
转载本文请注明出处:https://yudonglee.me/deepseek-llm-explained/ | 作者:yudonglee
📝 本文首发于 2026 年 1 月,后随系列连载持续修订,最近一次更新于 2026 年 6 月。
本文是 DeepSeek 论文专题系列的第 1 篇,详解 DeepSeek 公司 2024 年 1 月发表的开山之作 DeepSeek LLM: Scaling Open-Source Language Models with Longtermism (arXiv:2401.02954)。这篇论文本身的架构创新有限——它沿用了 LLaMA 的 pre-norm Transformer 设计——但其真正价值在于:(1) 是 DeepSeek 公司”长期主义”工程哲学的第一份公开声明;(2) 在 Kaplan (2020) 与 Chinchilla (2022) 已有的 Scaling Law 方法论之上,给出了一组针对中英双语 + 代码混合语料的完整、可复现的 IsoFLOP 拟合公式;(3) 明确指出数据质量会显著改变最优的模型/数据 scaling 分配——这一观察是后续 V2、V3、V4 工程取舍的理论起点。
一、为什么从 DeepSeek LLM 看起
读 DeepSeek 这两年半的论文有两种方式:直接从 V3 或 R1 这种代表性工作开始,或者从 LLM 这篇开山之作沿时间线读到 V4。后者更费时,但有一个无法替代的好处——你会看到 DeepSeek 团队逐步建立工程哲学的过程。
具体到 LLM 这篇:
- MLA、GRPO、Auxiliary-Loss-Free、FP8 等后续的核心创新这篇都没有
- DeepSeekMoE 的 fine-grained / shared expert 设计 也是同一团队在 6 天之后的另一篇论文里提出的
- 这篇 LLM 在架构上的选择几乎与 LLaMA-2 相同:pre-norm Transformer、RMSNorm、SwiGLU、RoPE
那为什么这篇论文仍然重要?两个独立的理由:
第一,论文的 Section 5(Scaling Laws)是过去三年里少数公开、完整、可复现的 IsoFLOP 拟合工作之一。Kaplan et al. (2020) 与 Chinchilla (Hoffmann et al., 2022) 已经奠定了模型/数据缩放的方法论框架,但都没有针对中文 + 代码混合语料给出实证;DeepSeek LLM 把这套方法在双语语料上重做了一次,并在过程中给出一个超出 Chinchilla 讨论范围的观察——数据质量会改变最优分配。这个观察直接影响了后续 V2/V3 的数据流水线设计。
第二,论文 Section 1 的”长期主义”宣言(Longtermism)是中国大模型公司公开材料里少有的、清晰阐述研究取舍的开篇。它不仅说明了 DeepSeek 自己想做什么,也间接解释了为什么 2024 整年这家公司能保持每月一篇论文、每篇都做到工程深度的产出节奏。
下面我们沿着论文章节顺序逐项展开。
二、长期主义宣言:DeepSeek 团队的自我定位
论文开篇引用了一段有些理想主义色彩的表述:DeepSeek 团队声明他们的目标不是赶上某个产品节奏,而是把开源大模型”做到 GPT 级别”作为长期目标,同时承诺把整个研究链路(数据流水线、训练框架、Scaling Law 实证、模型权重)开源。
这段在当时(2024 年 1 月)显得不太合时宜——彼时国内大模型行业的主流叙事是”快速产品化 + 接 API 套壳”,而 DeepSeek 选择把资源投入到”做一个真正能在 paper 维度上对标 LLaMA-2 的基础模型”上。回头看,这个取舍解释了 V2 / V3 / R1 / V4 为什么能持续在工程深度上领先——这是连续两年累积的复利结果。
从论文写作的角度看,这一段也是 DeepSeek 团队对外界给出的”研究路线图”:
- Scaling Law 优先:先把 scaling 规律拟合清楚,再据此训练模型,而不是反过来用经验值试错
- 数据质量优先:明确把数据流水线作为模型质量的核心驱动力之一
- Alignment 不是事后补丁:SFT + DPO 与 base 训练同等重要,且都要在论文中给出细节
后续 16 篇论文几乎都遵循了这三条。
三、模型架构:LLaMA 标准件 + 67B 引入 GQA
3.1 前置:LLaMA-2 与 Transformer 标准件
在看 DeepSeek LLM 的架构选择之前,需要先理解 LLaMA-2 的”标准件”是什么。LLaMA-2 (Touvron et al., 2023) 是 2023 年 7 月 Meta 发布的开源 LLM 系列,是后续大多数开源 LLM(包括 DeepSeek LLM、Yi、Qwen、Baichuan、Mistral 等)的架构参考。它确定的几个核心组件目前已经成为业界事实标准。
(1) Pre-norm Transformer 结构
传统 Transformer (Vaswani et al., 2017) 使用 post-norm,即 normalization 在 residual 加法之后:
LLaMA 系列改为 pre-norm,把 normalization 移到 residual 加法之前:
Pre-norm 的关键好处是训练更稳定:post-norm 的深层 Transformer (>40 层) 容易出现梯度消失或 loss spike,而 pre-norm 的梯度可以直接通过 residual 通路反向传播,无需经过 norm。这是当前几乎所有 30+ 层 LLM 的统一选择。
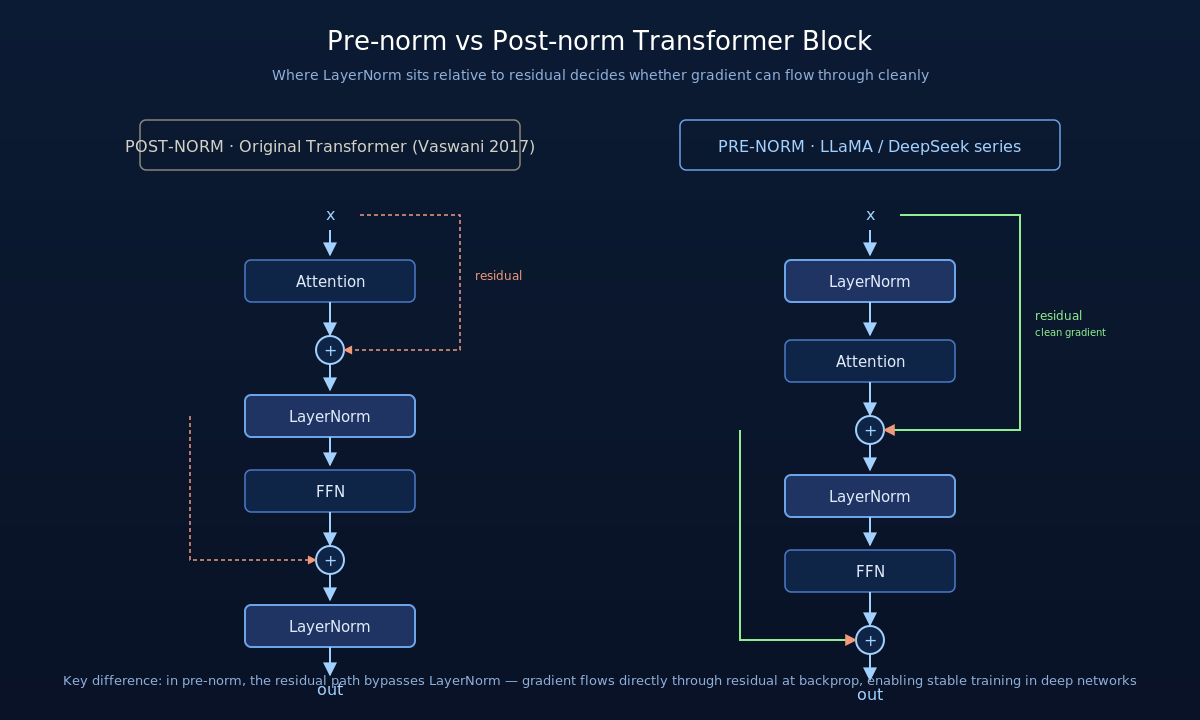
图 1:Pre-norm 与 Post-norm 的关键差异——pre-norm 把 LayerNorm 移到了 residual 加法之前,让 residual 通路完全绕过 norm;反向传播时梯度可以沿 residual 直通,深层(>40 层)训练更稳定。LLaMA / DeepSeek 系列全部采用 pre-norm。
(2) RMSNorm 替代 LayerNorm
LayerNorm 同时做均值中心化和方差归一化:

RMSNorm (Zhang & Sennrich, 2019) 只做方差归一化、不做均值中心化、并去掉偏置  :
:

效果几乎与 LayerNorm 相当,但计算量减少约 10%(少一次均值统计)、参数减半(去掉 )。LLaMA / LLaMA-2 / DeepSeek 系列全用 RMSNorm。
(3) SwiGLU 激活替代 ReLU / GeLU
传统 Transformer 的 FFN 用 ReLU 或 GeLU 激活:

SwiGLU (Shazeer, 2020) 引入门控机制,把激活分成两路相乘:

其中 SiLU(x) = x · sigmoid(x),⊙ 是逐元素乘法。SwiGLU 的门控让 FFN 能学习更细粒度的特征激活模式。代价是参数量增加约 33%(多出一个 V 矩阵),因此 LLaMA 系列把 FFN intermediate 设为 hidden 的 2.67×(而非 ReLU 时代的 4×),保持总参数量基本不变。
(4) RoPE 位置编码
RoPE (Rotary Position Embedding, Su et al., 2021) 把位置信息编码成旋转矩阵,作用到 Q 和 K 上:

其中  是位置
是位置  对应的二维旋转矩阵(每对维度旋转不同角度)。RoPE 的精妙之处在于:attention score
对应的二维旋转矩阵(每对维度旋转不同角度)。RoPE 的精妙之处在于:attention score  只依赖相对位置差
只依赖相对位置差  ,因此天然具备相对位置编码的属性,同时又是绝对位置的函数,可以无需重新训练就外推到比训练长度更长的上下文(配合 NTK / YaRN 等扩展技术)。LLaMA / LLaMA-2 / DeepSeek 全用 RoPE,且 DeepSeek-V2 之后用 YaRN 把它扩展到 128K。
,因此天然具备相对位置编码的属性,同时又是绝对位置的函数,可以无需重新训练就外推到比训练长度更长的上下文(配合 NTK / YaRN 等扩展技术)。LLaMA / LLaMA-2 / DeepSeek 全用 RoPE,且 DeepSeek-V2 之后用 YaRN 把它扩展到 128K。
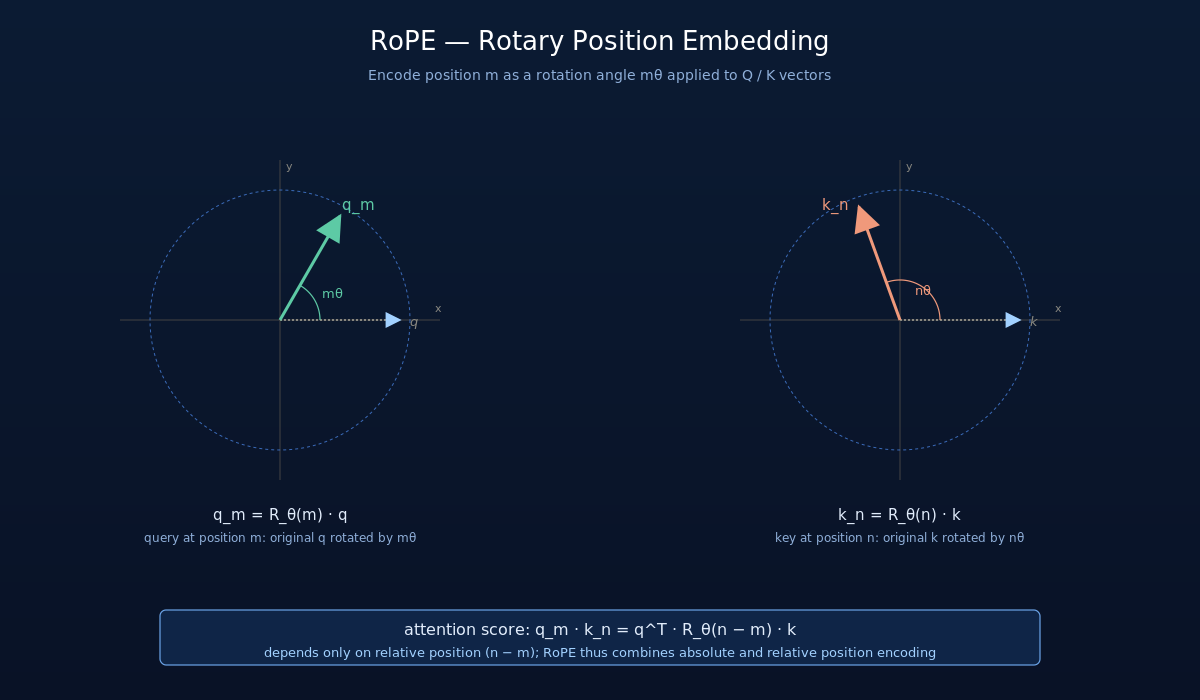
图 2:RoPE 把位置 m 编码成旋转角 mθ,分别作用在 query 和 key 上。q_m 和 k_n 内积展开后只剩 R_θ(n−m),即注意力分数只依赖相对位置差。这种性质让 RoPE 同时具备绝对位置(每个位置唯一旋转)与相对位置(注意力只看差值)两种编码的优点。
(5) GQA:Grouped-Query Attention(70B 引入)
标准 MHA(Multi-Head Attention)每个 query head 都有自己独立的 KV head(query : KV = 1 : 1),KV cache 显存随 head 数线性增长。MQA(Multi-Query Attention)走另一个极端,所有 query head 共享同一对 KV head,KV cache 压到 1/n,但质量会损失。
GQA (Ainslie et al., 2023) 是两者的折中:把 query head 分成若干组,每组共享一对 KV head。LLaMA-2 70B 用 64 个 query head + 8 个 KV head(8:1 grouping),KV cache 显存压到 1/8 而质量几乎不降。LLaMA-2 7B 和 13B 由于规模小、KV cache 显存压力不大,仍用标准 MHA。
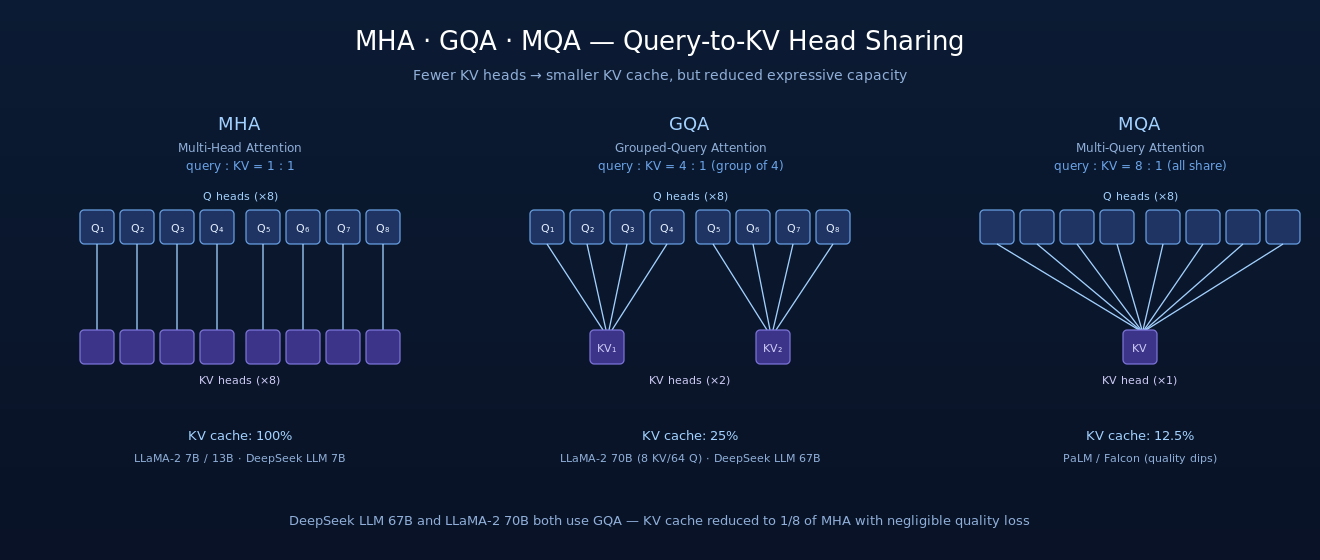
图 3:MHA / GQA / MQA 三种 attention 的 query-to-KV head 分组方式。从左到右共享程度递增,KV cache 体积递减:MHA 1:1(100%)、GQA 4:1(25%)、MQA 8:1(12.5%)。DeepSeek LLM 67B 与 LLaMA-2 70B 都采用 8:1 grouping 的 GQA,在显存与质量之间取平衡。
(6) Tokenizer
LLaMA-2 用 SentencePiece BPE 词表 32,000,主要针对英文优化——中文字符在词表中只有约 700 个,导致中文文本 token 效率非常低(一段中文文本可能比同样英文翻译多用 2–3 倍 tokens)。这是后续中文 LLM 几乎都重新设计 tokenizer 的根本原因。
LLaMA-2 标准件清单:
| 组件 | LLaMA-2 选择 | 替代了什么 |
|---|---|---|
| Block 结构 | Pre-norm | 替代传统 post-norm |
| Normalization | RMSNorm | 替代 LayerNorm |
| FFN 激活 | SwiGLU | 替代 ReLU / GeLU |
| 位置编码 | RoPE | 替代 absolute / 学习式位置编码 |
| Attention | MHA(7B/13B)/ GQA(70B) | MQA 与 MHA 之间的折中 |
| Tokenizer | SentencePiece BPE 32K | — |
LLaMA-2 的训练规模:
– 三个尺寸:7B / 13B / 70B
– 训练 tokens:2T(与 DeepSeek LLM 完全相同)
– Context length:4K
– 训练语料:以英文为主,少量代码与多语言
LLaMA-2 没有解决的:
– 多语言(特别是中文)支持有限
– 数学与代码能力相对薄弱(与同期专门优化的模型相比)
– Scaling Law 拟合公式没有公开
– 训练 hyperparameter 的选型理由没有公开
理解了这套”LLaMA-2 标准件”之后,DeepSeek LLM 的架构选择就一目了然——它完整沿用了 LLaMA-2 的全部六项标准件,只在三个维度上做差异化:
- Tokenizer:换成 102,400 词表的 byte-level BPE(vs LLaMA-2 的 32K SentencePiece),对中文 token 效率提升约 40%
- GQA 引入门槛降低:67B 就开始用 GQA(vs LLaMA-2 是 70B 才用),7B 仍保留 MHA
- 训练语料:英文与中文大致各占 50%(vs LLaMA-2 以英文为主),代码占比相对较小
3.2 DeepSeek LLM 的架构表
具体到 DeepSeek LLM 的架构配置:
| 维度 | DeepSeek LLM 7B | DeepSeek LLM 67B |
|---|---|---|
| 层数 | 30 | 95 |
| Hidden dim | 4096 | 8192 |
| FFN intermediate | 11008 | 22016 |
| Attention heads | 32 | 64 |
| Per-head dim | 128 | 128 |
| KV heads (GQA) | 32(即 MHA) | 8(GQA) |
| Vocab size | 102,400 | 102,400 |
| Context length | 4096 | 4096 |
| 位置编码 | RoPE | RoPE |
| FFN 激活 | SwiGLU | SwiGLU |
| Norm | RMSNorm(pre-norm) | RMSNorm(pre-norm) |
| 词表类型 | byte-level BPE | byte-level BPE |
| 总参数 | 7B | 67B |
3.3 三个值得注意的差异化决策
1. 67B 引入 GQA,提前了一个尺寸
LLaMA-2 是从 70B 才开始用 GQA(7B / 13B 都是 MHA),DeepSeek LLM 在 67B 这个相对接近的尺寸已经引入。具体配置是 64 个 query head + 8 个 KV head(grouping ratio 8:1,与 LLaMA-2 70B 一致),把 KV cache 显存降至完整 MHA 的 1/8。这个决定看似细节,实际上反映了 DeepSeek 团队对”长上下文推理显存压力”的早期重视——注意力机制的 KV cache 问题是 DeepSeek 从开山之作开始就持续投入的方向,一直贯穿到 V2 提出 MLA、V3 改进 MLA、V4 进一步引入 mHC / DualPath 等结构。
2. 词表 102,400 与 byte-level BPE
LLaMA-2 用 32K 词表的 SentencePiece BPE,主要为英文优化;DeepSeek LLM 把词表扩到 102,400,并切换到 byte-level BPE。两个改动叠加后,中文 token 效率比 LLaMA-2 提升约 40%——同样一段中文,DeepSeek tokenizer 的 token 数大约是 LLaMA tokenizer 的 60%。这个 102,400 词表底座 V2 / V3 / V4 一直沿用(V3 微调到 129,280,但 byte-level BPE 的底层不变),保证了模型间的词表兼容性,便于后续做权重蒸馏与知识迁移。
3. Context length 4096
这是 2024 年 1 月的标准长度,没有走 100K+ 长上下文路线。后续 V2 用 YaRN 扩展到 128K、V3 进一步稳定化长上下文训练、V4 推到百万 token——所有这些都建立在 LLM 这篇打下的 4K 训练基线上。长上下文不是 LLM 这一代的目标,DeepSeek 没有为了 PR 把它强行做到 100K。
四、训练数据:2T tokens 中英双语流水线
论文 Section 3 描述了数据流水线,包含三层处理:
第一层:去重(Deduplication)
跨整个 Common Crawl 历史快照做全局去重,而不是单个快照内去重。论文中明确指出:单快照去重去掉的重复样本约 19.8%,而跨快照(截至 91 个 dump)的全局去重能去掉 89.8% 的样本。这个数字告诉我们:互联网爬取数据的真实”信息量”远低于其字节数,而 Common Crawl 的多版本快照之间高度重复——如果不做跨快照去重,模型实际上会反复看到几乎相同的内容。
第二层:过滤(Filtering)
DeepSeek 用启发式规则 + 语言模型评分双管齐下:启发式规则过滤明显低质量内容(如重复 token、HTML 残留、广告页面),语言模型评分则保留困惑度合理的样本。值得注意的是,DeepSeek 没有像一些工作那样依赖单一的”质量分类器”,而是用多源信号叠加——这个工程取舍在 V2 之后被进一步细化。
第三层:重混(Remixing)
不同语料源(网页、书籍、代码、论文)按一组配比混合,并在训练过程中动态调整。论文给出的最终配比中,英文与中文大致各占 50%,代码与其他类型语料占比相对较小。这个配比是经过多轮小规模实验确定的,而不是凭经验固定。
最终训练集 2T tokens,其中 7B 模型训练用了全部 2T,67B 模型也是同样的 2T。这与 LLaMA-2 70B 的 2T 训练量是一致的——DeepSeek 没有刻意在数据量上”卷”过 LLaMA-2,而是把火力集中在数据质量 + Scaling Law 拟合上。
五、IsoFLOP 拟合实验:本文的核心贡献之一
如果只能从 DeepSeek LLM 这篇论文里挑一节读,应该是第 5 节 Scaling Laws。Scaling Law 本身是由 Kaplan et al. (2020) 与 Chinchilla (Hoffmann et al., 2022) 等先前工作奠定的研究范式,DeepSeek LLM 在这一框架内完成了一组针对中英双语语料的 IsoFLOP 拟合实验,并得出”数据质量影响最优分配”这一额外观察——这是整个 DeepSeek 系列后续数据流水线设计的方法论起点。
5.1 IsoFLOP profile 方法
Chinchilla 论文给出了三种拟合 scaling law 的方法,其中 IsoFLOP profile 是计算预算最高效的一种:固定一系列 compute budget  (FLOPs),对每个 训练多组不同 (N, D) 配比的小模型(N 是参数量,D 是 tokens 数,满足
(FLOPs),对每个 训练多组不同 (N, D) 配比的小模型(N 是参数量,D 是 tokens 数,满足  ),找出在该 budget 下 loss 最低的 (N, D) 配比,最后把这些”最优点”用幂律拟合。
),找出在该 budget 下 loss 最低的 (N, D) 配比,最后把这些”最优点”用幂律拟合。
DeepSeek LLM 也用了 IsoFLOP profile,但做了两个改进:
改进 1:把”模型规模 N”替换为”非 embedding FLOPs per token M”作为缩放变量。理由是 N 既包含 embedding 也包含 transformer 主体,而 embedding 参数对模型质量影响较小、却会显著影响 N 的数值。改用 M 后,拟合的稳定性和外推准确性都更好。
改进 2:把 batch size 和 learning rate 同时纳入缩放规律拟合,给出”任意 C 下最优 hyperparameter”的预测公式。这避免了对每个尺寸都做 hyperparameter sweep 的成本。
5.2 最优分配公式
论文给出的核心公式(见 Section 5)是:

其中  ,
, ;
; ,
, 。注意
。注意  (实际是 0.9999…),这是
(实际是 0.9999…),这是  约束下的必然结果。
约束下的必然结果。
这两个指数的物理含义是:给定一个 compute budget,应该把 52.4% 的资源”花在模型规模上”,47.6% 花在数据规模上。这与 Chinchilla 论文的 1:1 配比略有差异,主要原因是 DeepSeek 的训练语料质量分布不同(详见 5.4)。
5.3 Hyperparameter 的 power-law 缩放
论文同时给出了 batch size 和 learning rate 的最优缩放:

也就是说,compute budget 翻倍,最优 batch size 增加约 25%,最优 lr 下降约 8%。这两个数字看起来不大,但对训练稳定性至关重要——按这个公式选 hyperparameter,DeepSeek LLM 7B 和 67B 都能在第一次尝试就训练稳定(论文报告全程无 loss spike,无需 rollback)。
这是 DeepSeek 工程哲学的关键体现:不靠”调参经验”,而靠”预测公式”。后续 V2 / V3 都沿用了这种 hyperparameter scaling 思路。
5.4 数据质量对最优分配的影响(最重要的发现)
论文 Section 5.4 给出了一个超出 Chinchilla 框架的观察:
用同样的方法在不同质量的数据上拟合 scaling law,会得到不同的最优指数 a 和 b。具体来说,数据质量越高,最优分配越倾向于”更大模型 + 更少 tokens”。
直觉理解:当数据噪声大时,模型从每个 token 学到的信息量低,需要”看更多 token”来抵消噪声;当数据高质量时,每个 token 都有信息,相对地”模型规模”的边际收益更高。
这个观察对工程实践的指导意义是巨大的:数据流水线的投入(去重、过滤、质量分类)不是单纯的”成本节约”,而是会直接改变最优 model-size / data-size 配比。后续 V2 论文中把数据流水线作为重点优化方向,根源就在这里。
对这组拟合结果的两点方法论保留
作为本文核心贡献,这组 scaling law 实验值得认真对待,但我对它的外推有效性保留两点疑问。其一,拟合区间与使用区间相差多个数量级:IsoFLOP 实验的算力档位上限远低于 67B 模型的真实训练算力,scaling law 的幂律形式在外推两三个数量级后是否保持,本质上是假设而非实证——Chinchilla 与 DeepSeek 给出不同的最优配比,部分原因恰恰是两者的拟合区间、数据质量定义和学习率 schedule 口径不同,而不是谁”算错了”。其二,compute-optimal 不等于 deployment-optimal:这套公式回答的是”给定训练算力怎么分配参数和数据”,但工业界真正的约束往往是推理成本——LLaMA 路线”小模型 + 远超 compute-optimal 的数据量”在部署侧反而更经济。后来 DeepSeek 自己的 V2/V3 也没有严格沿着这条公式走,而是转向了 MoE 这个”参数和激活解耦”的方案,某种意义上绕开了 dense scaling law 的整个框架。
这不是否定这项工作——恰恰相反,”数据质量影响最优配比”这个发现比公式本身更重要,它解释了为什么各家的 scaling law 数字永远对不上:配比公式不可移植,但”先把数据质量做上去再谈 scaling”这个结论是可移植的。
六、训练超参与稳定性
具体的训练 hyperparameter(按 5.3 的公式预测得到的”最优值”):
| 模型 | Global batch size | Learning rate | 总训练 tokens |
|---|---|---|---|
| DeepSeek LLM 7B | 2304 | 4.2 × 10⁻⁴ | 2.0T |
| DeepSeek LLM 67B | 4608 | 3.2 × 10⁻⁴ | 2.0T |
Multi-step LR schedule 而非 Cosine
论文一个值得讨论的选择是 multi-step learning rate schedule,而不是当时主流的 cosine schedule:
- 前 2,000 步线性 warmup 到最大 lr
- 训练到 1.6T tokens 时(约总训练量的 80%),lr 阶跃下降到最大值的 31.6%
- 训练到 1.8T tokens 时(约 90%),再阶跃下降到最大值的 10%
为什么用 multi-step 而不用 cosine?论文给出的理由是:
- 续训友好:cosine schedule 一旦设定了总训练 steps,中途增加数据时需要重新调整曲线;multi-step 只需要把阶跃点向后推。
- 可复现性更好:multi-step 的两个阶跃点是离散的整数,不像 cosine 那样依赖浮点曲线计算。
- 实证 loss 曲线接近:论文在小规模 ablation 中验证了,最终 loss 与 cosine 基本相当。
这个选择在后续 V2 / V3 / V4 的训练中都得到了延续——这也是 DeepSeek 工程实用主义的体现:当两种方案效果相当时,选择对长期续训更友好的那个。
七、SFT + DPO 对齐流程
DeepSeek LLM 的对齐流程相对简单——SFT 之后直接接 DPO,没有走 RLHF 的 PPO 路线。
SFT 数据:约 2B tokens 指令数据,覆盖以下类别(论文中给出的明细比例):
– 数学与代码(约 30%)
– 通用对话(约 25%)
– 角色扮演 / 创意写作(约 15%)
– 安全相关(约 10%)
– 其他专业领域(约 20%)
SFT 训练:2 epochs,学习率 1e-5(67B)/ 1.5e-5(7B),与 base 模型训练学习率(3.2e-4 和 4.2e-4)相比下降一个数量级。
DPO 而非 PPO:DPO 直接从人类偏好对比数据 (chosen, rejected) 中学习,不需要训练独立的 reward model,工程上比 PPO 简单约 50% 的代码量。论文报告 DPO 后的 67B Chat 在 MT-Bench 上达到了与 GPT-3.5 相当的水平。
值得注意的是,DeepSeek 在这篇论文里选择 DPO 而非 PPO,但后续 R1 论文转向了 GRPO(Group Relative Policy Optimization),这是一种 PPO 的简化变体。这个变化反映了团队在 reasoning 任务上对 RL 算法的重新评估——DPO 在通用对话上够用,但在 reasoning 训练上 GRPO 更有效。这条算法演进线索是 W5(DeepSeekMath / GRPO 详解)的核心内容。
八、Benchmark 评测:超过 LLaMA-2 70B
论文 Section 4 与 6 给出了详细的评测结果。挑几个有代表性的指标:
| Benchmark | DeepSeek LLM 67B Base | LLaMA-2 70B | 备注 |
|---|---|---|---|
| MMLU (5-shot) | 71.3 | 68.9 | 通用知识 |
| BBH (3-shot) | 68.7 | 66.6 | 推理 |
| GSM8K (8-shot) | 63.4 | 56.5 | 小学数学 |
| MATH (4-shot) | 18.7 | 13.7 | 数学竞赛 |
| HumanEval (0-shot) | 42.7 | 30.5 | 代码 |
| MBPP (3-shot) | 57.4 | 49.6 | 代码 |
| TriviaQA (5-shot) | 78.9 | 85.0 | 英文 trivia |
| C-Eval | 66.1 | 51.7 | 中文知识 |
| CMMLU | 70.8 | 53.6 | 中文知识 |
几个观察:
- DeepSeek LLM 67B 在 9/9 中文知识任务上显著领先——这是预期的,毕竟训练语料中文占比 50%
- 在英文 trivia 类任务(TriviaQA、NaturalQuestions)上略输 LLaMA-2 70B——LLaMA-2 训练语料中英文占比更高,且包含更多英文百科类内容
- 数学和代码任务全面超越——这是 SFT 阶段数学/代码数据高占比的直接收益
Held-out 评测:LeetCode 与匈牙利高考
论文 Section 6.5 用了两个论文发表后才出现的 benchmark 作为 held-out 测试:
- LeetCode Weekly Contest 2023 年 7 月之后的周赛题
- 匈牙利国家高中数学考试 2023 年新发布的题目
这两个数据集的关键特点是:训练数据截止日期是 2023 年 5 月之前,因此论文模型无法看过这些题目——是真正的零数据泄露评测。DeepSeek LLM 67B Chat 在这两个测试上的表现:
- LeetCode:解出 27.2% 的题(同期 GPT-3.5 约 18%)
- 匈牙利高考:56 分 / 117 分(同期 GPT-3.5 约 41 分)
这个评测设计反映了 DeepSeek 团队对”benchmark 污染”问题的清醒认识——公开 benchmark 数据进入预训练语料几乎是行业普遍现象,唯一稳健的评测方式是使用模型训练截止日期之后才出现的题目。后续 V3 / R1 论文都延续了这个 held-out 评测的传统。
九、安全评估
论文 Section 7 用 100+ 个安全测试类别评估模型,涵盖:歧视、隐私、违法内容、心理诱导、敏感政治话题等。DeepSeek LLM 67B Chat 在内部综合安全分上得 97.8 分,论文报告这个数字略高于同期 ChatGPT 与 GPT-4 在相同测试集上的得分。
需要说明的是,这是 DeepSeek 团队自己的测试集,与 OpenAI 的 evaluator 没有完全可比性。但论文给出了详细的拆分类别和样本,第三方可以复现——这也是 DeepSeek 一贯的”开源到细节”作风。
十、DeepSeek LLM 对后续工作的影响
虽然 DeepSeek LLM 本身的架构创新有限,但它为整个 DeepSeek 系列奠定了几个不可忽视的基础:
- IsoFLOP 拟合公式(5.2 节)—— 后续 V2 / V3 / V4 都用这套 hyperparameter scaling 公式预测最优配置
- 数据质量影响最优分配(5.4 节)—— 直接驱动了 V2 论文中数据流水线的进一步优化
- Multi-step LR schedule(6 节)—— 沿用到 V2 / V3 / V4
- 102,400 词表 + byte-level BPE(3 节)—— 词表底座一直未变
- Held-out 评测传统(6.5 节)—— V3 / R1 论文都遵循
- DPO 后训练流程(7 节)—— R1 转向 GRPO 之前的标准做法
- GQA 在大尺寸引入(3 节)—— 后续 V2 进一步演化为 MLA
理解这些”基础选择”是理解后续 16 篇论文的前置——也是为什么我把这个系列从 LLM 开始而不是从 V3 开始的原因。
写在最后
DeepSeek LLM 不是一篇创新性极高的论文。它的架构选择保守,对齐流程标准,benchmark 性能虽然超过 LLaMA-2 70B 但差距并不悬殊。然而,它的真正价值在于完整、可复现、开放——团队公开了 Scaling Law 的拟合公式、数据流水线的处理细节、训练 hyperparameter 的具体数值,以及多个评测的细分得分。
这种”工程透明度”在 2024 年 1 月的开源大模型论文里是稀缺的,也是 DeepSeek 后续能持续在工程深度上领先的根源——每一篇论文都把”细节”作为对外承诺的一部分公开,迫使团队内部对每个选择都有清晰的依据。
11 天之后,同一团队发表了 DeepSeekMoE,提出 Fine-grained Expert Segmentation + Shared Expert Isolation 的 MoE 设计——这是 V2 / V3 / V4 都依赖的核心架构。下一篇我们详解这篇 paper。
参考资料
- DeepSeek-AI, DeepSeek LLM: Scaling Open-Source Language Models with Longtermism, arXiv:2401.02954, 2024.
- DeepSeek-LLM GitHub repository:
- Kaplan et al., Scaling Laws for Neural Language Models, arXiv:2001.08361, 2020.
- Hoffmann et al., Training Compute-Optimal Large Language Models (Chinchilla), arXiv:2203.15556, 2022.
- Touvron et al., Llama 2: Open Foundation and Fine-Tuned Chat Models, arXiv:2307.09288, 2023.
- Vaswani et al., Attention Is All You Need (Transformer), arXiv:1706.03762, 2017.
- Zhang & Sennrich, Root Mean Square Layer Normalization (RMSNorm), arXiv:1910.07467, 2019.
- Shazeer, GLU Variants Improve Transformer (SwiGLU), arXiv:2002.05202, 2020.
- Su et al., RoFormer: Enhanced Transformer with Rotary Position Embedding (RoPE), arXiv:2104.09864, 2021.
- Ainslie et al., GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, arXiv:2305.13245, 2023.
- Rafailov et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO), arXiv:2305.18290, 2023.
![]()
2026-02-17 at 5:45 下午
为什么 DPO 在 reasoning 上不行?是因为 DPO 只学”偏好对比”、缺乏 reasoning 需要的”过程奖励/多步采样”吗?