转载本文请注明出处:https://yudonglee.me/codec-explained/ | 作者:yudonglee
📝 本文首发于 2025 年 12 月。最近一次修订于 2026 年 6 月:更新了趋势判断与选型决策树。
2022 年之前,”音频编解码器”(audio codec)是一个相当无趣的工程话题——MP3、AAC、Opus 几十年没有大变化,听起来又老又稳。但到了 2024 年,codec 突然变成了语音 AI 圈最性感的研究方向。原因很简单:VALL-E(2023)、Moshi(2024)、CosyVoice(2024)、F5-TTS(2024)这些新一代 TTS / 语音 LLM 全部以 neural audio codec 作为”分词器”——把音频离散化成 token 序列,让 LLM 思路能直接处理音频。codec 的好坏直接决定上层模型的速度上限和质量上限。
本文是「语音技术深度系列」TTS 主线第 5 篇,紧接 F5-TTS 详解。这次我们把视角下沉到「语音 AI 的底层基础设施」——彻底拆透 4 个主流 neural audio codec:SoundStream(Google 2021 开山之作)、Encodec(Meta 2022 当代标准)、DAC(Descript 2023 高保真)、Mimi(Kyutai 2024 流式低帧率)。读完你将能回答:
- RVQ-VAE 究竟是什么?为什么它是所有现代音频 codec 的共同基础?
- SoundStream → Encodec → DAC → Mimi 四代演进各自解决了什么问题?
- 2024 年的 codec 设计趋势——更低帧率、更少 codebook、流式友好——背后的工程驱动力是什么?
- 给定一个 TTS 或语音 LLM 项目,我该选哪个 codec?
1. 背景:从 MP3 到 LLM 时代的 codec
传统音频压缩有两个目标:降低比特率(让音频文件更小)和保持人类听感(不可察觉的损失)。MP3、AAC、Opus 都围绕这两个目标用心理声学 (psychoacoustic) 模型做了几十年精雕细琢——什么频率人耳不敏感就丢、什么时刻被掩蔽就压低分辨率。结果是 Opus 在 32 kbps 就能编码可接受的语音,6 kbps 是行业公认的”实用下限”。
但 neural codec 时代加入了第三个目标:输出离散 token 序列,便于 LLM 建模。这个新目标让经典 codec 完全不适用——MP3 的 bit stream 是连续浮点数的熵编码结果,无法直接当成 LLM 的”单词”。语音 LLM 需要的是固定 vocab 大小的整数序列,每个整数代表一个”音频 token”。这正是 neural codec 的卖点:
| 维度 | 经典 codec (Opus) | Neural codec (Encodec) |
|---|---|---|
| 输出形式 | 变长比特流 | 固定时步的整数 token |
| 核心方法 | 心理声学 + 熵编码 | RVQ-VAE 端到端学习 |
| 设计目标 | 最小比特率 / 高听感 | 低帧率 / 易被 LLM 建模 |
| 典型比特率 | 6–24 kbps | 1.5–24 kbps |
| 是否可微 | 否 | 是 (能与 LLM 联合训练) |
| 典型用途 | WhatsApp / Zoom / 流媒体 | VALL-E / Moshi / CosyVoice |
所以 neural codec 不是要替代 Opus——后者在传统 VoIP/直播场景仍然无可替代。它是为 「LLM-as-Audio-Processor」 这种新范式量身定做的基础设施。
2. 共同的数学骨架:RVQ-VAE
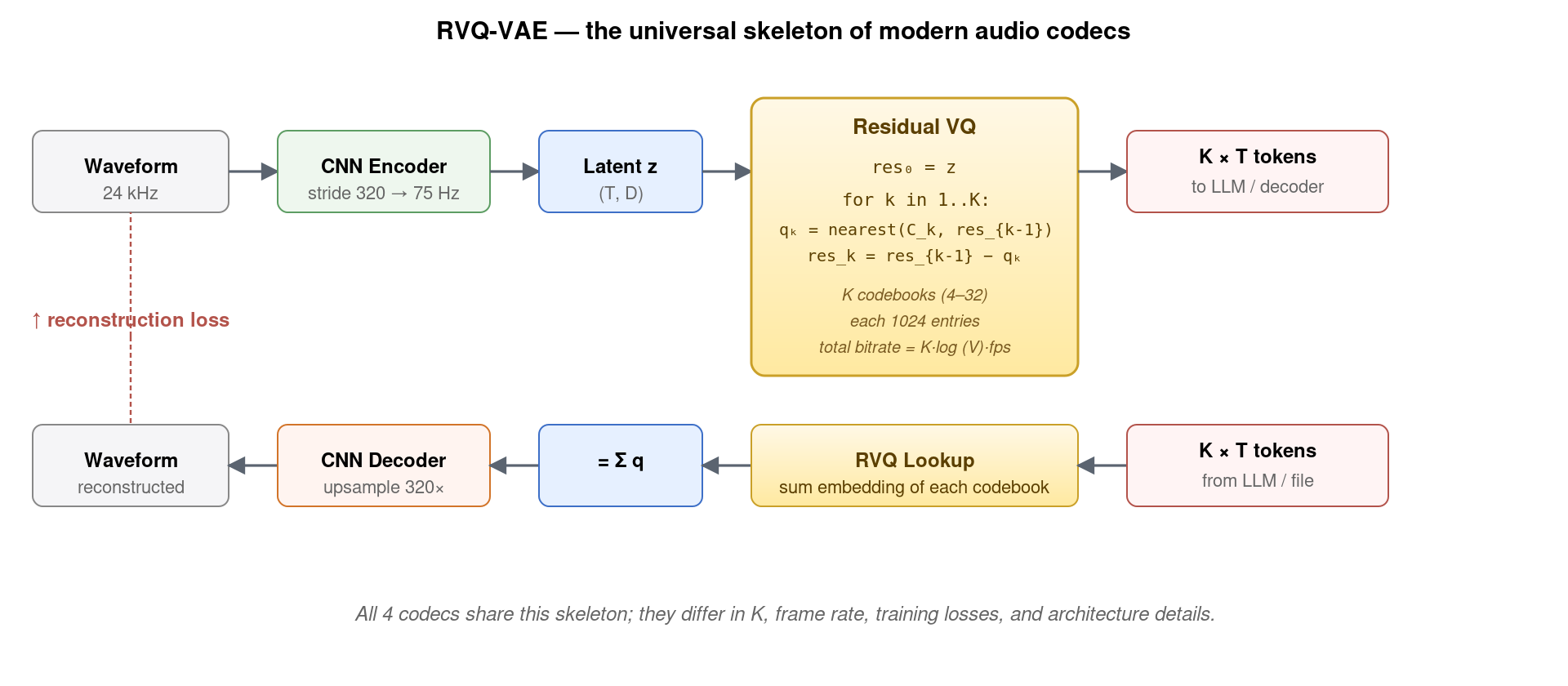
所有四个现代音频 codec 都建立在同一个数学骨架上——RVQ-VAE (Residual Vector Quantized Variational AutoEncoder)。这个名字虽然吓人,但拆开看其实只有三层:
- VAE:自编码器范式——CNN encoder 把波形压缩成低维 latent,CNN decoder 还原。
- Vector Quantization (VQ):把连续 latent 离散化——每帧 latent 向量在一个学到的 codebook 中找最近邻,输出 codebook 中的 entry id。
- Residual:单一 codebook 量化精度不够,所以用多层残差——第 1 层量化原始 latent,第 2 层量化第 1 层的残差,第 3 层量化第 2 层的残差……以此类推。每加一层 codebook 就把误差减半。
关键的训练 loss 是三件套:(1)重建 loss——原波形 vs 重建波形的 L1/L2 + 频谱 loss;(2)VQ commitment loss——鼓励 encoder 输出靠近 codebook entry;(3)对抗 loss (GAN)——用 multi-scale STFT 判别器提升听感真实度。对抗 loss 是 SoundStream 首次引入的”杀手锏”——没有它,CNN decoder 输出的波形听起来”糊”,加上它瞬间逼真。
整个框架的核心可调超参是:
- K(codebook 数量):越多重建越好,但 token 数也越多(每帧产 K 个 token),增加下游 LLM 负担。典型 4–32。
- V(每个 codebook 大小):典型 1024。
- frame rate(帧率,Hz):encoder 的时间下采样比决定。越低 token 越少。典型 12.5–75 Hz。
总比特率 = K × log₂(V) × frame_rate。比如 Encodec 8 codebook × 10 bit × 75 Hz = 6 kbps。四个 codec 的演进就是在 (K, V, frame_rate, 重建质量) 这个四维空间中做不同取舍。
3. SoundStream (Google 2021):开山之作
SoundStream 是 Google Brain 在 2021 年提出的第一个端到端可学的 neural audio codec。它最重要的几个贡献:
- 首次把 RVQ 引入端到端音频压缩。之前 VQ-VAE 类工作(如 Jukebox)都是单 codebook,码本规模动辄数万,训练不稳定。SoundStream 把”多层 1024-entry codebook”这套配方做 work。
- SEANet encoder/decoder 架构——基于扩张卷积的 1D ConvNet,stride 模式 (2, 4, 5, 8) 实现 320× 下采样到 50 Hz。这个架构后来被 Encodec、Mimi 直接继承。
- Multi-scale STFT 判别器对抗训练——分别在多个 STFT 窗长(256/512/1024/2048)上判别真假音频,覆盖不同频率分辨率。这是 SoundStream 在 3 kbps 还能保持高音质的关键。
- Bitrate-flexible inference——一次训练,多档比特率可调。推理时丢掉后几层 codebook 即可降低比特率(也降低重建质量),不需要重训。
SoundStream 配置:8 codebook × 1024 entries × 50 Hz = 4 kbps(默认),可降到 1 kbps。论文实测在 3 kbps 上 MUSHRA 评分超过 Opus 12 kbps——压缩率高 4 倍、质量更好。这是 neural codec 第一次明确证明能在传统 codec 强项(低比特率压缩)上取胜。
4. Encodec (Meta 2022):当代事实标准
Encodec 是 Meta AI 在 2022 年 10 月开源的 codec,本质是 SoundStream 的”工业化加强版”。它没有发明全新概念,但做了一系列工程改进让它成为 2023–2024 年所有 codec-LM TTS 的事实标准:
- 更深的 SEANet 结构——encoder/decoder 都加了 LSTM 中间层,增强时序建模。
- 更丰富的判别器——除了 multi-scale STFT,还加了 multi-period 判别器(借自 HiFi-GAN),覆盖更广频谱范围。
- 支持 24 kHz 与 48 kHz 两档采样率——前者用于语音(VALL-E 用这个),后者用于音乐 (MusicGen 用这个)。
- Language Model 熵编码——可选地用一个小型 Transformer LM 对 token 序列做无损熵编码,进一步降低比特率 25-40%。
- 预训练权重开源 + 代码完整——这是 Encodec 跑赢 SoundStream 的关键工程优势,VALL-E、Bark、MusicGen 都直接调用 Encodec。
Encodec 24 kHz 默认配置:8 codebook × 1024 entries × 75 Hz = 6 kbps。在 LibriSpeech 上的客观指标 PESQ 3.2、ViSQOL 4.4,明显超过 Opus。但它有一个被广泛诟病的致命缺陷:token 序列对下游 LLM 太长——75 Hz × 8 codebook = 每秒 600 个 token。在 10 秒音频上要让 LLM 处理 6000 个 token,自回归解码就要 6000 步——慢得让人无法忍受。这是后续 DAC、Mimi 工作的核心改进动机。
5. DAC (Descript 2023):高保真竞争者
DAC (Descript Audio Codec) 是 Descript 公司在 2023 年发布的 codec,目标是「同比特率下更高质量」。它的改动集中在:
- Snake 激活函数替代 ELU——Snake 是 BigVGAN 引入的周期激活函数
x + sin²(x)/α,对周期信号(语音、音乐)建模更好。 - 9 个 codebook(vs Encodec 8 个)——多一层把残差进一步细化,重建质量提升。
- 更严格的 commitment loss + codebook 学习率——避免 codebook collapse(一个常见 RVQ 问题)。
- 44.1 kHz 全频带——支持音乐级高保真,最高 24 kbps。
DAC 在客观指标上确实是当时最强:44.1 kHz 8 kbps 配置下 ViSQOL 达到 4.74(接近上限 5.0),明显超过 Encodec 48 kHz 同比特率的 4.5。它在 Suno、Bark、Riffusion 等音乐生成项目中是默认 codec。但token 数仍然很多——9 codebook × 88 Hz(44.1 kHz 下) = 每秒 ~800 token,对 LLM 更不友好。
6. Mimi (Kyutai 2024):流式 + 低帧率革命
2024 年 9 月,法国独立 AI 实验室 Kyutai 开源了语音 LLM Moshi,同时发布了为它专门设计的 codec Mimi。Mimi 的设计哲学完全不同于前三代——它不追求”同比特率下更好”,而是追求”更低帧率 + 流式可用”,因为这是支撑 200 ms 端到端语音 LLM 延迟的唯一方式。
Mimi 的关键创新:
- 12.5 Hz 帧率——比 Encodec (75 Hz) 低 6 倍。一段 10 秒音频只需要 125 个时间步,让上层 LLM 的自回归解码可以毫秒级完成。这是 Mimi 区别于所有先前 codec 的最大特征。
- 语义 + 声学两路 codebook——8 个 codebook 中的第 1 个是 WavLM 蒸馏的语义 token(与 ASR/TTS 任务对齐),后 7 个才是普通声学 RVQ。这种”显式分工”让上层 LLM 可以分别处理”内容”和”音色”。
- 完全因果架构——encoder/decoder 都是因果卷积,没有任何未来 padding。这是流式合成的硬性要求——Encodec/DAC 都做不到。
- 知识蒸馏——用 Encodec/WavLM 作为教师模型蒸馏 Mimi,加速收敛。
Mimi 8 codebook × 12.5 Hz = 100 token/秒,是 Encodec 的 1/6。MUSHRA 评分约 4.0(比 Encodec 略低,但接近)。这个”小损失换巨大效率”的取舍是 Moshi 200 ms 端到端延迟的关键。可以说Mimi 不是为压缩设计的,而是为「让 LLM 实时处理音频」设计的——这代表了 2024 年后 codec 设计的根本转向。

这张对比图直观说明了 Mimi 革命性的意义:同样 1 秒音频,Encodec 要 LLM 处理 600 个 token,Mimi 只要 100 个。对于自回归解码的语音 LLM 来说,这是 6 倍的速度提升,且 每多砍掉一倍 token 就让长上下文成本下降一个数量级。这正是为什么 Moshi 团队不得不重新发明一个 codec——Encodec 的 token 数对实时对话来说根本无法接受。
7. 四代 codec 全维度对比
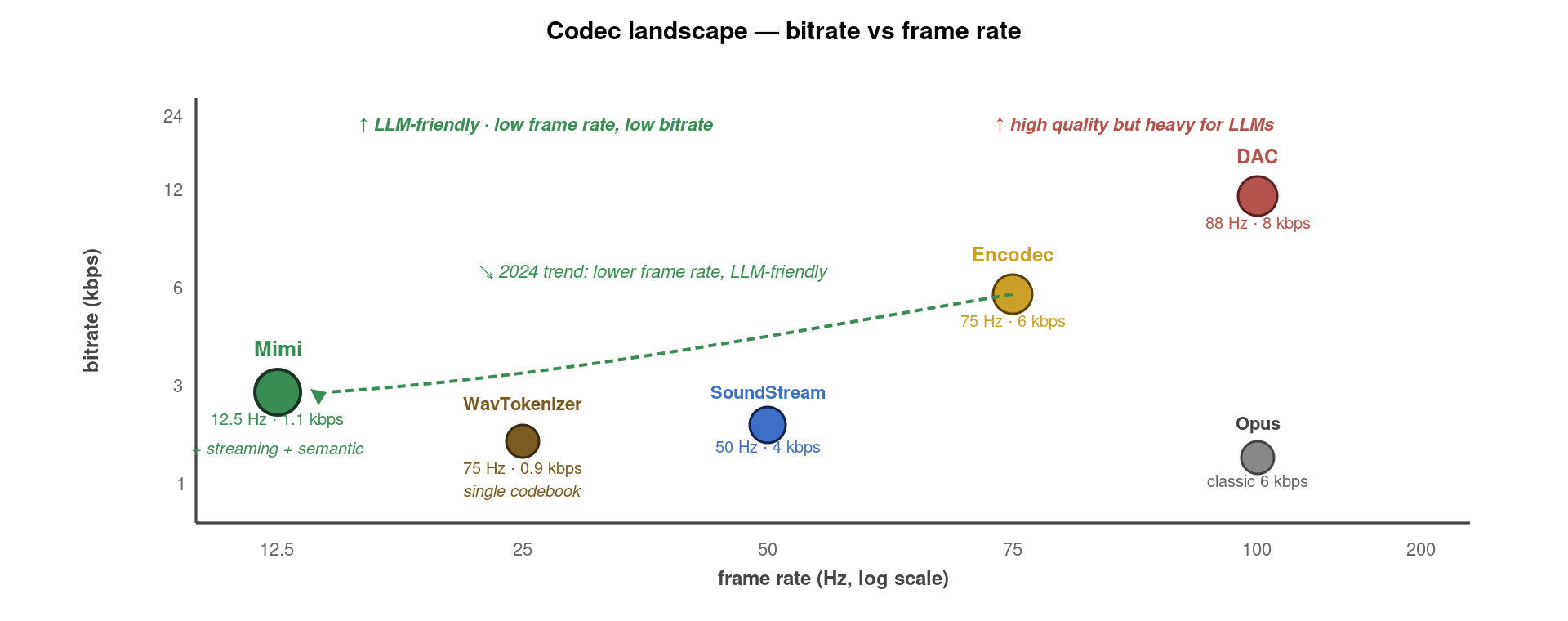
| Codec | 提出方/年份 | Sample Rate | Frame Rate | Codebooks | Bitrate | 核心特色 |
|---|---|---|---|---|---|---|
| SoundStream | Google 2021 | 24 kHz | 50 Hz | 8 | 4 kbps | RVQ + 多尺度 GAN 开山之作 |
| Encodec | Meta 2022 | 24 / 48 kHz | 75 Hz | 8 | 6 kbps | 工业化标准,VALL-E/Bark 底座 |
| DAC | Descript 2023 | 44.1 kHz | 88 Hz | 9 | 8 kbps | Snake 激活 + 9 codebook,最高音质 |
| Mimi | Kyutai 2024 | 24 kHz | 12.5 Hz | 8 (含 1 语义) | 1.1 kbps | 流式 + 极低帧率,Moshi 底座 |
| WavTokenizer | 2024 | 24 kHz | 75 Hz | 1 | 0.9 kbps | 单 codebook 极简,便于 LM |
8. PyTorch 使用:3 行调用 Encodec
Encodec / DAC / Mimi 都有官方权重 + pip 安装。下面演示用 Encodec 把音频编码到 token 再还原:
# pip install encodec
from encodec import EncodecModel
import torchaudio
import torch
# 1) 加载预训练模型(24 kHz 版,约 14 MB)
model = EncodecModel.encodec_model_24khz()
model.set_target_bandwidth(6.0) # 6 kbps = 8 codebook
model.eval()
# 2) 读音频 + 重采样到 24 kHz
wav, sr = torchaudio.load("input.wav")
if sr != 24000:
wav = torchaudio.functional.resample(wav, sr, 24000)
wav = wav.mean(0, keepdim=True).unsqueeze(0) # → (1, 1, T)
# 3) Encode: 波形 → token (K × T_token)
with torch.no_grad():
encoded = model.encode(wav) # list of (codes, scale)
codes = encoded[0][0] # (1, K=8, T_token)
print(f"audio shape: {wav.shape}")
print(f"tokens shape: {codes.shape} (K={codes.shape[1]}, T={codes.shape[2]})")
# 4) Decode: token → 波形 (重建)
with torch.no_grad():
wav_recon = model.decode(encoded) # (1, 1, T)
torchaudio.save("recon.wav", wav_recon.squeeze(0), 24000)
print(f"reconstructed: {wav_recon.shape}")
# 5) 量化看看:token 是整数序列
print("first 8 codes of codebook 0:", codes[0, 0, :8].tolist())
# 输出例如: [423, 88, 512, 901, 17, 256, 700, 42]
这 30 行代码完成了”音频→token→音频”全链路。生成的 codes 张量正是 VALL-E / MusicGen / Bark 等模型的训练输入——它们都是用这些整数序列当作”audio BPE token”做 LLM 训练。Mimi 的调用方式与此几乎相同(moshi.modules.MimiModel + 同样的 encode/decode API),只是模型尺寸更大、token 数更少。
论文数字不可横比:怎么自己做 5 分钟的 codec 验货
上面四代 codec 的对比表有一个我必须提醒的坑:各家论文的主观/客观分数不能直接横比。MUSHRA 和 ViSQOL 的测试集不同(SoundStream 用内部数据、Encodec 混合 DNS/AudioSet、DAC 强调音乐)、bitrate 条件不同、采样率不同(24k vs 44.1k),把它们放进同一张表只能看趋势,不能当排名。
好在 codec 是少数你可以在 5 分钟内自己验货的组件,方法很简单:拿你业务里最有代表性的 3~5 段音频(中文语音就用真实的中文录音,别用英文测试集),encode 再 decode,重点听三处——高频齿音(s/sh 是否发毛)、瞬态(爆破音是否糊)、静音段(是否有底噪伪影),再用 RTF 跑一下你的目标硬件。选型的经验法则我总结为三句:做 TTS / 语音 LLM 优先低帧率语义友好的 Mimi 路线(token 少 = LM 负担小);做通用音频/音乐保真优先 DAC;要生态兼容性和现成 checkpoint,Encodec 仍是默认项。Codec 选错是后患最大的决策之一——它是整条语音管线的”地基”,上层模型训完才发现 codec 上限不够,代价是全部重训。
9. 在 TTS / 语音 LLM 中的应用
| 上层模型 | 使用的 codec | 选择理由 |
|---|---|---|
| VALL-E (Microsoft 2023) | Encodec 24 kHz 6 kbps | 2022 年只有这个开源 codec 足够稳 |
| Bark (Suno 2023) | Encodec | 同上 |
| MusicGen (Meta 2023) | Encodec 32 kHz 6 kbps | 支持音乐高保真 |
| Riffusion (2024) | DAC 44.1 kHz | 音乐质量优先 |
| Moshi (Kyutai 2024) | Mimi 12.5 Hz | 必须低帧率才能 200 ms 端到端延迟 |
| NaturalSpeech 3 (Microsoft 2024) | FACodec (自研) | 显式解耦 content/timbre/prosody |
| CosyVoice 2 (Alibaba 2024) | 监督语义 token + HiFi-GAN | 放弃通用 codec,自研监督式 token |
| F5-TTS (SWivid 2024) | 无 codec, 直生 mel + Vocos | 纯 Flow Matching 无需离散化 |
2024 年的明显趋势:通用 codec(Encodec/DAC)正在被特定上层模型自研 / 改造的方案取代——CosyVoice 用监督语义 token、NaturalSpeech 3 用 FACodec 解耦多属性、Moshi 用 Mimi 低帧率、F5-TTS 干脆绕过 codec。“通用 codec 完美适配所有任务”的愿景没有实现——不同的下游任务对 codec 有不同的最优解。
10. 工程化与未来趋势
- “少 codebook”是未来方向。WavTokenizer 把 codebook 数压到 1,vocab 4096,单 codebook × 75 Hz = 75 token/秒;SingleCodec 进一步把 token rate 压到 25 / 秒。这些”纯单 codebook“codec 训练上层 LLM 时极简单——不需要 NAR Transformer 处理 cross-codebook 依赖,直接一条 token 序列像 NLP 那样训。预计 2025-2026 年单 codebook codec 会成为主流。
- “流式”是硬需求。所有需要 voice agent / 实时合成的场景都必须用因果 codec。Mimi 是第一个完全因果设计的开源 codec,后续会有更多类似设计。
- “语义 + 声学”分离架构。Mimi 的第 1 个 codebook 是 WavLM 蒸馏语义 token,后 7 个是声学 RVQ——这种显式分工被证明对上层 LLM 友好。NaturalSpeech 3 的 FACodec 把分工做得更彻底(content/timbre/prosody/acoustic 四路)。
- 量化部署友好性。Encodec/Mimi 都是 ~50 M 参数,INT8 量化后 CPU 上能毫秒级推理。生产环境部署成本很低,不是瓶颈。
- 多模态统一 tokenizer。OpenAI/Anthropic/Google 都在探索音频+文本+图像的统一 token 化方案——理想是一个 codec 能编码所有模态。2025 年的早期工作(如 Mimi + image VQGAN 联合训练)已经初见端倪。这将彻底改变多模态 LLM 的架构。
- 无损 vs 有损。所有当前 codec 都是有损压缩,重建后听感与原音不同。学术界已有探索无损 neural codec(NeuRiQ、NeLoC),但比特率比 FLAC 高 2-3 倍、尚未实用。
11. 总结
Neural audio codec 在 2021-2024 年完成了一次从”音频压缩工具“到”语音 AI 基础设施“的角色转变。SoundStream 证明端到端 RVQ-VAE 在低比特率上能打败 Opus;Encodec 把这套范式工业化,成为整个 codec-LM TTS 时代的事实标准;DAC 把音质推到上限;Mimi 反向把帧率压到极致以服务流式语音 LLM;WavTokenizer 等单 codebook 路线则把”易被 LLM 建模”做到极致。四代演进恰好对应了上层应用需求的演变——从”压缩”到”重建”到”建模”到”实时交互”。
对从业者而言,当下选 codec 的决策树大致这样:纯音质优先选 DAC;VALL-E 风格 TTS选 Encodec;实时语音 LLM选 Mimi;简单上层 LLM 训练选 WavTokenizer;纯流式 ASR / TTS 不需要离散 token则完全跳过 codec(如 F5-TTS)。没有一个 codec 能 cover 所有场景,但每个场景都有了优秀的开源选项。这就是 今天语音 AI 工程的现实。
把这篇放到我之前的 Whisper、SSL 三部曲、TTS 演进史、VALL-E、CosyVoice 2、F5-TTS 系列里看,你应该能完整理解 2020 年以来端到端语音 AI 的整张技术地图。codec 是这张地图的底座——所有上层模型都直接或间接依赖它。
参考资料
- Zeghidour, N. et al. SoundStream: An End-to-End Neural Audio Codec. arXiv:2107.03312, IEEE/ACM TASLP 2021.
- Défossez, A. et al. High Fidelity Neural Audio Compression (Encodec). arXiv:2210.13438, 2022.
- Kumar, R. et al. High-Fidelity Audio Compression with Improved RVQGAN (DAC). arXiv:2306.06546, NeurIPS 2023.
- Défossez, A. et al. Moshi: a speech-text foundation model for real-time dialogue. arXiv:2410.00037, 2024.(Mimi 出处)
- Ji, S. et al. WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling. arXiv:2408.16532, 2024.
- Ju, Z. et al. NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models. arXiv:2403.03100, 2024.(FACodec 出处)
- van den Oord, A. et al. Neural Discrete Representation Learning (VQ-VAE). NeurIPS 2017.(RVQ 的祖师爷)
- Encodec 官方仓库:github.com/facebookresearch/encodec
- DAC 官方仓库:github.com/descriptinc/descript-audio-codec
- Mimi 官方仓库:github.com/kyutai-labs/moshi(含 Mimi 实现)
![]()
2026-01-17 at 5:28 下午
第 11 节那个决策树太实用了——纯音质 DAC、VALL-E 风格 Encodec、实时 LLM Mimi、简单上层训练 WavTokenizer、不要离散 token 就 F5