
转载本文请注明出处:https://yudonglee.me/deepseek-prover-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 3 月,后随系列连载持续修订,最近一次更新于 2026 年 6 月。
本文是 DeepSeek 论文专题系列的第 7 篇,详解 DeepSeek 公司在 2024 年发表的 DeepSeek-Prover V1 与 V1.5 系列论文:(1) DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data (arXiv:2405.14333, 2024-05);(2) DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search (arXiv:2408.08152, 2024-08)。这两篇 paper 把 LLM 与 Lean 4 形式化证明结合,提出两个核心方法:(a) 大规模合成数据 pipeline——通过 autoformalization 把自然语言竞赛题翻译成 Lean 4 形式陈述,配合 Lean 验证生成 800 万级形式定理-证明对;(b) RLPAF + RMaxTS——用 Lean 证明助手提供的 binary reward 做 RL 训练,再用一种叫 RMaxTS 的蒙特卡洛树搜索变种解决稀疏 reward 的探索问题。Prover V1.5 7B 在 miniF2F-test 上取得 63.5% 的 pass rate,是 2024 年开源形式化定理证明的 SOTA。更重要的是,Prover 这条主线为半年后的 R1(长链推理 + RL)提供了关键方法论启示——把”答案可自动验证”的设定一般化到通用 reasoning。
一、为什么 DeepSeek 要做形式化数学
W1 序言里我们把 DeepSeek 论文分为四条主线,其中推理(Reasoning)主线有两条平行分支:

两条线在 reasoning 上各自代表一种范式:
- 自然语言 CoT (Chain-of-Thought):模型用自然语言写出推理步骤,最后给出答案。优点是灵活、可读、迁移性强;缺点是中间步骤无法被外部 verifier 验证,reward 只能用 outcome(答案对错)
- 形式化证明 (Formal Theorem Proving):模型用 Lean / Coq 等形式语言写证明,每个证明步骤都可以被 proof assistant 严格验证。优点是每个中间步骤都有 ground truth,理论上可以做 process-level supervision;缺点是形式语言学习曲线陡峭,数据稀缺
DeepSeek 同时在两条线上下注的原因是:
- 形式化证明是 reasoning 训练的”干净实验台”:proof assistant 提供严格、廉价、可大规模并行的 verifier。这个设定是 RL training 的理想环境——比依赖人类标注或 reward model 干净得多
- 形式化方法论可以反哺自然语言推理:在 Prover 上验证有效的 search / RL / 数据合成方法,可以迁移到通用 reasoning。R1 的 cold-start + 多阶段 RL 思路与 Prover V1.5 的训练范式有明显方法论亲缘关系
- 战略卡位 AI for Math 赛道:IMO / Olympiad 级数学题、4 大数学猜想形式化、Liquid Tensor Experiment 这些项目是 AI 顶级研究热点,DeepSeek 早早布局这条线对学术品牌建设有意义
具体地看,Prover V1 / V1.5 相对同期形式化定理证明工作(GPT-f、ReProver、Llemma-Lean、AlphaProof)贡献了什么?三点:
- autoformalization 驱动的大规模合成数据 pipeline:把 8M 个高中-本科竞赛题翻译成 Lean 4 形式陈述,再用模型自身生成证明、Lean 验证、迭代精炼,得到工业级训练语料
- RLPAF (Reinforcement Learning from Proof Assistant Feedback):把 Lean 的”证明通过 / 失败”作为 binary reward,配合 GRPO 训练。这是把”环境天然提供 reward”这一理念在 reasoning 训练中的标准实现
- RMaxTS:一种为稀疏 reward 设计的蒙特卡洛树搜索变种,通过 RMax-style intrinsic reward 鼓励探索多样化的证明路径
下面分阶段展开。
二、前置:Lean 4 / mathlib / miniF2F 工具栈
要理解 Prover 系列,需要先了解形式化数学社区使用的标准工具。
2.1 Lean 4 与 mathlib
Lean 4 是当前主流的形式化定理证明语言(其前身 Lean 3 在 2022 年被 Lean 4 取代)。它的核心特性:
- 依赖类型 (dependent type):每个数学对象都有精确的类型签名,类型本身可以包含值
- tactic 模式:除了直接写证明项,还支持像”先用归纳法再用反证”这样的策略式证明,更接近人类思维
- 元编程:Lean 4 把语言本身的语法树暴露给用户,可以定义自己的 tactic
mathlib 是 Lean 社区维护的标准数学库,目前包含 200,000+ 已形式化的定理和 100,000+ 定义,覆盖从基础代数到现代代数几何的大量数学。mathlib 是 Prover 系列训练数据的核心来源。
一个 Lean 4 定理证明的例子(自然数加法交换律):
这段代码:
theorem add_comm声明定理名(a b : Nat)是输入参数(两个自然数): a + b = b + a是命题(要证明的结论)by ...后面是 tactic 证明,用归纳法
每一步 tactic 都会被 Lean 4 严格验证。模型生成的证明,要么 Lean 接受(reward = 1),要么报错(reward = 0),没有中间状态。
2.2 miniF2F 与 ProofNet 评测基准
形式化定理证明社区有几个标准 benchmark:
| Benchmark | 来源 | 题目难度 | 题量 |
|---|---|---|---|
| miniF2F | 高中竞赛 (AMC, AIME, IMO) | 高中 | 488 |
| ProofNet | 本科教材习题 | 本科 | 371 |
| FIMO | IMO 形式化 | 本科到 IMO | 148 |
| PutnamBench | Putnam 竞赛 | 本科到研究生 | 660 |
miniF2F 是最常用的 benchmark,分 valid 与 test 两个 split,包含从基础代数到 IMO 难度的题目。Prover 系列主要在 miniF2F 上报告成绩。
2.3 形式化证明的核心挑战
LLM 做形式化定理证明远比做自然语言数学难:
- 语法严格:一个 token 错就整个证明 fail,没有”大概意思对”
- 搜索空间巨大:每一步 tactic 的可选项数十到数百个,证明可能需要几十步
- 稀疏 reward:只有完整证明通过才有 +1 reward,中间步骤无信号
- 数据稀缺:人工形式化的数学定理总量约 mathlib 的 30 万条,远小于自然语言数学语料
Prover 系列就是要在这三个约束下找到工程突破。
工具栈背后的隐形门槛:为什么复现 Prover 的人远少于复现 R1 的
把上面的工具栈读完,你可能觉得 Lean 4 不过是「另一门 DSL」。我认为这严重低估了这条线的工程门槛,也正好解释一个现象:R1 发布后社区复现遍地开花,Prover 这条线的复现者却始终寥寥。三个原因:
- 学习曲线是一整个学科:依赖类型系统、mathlib 的命名与证明惯例、tactic 的语义,对没有交互式定理证明背景的 ML 工程师来说是全新领域;Lean 3 到 Lean 4 的不兼容迁移还让大量旧教程失效。一个能独立调通 GRPO 的工程师,未必读得懂一条 mathlib 的类型报错。
- 验证基础设施是另一套工程:R1 的 reward 本质是字符串比对,Prover 的 reward 是完整编译一次 Lean——每个证明候选都要在带 mathlib 环境的沙箱里跑,大规模 RL 意味着维护一个 CPU 编译农场,这和 GPU 训练栈是两条独立的工程线。
- autoformalization 有语义陷阱:类型检查只能保证陈述「合法」,不能保证它与原题等价——前提自相矛盾的陈述可以被平凡证明却毫无意义,这类 faithfulness 问题在 autoformalization 文献里被反复讨论。审计合成数据需要既懂数学又懂 Lean 的人,这种复合人才比 GPU 还稀缺。
我的判断是:这条线真正的护城河不在算法——RLPAF 和 RMaxTS 都不难懂——而在「ML + 形式化验证」的交叉工程能力。这也是评估任何宣称要复现 Prover 的团队时,最值得先问的一项。
三、Prover V1:合成数据驱动(2024-05)
3.1 核心创新:autoformalization 合成数据 pipeline
Prover V1 的核心思路是用模型自己生成训练数据。完整流程:
Step 1: 收集自然语言竞赛题
从 AOPS、高中数学竞赛、本科教材中收集自然语言的数学竞赛题(陈述 + 答案)。
Step 2: Autoformalize 到 Lean 4 陈述
用 DeepSeekMath 7B 做 autoformalization——把自然语言陈述翻译成 Lean 4 的 theorem 声明。例如:
- 自然语言:“证明对任意正整数 n,n² + n 是偶数”
- Lean 4:
theorem even_n_squared_plus_n (n : Nat) (h : n > 0) : Even (n^2 + n)
这一步是 noisy 的——LLM 输出的 Lean 陈述可能有语法错误、类型不匹配、或与原题不等价。所以需要:
Step 3: 过滤无效陈述
用 Lean 4 的类型检查器扫描所有 autoformalized 陈述,去掉编译失败的。剩下的就是”语法上有效”的 Lean 4 命题。
Step 4: 模型生成证明
对每个有效陈述,让 DeepSeekMath 7B 用 tactic 模式生成证明候选(每题采样 N 个候选)。
Step 5: Lean 验证 + 保留通过的
每个证明候选都送进 Lean 4 编译器验证。只有完整通过验证的证明才被保留。这就是 binary reward 的天然来源。
Step 6: 把通过的 (陈述, 证明) 对加入训练集
不断迭代——每一轮训练完用新模型再做一轮合成,反复 bootstrap。
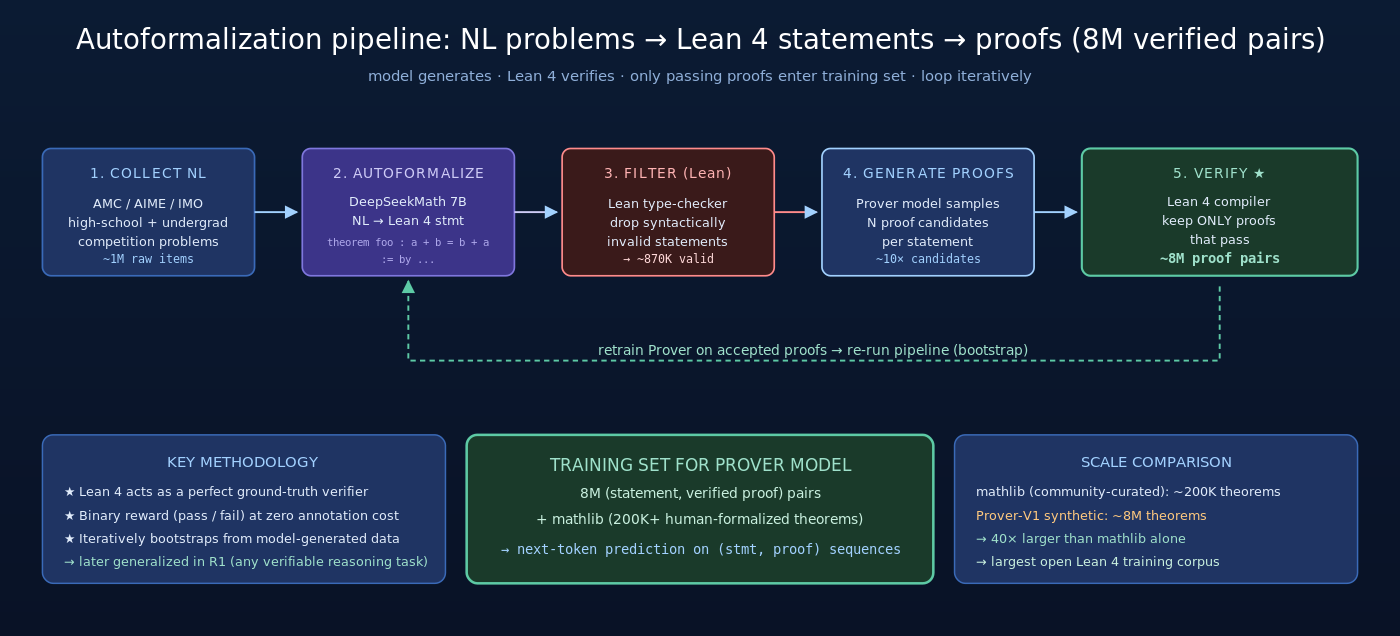
3.2 数据规模与训练
V1 论文报告的最终数据规模:
- autoformalize 输入:高中-本科级竞赛题
- 过滤后有效陈述:约 870K
- 生成 + 验证通过的证明:约 8M (8 million) formal statement-proof pairs
这是 2024 年最大规模的开源 Lean 4 训练语料。
训练上:
- 基模型:DeepSeekMath-Base 7B(注意是 Math 不是 LLM!因为数学预训练已经强化了符号推理能力)
- 训练数据:合成的 8M 对 + mathlib 已有定理
- 训练目标:标准 next-token prediction,”陈述 → 证明” 格式
3.3 Prover V1 评测结果
V1 在 miniF2F-test 上的表现:
| 模型 | miniF2F-test (1 sample) | miniF2F-test (64 samples) | FIMO (148 题) |
|---|---|---|---|
| GPT-4 (2024-05) | 14.8% | 23.0% | 0/148 |
| ReProver (Llemma 7B) | 25.6% | 33.2% | – |
| Hypertree-Proof-Search | – | 41.0% | – |
| DeepSeek-Prover V1 | 30.0% | 46.3% | 5/148 |
| + cumulative | – | 52.0% | – |
关键观察:
- 64 采样下 V1 (46.3%) 大幅超过 GPT-4 (23.0%)——一个 7B 开源模型 2× 于 GPT-4 这种 trillion-param 闭源模型,证明在垂直领域足够多的合成数据可以填补模型规模的差距
- FIMO 上 V1 证明了 5 道 IMO 题(GPT-4 一道都没有证出来)——这是开源模型第一次在 IMO 难度上有非零成绩
- Cumulative pass rate 52%——多 sample 之后接近一半 miniF2F 题目可证
3.4 V1 的局限
V1 验证了”合成数据 + Lean 验证”路线的可行性,但仍有几个明显问题:
- 训练只用通过的证明,浪费了”失败信号”:被 Lean 拒绝的证明候选其实可以作为 RL 的负样本,V1 没有利用
- 采样过程是无搜索的并行采样:每题独立采样 N 次,等于做 64 次”瞎猜”。没有利用证明步骤的中间状态来引导搜索
- 缺乏对错误证明的 RL 修正:单纯 SFT 不能让模型从 Lean 的反馈中学到东西
这三个问题正是 V1.5 要解决的。
四、Prover V1.5:RLPAF + RMaxTS(2024-08)
V1.5 在 V1 基础上做了两个关键升级:
4.1 RLPAF(Reinforcement Learning from Proof Assistant Feedback)
V1.5 把 Lean 4 验证器直接当成 reward function:
- 模型生成证明 → Lean 4 编译 → 通过 → reward = 1
- 编译失败 / 超时 / 类型错误 → reward = 0
然后用 GRPO(W5 详解过的算法)做 policy update。GRPO 的优势在这里特别合适:
- 每个 prompt(题目)采样 G 个证明候选——天然适合 Lean 的并行验证
- 组内归一化 advantage 让 sparse binary reward 不会让训练崩溃(避免 PPO 在稀疏 reward 下的方差爆炸问题)
- 不需要 value model——节省显存让 7B prover 可以训练长上下文证明
从 V1 到 V1.5 的方法论跃迁:V1 用 Lean 验证过滤数据(pre-training-time supervision),V1.5 把 Lean 验证当成在线 reward signal(RL-time supervision)。前者只能利用已合成的固定数据集,后者可以无限地从模型自己的探索中产生新的训练信号。这个范式转变与 R1 的 RL training 完全同源。
4.2 RMaxTS:为稀疏 reward 设计的 MCTS
但仅仅 RLPAF 还不够。形式化证明有一个独特的难点——reward 极度稀疏:
- 一个 50 步的证明,前 49 步都可能”看起来对”,但最后一步类型不匹配,整个证明 fail
- 模型采样 64 次都失败的概率很高,导致 GRPO 训练时整组 advantage 全是 0,无信号可学
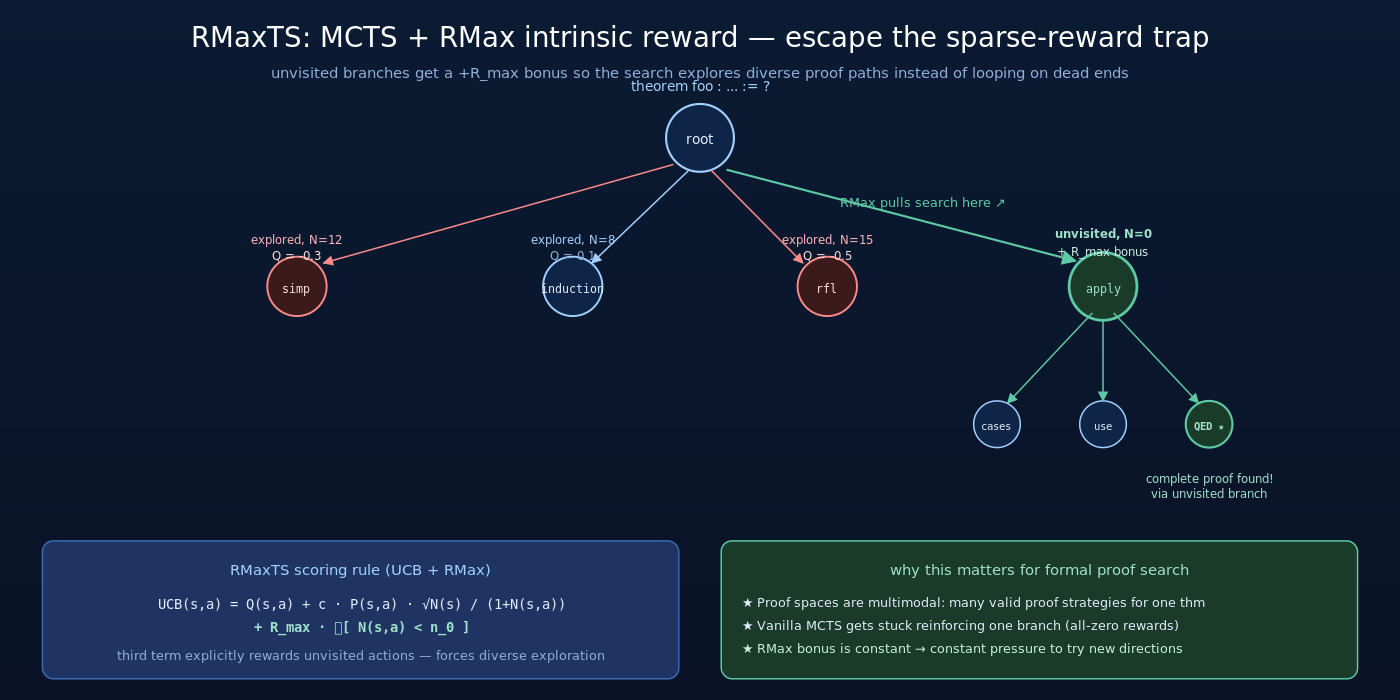
V1.5 的解法是树搜索 + intrinsic reward——具体地,引入 RMaxTS (RMax-style Monte-Carlo Tree Search)。
RMaxTS 的核心思路:
- 把证明搜索建模成 MCTS:每个节点是一个 partial proof state,每条边是一个 tactic 选择。模型用作 policy(选择 tactic)+ value(估计这个 state 能否走到完整证明)
- 传统 MCTS 在稀疏 reward 下退化:因为大多数 rollout 失败,几乎所有节点的 value 都是 0,UCB 退化成纯随机
- RMax-style intrinsic reward:借鉴 RMax 算法的思想,给”未充分探索的 state”加一个固定的 intrinsic reward
 。这样没探索过的分支天然有吸引力,鼓励模型尝试多样化的证明路径
。这样没探索过的分支天然有吸引力,鼓励模型尝试多样化的证明路径
具体地,每个 state 的 UCB 评分:
![\text{UCB}(s, a) = Q(s, a) + c \cdot P(s, a) \cdot \frac{\sqrt{N(s)}}{1 + N(s, a)} + R_{\max} \cdot \mathbb{1}[N(s, a) < n_0]](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-67152897131f32f80f20cbde055f6d23_l3.png "Rendered by QuickLaTeX.com")
- 第一项:标准 Q 值
- 第二项:UCB exploration term(policy prior)
- 第三项:RMax intrinsic reward——访问次数
 (即没探索过)的 action 额外加分
(即没探索过)的 action 额外加分
这相当于”明确鼓励探索新分支”,弥补了稀疏 reward 下 UCB 自然 exploration 不足的问题。
4.3 V1.5 的评测结果
V1.5 在 miniF2F-test 上的表现(与 V1 对比):
| 模型 | miniF2F-test | ProofNet | 备注 |
|---|---|---|---|
| DeepSeek-Prover V1 | 50.0% | 16.0% | SFT only |
| DeepSeek-Prover V1.5-Base | 50.0% | 17.7% | DeepSeekMath-Base 重训 |
| DeepSeek-Prover V1.5-SFT | 53.3% | 21.0% | SFT 升级 |
| DeepSeek-Prover V1.5-RL | 56.5% | 22.6% | + RLPAF |
| DeepSeek-Prover V1.5-RL + RMaxTS | 63.5% | 25.3% | + 树搜索 |
关键观察:
- SFT 升级带来 +3.3% 提升(V1 → V1.5-SFT)
- RLPAF 再贡献 +3.2%(V1.5-SFT → V1.5-RL)
- RMaxTS 再贡献 +7.0%(V1.5-RL → V1.5-RL + RMaxTS)——树搜索是最大单点贡献
V1.5-RL + RMaxTS 的 63.5% miniF2F-test 在 2024-08 是开源 SOTA,首次让 7B 模型在形式化证明上超过了 GPT-4 多倍 sampling 的水平。
4.4 RMaxTS 为什么有效
RMaxTS 的有效性回到一个根本观察:形式化证明的搜索空间是高度多模态的。同一个定理可以有多种证明思路(直接证、反证、归纳、构造),每种思路下又有多种具体 tactic 序列。
传统 MCTS 容易 overconfident 在一条路径上反复 rollout,浪费 sample budget。RMax intrinsic reward 强行打破这种 overconfidence——让搜索器有动力同时探索几条平行思路。
这种”显式鼓励多样化”的 RL 设计后来在 R1 的”温度采样 + 多样化 reward”中也有体现,是 DeepSeek 团队从 Prover 工作中沉淀的一条方法论。
五、Prover V2 简略前瞻(2025-04)
Prover V1.5 之后,DeepSeek 在 2025 年 4 月发布了 DeepSeek-Prover-V2(arXiv:2504.21801)。这是一个更大的跳跃:
| 维度 | Prover V1.5 | Prover V2 |
|---|---|---|
| 模型规模 | 7B | 671B(基于 DeepSeek-V3) |
| 核心方法 | RLPAF + RMaxTS | Subgoal Decomposition + Cold-Start + RL |
| miniF2F-test | 63.5% | 88.9% |
| Putnam | – | 49/660 |
V2 的核心创新是 Subgoal Decomposition——用 LLM 把一个大定理分解成若干 subgoal,每个 subgoal 单独证明,最后拼接成完整证明。这是从 V1.5 的”端到端生成完整证明”升级到”分治式证明”——本质是把人类数学家做证明的层次结构内化到 LLM 推理流程里。
V2 在 miniF2F-test 上的 88.9% 已经接近”人类高水平大学生”的水平,是开源 reasoning 模型在形式化数学上的一个里程碑。V2 的详细解读不在本文范围(会在后续单独成文或归入 R1 系列展开)。
六、Prover 主线对 R1 / 通用 reasoning 的方法论启示
Prover 工作本身只解决了形式化数学这一个垂直领域,但它奠定的方法论却辐射到了整个 DeepSeek reasoning 主线。三个关键启示:
启示一:环境天然 reward 是 RL 训练的最佳起点
Prover 用 Lean 4 作为”完美 verifier”,提供 binary、廉价、可大规模并行的 reward signal。这个 setup 比”用 reward model 模拟人类偏好”干净 100 倍。
R1 把这个观察一般化——所有有客观答案的任务(数学题、代码、逻辑题)都可以提供 environment-level reward,不需要 reward model。R1 的 cold-start 阶段使用的就是这类”答案可验证”的 reasoning 任务。
启示二:稀疏 reward 下树搜索 + 多样化探索
Prover V1.5 的 RMaxTS 解决了”稀疏 reward + 多模态搜索空间”的探索问题。这个问题在 reasoning 任务里普遍存在——不只是形式证明,CoT、code generation、agent planning 都有类似结构。
R1 没有直接用 MCTS(因为推理路径不像 proof 那么离散化),但 R1 的 multi-stage RL + 多样化温度采样可以看作是 RMaxTS 思想的 informal 应用——在 sample 多样性与 exploitation 之间显式 trade-off。
启示三:合成数据 bootstrap 是 reasoning 训练的关键瓶颈
V1 的 autoformalization + 8M 合成证明对,开创了”模型生成、environment 验证、迭代加入训练集”的循环。这个 loop 后来在 R1 的 reasoning data 合成、V3 的 code/math 数据生成、甚至 V4 的 long-CoT 数据准备中都被复用。
R1 论文里专门有一节讨论”如何构造高质量 reasoning trace 训练数据”,本质上就是 Prover V1 这套 pipeline 的一般化——只是 Lean 4 验证器被替换成了”答案 ground truth”或”unit test”。
总的来说:Prover 是 DeepSeek reasoning 主线上的”先锋实验场”——在 Lean 这种干净环境下先把 RL + search + 合成数据三件套跑通,然后把成功的方法论迁移到 R1 这种更复杂的通用 reasoning 任务里。
写在最后
DeepSeek-Prover V1 / V1.5 是 DeepSeek 系列里最”学术”的一篇 paper——研究对象是 AI for Math 这种相对冷门但学术声誉极高的方向,与商业模型的实际应用距离最远。
但它做对的三件事——合成数据 pipeline、environment reward、树搜索多样化探索——都是后续 R1 这种”商业 reasoning 旗舰”的方法论支柱。可以说没有 Prover 这条线的先行实验,R1 的训练设计会缺少很多关键的工程信心。
这种”在垂直、干净的研究场景里先把方法论跑通,再迁移到通用任务”的研究节奏,是 DeepSeek 团队一种独特的工作方式。Math (W5) 是同样思路在”答案可验证的自然语言推理”上的应用,Prover 是同样思路在”完全形式化的证明搜索”上的应用。两者并行推进,最终在 R1 上汇合。
下一篇 W9 我们详解 ESFT (Expert-Specialized Fine-Tuning)(arXiv:2407.01906),这是 DeepSeek 在 MoE 模型 fine-tuning 方法上的一项独特探索——观察到 MoE 模型在下游任务上只有少数 expert 被频繁激活,于是设计一种只更新”任务相关 expert”的稀疏 fine-tuning 方法,把 MoE 模型的 task adaptation 成本降低 60%+。这是 V2 之后 DeepSeek 围绕 MoE 工程化的几篇配套论文之一,与 W3 的 DeepSeekMoE、W10 的 Aux-Loss-Free 共同构成 DeepSeek MoE 工程方法论的三件套。
参考资料
- Xin et al., DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data, arXiv:2405.14333, 2024.
- Xin et al., DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search, arXiv:2408.08152, 2024.
- Ren et al., DeepSeek-Prover-V2: Advancing Formal Mathematical Reasoning via Reinforcement Learning for Subgoal Decomposition, arXiv:2504.21801, 2025.
- DeepSeek-Prover GitHub:
- Moura & Ullrich, The Lean 4 Theorem Prover and Programming Language, Conference on Automated Deduction, 2021.
- The mathlib Community, The Lean Mathematical Library, CPP 2020.
- Zheng et al., miniF2F: a cross-system benchmark for formal Olympiad-level mathematics, ICLR 2022.
- Polu & Sutskever, Generative Language Modeling for Automated Theorem Proving (GPT-f), arXiv:2009.03393, 2020.
- Brafman & Tennenholtz, R-MAX – A General Polynomial Time Algorithm for Near-Optimal Reinforcement Learning, JMLR, 2002.
![]()
2026-03-29 at 9:36 上午
V1 的 8M 合成证明对里,”陈述”来自竞赛题 autoformalize、”证明”来自模型生成 + Lean 验证。那这 8M 证明的难度分布是怎样的?