
转载本文请注明出处:https://yudonglee.me/qwen-2-explained/ | 作者:yudonglee

本文是 Qwen 论文专题系列 第三篇。2024 年 6 月,通义实验室发布 Qwen-2(arXiv:2407.10671)。表面上看这是一次”常规升级”——版本号从 1.5 到 2,size 矩阵小幅扩展。但这一代实际上做了两件影响 Qwen 整条主线的事情:(1) GQA 全 size 化——把 Grouped-Query Attention 从”只在大 size 用”推到 0.5B 到 72B 七档全部用,统一推理引擎;(2) 第一次 MoE 尝试——57B-A14B 模型,14B 激活参数对标 70B dense 性能。两件事叠加起来,意味着 Qwen 完成了从”开源精品”到”全 size 矩阵 + 工业级 MoE 旗舰”的范式转换。
一、引言:Qwen-2 在主线里的位置
如果把 Qwen 主线画成一条线:
Qwen-1 (2023-08) → Qwen-1.5 (2024-02) → [ Qwen-2 (2024-06) ] → Qwen-2.5 (2024-09) → Qwen-3 (2025-04)
开山之作 升级版 关键一跳 规模化 Thinking ModeQwen-2 在这条线上的角色既不是”开山”(那是 Qwen-1)也不是”集大成”(那是 Qwen-2.5 / 3),它是“工程范式定型”的那一代——把 Qwen-1 时代的探索性选择固化成”以后每一代都这么做”的标准件:
- GQA 不再是大模型独享——所有 size 默认 GQA,不再混用 MHA / GQA
- MoE 不再是研究 demo——57B-A14B 成为 Qwen 第一个工业级 MoE 旗舰
- 长上下文不再是工程 hack——YaRN-style 扩展成为官方 supported 配置
- 训练数据从 3T → 7T——数据规模 2.3× 扩展,27 种语言均衡覆盖
- 后训练从 PPO → DPO——RLHF 范式从 reward model + PPO 转向直接偏好优化
Qwen-2 这一代的”创新密度”看起来不如 Qwen-2.5(DCA)或 Qwen-3(Thinking Mode)——但它把 Qwen-1 时代的所有”对的方向”全部一次性兑现。读懂 Qwen-2,你才能理解为什么 Qwen-2.5 / 3 可以走得那么稳。
二、论文基本数据
| 维度 | Qwen-2 |
|---|---|
| 论文 | Qwen2 Technical Report(arXiv:2407.10671) |
| 发布时间 | 2024-06-07 |
| 模型 size | 0.5B / 1.5B / 7B / 57B-A14B (MoE) / 72B |
| 训练 tokens | 7T(72B 主模型)· MoE 模型 4.5T |
| 架构 | decoder-only · GQA 全 size · RoPE base=1e6 · RMSNorm · SwiGLU |
| Tokenizer | 沿用 Qwen-1 的 151K BPE(未做大改) |
| 上下文 | 训练 32K · YaRN 推理时扩到 128K |
| 后训练 | SFT + DPO(替代 PPO) |
| 多语言 | 29 种语言(Qwen-1 覆盖约 10 种) |
| 开源协议 | Apache 2.0(除 72B 用 Tongyi Qianwen License) |
放在 2024 年 6 月这个时间点对比:
- 同期 LLaMA-3-8B(2024-04)训了 15T tokens(中英文混合)
- DeepSeek-V2(2024-05)236B-A21B,MLA + DeepSeekMoE
- Qwen-2-72B 训了 7T tokens(中英文 + 多语言均衡)
Qwen-2-72B 在英文 benchmark 上略弱于 LLaMA-3-70B(数据量差距),但在中文 + 多语言 benchmark 上反超——这是 Qwen-1 时代就埋下的 tokenizer + 中文数据配比优势的延续。
三、整体架构:与 Qwen-1 的对照
Qwen-2 的整体架构和 Qwen-1 高度一致:
Input tokens
│
▼
Embedding (untied) ─────────────── 沿用 Qwen-1 · 151K 词表
│
▼
┌──────────────────────────────────────────────────┐
│ Transformer Block × N │
│ RMSNorm │
│ ├── GQA Self-Attention ◄── 改动 ①:全 size GQA │
│ │ · num_kv_heads = num_q_heads / 4 ~ 1 │
│ │ · RoPE base = 1e6 │
│ ├── Add & RMSNorm │
│ ├── SwiGLU FFN ─ OR ─ ◄── 改动 ②:57B MoE │
│ │ MoE Layer: │
│ │ Top-2 routing · 60 experts · 1 shared │
│ └── Add │
└──────────────────────────────────────────────────┘
│
▼
Final RMSNorm
│
▼
Linear → Logits (lm_head, untied)继承自 Qwen-1: – Untied embeddings(input / output 解绑) – 151K BPE tokenizer – RoPE base = 1e6 – Pre-Norm + RMSNorm + SwiGLU – 主体 decoder-only Transformer
Qwen-2 的两个核心改动: 1. GQA 推广到所有 size(Qwen-1 是部分层 GQA、部分 MHA 混用) 2. 第一次 MoE 尝试(57B-A14B)
接下来逐个看。
四、关键创新 1:GQA 全 size 化
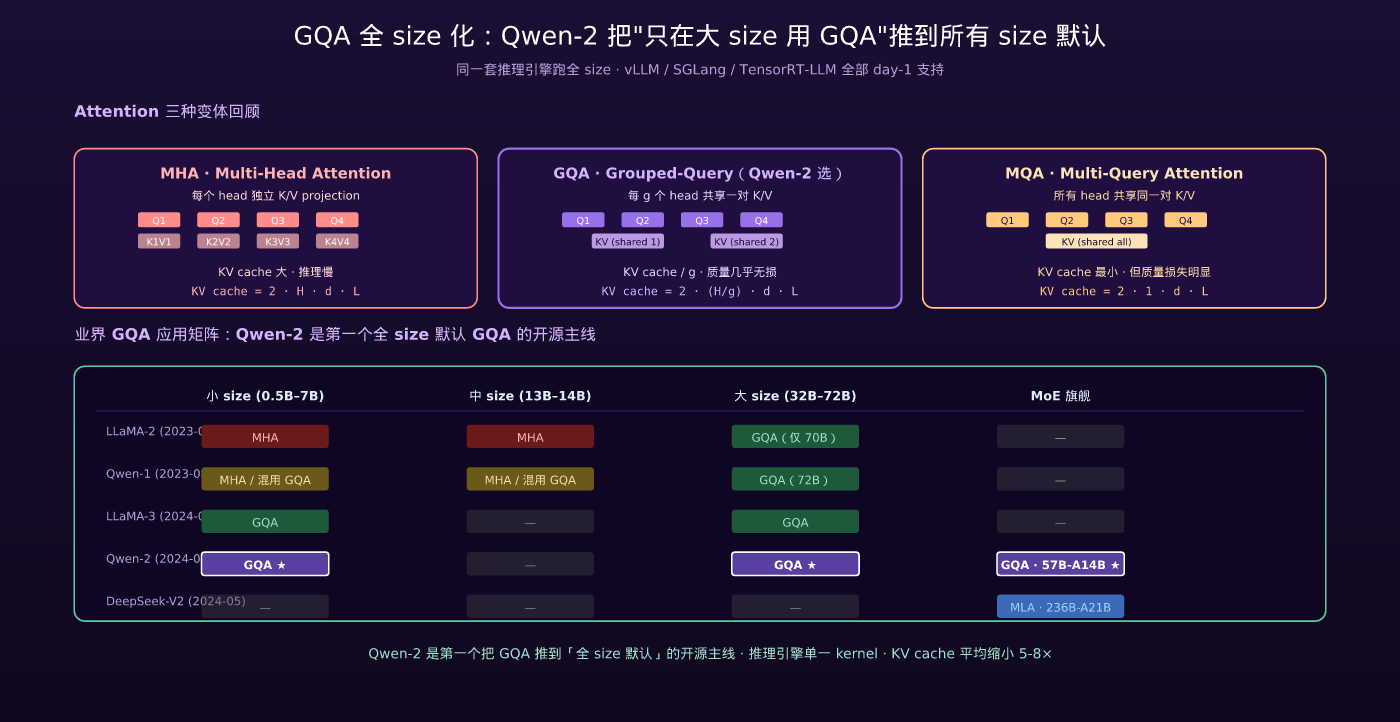
4.1 复习 GQA 是什么
Grouped-Query Attention(GQA)由 Ainslie et al. (2023) 提出,是 MHA 和 MQA 之间的折中:
- MHA (Multi-Head Attention):每个 head 有独立的 Q / K / V projection
- MQA (Multi-Query Attention):所有 head 共享同一对 K / V projection
- GQA:head 分组,每 g 个 head 共享一对 K / V projection

其中 H 是 head 总数,d_h 是每 head 维度,L 是序列长度。
效果:KV cache 缩小 g 倍(不损失明显质量),推理吞吐显著提升,长上下文场景显存压力大幅缓解。
4.2 Qwen-2 的取舍:所有 size 都用 GQA
LLaMA-2 的 GQA 策略是只在 70B 用(7B / 13B 还是 MHA);Qwen-1 也是部分层 GQA、部分 MHA 混用。这种”按 size 分层”的设计在工程上是个负担——同一套推理引擎要适配两种 attention 类型,量化 / 部署都要分别测试。
Qwen-2 选了“所有 size 一律 GQA”:
| Size | Q heads | KV heads | 分组数 g |
|---|---|---|---|
| 0.5B | 14 | 2 | 7 |
| 1.5B | 12 | 2 | 6 |
| 7B | 28 | 4 | 7 |
| 57B-A14B | 28 | 4 | 7 |
| 72B | 64 | 8 | 8 |
对推理引擎的好处:vLLM / SGLang / TensorRT-LLM 上 Qwen-2 是”同一套 kernel 跑全 size”——这是 Qwen-2 之后 Qwen 主线工程稳定性的关键来源。
4.3 代价:小模型是否过度节省了?
学界曾质疑:0.5B / 1.5B 这种小模型,KV cache 本来就不大,GQA 的”节省”是不是没必要、反而损失质量?
Qwen-2 论文的消融实验给出了答案:在 0.5B 和 1.5B 上,MHA vs GQA 的 PPL 差距 < 0.1,但 GQA 在长上下文(>16K)场景吞吐快 30-40%。结论:全 size GQA 在质量上几乎无损,工程收益巨大。
4.4 GQA 全 size 化对 Qwen 主线的长期影响
Qwen-2 之后,所有 Qwen 模型默认 GQA:
- Qwen-2.5(2024-09):继续全 size GQA
- Qwen-3(2025-04):dense + MoE 双轨,仍然 GQA
- Qwen-3.5(2026-02):Hybrid Linear Attention 一部分用 Gated DeltaNet 替代 GQA,但保留的 attention 层仍是 GQA
可以说,GQA 是 Qwen-2 留给整条主线的”标准件”——和 LLaMA-2 留给业界的 RMSNorm / SwiGLU 一样重要。
五、关键创新 2:第一次 MoE 尝试(Qwen-2-57B-A14B)

5.1 为什么 Qwen-2 要做 MoE?
2024 年上半年开源 LLM 圈最大的趋势就是 MoE 化:
- Mixtral 8x7B(2023-12)证明 sparse MoE 在工业级开源里可行
- DeepSeek-V2(2024-05)236B-A21B 用 DeepSeekMoE + MLA,把 MoE 推到中国开源旗舰
- Qwen-2-57B-A14B(2024-06)是 Qwen 系列的第一次 MoE 尝试
Qwen 加入 MoE 赛道的动机:性能/激活参数比。Qwen-2-57B-A14B 用 14B 激活参数(比 72B 少 80%),性能接近 72B dense——这意味着推理算力可以省下 5×,部署成本更低。
5.2 Qwen-2 MoE 的设计
Qwen-2-57B-A14B 的 MoE 配置:
| 维度 | Qwen-2-57B-A14B | DeepSeek-V2-236B-A21B |
|---|---|---|
| 总参数 | 57B | 236B |
| 激活参数 | 14B | 21B |
| 激活比例 | 24.6% | 8.9% |
| Expert 数量 | 60 | 162 |
| 共享 Expert | 1 个 | 2 个 |
| Top-k | Top-2 | Top-6 |
| Routing | 标准 noisy top-k | DeepSeekMoE (fine-grained) |
| Aux loss | 标准 load balancing | DeepSeekMoE 双重 aux loss |
关键设计取舍:
- 激活比例偏高(24.6%):远高于 DeepSeek-V2 的 8.9%。Qwen-2 用”较少但较大的 expert”,每个 expert 容量更大;DeepSeek-V2 用”更多但更细的 expert”。
- Top-2 routing:每个 token 只激活 2 个 expert(DeepSeek-V2 是 Top-6)。Routing 决策更稀疏,推理 latency 更稳定。
- 1 个共享 expert:所有 token 都过这个 expert,承担”通用语言模式”的学习;剩下 59 个 expert 处理”特化模式”。
- 沿用标准 load balancing:用最经典的 auxiliary loss(DeepSeek-V2 后来发明的 aux-loss-free 是 2024-08 的 paper,Qwen-2 时间上来不及用)。
5.3 实际性能
Qwen-2-57B-A14B 在 benchmark 上的表现(对比 dense 模型):
| 评测 | Qwen-2-57B-A14B (14B 激活) | Qwen-2-72B (72B dense) | 差距 |
|---|---|---|---|
| MMLU | 76.5 | 84.2 | -7.7 |
| HumanEval | 53.0 | 64.6 | -11.6 |
| GSM8K | 80.7 | 89.5 | -8.8 |
| C-Eval | 80.4 | 83.1 | -2.7 |
| 推理算力 / token | 14B FLOPs | 72B FLOPs | 5.1× 节省 |
观察:Qwen-2-57B-A14B 用 14B 激活参数达到 Qwen-2-72B 80-90% 的性能,但推理算力只要 1/5。这个性价比在 ToB 部署场景非常有吸引力。
但代价是总参数 57B 还是要全部加载到显存——这对端侧 / 中小企业部署是个门槛。这也是为什么 Qwen-2.5 / Qwen-3 在小 size 上仍然以 dense 为主,MoE 只用于 frontier 旗舰。
5.4 MoE 在 Qwen 主线的演化
Qwen-2-57B-A14B 是 Qwen MoE 的”试水之作”。后续演化:
Qwen-2 (2024-06)
57B-A14B ← 第一次 MoE
60 experts ← 较少 expert
Top-2 ← 稀疏 routing
24.6% 激活率 ← 激活比例偏高
│
▼
Qwen-3 (2025-04)
30B-A3B ← 端侧 MoE
235B-A22B ← 旗舰 MoE
128 experts ← 更细粒度
Top-8 ← 更密集 routing
~9% 激活率 ← 接近 DeepSeek 路线
│
▼
Qwen-3.5 (2026-02)
397B-A17B ← Hybrid MoE
+ Hybrid Attn ← Gated DeltaNet × Full
4.3% 激活率 ← 最激进的稀疏每一代 Qwen MoE 都在朝更稀疏(激活比例下降)、更细粒度(expert 数增加)、更复杂的 attention 配合(GQA → Hybrid GDN)演化。Qwen-2-57B-A14B 是这条线的起点。
六、关键创新 3:YaRN-style 长上下文官方支持
6.1 Qwen-1 时代的长上下文是”工程 hack”
Qwen-1 的长上下文(8K → 32K)靠”三件套”——NTK-aware 插值 + LogN-scaling + Windowed Attention。这套是推理时的临时增强,不是训练时官方支持:
- 训练只用 2K 上下文
- 推理时启用三件套强行扩展
- 长上下文质量随长度递减明显
6.2 Qwen-2 的官方做法
Qwen-2 把长上下文做成训练时一等公民:
- 训练阶段就用 32K 上下文(不再 2K)
- 训练阶段的 RoPE 仍然用 base=1e6(沿用 Qwen-1)
- 推理时启用 YaRN(Yet another RoPE extensioN)把 32K 扩到 128K
- 保留 Dual Chunk Attention 的雏形——长上下文场景启用 chunked attention,但还不是 Qwen-2.5 的成熟 DCA
YaRN 是一个比 NTK-aware 更精致的 RoPE 插值方法(参见原论文 Peng et al., 2023),核心思路:

其中 s 是上下文扩展倍数,α_i 是按维度 i 的渐变插值因子。
效果(Qwen-2 论文 Table 5):
| 上下文 | Qwen-1 (三件套推理) | Qwen-2 (YaRN 官方) |
|---|---|---|
| 8K | PPL ≈ 4.2 | PPL ≈ 3.7 |
| 32K | PPL ≈ 5.5 | PPL ≈ 4.0 |
| 128K | 不支持 | PPL ≈ 4.8 |
Qwen-2 在 32K 的 PPL 比 Qwen-1 低 27%,且支持到 128K。这是从”hack 出来的长上下文”到”训练时设计的长上下文”的范式转变。
6.3 长上下文路线的延续
- Qwen-2.5(2024-09):DCA(Dual Chunk Attention)正式登场,把 YaRN 升级为 chunked attention 的二阶 mapping,推理时支持 1M 上下文
- Qwen-3.5(2026-02):Hybrid Linear Attention 进一步降低长上下文 decode 复杂度从 O(N²) 到 O(N)(线性 attention 主导,full attention 占 1/4)
Qwen-2 是从”工程 hack 长上下文”到”训练设计长上下文”的拐点。
七、训练数据:7T tokens 与多语言扩展
7.1 数据规模翻倍
| 数据维度 | Qwen-1-72B | Qwen-2-72B | 提升 |
|---|---|---|---|
| 总 tokens | ~3T | 7T | 2.3× |
| 中文 tokens | ~0.9T (30%) | ~2.1T (30%) | 2.3× |
| 英文 tokens | ~1.5T (50%) | ~3.5T (50%) | 2.3× |
| 代码 tokens | ~0.3T (10%) | ~0.7T (10%) | 2.3× |
| 多语言 tokens | ~0.15T (5%) | ~0.7T (10%) | 4.7× |
| 数学 tokens | ~0.15T (5%) | ~0.35T (5%) | 2.3× |
观察:多语言数据扩展 4.7×——这是 Qwen-2 全球化战略的关键举措。Qwen-1 主要覆盖中英文 + 几个欧洲语言;Qwen-2 把覆盖扩到 29 种语言(含阿拉伯语、印地语、越南语、泰语、印尼语等)。
7.2 数据质量控制升级
Qwen-2 论文里详细描述了数据 pipeline 的几个升级:
- classifier-based filtering:训练一个轻量 classifier 给每条数据打”教育价值”分数,低分数据剔除
- N-gram 重叠去重:MinHash + LSH 在更大规模上做近似重复检测
- 逐 epoch 数据混合调整:训练后期逐步提升高质量数据(书籍、论文)占比,低质量数据(网页 boilerplate)占比下降
- 多语言数据采样平衡:用 temperature sampling 让小语种不被英文淹没
这套数据 pipeline 在 Qwen-2.5(2024-09)扩展到 18T tokens 时基本沿用,是 Qwen 数据工程的”成熟版”。
八、后训练:DPO 取代 PPO
8.1 RLHF 范式转变
Qwen-1 用的是经典 RLHF:训练 Reward Model → PPO 优化。这套流程在 InstructGPT / ChatGPT 时代是标准答案,但有几个工程痛点:
- Reward model 训练贵:要单独训一个大模型
- PPO 训练不稳定:超参敏感,发散风险高
- 样本利用率低:每条数据要采 4 个 response 算 reward
2023 年底 Rafailov et al. 提出 DPO(Direct Preference Optimization):
![\mathcal{L}_{\text{DPO}} = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma\left( \beta \log \frac{\pi_\theta(y_w | x)}{\pi_{\text{ref}}(y_w | x)} - \beta \log \frac{\pi_\theta(y_l | x)}{\pi_{\text{ref}}(y_l | x)} \right) \right]](https://yudonglee.me/wp-content/ql-cache/quicklatex.com-711b9f3b672dca24580f85808fec4ef0_l3.png "Rendered by QuickLaTeX.com")
其中 (y_w, y_l) 是同一 prompt 下的胜出 / 失败 response,π_θ 是被优化的模型,π_ref 是参考模型。
DPO 的核心是绕过显式 reward model,直接用偏好对优化策略——一个模型而非两个、一个 loss 而非 reward + PPO 两阶段。
8.2 Qwen-2 用 DPO 的细节
Qwen-2 的后训练 pipeline:
SFT (1-2M instruction pairs)
│
▼
DPO (大规模偏好对:人类标注 + 模型自助标注)
│ · 人类标注约 100K 对
│ · 模型自助标注约数百万对
│
▼
Qwen-2-Chat关键工程细节:
- 不用 reward model(这是 DPO 的主要卖点)
- β = 0.1(DPO 论文推荐值)
- 学习率 5e-7(比 SFT 低一个数量级,避免遗忘)
- 混合多任务:偏好对覆盖 helpfulness / safety / coding / math / reasoning 五个方向
8.3 DPO 的代价
DPO 也不是完全的免费午餐:
- 数据质量更敏感——没有 reward model 做”质量筛子”,低质量偏好对直接喂进 DPO 会污染策略
- 难以做 process reward——DPO 本质是 outcome-based,对推理过程的细粒度奖励难以表达
- 采样多样性退化——DPO 训练后模型趋向产生”安全保守”的回答,多样性低于 PPO
这些痛点在 Qwen-3 / QwQ 时代被部分纠正——Qwen-3 又回归 PPO + GRPO 混合,PRM(process reward model)也被引入 Qwen2.5-Math。DPO 是 Qwen-2 这一代的工程选择,不是 Qwen 永恒的方向。
九、Benchmark 结果
Qwen-2 在 2024-06 发布时的 benchmark 数字(对比同期竞品):
| 评测 | Qwen-2-72B | LLaMA-3-70B | Mixtral-8x22B | DeepSeek-V2-236B-A21B |
|---|---|---|---|---|
| MMLU | 84.2 | 82.0 | 77.7 | 78.5 |
| MMLU-Pro | 55.6 | 56.2 | 50.4 | – |
| C-Eval | 83.1 | 64.2 | 53.0 | 81.7 |
| CMMLU | 84.4 | 65.7 | 53.4 | 82.1 |
| HumanEval | 64.6 | 56.7 | 50.0 | 80.0 |
| MATH | 47.5 | 41.4 | 41.7 | 43.6 |
| GSM8K | 89.5 | 87.7 | 88.7 | 88.0 |
观察: 1. 中文(C-Eval / CMMLU)大幅领先 LLaMA-3-70B——延续 Qwen-1 时代的中文优势 2. MMLU 英文综合略胜 LLaMA-3-70B——这是 Qwen 第一次在英文综合上反超 LLaMA 旗舰 3. HumanEval 代码落后 DeepSeek-V2——MoE + 代码专项数据上 DeepSeek 在 2024 年中走得更前面 4. MATH 领先所有 dense 竞品——数学数据配比 + 后训练投入的回报
整体定位:Qwen-2-72B 是 2024-06 时点中文最强开源、英文 top-tier 开源。
十、Qwen-2 是范式定型的一代
Qwen-2 的所有改动看起来都”不够激进”——没有 MLA 这种架构突破,没有 GRPO 这种 RL 范式,没有 R1 那样的 reasoning specialist。但 Qwen-2 把 Qwen-1 时代的所有”对的方向”全部一次性兑现,并定型成主线标准。
| 维度 | Qwen-1 | Qwen-2 | Qwen-2.5 之后 |
|---|---|---|---|
| GQA | 部分层用 | 全 size 默认 | 沿用 |
| MoE | 没有 | 57B-A14B 试水 | 30B-A3B / 235B / 397B 系列 |
| 长上下文 | 推理 hack(三件套) | 训练 32K + YaRN 128K | DCA / Hybrid Linear |
| 训练数据 | 3T | 7T + 29 语种 | 18T / 36T |
| 后训练 | PPO | DPO | DPO → PPO+GRPO 混合 |
| 多语言 | ~10 种 | 29 种 | 119 种 → 201 种 |
| 开源协议 | Tongyi | Apache 2.0(多数 size) | 全 Apache 2.0 |
可以看到 Qwen-2 在每一行都完成了一次工程层面的”定型”。Qwen-2 之后,Qwen-2.5 / 3 / 3.5 都是在 Qwen-2 这套标准上做更大规模、更复杂的迭代。
理解 Qwen-2 的工程哲学,是理解整条 Qwen 主线为什么能持续稳定输出的钥匙:不在某一代押注单点架构创新,而在每一代逐项把工程标准件锁定。
十一、与同期开源旗舰横向对比
把 Qwen-2 放到 2024-06 时点的开源 LLM 矩阵:
| 维度 | Qwen-2-72B | LLaMA-3-70B | DeepSeek-V2-236B | Mixtral-8x22B |
|---|---|---|---|---|
| 发布时间 | 2024-06 | 2024-04 | 2024-05 | 2024-04 |
| 总参数 | 72B dense + 57B-A14B MoE | 70B dense | 236B-A21B MoE | 8x22B MoE |
| 训练 tokens | 7T | 15T | 8.1T | 闭源 |
| Attention | GQA 全 size + YaRN | GQA + RoPE 扩展 | MLA + DeepSeekMoE | GQA |
| 长上下文 | 128K(YaRN) | 8K → 128K | 128K | 64K |
| 多模态 | Qwen-VL 同步发布 | Llama-Vision 单独 | DeepSeek-VL 同步 | 无 |
| Reasoning | 通用模型 | 通用模型 | 通用模型 | 通用模型 |
| 协议 | Apache 2.0 | LLaMA-3 community | MIT | Apache 2.0 |
| 主市场 | 中国 + 全球 | 全球 | 全球研究 + ToB | 欧洲 |
Qwen-2 的差异化定位:
- Vs LLaMA-3-70B:中文 + 多语言碾压;英文略胜或持平;多模态同步覆盖(VL 与 Qwen-2 同发)
- Vs DeepSeek-V2-236B:dense / MoE 双线(DeepSeek 只走 MoE);size 矩阵更全(DeepSeek 只一档);代码弱于 DeepSeek
- Vs Mixtral:在中文 / 多语言 / 数学 / 上下文长度上全面胜出
整体看,Qwen-2 在 2024-06 时点占据了”中文开源最强 + 全球开源前列”的位置。这个定位一直延续到 2026 年的 Qwen-3.5。
十二、写在最后:Qwen-2 给我们的启示
回过头看 Qwen-2 这篇技术报告(arXiv:2407.10671),最大的体感是:它是一篇”工程白皮书”,不是”研究突破论文”。
通义实验室没有在 Qwen-2 里炫任何”我们发明了 X”——所有的技术组件(GQA / MoE / YaRN / DPO)都是同期业界已有的。Qwen-2 做的事情是把这些成熟组件一次性、系统地、跨全 size 地集成进来。
这种”重工程、轻发明”的风格和 DeepSeek 形成强烈对比:
- DeepSeek 风格:每一代都发明新组件(MLA、GRPO、MTP、FP8、DualPipe)
- Qwen 风格:每一代都把业界标准件做到位(GQA、MoE、YaRN、DPO)
两种风格都是有效的——DeepSeek 适合 frontier research,Qwen 适合产品级开源。理解了这个差别,你也就理解了为什么 Qwen 能持续走得这么稳:它在每一代都不押注单点突破,而是稳步推进”标准件成熟度”。
下一篇 Q4 Qwen-2.5 / 1M 详解(撰写中):2024-09 发布的 Qwen-2.5 把训练数据推到 18T,引入 Dual Chunk Attention(DCA)实现推理时 1M 上下文。Qwen 长上下文路线从”YaRN 工程扩展”升级为”chunk 内/间双层 attention 的架构原生支持”——这是 Qwen 在 attention 演化上第一个真正的原创贡献。
参考资料
- Qwen Team, Qwen2 Technical Report, arXiv:2407.10671, 2024. <https://arxiv.org/abs/2407.10671>
- Ainslie et al., GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints, arXiv:2305.13245, 2023. <https://arxiv.org/abs/2305.13245>
- Peng et al., YaRN: Efficient Context Window Extension of Large Language Models, arXiv:2309.00071, 2023. <https://arxiv.org/abs/2309.00071>
- Rafailov et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model, NeurIPS 2023. <https://arxiv.org/abs/2305.18290>
- Jiang et al., Mixtral of Experts, arXiv:2401.04088, 2024. <https://arxiv.org/abs/2401.04088>
- DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, arXiv:2405.04434, 2024. <https://arxiv.org/abs/2405.04434>
- Meta AI, The Llama 3 Herd of Models, arXiv:2407.21783, 2024. <https://arxiv.org/abs/2407.21783>
- yudonglee, Qwen-1 详解(本系列 Q2), <https://yudonglee.me/qwen-1-explained/>
![]()
发表回复