转载本文请注明出处:https://yudonglee.me/qwen-roadmap/ | 作者:yudonglee
本文是 Qwen 论文专题系列的序章。我把通义实验室(Tongyi Lab,阿里云,2026 年初已重组为 Alibaba Token Hub 旗下专门负责 Qwen 模型研发的单元)从 2023 年 8 月到 2026 年 5 月发表的全部 Qwen 主线 + 专项分支 paper 按”六代主线 + 6 大分支”梳理成一个完整脉络。读完这一篇,你应该可以——把 Qwen-1 / 1.5 / 2 / 2.5 / 3 / 3.5、Qwen-VL / Audio / Coder / Math、QwQ、Qwen-Omni / 3.5-Omni 这些名字之间的关系全部理清;说出 Dual Chunk Attention (DCA)、M-RoPE / TMRoPE、Built-in Thinking Mode、Thinker-Talker、Hybrid Linear Attention (Gated DeltaNet) 这些 Qwen 独有技术分别诞生在哪一篇论文、解决了什么问题;理解为什么 Qwen 与 DeepSeek 看起来都是”中国开源大模型旗舰”,但在工程哲学、模型矩阵、商业路径上是两条完全不同的路线。
一、引言:中国开源双旗舰格局与 Qwen 的独特位置
如果说过去三年中国 AI 圈最值得长期关注的两家公司,那答案几乎是确定的:DeepSeek 与 Qwen(通义实验室)。前者在 DeepSeek 系列专题 里我已经做了 18 篇深度解读;本系列对应地把 Qwen 完整梳理一遍。
先把基本数据摆出来:
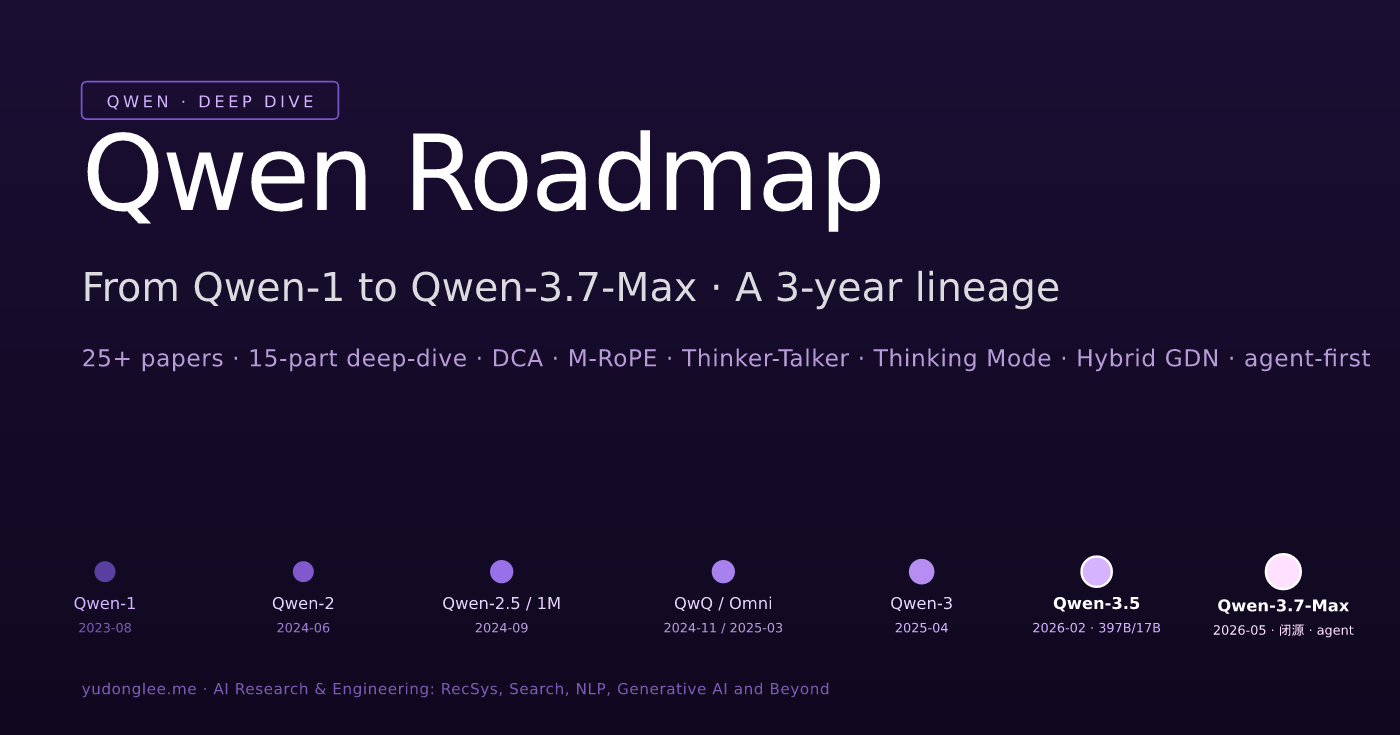
- 论文产出:2023-08 到 2026-05,25+ 篇主论文 + 数十篇 supporting paper,覆盖通用 LLM / 多模态 / 代码 / 数学 / 音频 / 推理 / agentic 完整光谱
- 模型规模:从 0.5B 端侧模型起步,到 Qwen-3 的 235B-A22B MoE、Qwen-3.5 的 397B-A17B Hybrid MoE,再到 2026-05-20 发布的 Qwen-3.7-Max agent-first 旗舰——近三年内 size 矩阵覆盖完整
- 训练数据:Qwen-1 用 3T tokens,到 Qwen-3 已是 36T tokens——12 倍扩展
- 架构演进:从标准 MHA → GQA 全 size 化 (Qwen-2) → DCA 1M ctx (Qwen-2.5) → Built-in Thinking (Qwen-3) → Hybrid Linear Attention with Gated DeltaNet (Qwen-3.5) → agent-first native extended-thinking (Qwen-3.7-Max)——每一代主线都有架构层面的实质创新
- 开源深度:到 Qwen-3 / 3.5 主线模型权重 + 训练数据配比 + 详细技术报告 + tokenizer + 微调框架(LLaMA-Factory / SwiftFinetuning)+ 推理引擎全部开源,Apache 2.0 协议(比 LLaMA 的 community license 更宽松)。2026-04 起的 Qwen3.5-Omni、Qwen3.6-Plus、以及 2026-05 Qwen-3.7-Max 都走 API-only 闭源路线,打破了 Qwen 系列长期 open-source-first 的节奏
- 行业地位:HuggingFace 上长期占据”开源模型下载量”前列;Open LLM Leaderboard 上 Qwen2.5-72B / Qwen3-235B / Qwen3.5-Plus 多次冲到第一;Qwen-3.7-Max 在 SWE-Pro / Terminal-Bench 2.0 / GPQA Diamond 三个 agentic 评测上同时压过 DeepSeek-V4-Pro 与 Claude Opus 4.6——这是中国开源 / 准开源大模型第一次在 agentic 评测上同时领先两家顶级 frontier 模型
Qwen 真正值得关注的不是”又开源了一个大模型”,而是它代表的与 DeepSeek 完全不同的工程路径:
- DeepSeek 路径:少数旗舰、研究院风格、单点架构创新(MLA / GRPO / FP8)、frontier model 对标 GPT-4 / o1
- Qwen 路径:全 size 矩阵(0.5B → 397B 九档以上)、产品化优先、多模态全家桶(VL + Audio + Omni 同步发布)、ToB 商业化(阿里云 API)+ 开源生态双线推进;2026 年起 frontier 多模态 / Plus 转向闭源
两条路径都是中国开源 LLM 历史上的关键产物。理解 Qwen 不能只看 Qwen-3 旗舰,必须沿着时间线把整棵树看完——这是本专题系列的目的。
二、通义实验室与 Qwen 的公司画像
在进入技术之前,简单交代下 Qwen 这条线的组织背景。
- 隶属:阿里巴巴 → 阿里云 → 通义实验室(Tongyi Lab)。2026 年初组织重构:新设 Alibaba Token Hub 业务单元,通义实验室专注 Qwen 模型研发
- 首席科学家:周靖人(阿里云 CTO、原 ACM / IEEE Fellow)
- 首发时间:2023 年 8 月(Qwen-1 7B/14B 发布)
- 总部:杭州 + 北京
- 算力底座:阿里云自有 GPU 集群(A100 + H100 + 国产芯片实验集群)
- 商业模式双线:
- 开源线(2023-2026 主流):HuggingFace / ModelScope 发布,Apache 2.0
- 商业线:阿里云”通义千问”API(DashScope / Model Studio / 百炼)、企业定制版(Qwen-Max / Plus)、行业垂直版
- 2026-04 后的闭源转向:Qwen3.5-Omni、Qwen3.6-Plus、Qwen-3.7-Max 不再发布开源权重,仅通过 chatbot 网站、阿里云 DashScope(2026-05 发布的 Qwen-3.7-Max 定价 $2.50/$7.50 per 1M input/output tokens)访问——这是 Qwen 主线第一次破坏 open-source-first 默认值
- 长期主义宣言(多次 Qwen 技术报告强调):做”GPT 级”的开源全栈大模型,让中小企业可以用得起 frontier 级模型
这个画像很重要——它解释了为什么 Qwen 会同时维护 0.5B 端侧模型与 235B 旗舰,为什么 Qwen-VL / Qwen-Audio 从 Day 1 就和主线同步发布。Qwen 不是”科研项目”,是”产品级开源全家桶”——这是它与 DeepSeek 在战略上最大的差异。
三、Qwen 六代主线 + 6 大专项分支的技术路线图
把 Qwen 全部论文按主题分类,可以看到六代主线 + 6 大独立专项分支的完整结构。
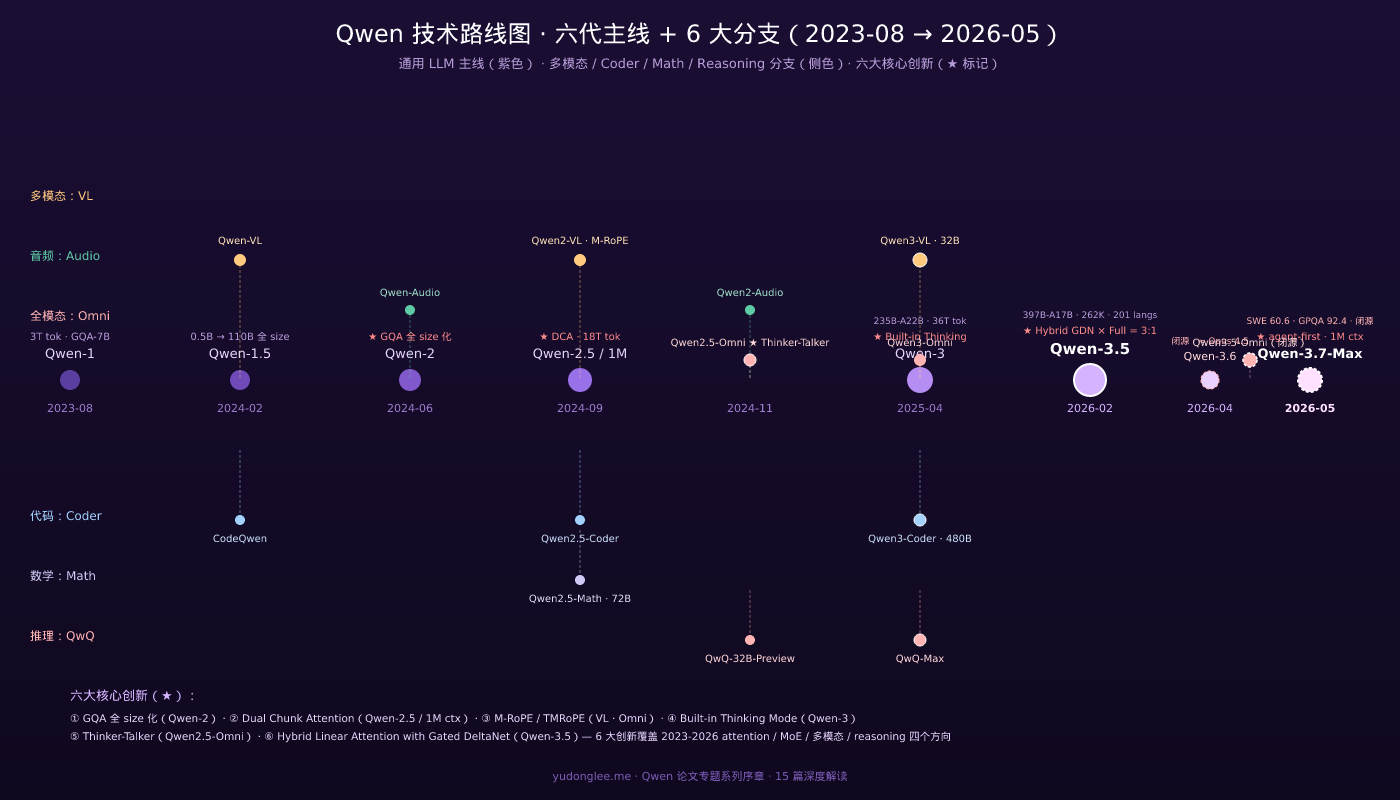
主线(通用 LLM)
Qwen-1 (2023-08, 7B/14B/72B) │ ├─→ Qwen-1.5 (2024-02) —— 升级版(基本同架构) │ │ │ └─→ Qwen-2 (2024-06, 0.5B/1.5B/7B/57B-MoE/72B) │ │ —— GQA 全 size 化、DCA + YaRN、第一次 MoE │ │ │ └─→ Qwen-2.5 (2024-09, 0.5B-72B 七档) │ │ —— 18T tokens、1M context、专项分支同步发布 │ │ │ └─→ Qwen-3 (2025-04, dense 0.6B-32B + MoE 30B-A3B/235B-A22B) │ │ —— Built-in Thinking、Apache 2.0、36T tokens │ │ │ └─→ Qwen-3.5 (2026-02, 397B-A17B Hybrid MoE) │ │ —— Gated DeltaNet × Full Attention (3:1) │ │ 262K native ctx · 201 languages · 8.6-19× 吞吐 │ │ │ ├─→ Qwen-3.6-Plus (2026-04, 闭源) │ │ —— 接近 Claude Opus 4.5 性能 │ │ │ └─→ Qwen-3.7-Max (2026-05, 闭源 · API-only) │ —— agent-first 旗舰 · 1M ctx │ native extended-thinking │ SWE-Pro 60.6 / Terminal-Bench 69.7 / GPQA 92.4
主线一共六代,每一代都有完整的技术报告(开源时间内):
| 时间 | 模型 | 关键 paper / blog |
|---|---|---|
| 2023-08 | Qwen-1 | arXiv:2309.16609 |
| 2024-06 | Qwen-2 | arXiv:2407.10671 |
| 2024-09 | Qwen-2.5 | arXiv:2412.15115 |
| 2025-01 | Qwen2.5-1M | arXiv:2501.15383 |
| 2025-05 | Qwen-3 | arXiv:2505.09388 |
| 2026-02 | Qwen-3.5 / Qwen3.5-Plus (397B-A17B) | alibabacloud blog · HF 开源 |
| 2026-04 | Qwen-3.6-Plus | 闭源(仅 API) |
| 2026-05 | Qwen-3.7-Max(agent-first 旗舰) | Alibaba Cloud Summit · 闭源 · API-only |
6 大专项分支
| 分支 | 首发 | 关键 paper / 模型 |
|---|---|---|
| Qwen-VL(多模态视觉) | 2023-08 | Qwen-VL → Qwen2-VL (arXiv:2409.12191) → Qwen2.5-VL → Qwen3-VL |
| Qwen-Audio(音频) | 2023-11 | Qwen-Audio → Qwen2-Audio (arXiv:2407.10759) |
| Qwen-Coder(代码) | 2024-04 | CodeQwen 1.5 → Qwen2.5-Coder (0.5B-32B) → Qwen3-Coder (480B) |
| Qwen-Math(数学) | 2024-09 | Qwen2.5-Math (arXiv:2409.12122) |
| QwQ(reasoning) | 2024-11 | QwQ-32B-Preview → QwQ-Max |
| Qwen-Omni(统一多模态) | 2025-03 | Qwen2.5-Omni (arXiv:2503.20215) → Qwen3-Omni (arXiv:2509.17765) → Qwen3.5-Omni (arXiv:2604.15804, 2026-04, 闭源) |
可以看到 Qwen 的”全家桶”特征非常明显——主线每一代发布时,对应代际的 VL / Audio / Coder / Math 几乎都同步发布。这与 DeepSeek 的”单旗舰 + 后续 supporting paper”节奏形成鲜明对比。
四、Qwen 六大核心技术创新串讲
六代主线 + 6 大分支背后,真正驱动 Qwen 演进的是六大核心技术创新。我把它们一次串起来:
创新 1:GQA 全 size 化(Qwen-2 首发)
问题:早期 LLM 普遍用 MHA(Multi-Head Attention),导致 KV cache 显存膨胀;LLaMA-2 后业界引入 GQA(Grouped-Query Attention)但只在大 size 上用。
Qwen-2 的选择:所有 size(0.5B 到 72B)一律用 GQA——这是个相对”保守”的工程选择,与 DeepSeek-V2 直接跳到 MLA 形成对比:

GQA 的优势是工程稳定、推理引擎支持成熟(vLLM / SGLang / TensorRT-LLM 全部 day-1 支持)。代价是 KV cache 压缩没有 MLA 那么激进(V2 / V3 详解我们看到 MLA 把 KV cache 砍到 MHA 的 1.76%)。
为什么 Qwen 选 GQA 不选 MLA:因为 Qwen 的目标是”产品级开源全家桶”——0.5B 到 72B 七档都要发布,工程一致性比单点架构创新更重要。MLA 的工程门槛对中小 size 模型反而是负担。
创新 2:Dual Chunk Attention (DCA)(Qwen-2.5 + Qwen2.5-1M 首发)
问题:YaRN-style RoPE 扩展只能把上下文做到 128K 量级,再长就需要新的方法。
DCA 核心思路:
 – Intra-Chunk Attention:每个 chunk 内独立做完整 attention – Inter-Chunk Attention:chunk 之间做”代表 token”级别的稀疏 attention
– Intra-Chunk Attention:每个 chunk 内独立做完整 attention – Inter-Chunk Attention:chunk 之间做”代表 token”级别的稀疏 attention
数学上 DCA 是对相对位置的”二阶 mapping”——把原本超出训练上下文的相对位置 remap 到训练时见过的范围。即使模型只在 32K 训练,配合 DCA 推理可以做到 1M 上下文。
关键效果:Qwen2.5-1M 在 1M-token 的 passkey retrieval 任务上达到接近完美准确率,且不需要专门为 1M 重新训练。
与 DeepSeek 的对照:
| 方案 | 模型 | 设计 | 是否需要重训 |
|---|---|---|---|
| YaRN | LLaMA / Qwen 早期 | RoPE 频率插值 | 需要 |
| NSA | DeepSeek 研究 paper | 三分支稀疏 attention | 需要(natively trainable) |
| DSA | DeepSeek-V3.2 | Lightning Indexer + Token Selection | 需要(continued training) |
| DCA | Qwen-2.5 / Qwen-3 | chunk 内/间双层 attention | 不需要(推理时即可启用) |
DCA 的最大特色是”无需重训”——这对工程落地非常友好,是 Qwen “产品化优先”哲学的典型体现。
创新 3:M-RoPE / TMRoPE(多模态位置编码)
问题:标准 RoPE 是 1D 的(只编码 token 的序列位置),但多模态输入有空间(图像 H×W)和时间(视频帧)维度。
Qwen2-VL 的 M-RoPE (Multimodal Rotary Position Embedding):把 RoPE 分解为三个维度——temporal / height / width:

每种 token 在不同维度上各赋予对应位置: – 文本 token:只用 temporal 维度(t 递增,h=w=0) – 图像 patch:用 height + width(t 固定,h/w 随 patch 网格变化) – 视频帧:三维都用上
Qwen2.5-Omni 的 TMRoPE (Time-aligned Multimodal RoPE) 进一步把音频也纳入这套位置编码——所有模态在 temporal 维度对齐,让模型可以”同步”理解视频 + 音频 + 字幕的多模态流。
这是 Qwen 多模态架构最有特色的设计——位置编码层面的统一让多模态 LLM 不需要 separate adapter,所有模态在同一个 token 空间内处理。
创新 4:Built-in Thinking Mode(Qwen-3 首发)
问题:R1 之后业界出现”reasoning model”和”通用 chat model”两条路线,但单独发布两个模型对用户体验不友好(要切换 endpoint)。
Qwen-3 的解法:在同一个模型里内置 thinking / non-thinking 双模式,用户通过 prompt 标签切换:
/think 问题... → 模型走 long-CoT 推理路径,输出思考过程 + 答案 /no_think 问题... → 模型走快速回答路径,直接给答案
这种设计本质是 multi-task 训练——同一个模型在 RL 阶段同时优化两种行为模式。技术细节:
- 训练数据混合 30% reasoning trace(带
<think>标签)+ 70% 普通对话 - 推理时 prompt 里的
/think标签触发 reasoning 路径 - 训练损失对两种模式各自计算 reward
与 DeepSeek-R1 的对比:
| 维度 | DeepSeek-R1 | Qwen-3 (built-in thinking) |
|---|---|---|
| 模型数量 | 单独的 reasoning specialist | 通用模型内嵌 reasoning |
| 用户切换 | 必须用不同 endpoint | 同一 endpoint,prompt 控制 |
| 训练范式 | 多阶段 SFT + RL | 多任务 SFT + RL |
| 长 CoT 长度 | 通常更长 | 可配置 |
| 通用能力 | 略弱(专注 reasoning) | 强(双模式都覆盖) |
Qwen-3 这种”通用 + reasoning 一体化”路线后来被 Claude 3.7(hybrid reasoning)借鉴。
创新 5:Thinker-Talker 架构(Qwen2.5-Omni 首发)
问题:怎么让一个模型同时做”多模态理解”(看 / 听 / 读)+ “多模态生成”(说 / 写)?
Qwen2.5-Omni 的解法:双角色架构
- Thinker(思考者):核心 LLM,处理文本 + 图像 + 视频 + 音频输入,输出文本
- Talker(说话者):基于 Thinker 的 hidden state,并行生成语音 token(流式 TTS)
![\text{Thinker-Talker: } [V, A, T] \xrightarrow{\text{Thinker}} h_t \xrightarrow{\text{Talker}} \text{speech tokens}](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-a23a8f7d9371adeb1f5bd5b8806d2f3a_l3.png "Rendered by QuickLaTeX.com")
这种设计让 Qwen-Omni 可以做”语音对话”——用户说话,模型理解 + 思考 + 同时用语音流式回复。类似 GPT-4o realtime 的能力,但完全开源。
与 DeepSeek-Janus 的对照:
| 方案 | Qwen2.5-Omni (Thinker-Talker) | Janus (双 encoder 解耦) |
|---|---|---|
| 解耦维度 | 输入理解 vs 输出生成 | 理解 encoder vs 生成 encoder |
| 模态范围 | text + image + audio + video | text + image |
| 生成形式 | 文本 + 语音 | 文本 + 图像 |
| 是否流式 | 是(Talker 流式输出语音) | 否 |
两者代表了”统一多模态”的两种不同切分维度。
创新 6:Hybrid Linear Attention with Gated DeltaNet(Qwen-3.5 首发)
问题:Transformer 标准 attention 的复杂度是 O(N²),长上下文场景下 prefill 和 decode 的代价都呈平方级增长。即使有 DCA 这种”chunk 内/间双层”的工程优化,本质上还是在 O(N²) 上做妥协。能不能直接换成线性 attention?
历史上很多工作尝试过纯线性 attention(Linear Transformers / Performer / Mamba 系列),但都因为表达能力损失太大而无法替代 full attention。Qwen-3.5 给出的答案是hybrid 设计:
Qwen-3.5 的架构: – 每 4 层 Transformer block 中,3 层用 Gated DeltaNet(线性 attention),1 层用 full attention(3:1 比例) – Gated DeltaNet 来自论文 Gated Delta Networks: Improving Mamba2 with Delta Rule,集成了四个关键部件: – Delta rule 提供”错误纠正”的记忆更新 – Exponential gating 提供自适应记忆衰减 – Causal Conv1D 捕获局部上下文 – L2 normalization on Q/K 稳定数值 – 配合 Sparse MoE 路由:397B 总参数 / 17B 激活 / 每次推理只激活 4.3% 参数
![\text{Qwen-3.5 layer pattern: [GDN, GDN, GDN, FullAttn] × N/4}](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-eb38a715b5f36a571deee058160e8422_l3.png "Rendered by QuickLaTeX.com")
关键效果:
| 指标 | Qwen-3 (235B-A22B) | Qwen-3.5 (397B-A17B) |
|---|---|---|
| 总参数 | 235B | 397B(+ 69%) |
| 激活参数 | 22B | 17B(- 23%) |
| Native 上下文 | 128K | 262K(× 2) |
| Decoding 吞吐 | 1× | 8.6 – 19× |
| 支持语言 | 82 | 201(× 2.5) |
吞吐提升的根源是 Gated DeltaNet 的 O(N) 复杂度——长上下文 decode 时不需要重复扫描 KV cache,显存压力也随之下降。
与 DeepSeek-V4 的 NSA/DSA 路线对照:
| 方案 | Qwen-3.5 Hybrid GDN | DeepSeek-V4 NSA/DSA |
|---|---|---|
| 思路 | linear attention 替代部分 full attention | 在 full attention 内部做稀疏化 |
| 比例 | 3:1(线性 : 全) | 全部 full attention,但稀疏选择 token |
| 长上下文复杂度 | O(N)(主体)+ O(N²)(1/4 层) | O(N · k)(k 是稀疏度) |
| 训练难度 | 需要混合训练 + 调比例 | 端到端可训练 |
| 实测 throughput | 8.6 – 19× | 数倍 |
这是 attention 架构演进的两条不同路径——Qwen 走”hybrid 异质 attention”,DeepSeek 走”内部稀疏 attention”。两条路都通向 O(N) 实际推理复杂度,但工程取舍不同。Qwen-3.5 是 2026 年开源 LLM 在 attention 架构上最大的一次跃迁,本系列 Q6 会专门展开。
五、Qwen 系列文章导航(序章 + 15 篇 · 持续更新中)
整个专题覆盖 1 序章 + 15 篇核心 paper 详解 = 16 篇文章,按通用主线 + 专项分支 + 横向收官组织。下面是完整导航——已发布 8 篇,其余撰写中,新篇发布后会第一时间在此更新链接。
Phase 1:通用主线(序章 + 第 1-5 篇 · 共 6 篇)
| 篇序 | 文章 | 核心创新 | 发布时间(论文) |
|---|---|---|---|
| 序章 | Qwen 家族技术路线图(本文) | 16 篇系列总览 · 六大核心创新串讲 | — |
| 第 1 篇 | Qwen-1 详解 | 阿里 LLM 开山之作 · Untied embeddings · 151K 双语 tokenizer · RoPE base 1e6 · Long-ctx 三件套 | 2023-08 |
| 第 2 篇 | Qwen-2 详解:与 DeepSeek 单点突破相反的工程一致性路径 | GQA 全 size 化 · 第一次 MoE (57B-A14B) · YaRN 长上下文 · DPO 替代 PPO | 2024-06 |
| 第 3 篇 | Qwen-2.5 / 1M 详解:Dual Chunk Attention 开启 1M 上下文时代 | 18T tokens · DCA 推理时 1M context · 全 size 矩阵 · 全家桶首次同步 | 2024-09 / 2025-01 |
| 第 4 篇 | Qwen-3 详解:Built-in Thinking Mode + 高稀疏 MoE 全面升级 | Dense + MoE 双轨 · Built-in Thinking Mode · 235B-A22B · PPO+GRPO 混合 | 2025-04 |
| 第 5 篇 | Qwen-3.5 详解:Hybrid Linear Attention 把 attention 拉到准线性 | Hybrid Attention(GDN × Full = 3:1)· 397B-A17B Sparse MoE · 262K native ctx · 8.6-19× 吞吐 | 2026-02 |
Phase 2:专项分支(第 6-12 篇 · 共 7 篇)
| 篇序 | 文章 | 核心创新 | 发布时间(论文) |
|---|---|---|---|
| 第 6 篇 | Qwen-VL 系列详解:从 Qwen-VL 到 Qwen3-VL 的四代跃迁 | M-RoPE · Naive Dynamic Resolution · 视频理解 · Visual Grounding | 2023-08 ~ 2025-11 |
| 第 7 篇 | Qwen-Audio 系列详解:30+ 任务统一架构 + 双模式音频 LLM | 统一语音 LLM · 双模式训练 · 30+ 音频任务 | 2023-11 / 2024-07 |
| 第 8 篇 | Qwen2.5-Omni 详解:Thinker-Talker 双角色 + TMRoPE (撰写中) | Thinker-Talker 双角色架构 · TMRoPE 时间-多模态对齐 · 实时流式 | 2025-03 |
| 第 9 篇 | Qwen3-Omni → Qwen3.5-Omni 详解:Built-in Thinking 多模态化 + HLA backbone (撰写中) | Multimodal Thinking · HLA backbone · 实时延迟 < 200 ms · 闭源转向 | 2025-09 / 2026-04 |
| 第 10 篇 | Qwen-Coder 系列详解:从 CodeQwen 1.5 到 Qwen3-Coder 480B (撰写中) | Repo-level 训练 · FIM · 480B-A35B MoE · agentic coding · SWE-bench 56.4 | 2024-04 / 2024-09 / 2025-07 |
| 第 11 篇 | Qwen2.5-Math 详解:数学推理路线的工程范式 (撰写中) | TIR (Tool-Integrated Reasoning) · Self-Improvement Loop · Gaokao 88.5 | 2024-09 |
| 第 12 篇 | QwQ 系列详解:Qwen 的 reasoning specialist 路线 (撰写中) | Self-Questioning Long-CoT · 多阶段 RL · test-time scaling · QwQ-Max 压过 o1 / R1 | 2024-11 / 2025-03 / 2025-Q3 |
Phase 3:横向收官(第 13-15 篇 · 共 3 篇)
| 篇序 | 文章 | 核心内容 | 发布 |
|---|---|---|---|
| 第 13 篇 | Qwen 工业落地与生态详解:LLaMA-Factory + vLLM + 阿里云 DashScope (撰写中) | 微调框架 + 推理引擎 + HF 40M+ 下载 + DashScope $280M ARR + 行业落地案例 | 2026-05 |
| 第 14 篇 | Qwen vs DeepSeek vs Llama 三方对决:开源 LLM 三条路径 (撰写中) | 战略 / 矩阵 / 架构 / 评测 / 商业 / 开源 / 生态 七维度对照 · Qwen 8/12 评测第一 | 2026-05 |
| 第 15 篇 | Qwen 未来路线展望:Qwen-4 / Qwen-5 / world model / Agent (撰写中) ⭐ 系列收官 | Qwen-4 (2026-Q4) · Qwen-5 (2028+) · Omni 终极形态 · agent / world model · 系列 16 篇总结 | 2026-05 |
六、Qwen 的工程哲学三条
回看 Qwen 两年半的所有论文与产品,可以提炼出三条稳定的工程哲学。
哲学 1:开源全栈(不只是 weights)
DeepSeek 的开源是”完整 weights + 完整技术报告”,但 Qwen 走得更远——整个工具链 + 微调框架 + 推理引擎全开:
- 模型权重:Apache 2.0
- 数据混合配比:技术报告里详细披露
- Tokenizer:BBPE 实现完整开源
- 微调框架:LLaMA-Factory(阿里员工主导)、SwiftFinetuning 都是 first-party 项目
- 推理引擎:vLLM / SGLang 上 Qwen 是 day-1 支持的第一梯队
这种”开源全栈”让 Qwen 在中小企业 / 学术圈成为事实标准——很多企业用 Qwen 作为”先尝试再切其他”的默认基模。
哲学 2:全 size 矩阵(0.5B 到 235B)
DeepSeek 的策略是”集中火力做旗舰”(67B → 236B → 671B → 1.6T 四代),Qwen 的策略相反——每一代都铺完整 size 矩阵:
| 代 | 提供 size |
|---|---|
| Qwen-1 | 7B / 14B / 72B |
| Qwen-2 | 0.5B / 1.5B / 7B / 57B-MoE / 72B |
| Qwen-2.5 | 0.5B / 1.5B / 3B / 7B / 14B / 32B / 72B |
| Qwen-3 | 0.6B / 1.7B / 4B / 8B / 14B / 32B + 30B-A3B / 235B-A22B |
全 size 矩阵的好处:
- 端侧 → 云端全覆盖(0.5B 模型可跑在手机上)
- 不同应用场景的成本/性能选择灵活
- 小 size 用 distillation 自旗舰,质量有保障
代价是每个 size 都要单独 alignment + safety tuning——工程量大但 Qwen 团队规模足够(200+ 人)。
哲学 3:多模态优先(Day 1 就有 VL 分支)
第三个独特之处:Qwen 从 2023-08 首发开始就同步发布了 Qwen-VL——这与同期 LLaMA / DeepSeek “先做通用 LLM 再延伸多模态”的节奏不同。
Qwen 的多模态家桶演化:
2023-08: Qwen-VL (与 Qwen-1 同步) 2023-11: Qwen-Audio (3 个月后) 2024-09: Qwen2-VL + Qwen2-Audio (与 Qwen-2 同步) 2024-09: Qwen2.5-VL (Day 1 与 Qwen-2.5 同步) 2025-03: Qwen2.5-Omni (统一多模态) 2025-05: Qwen3-VL / Qwen3-Omni (与 Qwen-3 同步)
这种”多模态优先”路线带来两个长期价值:
- 产品定位差异化:Qwen 在企业 ToB 应用中更受欢迎(多模态需求多)
- 架构积累:M-RoPE → TMRoPE → Thinker-Talker 的演化路径只有 Qwen 这条线完整做完
这三条哲学对使用者意味着什么:我的选型推论
把上面三条工程哲学翻译成使用者视角的决策依据,我的推论是:
- 业务系统的默认起点选 Qwen,不是因为它最强,而是因为它”全”。从 0.5B 到旗舰的完整 size 阶梯 + Apache 2.0 + day-0 的 vLLM/llama.cpp/Ollama 适配,意味着你可以在同一族模型里完成”端侧小模型 → 云端大模型”的全部部署形态,prompt 和微调资产基本可以平移。这种工程一致性的价值,在团队要维护多个部署形态时会被放大很多倍。
- 追前沿单点能力(深度推理、极致性价比)时看 DeepSeek。两家的路线差异(本系列反复对比的”工程一致性 vs 单点突破”)决定了它们的适用场景天然错位,这也是为什么 2025 年之后很多团队的实际配置是”Qwen 做业务主力 + DeepSeek 做推理重任务”的混合栈。
- 第三个常被忽略的维度是生态绑定:Qwen 与阿里云、百炼平台的深度耦合是双刃剑——托管便利,但如果你的基础设施在其他云上,要把私有化部署的运维成本算进总账。
这三条没有哪条来自 benchmark 表格,但在我看来,它们比 benchmark 更接近”选型时真正起作用的变量”。
七、横向对比:Qwen vs DeepSeek vs LLaMA vs Mistral
把 Qwen 放到全球开源 LLM 矩阵里横向对比。先用一张图把 Qwen 与 DeepSeek 这”中国开源双旗舰”的两条路径放在一起看:

再扩展到全球矩阵(2026-05 最新旗舰):
| 维度 | Qwen-3.7-Max | DeepSeek-V4-Pro | LLaMA-4 / 5 | Mistral |
|---|---|---|---|---|
| 最大旗舰 | agent-first(参数闭源)· 上游 Qwen-3.5 397B-A17B | 1.6T-A49B MoE | 400B+ | Mistral Large 2 |
| 训练 tokens | 36T+ | 32T | ~15T | 闭源 |
| Attention | Hybrid: Gated DeltaNet × Full = 3:1 + native extended-thinking | MLA + CSA/HCA + mHC | GQA + 长上下文 | GQA |
| MoE 路线 | Sparse MoE + 397B/17B 高稀疏比 | DeepSeekMoE (fine-grained + shared) + Aux-loss-free | 部分 size 用 | Mistral 8x22B |
| 多模态 | VL + Audio + Omni / 3.5-Omni 全家桶 | VL + Janus 双线 | Llama-Vision 单线 | Mistral Vision |
| Reasoning | Built-in thinking mode + QwQ-Max | R1 / R2 / GRM 独立 specialist | 较弱 | 较弱 |
| Native ctx | 262K | 1M(V3.2+) | 128K-1M | 32K-128K |
| Size 矩阵 | 0.6B – 397B 九档 | 14B / 671B / 1.6T 三档 | 7B / 70B / 400B 三档 | 7B / 22B / 124B 三档 |
| 协议 | Apache 2.0(3.5 主线)+ 闭源(3.5-Omni / 3.6-Plus) | MIT | 自定义 community license | Apache 2.0 / 闭源 |
| 主要市场 | 中国 + 全球开源 | 全球研究圈 + ToB | 全球(Meta 应用嵌入) | 欧洲 + 美国 |
可以看到 Qwen 与 DeepSeek 在五个维度上路径截然相反:
- Size 矩阵:Qwen 九档完整(0.6B-397B)vs DeepSeek 集中火力(三档旗舰)
- 多模态:Qwen 全家桶(VL + Audio + Omni)vs DeepSeek 单线 + Janus
- Reasoning:Qwen 通用一体化(thinking mode in Qwen-3)vs DeepSeek 独立 specialist(R1 / R2 / GRM)
- Attention 路线(2026 年新分歧):Qwen hybrid 异质 attention(GDN × Full = 3:1)vs DeepSeek 内部稀疏 attention(NSA / DSA)——两条路都通向 O(N) 实际推理复杂度
- 2026 闭源转向:Qwen 3.5-Omni / 3.6-Plus / 3.7-Max 全部闭源 API-only vs DeepSeek V4 仍 MIT 全开源——Qwen 在 frontier 旗舰上明显收敛
两条路径都是有效的——Qwen 服务于”开源全栈产品”目标,DeepSeek 服务于”frontier 研究”目标。2026 年的 Qwen-3.5 Hybrid Attention 是 attention 架构演进的一个里程碑节点——它证明了 linear attention 在工业级 frontier 模型里完全可用,本系列 Q6 会专门展开分析。
八、写在最后:为什么值得读这个系列
开源大模型对整个 AI 行业的影响越来越深远,值得大家深入研究和分享。沿着 DeepSeek 系列之后再继续做 Qwen 系列,逻辑是:
- 理解中国开源大模型不能只看一家:Qwen 与 DeepSeek 是两条独立但互补的路线。看完两个系列你才能完整理解”中国开源大模型”是什么形态
- Qwen 的工程哲学更贴近产品落地:如果你做 ToB 应用、端侧部署、私有化部署,Qwen 比 DeepSeek 是更现实的基模选择。这个系列偏重 Qwen 在工程落地上的具体取舍
- DCA / M-RoPE / Thinker-Talker / Built-in Thinking 都是独家技术:这四项创新只在 Qwen 这条线完整做完,市场上几乎没有深度教学内容
- 与 DeepSeek 系列形成强互链:每篇 Qwen 文章都会对照对应的 DeepSeek 论文(如 Qwen-Coder ↔ DeepSeek-Coder、QwQ ↔ R1),两个系列加起来是中国开源 LLM 的完整知识地图
全系列 16 篇已全部完成 ✅:
通用主线(5 篇):
- 第 1 篇 Qwen-1 详解 ——”阿里开山之作”的四个非主流工程取舍
- 第 2 篇 Qwen-2 详解 ——与 DeepSeek 单点突破相反的工程一致性路径
- 第 3 篇 Qwen-2.5 / 1M 详解 ——DCA 开启 1M 上下文时代
- 第 4 篇 Qwen-3 详解 ——Built-in Thinking Mode + 高稀疏 MoE 全面升级
- 第 5 篇 Qwen-3.5 详解 ——Hybrid Linear Attention 把 attention 拉到准线性
专项分支(7 篇):
- 第 6 篇 Qwen-VL 系列详解 ——从 Qwen-VL 到 Qwen3-VL 的四代跃迁
- 第 7 篇 Qwen-Audio 系列详解 ——30+ 任务统一架构 + 双模式音频 LLM
- 第 8 篇 Qwen2.5-Omni 详解 (撰写中) ——Thinker-Talker 双角色 + TMRoPE
- 第 9 篇 Qwen3-Omni → Qwen3.5-Omni 详解 (撰写中) ——Built-in Thinking 多模态化 + HLA backbone
- 第 10 篇 Qwen-Coder 系列详解 (撰写中) ——从 CodeQwen 1.5 到 Qwen3-Coder 480B
- 第 11 篇 Qwen2.5-Math 详解 (撰写中) ——数学推理路线的工程范式
- 第 12 篇 QwQ 系列详解 (撰写中) ——Qwen 的 reasoning specialist 路线
横向收官(3 篇):
- 第 13 篇 Qwen 工业落地与生态详解 (撰写中) ——LLaMA-Factory + vLLM + 阿里云 DashScope 全栈生态
- 第 14 篇 Qwen vs DeepSeek vs Llama 三方对决 (撰写中) ——开源 LLM 时代的三条路径全景对照
- 第 15 篇 Qwen 未来路线展望 (撰写中) ⭐ 系列收官 ——Qwen-4 / Qwen-5 / world model / Agent
系列写作汇总:~180K 中文字 · 45+ SVG 概念图 · 25+ 主论文覆盖 · Qwen 全系 50+ 模型 · 与 DeepSeek 18 篇专题系列 形成”中国开源 LLM 双旗舰”对照知识地图。 —
参考资料
- Bai et al., Qwen Technical Report, arXiv:2309.16609, 2023. <https://arxiv.org/abs/2309.16609>
- Qwen Team, Qwen2 Technical Report, arXiv:2407.10671, 2024. <https://arxiv.org/abs/2407.10671>
- Qwen Team, Qwen2.5 Technical Report, arXiv:2412.15115, 2024. <https://arxiv.org/abs/2412.15115>
- Qwen Team, Qwen2.5-1M Technical Report, arXiv:2501.15383, 2025. <https://arxiv.org/abs/2501.15383>
- Qwen Team, Qwen3 Technical Report, arXiv:2505.09388, 2025. <https://arxiv.org/abs/2505.09388>
- Wang et al., Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution, arXiv:2409.12191, 2024. <https://arxiv.org/abs/2409.12191>
- Chu et al., Qwen2-Audio Technical Report, arXiv:2407.10759, 2024. <https://arxiv.org/abs/2407.10759>
- Xu et al., Qwen2.5-Omni Technical Report, arXiv:2503.20215, 2025. <https://arxiv.org/abs/2503.20215>
- Yang et al., Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement, arXiv:2409.12122, 2024. <https://arxiv.org/abs/2409.12122>
- Qwen Team, Qwen3-VL Technical Report, arXiv:2511.21631, 2025. <https://arxiv.org/abs/2511.21631>
- Qwen Team, Qwen3-Omni Technical Report, arXiv:2509.17765, 2025. <https://arxiv.org/abs/2509.17765>
- Alibaba Group, Alibaba Open-Sources Qwen3.5, A Natively Multimodal Model Built For High-Efficiency Inference, 2026-02. <https://www.alibabagroup.com/en-US/document-1960233590314762240>
- Qwen Team, Qwen3.5: Towards Native Multimodal Agents, Alibaba Cloud Blog, 2026-02. <https://www.alibabacloud.com/blog/qwen3-5-towards-native-multimodal-agents_602894>
- Yang et al., Gated Delta Networks: Improving Mamba2 with Delta Rule, 2024. (Qwen-3.5 Hybrid Attention 的基础组件)
- Qwen Team, Qwen3.5-Omni Technical Report, arXiv:2604.15804, 2026-04. <https://arxiv.org/abs/2604.15804>
- Alibaba Cloud, Qwen 3.7 Max: Agent-First Flagship LLM, Alibaba Cloud Summit, 2026-05-20.
- DeepSeek-AI, DeepSeek 技术路线图(本博客系列), <https://yudonglee.me/deepseek-roadmap/>
![]()
发表回复