
转载本文请注明出处:https://yudonglee.me/qwen-vl-series-explained/ | 作者:yudonglee

本文是 Qwen 论文专题系列 第七篇。我们离开通用 LLM 主线,进入 Qwen 多模态全家桶的第一个分支——Qwen-VL 系列。从 2023-08 与 Qwen-1 同步发布的 Qwen-VL(arXiv:2308.12966),到 2024-09 的 Qwen2-VL(arXiv:2409.12191)、2025-01 的 Qwen2.5-VL(arXiv:2502.13923),再到 2025-11 的 Qwen3-VL,这条线一共四代。四代演进对应四个核心技术贡献:(1) 早期的 cross-attention adapter 范式;(2) M-RoPE(Multimodal Rotary Position Embedding)——把 RoPE 分解为 temporal/height/width 三维;(3) Naive Dynamic Resolution——任意分辨率输入,无固定 size 限制;(4) 视频时序理解 + Visual Grounding(物体定位)。本文一次串讲完整四代。
一、引言:Qwen-VL 这条线为什么重要
回到 Q1 序章 里我说的”Qwen vs DeepSeek 两条路径”:Qwen 选了”多模态全家桶 + 主线同步”的路径,DeepSeek 选了”通用 LLM 优先、多模态滞后”的路径。Qwen-VL 系列就是这条全家桶战略的奠基分支——从 2023-08 Qwen-1 与 Qwen-VL 同月发布开始,多模态就被定位为”与通用 LLM 同等优先级”的产品线。
把四代 Qwen-VL 放到时间线里看:
2023-08 Qwen-VL 7B · OpenCLIP ViT-bigG · cross-attention adapter
↑ 与 Qwen-1 同月发布
2024-09 Qwen2-VL 2B / 7B / 72B · ★ M-RoPE · ★ Naive Dynamic Resolution
↑ 比 Qwen-2 晚 3 个月
2025-01 Qwen2.5-VL 3B / 7B / 72B · 视频时序理解 · Visual Grounding · 文档 OCR
↑ 与 Qwen-2.5 / 1M 同期发布
2025-11 Qwen3-VL 8B / 32B Dense + MoE 旗舰 · Built-in Thinking · 与 Qwen-3 backbone 对齐
↑ 与 Qwen-3 半年后同步迭代
四代演进的核心命题各不相同:
- Qwen-VL(2023-08):早期范式——用 cross-attention adapter 把视觉信息注入 LLM。目标是把多模态推到工业级开源
- Qwen2-VL(2024-09):架构原创——M-RoPE 把 RoPE 扩展到三维(temporal/height/width),Naive Dynamic Resolution 让任意分辨率输入成为可能
- Qwen2.5-VL(2025-01):能力扩展——视频时序理解 + Visual Grounding + 文档 OCR 三项跨能力扩展
- Qwen3-VL(2025-11):对齐主线——与 Qwen-3 backbone 完全对齐,引入 Built-in Thinking Mode 处理视觉推理任务
理解 Qwen-VL 不只是理解”一个 VL 模型”——理解的是 Qwen 整个多模态战略的工程演化轨迹。
二、Qwen-VL 系列论文 / 模型一览
| 维度 | Qwen-VL(2023-08) | Qwen2-VL(2024-09) | Qwen2.5-VL(2025-01) | Qwen3-VL(2025-11) |
|---|---|---|---|---|
| 论文 | arXiv:2308.12966 | arXiv:2409.12191 | arXiv:2502.13923 | tech blog |
| 模型 size | 7B | 2B / 7B / 72B | 3B / 7B / 72B | 8B / 32B Dense + MoE |
| LLM backbone | Qwen-1-7B | Qwen-2 | Qwen-2.5 | Qwen-3 |
| 视觉 encoder | OpenCLIP ViT-bigG | 重写的 ViT(任意分辨率) | 同 Qwen2-VL 升级版 | 进一步升级 + 视频编码优化 |
| 视觉-语言桥接 | cross-attention adapter | M-RoPE 直接共享 token 空间 | 同 + 视频时序扩展 | 同 + Built-in Thinking 适配 |
| 输入图像 size | 固定 448×448 | 任意分辨率(无 padding) | 同 + 视频帧任意分辨率 | 同 |
| 视频支持 | 无 | 简单视频帧序列 | 完整视频时序理解 | 同 + 长视频(30 分钟+) |
| Visual Grounding | 部分(粗粒度 box) | 增强 | 像素级精确 grounding | 同 |
| 文档 OCR | 弱 | 中等 | 强(媲美专项 OCR 模型) | 同 |
| 协议 | Tongyi Qianwen License | Apache 2.0 | Apache 2.0 | Apache 2.0 |
| 关键贡献 | 多模态开源工业级 | M-RoPE + Naive Dynamic Resolution | 视频 + grounding + OCR | 对齐 Qwen-3 + thinking |
放到同期对比:
| 时间 | Qwen-VL 代 | 同期同类竞品 |
|---|---|---|
| 2023-08 | Qwen-VL-7B | LLaVA-1.5(2023-10)· MiniGPT-4(2023-04) |
| 2024-09 | Qwen2-VL-72B | LLaVA-OneVision · DeepSeek-VL · InternVL-2 |
| 2025-01 | Qwen2.5-VL-72B | DeepSeek-VL2 · InternVL-2.5 · GPT-4o |
| 2025-11 | Qwen3-VL-32B | GPT-4o · Gemini 2.0 Pro · Claude 3.7 |
Qwen-VL 系列是开源多模态 LLM 里唯一与主线 LLM 同节奏迭代了 4 代的——LLaVA / DeepSeek-VL / InternVL 的多模态迭代节奏都明显慢于通用 LLM 主线。
三、第一代 Qwen-VL:cross-attention adapter 范式
3.1 Qwen-VL 的设计
Qwen-VL(2023-08)的整体架构:
Image (448×448)
│
▼
OpenCLIP ViT-bigG/14
│ (产生 256 个 visual tokens)
▼
Position-aware Cross-Attention Adapter
│ (把 256 个 visual tokens → 256 维的 query 序列)
▼
┌────────────────────────────────┐
│ Qwen-1-7B LLM │
│ 每隔几层加 cross-attention: │
│ Q from LLM │
│ K, V from visual tokens │
└────────────────────────────────┘
│
▼
Output text
关键设计:
- 视觉 encoder:OpenCLIP ViT-bigG/14,约 1.9B 参数
- Adapter:position-aware cross-attention,把 256 个视觉 token 注入到 LLM 中间层
- 图像输入固定 448×448:不能动态分辨率,所有图像被强制 resize
- 训练 pipeline 三阶段:visual-language alignment → multi-task pretraining → SFT
3.2 Qwen-VL 的局限
回头看,Qwen-VL 这一代有三个明显局限:
- 固定分辨率:所有图像 resize 到 448×448,长宽比信息丢失、细节模糊
- Visual tokens 数量固定(256):对于复杂图像/文档 OCR 信息不够,对简单图像又浪费 budget
- Cross-attention adapter 是后置补丁:视觉信息和文本信息不在同一个 token 空间,需要专门的 attention 路径
但 Qwen-VL 仍然是 2023-08 时点开源多模态最强之一——它在 ScienceQA、VQAv2、TextVQA、RefCOCO 等多模态评测上超过同期 LLaVA-1.5、MiniGPT-4。
这一代的工程贡献不在”突破架构”,而在把多模态推到工业级开源 + 与通用 LLM 同步发布。Qwen-VL 是 Qwen 全家桶战略的第一块多模态基石。
四、第二代 Qwen2-VL:M-RoPE 与 Naive Dynamic Resolution(架构原创)
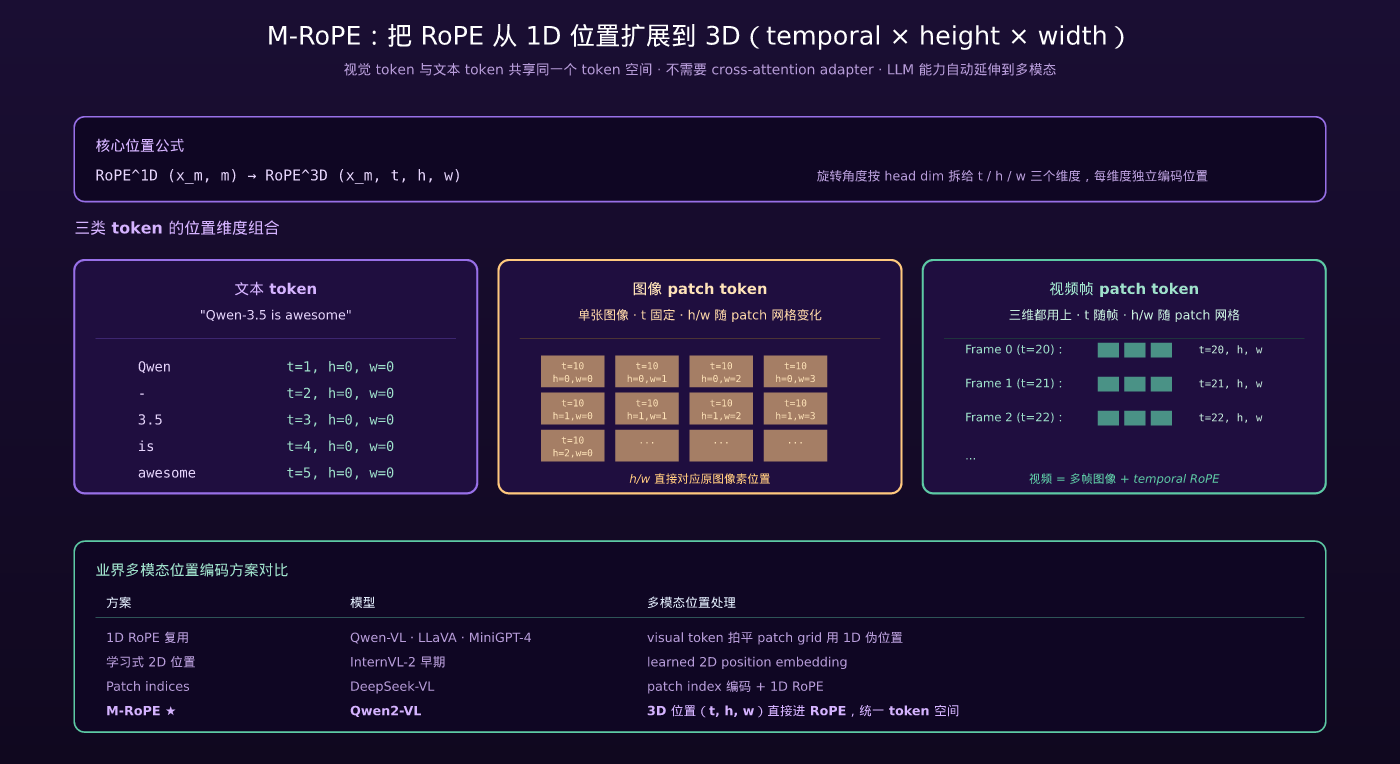
4.1 Qwen2-VL 的两大原创
Qwen2-VL(2024-09,arXiv:2409.12191)是 Qwen-VL 系列里最重要的一代——它做了两个真正的架构原创:
原创 ①:M-RoPE(Multimodal Rotary Position Embedding)
把 RoPE 从一维位置(只有 token 序列位置)扩展到三维:

其中: – t = temporal(时间维度,视频帧序号) – h = height(图像高度位置) – w = width(图像宽度位置)
不同 token 类型使用不同的位置维度组合:
| Token 类型 | t | h | w |
|---|---|---|---|
| 文本 token | t 递增 | 0 | 0 |
| 单张图像 patch | t 固定 | h 随 patch 行变化 | w 随 patch 列变化 |
| 视频帧 patch | t 随帧序号变化 | h 随 patch 行变化 | w 随 patch 列变化 |
这种设计的关键好处是:视觉 token 和文本 token 共享同一个 token 空间——视觉信息不再通过 cross-attention adapter 注入,而是直接作为 token 序列的一部分喂进 LLM。

旋转角度按 head dimension 分配给 t / h / w 三个维度,每个维度独立编码位置。
原创 ②:Naive Dynamic Resolution
抛弃”图像必须 resize 到固定 size”的传统。Qwen2-VL 直接处理任意分辨率图像:
输入图像 1920×1080
│
▼
切成 14×14 patch(不做 resize)
│ 产生 ~10,500 个 patch
▼
ViT encoder(每个 patch 一个 token)
│
▼
2× compression(相邻 4 个 patch → 1 个 visual token)
│ 产生 ~2,600 个 visual token
▼
带 M-RoPE 位置编码注入 LLM
关键设计:
- 任意输入分辨率:图像不需要 padding 或 resize 到固定 size
- 动态 token 数量:低分辨率图像产生少量 token、高分辨率图像产生大量 token
- 2× compression:用相邻 4 patch 平均池化压缩,节省 visual token budget
- 绝对位置不变:M-RoPE 的 h/w 维度直接对应原图像素位置(不是相对位置)
4.2 M-RoPE + Dynamic Resolution 组合的工程影响
这两个原创组合起来产生了三个重要效果:
效果 ①:图像理解精度大幅提升 固定 448×448 + 256 visual tokens 对一张 1920×1080 的截图来说损失太多细节。Dynamic resolution 让 Qwen2-VL 在 DocVQA / TextVQA / ChartQA 上的得分相比 Qwen-VL 提升 15-25 个点。
效果 ②:视频时序自然延伸 M-RoPE 的 t 维度天然支持视频——每一帧 t 递增、帧内 h/w 不变。这让 Qwen2-VL 不需要专门的视频编码器,视频 = 多帧图像 + temporal RoPE。
效果 ③:与 LLM 完全统一 Visual token 和 text token 在同一 token 序列里,不需要 cross-attention adapter。LLM 的所有能力(in-context learning / chain-of-thought / 多轮对话)自动延伸到多模态场景。
4.3 M-RoPE 与业界其他多模态位置编码的对比
| 方案 | 模型 | 多模态位置处理 |
|---|---|---|
| 1D RoPE 复用 | Qwen-VL · LLaVA · MiniGPT-4 | visual token 用伪 1D 位置(拍平 patch grid) |
| 学习式 2D 位置 | InternVL-2 早期 | visual token 用 learned 2D position embedding |
| Patch indices | DeepSeek-VL | 视觉 patch index 编码 + 复用 1D RoPE |
| M-RoPE | Qwen2-VL | 3D 位置(t, h, w)直接进 RoPE |
| Hybrid 1D + 2D | Llama-3.2-Vision | LLM 主体 1D RoPE,视觉用 2D |
M-RoPE 是业界第一个把多模态位置编码做到”完全统一进 RoPE”的开源方案——这是 Qwen 多模态系列最具影响力的架构贡献,后续 Qwen2.5-Omni 把 M-RoPE 扩展到 TMRoPE(再加音频维度),具体见 Q9 Omni 详解。
五、第三代 Qwen2.5-VL:视频 + Grounding + OCR 三项跨能力
5.1 Qwen2.5-VL 的能力扩展方向
Qwen2.5-VL(2025-01,arXiv:2502.13923)继承 Qwen2-VL 的 M-RoPE + Dynamic Resolution 架构基础,在能力上做了三项跨越:
扩展 ①:长视频时序理解
Qwen2-VL 的视频支持限于”短视频帧序列”(几十秒)。Qwen2.5-VL 做了三件事让长视频可用:
- 时序压缩:视频帧用更激进的 spatial + temporal 压缩,30 分钟视频可装进 32K context
- 关键帧选择:自动选择信息密度高的帧重点处理
- 时间戳对齐:模型可以输出”视频第 X 分钟 Y 秒发生了什么”
效果:Qwen2.5-VL-72B 在 LongVideoBench(30 分钟长视频 QA 评测)上达到 60.1%——是 2025-01 时点的开源 SOTA。
扩展 ②:精确 Visual Grounding(物体定位)
Qwen-VL 时代的 grounding 输出是粗粒度 box(精度低);Qwen2.5-VL 升级到像素级精确 grounding:
User: 标出图中所有红色的苹果 Qwen2.5-VL 输出: 苹果 1: <box>[245, 132, 387, 274]</box> (像素坐标) 苹果 2: <box>[512, 89, 654, 231]</box> 苹果 3: <box>[178, 305, 320, 447]</box>
技术关键: – 视觉 token 的 M-RoPE h/w 位置直接对应原图像素坐标 – 训练数据包含大量 grounding 标注(COCO + RefCOCO + 自合成) – 输出 token 直接 decode 成像素 box,不需要额外 detection head
Qwen2.5-VL 在 RefCOCO / RefCOCO+ / RefCOCOg 等 grounding 评测上达到 90%+ 准确率,接近专项 detection 模型水平。
扩展 ③:文档 OCR 接近专项模型
Qwen2.5-VL 在文档 OCR 任务上专门做了能力强化:
- 训练数据补充 PDF / 表格 / 公式 / 手写体大量样本
- M-RoPE 的 h/w 位置编码让 OCR 输出可以保留版面结构
- 输出格式直接是 markdown(表格、列表、标题层级)
在 DocVQA / ChartQA / InfographicsVQA 上 Qwen2.5-VL-72B 达到 96.4% / 91.2% / 81.1%——已经在 ToB 文档处理场景可以替代 GPT-4o。
5.2 Qwen2.5-VL 与 Qwen2.5 主线的同步
Qwen2.5-VL 与 Qwen2.5 主线完全同步发布——这是 Qwen 全家桶战略的第一次真正落地:
- 共享 backbone:Qwen2.5-VL 直接用 Qwen2.5 backbone 做继续训练(不是单独从头训)
- 共享 tokenizer:151K BPE 一致
- 共享后训练:DPO + 部分 PPO 沿用 Qwen2.5
- 同步 size 矩阵:3B / 7B / 72B 与主线对齐
这种”共享 backbone + 多模态专项继续训练”的工程模式后来被 Qwen-3-VL / Qwen3-Omni 继续沿用,成为 Qwen 多模态分支的固定开发范式。
六、第四代 Qwen3-VL:对齐 Qwen-3 主线 + Built-in Thinking
6.1 Qwen3-VL 的关键改动
Qwen3-VL(2025-11)的核心改动是对齐 Qwen-3 主线特性:
| 维度 | Qwen2.5-VL | Qwen3-VL |
|---|---|---|
| LLM backbone | Qwen-2.5 | Qwen-3 |
| Size 矩阵 | 3B / 7B / 72B dense | 8B / 32B Dense + MoE 旗舰 |
| Reasoning | 通用 | Built-in Thinking Mode(/think + /no_think) |
| 视频长度 | 30 分钟+ | 更长(小时级) |
| 长上下文 | 32K | 128K-1M(继承 Qwen-3 DCA) |
最有意思的是 Built-in Thinking 进入视觉推理——用户可以用 /think 标签让 Qwen3-VL 在 GUI agent / 数学几何题 / 科学图表问题等任务上做 long-CoT 视觉推理。
6.2 Qwen3-VL 的应用场景拓展
Qwen3-VL 重点扩展了三个应用场景:
- GUI agent:处理屏幕截图、操作 GUI 应用(点击 / 滚动 / 输入),与 Qwen-3 的 agentic 能力配合
- 科学问答:复杂图表 + 长 CoT 推理(化学反应式、物理示意图等)
- 长视频理解:小时级会议视频 / 教学视频自动摘要
这把 Qwen-VL 从”单图像理解”工具升级为”视觉智能体”的基础组件。
七、四代 Qwen-VL 的演化总结

把四代演化压缩成一张表:
| 维度 | Qwen-VL (2023-08) | Qwen2-VL (2024-09) | Qwen2.5-VL (2025-01) | Qwen3-VL (2025-11) |
|---|---|---|---|---|
| 多模态融合方式 | cross-attention adapter | M-RoPE 统一 token 空间 ★ | 同 + 视频维度扩展 | 同 + Thinking 适配 |
| 图像分辨率 | 固定 448 | 任意分辨率(Naive Dynamic) ★ | 同 + OCR 增强 | 同 |
| 视频 | 无 | 简单短视频 | 长视频时序理解 ★ | 小时级 |
| Grounding | 粗粒度 | 增强 | 像素级精确 ★ | 同 |
| OCR | 弱 | 中等 | 接近专项模型 ★ | 同 |
| Reasoning | 无 | 通用 | 通用 | Built-in Thinking ★ |
| LLM backbone | Qwen-1 | Qwen-2 | Qwen-2.5 | Qwen-3 |
| 每代关键贡献 | 多模态开源工业级 | M-RoPE + Dynamic Resolution | 视频 + Grounding + OCR | 对齐主线 + Thinking |
Qwen-VL 系列的核心叙事:
- 第一代奠基(Qwen-VL):用现成的 cross-attention adapter 范式把多模态推到工业级开源
- 第二代架构原创(Qwen2-VL):M-RoPE 把多模态位置编码统一进 RoPE,Naive Dynamic Resolution 抛弃固定分辨率限制
- 第三代能力扩展(Qwen2.5-VL):把架构原创做的”基底”用足,扩展到视频 + grounding + OCR 三个场景
- 第四代主线对齐(Qwen3-VL):与 Qwen-3 backbone 完全对齐,引入 Built-in Thinking 处理视觉推理
每一代都有明确的工程目标,没有任何一代是”小修小补”。这是 Qwen 多模态全家桶战略最关键的执行力体现。
八、与 DeepSeek-VL / Janus 横向对比
把 Qwen-VL 与 DeepSeek 的多模态分支对比(Q1 序章 里我提到过这条对照线):
| 维度 | Qwen-VL 系列 | DeepSeek-VL 系列 + Janus |
|---|---|---|
| 迭代节奏 | 4 代(2023-08 → 2025-11)· 与主线同步 | 2 代 DeepSeek-VL + 2 代 Janus · 与主线异步 |
| 多模态融合 | M-RoPE 统一 token 空间 | DeepSeek-VL: 双 encoder · Janus: 理解/生成解耦 |
| 长视频 | 小时级 | 主要短视频 |
| Visual Grounding | 像素级 | 中等 |
| 文档 OCR | 强 | 中等 |
| 生成能力 | 仅理解(生成留给 Omni) | Janus 做理解 + 生成统一 |
| 工程定位 | 全家桶 | 探索性 / 研究导向 |
核心差异:
- Qwen-VL 选了”产品级开源全家桶 + 与主线同步”路线——多模态能力广度全部覆盖
- DeepSeek-VL + Janus 选了”探索研究 + 单点创新”路线——Janus 的”理解+生成统一” 是 DeepSeek 多模态最有创意的设计(详见 W11 Janus 详解),但产品矩阵覆盖比 Qwen 窄
这种”两条路径互补”的格局延续到 2025-11 仍然成立——Qwen 偏产品落地,DeepSeek 偏架构探索。
九、Qwen-VL 在主线里的位置
Qwen-VL 不只是”多模态分支”,它对整个 Qwen 主线有三个反向影响:
反向影响 ①:M-RoPE → TMRoPE → Qwen2.5-Omni Qwen2-VL 的 M-RoPE 启发了 Qwen2.5-Omni 的 TMRoPE(再加音频维度),是 Omni 全模态架构的位置编码基础。
反向影响 ②:Naive Dynamic Resolution → Token budget 管理 Qwen2-VL 的”任意分辨率 + 动态 token 数”工程经验,后来被 Qwen 主线用于 long-context 管理——动态 token budget 是 Qwen-3 / Qwen-3.5 的 DCA 设计的思想源头之一。
反向影响 ③:Visual Grounding + OCR → Agent 能力底座 Qwen2.5-VL 的精确 grounding 和 OCR 能力,是 Qwen-3.7-Max 的”agent-first” 设计的视觉基础——GUI agent 需要精确点击坐标、文档 agent 需要 OCR + 版面理解。
Qwen-VL 系列对 Qwen 主线的反向贡献比表面看起来大得多——很多通用 LLM 主线的工程哲学其实是从 VL 分支演化过来的。
十、写在最后:Qwen-VL 给我们的启示
Qwen-VL 系列四代演进最值得思考的不是某一个技术点,而是 Qwen 团队对”多模态优先级”的工程判断。
2023-08 当大部分开源 LLM 团队还在专注通用 LLM 时,Qwen 选了”VL 与主线同月发布”。这个判断从产品角度看是激进的——多模态训练复杂度高、用户基数小、商业回报不明确。但从长期工程价值看,这个早期投入给后来 Qwen-2.5-Omni / Qwen3.5-Omni 这些”业界领先的全模态模型”留出了 18 个月的领先窗口。
理解这个长期主义判断,也就理解了为什么 Qwen 主线能从 2023 到 2026 持续在多模态维度引领——多模态不是”通用 LLM 训完之后再做”,而是 day 1 就该并行做。这条工程哲学在 2025-2026 frontier 模型(Claude 3.7 / GPT-5)也都得到了验证。
下一篇 Q8 Qwen-Audio 系列详解(撰写中):从 2023-11 Qwen-Audio(arXiv:2311.07919)到 2024-07 Qwen2-Audio(arXiv:2407.10759),讲 Qwen 在音频理解(speech / 自然声 / 音乐)上的统一架构演进。Qwen-Audio 与 Qwen-VL 类似但不同——它是 Qwen 全模态战略的另一根支柱。
参考资料
- Bai et al., Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond, arXiv:2308.12966, 2023. <https://arxiv.org/abs/2308.12966>
- Wang et al., Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution, arXiv:2409.12191, 2024. <https://arxiv.org/abs/2409.12191>
- Bai et al., Qwen2.5-VL Technical Report, arXiv:2502.13923, 2025. <https://arxiv.org/abs/2502.13923>
- Qwen Team, Qwen3-VL Release Notes, Alibaba Cloud Blog, 2025-11.
- Su et al., RoFormer: Enhanced Transformer with Rotary Position Embedding, arXiv:2104.09864, 2021. <https://arxiv.org/abs/2104.09864>
- yudonglee, DeepSeek-VL 详解, <https://yudonglee.me/deepseek-vl-explained/>
- yudonglee, Janus 详解(V1 + Pro), <https://yudonglee.me/deepseek-janus-explained/>
- yudonglee, Qwen-2.5 / 1M 详解(本系列 Q4), <https://yudonglee.me/qwen-2-5-explained/>
![]()
发表回复