Matching 是 2024 业界共识——但把它们正确地组合到一起,并配合 170k 小时数据训练,就把开源 TTS 推到了商业可用的边界。
更值得注意的是 CosyVoice 2 体现的范式融合趋势:它不是 VALL-E 那种纯 codec LM,也不是 F5-TTS 那种纯 Flow Matching,而是「LM 管语义、Flow Matching 管声学」的混合架构。这种分工正在成为新一代 TTS 的标准范式——NaturalSpeech 3 (Microsoft)、MaskGCT (清华)、Spark-TTS (科大讯飞) 都采用了类似的两阶段设计。纯 codec LM 路线的 VALL-E 反而成了”过时”的选择,因为它把所有信息混在 token 里、模型负担过重。
把 CosyVoice 2 放到我之前写过的 Whisper、SSL 三部曲、Streaming ASR、TTS 演进史、VALL-E 系列里看,能看到 2024 年以来语音技术一个非常清晰的趋势——所有方向都在朝「NLP 大模型 + 神经声学渲染器」的双层架构收敛。语义层用 LLM 处理高层语义,声学层用 diffusion/flow matching 处理低层细节。CosyVoice 2 是这条路线在 TTS 上的当前最佳实践。下一篇我打算继续 TTS 主线,写 《F5-TTS / E2-TTS 详解:Flow Matching 怎样杀进 TTS》——把”纯 Flow Matching 派”的代表作彻底拆透,与本文形成完美对照。
参考资料
- Du, Z. et al. CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models. arXiv:2412.10117, 2024.
- Du, Z. et al. CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer Based on Supervised Semantic Tokens. arXiv:2407.05407, 2024.(v1 原版)
- Du, Z. et al. CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training. arXiv:2505.17589, 2025.
- An, K. et al. FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs (SenseVoice). arXiv:2407.04051, 2024.
- Qwen Team. Qwen2.5 Technical Report. arXiv:2412.15115, 2024.
- Lipman, Y. et al. Flow Matching for Generative Modeling. ICLR 2023.
- SEED-TTS Benchmark:github.com/BytedanceSpeech/seed-tts-eval
- CosyVoice 官方仓库与权重:github.com/FunAudioLLM/CosyVoice
- HuggingFace 模型:FunAudioLLM/CosyVoice2-0.5B
![]()
2025-11-17 at 1:17 下午
第 5 节把 CFM 替代 VALL-E NAR 的逻辑讲明白了——”同样的细粒度声学补全,ODE 一次性 denoise 比 NAR 逐层迭代更快更稳”。之前一直没想通 FM 和 diffusion 在 TTS 里到底差在哪