
转载本文请注明出处:https://yudonglee.me/qwen-3-explained/ | 作者:yudonglee

本文是 Qwen 论文专题系列 第五篇。2025-04 通义实验室发布 Qwen-3 模型权重,2025-05 上传技术报告(arXiv:2505.09388)。这一代是 Qwen 主线对 reasoning 范式的第一次主线级响应——但 Qwen 没有选择 DeepSeek-R1 那种”独立 reasoning specialist”路线,而是做了 Built-in Thinking Mode:同一个模型内置
/think(long-CoT 推理路径)和/no_think(快速回答路径)双模式,用户通过 prompt 标签切换。同时 Qwen-3 把 MoE 升级到了 128 experts + Top-8 routing 的细粒度版本,端侧的 30B-A3B 与旗舰的 235B-A22B 双轨发布——这是 Qwen MoE 路线从 Qwen-2 试水之后的回归与全面升级。
一、引言:Qwen-3 的两条主线和一个分水岭
Qwen-3 这一代有三件大事:
- Built-in Thinking Mode:通用模型内嵌 reasoning 能力,与 R1 specialist 路线形成鲜明对照
- MoE 全面升级回归:30B-A3B(端侧)+ 235B-A22B(旗舰)双轨,128 experts + Top-8,9% 激活率
- 训练数据再翻倍到 36T tokens:Qwen-3 训练数据是 Qwen-1 的 12 倍、Qwen-2.5 的 2 倍
这三件事每一件都值得展开,但其中 Built-in Thinking Mode 是 Qwen 主线对 2024-2025 整个开源 LLM 圈”reasoning 模型独立化”趋势的最重要回应。
把 Qwen-3 放到 2025 年开源 reasoning 模型生态里看:
DeepSeek 路线:
V3 通用 (2024-12) → R1 reasoning specialist (2025-01) → R2 (2025+)
独立 endpoint · 用户必须切换 · 多阶段 SFT + RL
Qwen 路线:
Qwen-2.5 通用 (2024-09) → QwQ-32B-Preview specialist (2024-11) →
Qwen-3 通用 + 内嵌 thinking (2025-04) ★
单一 endpoint · prompt 标签切换 · 多任务联合 SFT + RL
LLaMA 路线:
Llama-3.x (2024-2025) → 无独立 reasoning specialist 发布可以看到,Qwen-3 选了一条与 DeepSeek 截然相反的工程路径——把 reasoning 做成通用模型的”可选行为”,而不是独立产品。这条路线后来被 Claude 3.7(hybrid reasoning)借鉴,成为 2025 下半年主流 frontier 模型的设计模式之一。
二、论文基本数据
| 维度 | Qwen-3 |
|---|---|
| 论文 | Qwen3 Technical Report(arXiv:2505.09388) |
| 发布时间 | 2025-04(模型权重)· 2025-05(paper) |
| Dense size | 0.6B / 1.7B / 4B / 8B / 14B / 32B(六档 dense) |
| MoE size | Qwen3-30B-A3B(端侧 MoE)· Qwen3-235B-A22B(旗舰 MoE) |
| 训练 tokens | 36T(vs Qwen-2.5 的 18T,2× 扩展) |
| 架构 | decoder-only · GQA · RoPE base 动态调整 · RMSNorm · SwiGLU · MoE in 30B / 235B |
| Tokenizer | 沿用 151K BPE(扩展 thinking tag + agentic tag) |
| 上下文 | 训练 32K · DCA 推理时扩到 128K-1M |
| 后训练 | SFT + PPO + GRPO 混合(DPO 不再是主路) |
| 多语言 | 119 种语言(vs Qwen-2.5 的 29 种,4× 扩展) |
| 开源协议 | Apache 2.0 |
| 关键新机制 | Built-in Thinking Mode(/think vs /no_think) |
放到 2025-04 时点对比:
| 维度 | Qwen-3-235B-A22B | DeepSeek-V3 (671B-A37B) | DeepSeek-R1 (specialist) | Llama-4 |
|---|---|---|---|---|
| 总参数 | 235B | 671B | 671B (R1) | 400B+ |
| 激活参数 | 22B | 37B | 37B | dense |
| Thinking 路线 | 内嵌双模式 | 通用 | 独立 specialist | 较弱 |
| 训练 tokens | 36T | 14.8T | 14.8T 基础 + RL | ~15T |
| 上下文 | 128K(DCA 可扩 1M) | 128K | 128K | 128K-1M |
| MoE 配置 | 128 experts · Top-8 | DeepSeekMoE 细粒度 | 同 V3 | 部分 size MoE |
Qwen-3 在 2025-04 时点的差异化定位:唯一同时提供”全 size dense 矩阵 + 内嵌 reasoning + 端侧 MoE + 旗舰 MoE”的开源模型家族。
三、整体架构:dense + MoE 双轨
Qwen-3 是 Qwen 主线第一次正式确立 dense + MoE 双轨:
Dense 主线(6 档):
Qwen3-0.6B / 1.7B / 4B / 8B / 14B / 32B
· 全 size GQA(继承 Qwen-2 标准件)
· RoPE base 动态调整
· 沿用 DCA 长上下文机制
· 端侧 → 工业级单卡部署
MoE 主线(2 档):
Qwen3-30B-A3B(端侧 MoE 旗舰)
Qwen3-235B-A22B(旗舰 MoE)
· 128 experts + Top-8 routing ← 全面升级
· ~9% 激活率 ← 接近 DeepSeek 路线
· DCA + RoPE base 1e7两个 MoE 模型的设计哲学:
- Qwen3-30B-A3B:3B 激活参数 + 30B 总参数 = 端侧 MoE。这是 Qwen 第一次把 MoE 推到端侧 / 移动 GPU 场景——A100 单卡可跑、推理算力只要 3B FLOPs/token
- Qwen3-235B-A22B:22B 激活 + 235B 总参数 = 旗舰 MoE。对标 DeepSeek-V3(671B-A37B),但参数规模只有 1/3、激活更精简
下面分别看三个核心改动。
四、关键创新 1:Built-in Thinking Mode
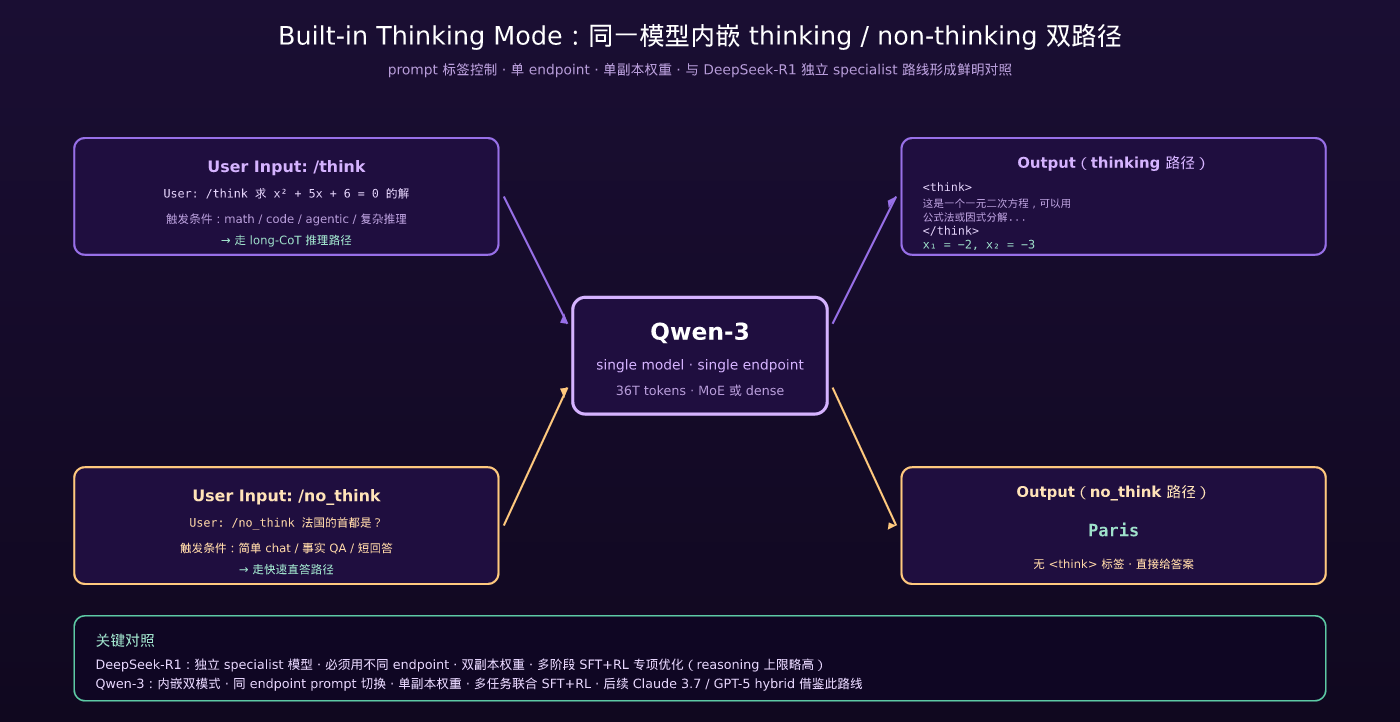
4.1 业界两种 reasoning 模型路线
2024-11 OpenAI 发布 o1,开启了”reasoning model”赛道。到 2025-04 业界已经形成两条明显不同的路径:
路线 A:Reasoning Specialist(DeepSeek 选) – 训练一个独立的 reasoning specialist 模型(R1 / R2) – 与通用模型分别发布、分别 finetune、分别 deploy – 用户必须显式选择走通用 endpoint 还是 reasoning endpoint – 优势:每条路径可以独立优化到极致 – 劣势:用户体验割裂、deployment 复杂
路线 B:Hybrid / Built-in Thinking(Qwen-3、Claude 3.7 选) – 同一个模型内置 thinking / non-thinking 双行为 – 通过 prompt 控制路径(/think 或 /no_think) – 用户 endpoint 单一、切换成本零 – 优势:deployment 简单、不需要双副本权重 – 劣势:双任务训练复杂、单 size 的纯 reasoning 上限略低于 specialist
4.2 Qwen-3 的 prompt 接口
Qwen-3 提供两种调用方式:
/think 模式:模型走 long-CoT 推理路径,输出格式为 <think> ... </think> 包裹的思考过程 + 最终答案。
/no_think 模式:模型走快速回答路径,直接给出答案,不输出思考过程。
默认行为可以在 system prompt 里配置——简单 chat 默认 /no_think、agentic / 数学 / 代码任务默认 /think。
4.3 训练范式:multi-task 混合 SFT + RL
要让一个模型同时具备”显式思考”和”快速回答”两种行为,训练阶段必须做 multi-task 联合优化。Qwen-3 的训练 pipeline:
Stage 1: Pre-train (36T tokens, 通用语料 + 代码 + 数学 + 多语言)
│
▼
Stage 2: Long-CoT SFT
· 训练数据:~70% 普通对话 + ~30% 带 <think>...</think> 标签的 reasoning 轨迹
· 模型学会"看到 /think 标签时输出思考过程"
│
▼
Stage 3: Reasoning RL (Math + Code 数据)
· 用 PPO + GRPO 混合优化 reasoning 路径
· 同时对 /no_think 路径做安全 + 流畅度对齐
│
▼
Stage 4: General RL(人类偏好 + safety)
· 双模式分别对齐
│
▼
Qwen-3 (with built-in thinking)关键工程细节:
- SFT 数据混合比 70:30:70% 普通对话保证通用能力不掉,30% reasoning 轨迹建立 thinking 行为
- PPO + GRPO 混合 RL:PPO 处理通用偏好,GRPO(DeepSeek-R1 同款)处理 reasoning 任务
- 双模式 reward:训练时对 thinking 和 non-thinking 输出各自计算 reward,两路独立优化
4.4 Qwen-3 vs DeepSeek-R1 对比
| 维度 | DeepSeek-R1 (specialist) | Qwen-3 (built-in thinking) |
|---|---|---|
| 模型数量 | 单独的 reasoning specialist | 通用模型内嵌 reasoning |
| 用户切换 | 必须用不同 endpoint | 同一 endpoint,prompt 标签控制 |
| 训练范式 | 多阶段 SFT + RL(专项优化) | 多任务联合 SFT + RL |
| Long-CoT 长度 | 通常更长(专门优化) | 可配置,平均略短 |
| 通用对话能力 | 略弱(专注 reasoning) | 强(双模式都覆盖) |
| 部署成本 | 双副本权重 | 单副本权重 |
| Deployment 复杂度 | 高 | 低 |
Qwen-3 这种”通用 + reasoning 一体化”路线后来被 Claude 3.7(hybrid reasoning)借鉴——这是 Qwen 主线第一次在工程哲学上”被业界跟随”。
4.5 Built-in Thinking 在 Qwen 主线后续的延续
Qwen-3 之后,Built-in Thinking 成为 Qwen 通用模型的固定配置:
- Qwen-3.5(2026-02):Hybrid Linear Attention 上的 thinking 模式
- Qwen-3.7-Max(2026-05):native extended-thinking,进一步把 thinking 长度可控化
这条路线最终走向”thinking 是模型的内置特性,不是独立产品”的工程定型。
五、关键创新 2:MoE 从 Qwen-2 试水到全面升级
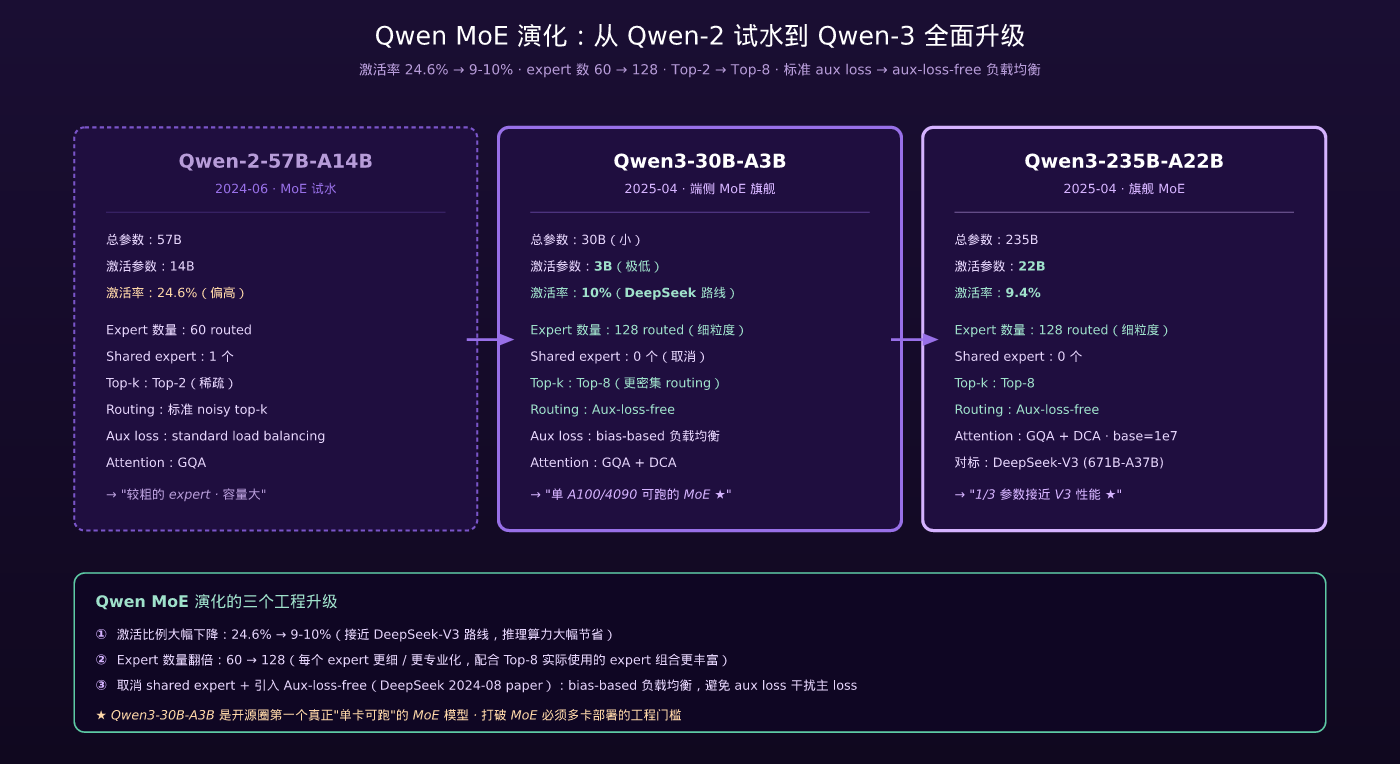
5.1 Qwen-2 → Qwen-3 MoE 升级一览
| 维度 | Qwen-2-57B-A14B | Qwen3-30B-A3B | Qwen3-235B-A22B |
|---|---|---|---|
| 总参数 | 57B | 30B | 235B |
| 激活参数 | 14B (24.6%) | 3B (10%) | 22B (9.4%) |
| Expert 数量 | 60 | 128 | 128 |
| 共享 Expert | 1 个 | 0 个 | 0 个 |
| Top-k | Top-2 | Top-8 | Top-8 |
| Routing | 标准 noisy top-k | Aux-loss-free | Aux-loss-free |
| Attention | GQA | GQA + DCA | GQA + DCA |
三个关键升级:
升级 ①:激活比例大幅下降(24.6% → 9-10%) Qwen-3 MoE 的激活率从 Qwen-2 的 24.6% 降到 ~10%,接近 DeepSeek-V3 路线。这意味着推理算力更省、batching 更高效。
升级 ②:Expert 数量翻倍(60 → 128) 更多 expert 意味着每个 expert 容量更细、专业化更深。配合 Top-8 routing,每 token 实际使用的 expert 组合更丰富。
升级 ③:取消 shared expert + 引入 aux-loss-free Qwen-2 用 1 个 shared expert + 标准 aux loss;Qwen-3 取消 shared expert,改用 DeepSeek 2024-08 paper 提出的 Aux-loss-free 负载均衡(通过更新 expert bias 来均衡负载,避免 aux loss 干扰主 loss)。
5.2 端侧 MoE:Qwen3-30B-A3B 的设计意义
Qwen3-30B-A3B 是开源 LLM 圈第一个真正意义上的端侧 MoE:
- 3B 激活参数 = 推理算力相当于一个 3B dense 模型
- 30B 总参数 = 适合 24GB-48GB 显存的工作站 / 单 A100 卡
- 在 A100 / RTX 4090 上推理速度比 7B dense 还快
这打破了过去 MoE 模型”必须多卡部署”的工程门槛——Qwen3-30B-A3B 让中小企业 / 个人开发者也能本地跑 MoE 模型。
5.3 旗舰 MoE:Qwen3-235B-A22B 的工程取舍
Qwen3-235B-A22B vs DeepSeek-V3-671B-A37B:
- 参数规模:Qwen 是 DeepSeek 的 35%
- 激活参数:Qwen 22B 略低于 DeepSeek 37B
- 推理成本:Qwen 显著低(参数加载 + 算力都更省)
- 性能:在 MMLU / GSM8K / HumanEval 上 Qwen 与 DeepSeek-V3 相差 2-5 个百分点
Qwen 的取舍是”用更紧凑的 MoE 接近 frontier 性能”,而 DeepSeek 是”堆参数到极致”。两条路服务不同的部署预算。
六、关键创新 3:训练 pipeline 从 DPO 回到 PPO + GRPO 混合
6.1 为什么放弃 DPO
Q3 Qwen-2 详解 里我说 Qwen-2 用 DPO 替代 PPO,理由是”工程更简单 + 不需要 reward model”。Qwen-3 把这个决定推翻了——回到 PPO + 新增 GRPO 混合。
放弃 DPO 的原因,Qwen-3 paper 里给了三条:
- DPO 难以处理 process reward:reasoning 任务的奖励信号不只是”最终答案对不对”,还要看推理过程是否合理。DPO 是 outcome-based 的,对 process 表达力不足。
- DPO 多样性退化:长期用 DPO 训练,模型生成的回答越来越”安全保守”。
- GRPO 的崛起:2024 年 DeepSeek 发明 GRPO(详见 W5 DeepSeekMath 详解),证明了”群组相对奖励”在 reasoning RL 上比 PPO 更稳定、更高效。
Qwen-3 的选择:通用偏好用 PPO,reasoning 任务用 GRPO,两个分别优化、加权融合到同一个模型。
6.2 PPO + GRPO 混合训练
Reasoning data (Math + Code + Science) ──→ GRPO 优化
· group-relative reward
· 没有 critic 网络
· 更稳定、采样高效
↓
┌────────────────┐
│ 同一个模型 │
│ Qwen-3 │
└────────────────┘
↑
General data (Chat + Helpfulness + Safety) ─→ PPO 优化
· classic actor-critic
· 人类偏好 reward
· 处理通用对齐这套混合 RL 训练栈是后续 Qwen-3.5 / 3.7 持续沿用的基础。
七、训练数据:18T → 36T
Qwen-3 训练数据规模再翻 2 倍:
| 类别 | Qwen-2.5-72B | Qwen-3-235B-A22B | 提升 |
|---|---|---|---|
| 总 tokens | 18T | 36T | 2× |
| 英文 | 8.4T (47%) | ~16T (44%) | 1.9× |
| 中文 | 5.4T (30%) | ~10T (28%) | 1.9× |
| 代码 | 2.6T (14%) | ~6T (17%) | 2.3× |
| 多语言 | 1.6T (9%) | ~4T (11%) | 2.5× |
最显著的两个变化:
- 代码占比上升(14% → 17%):为 Qwen3-Coder 系列(480B 旗舰)服务
- 多语言扩展:从 29 种扩到 119 种语言,做了”长尾语言”的覆盖(如非洲语种、小语种东南亚)
数据质量管线也做了升级:
- classifier-based filtering 升级到 Qwen2.5-72B 评分(自举式质量分类)
- 代码数据补充编译器 + 单元测试反馈(CodeQwen 团队贡献)
- 数学数据补充 Lean / Coq 形式化证明(QwQ 团队贡献)
八、Qwen-3 模型矩阵全览
| Size | 类型 | 主要用途 |
|---|---|---|
| 0.6B | dense | 端侧 / IoT |
| 1.7B | dense | 移动 |
| 4B | dense | 平板 |
| 8B | dense | 消费级 GPU |
| 14B | dense | 单卡工业级 |
| 32B | dense | 多卡工业级 |
| 30B-A3B | MoE(端侧旗舰) | 单 A100 / 4090 跑得起的 MoE |
| 235B-A22B | MoE(旗舰) | 多卡集群 / 阿里云 API |
8 档模型一次性发布,覆盖从 IoT 到 frontier 全部部署场景。Qwen-3 是 Qwen 主线 size 矩阵最完整的一代——也是开源 LLM 圈第一个同时提供”6 档 dense + 端侧 MoE + 旗舰 MoE”的家族。
九、Benchmark 结果
9.1 旗舰模型对比
Qwen-3-235B-A22B(2025-04 时点)在主流 benchmark 上的表现:
| 评测 | Qwen-3-235B-A22B | DeepSeek-V3 | DeepSeek-R1 | Llama-4 (假设值) | Claude 3.7 |
|---|---|---|---|---|---|
| MMLU | 86.8 | 87.1 | – | 88.0 | 88.7 |
| MMLU-Pro | 70.4 | 72.6 | 75.8 | 73.0 | 79.0 |
| GPQA Diamond | 60.5 | 59.1 | 71.5 | 62.0 | 78.0 |
| MATH 500 | 88.4 | 87.3 | 97.3 | 85.0 | 90.0 |
| AIME 2024 | 70.3 | 39.2 | 79.8 | – | 80.0 |
| HumanEval | 88.4 | 89.6 | – | 88.0 | 92.0 |
| LiveCodeBench | 65.1 | 61.7 | 65.9 | – | 68.0 |
观察:
- MMLU 通用能力:Qwen-3 略低于 DeepSeek-V3 和 Claude 3.7(差距 1-2 个点),但已经在第一梯队
- AIME 数学竞赛(thinking 模式):Qwen-3-235B-A22B 达到 70.3%,与 DeepSeek-R1(79.8%)有差距但远超 DeepSeek-V3 通用版本(39.2%)——证明 Built-in Thinking 真的有效
- GPQA Diamond:Qwen 60.5%,弱于 R1 specialist(71.5%)但通用模型这个分数已经接近 LLaMA 旗舰
- HumanEval / LiveCodeBench 代码:与 DeepSeek 持平
核心洞察:Built-in Thinking 让 Qwen-3 通用模型在 reasoning 任务上接近 R1 specialist 的 80%-90% 性能,同时保持通用能力——这就是路线 B 的工程价值。
9.2 端侧 MoE Qwen3-30B-A3B 性能
| 评测 | Qwen3-30B-A3B | Qwen2.5-32B (dense) | Llama-3.3-70B |
|---|---|---|---|
| MMLU | 76.4 | 83.3 | 85.0 |
| MATH 500 | 74.1 | 56.0 | 65.0 |
| HumanEval | 79.3 | 81.4 | 81.0 |
| 推理算力 | 3B FLOPs/tok | 32B FLOPs/tok | 70B FLOPs/tok |
| 单卡部署 | ✅ A100/4090 | ✅ A100 | ❌ 必需多卡 |
Qwen3-30B-A3B 用 3B 激活参数达到 Llama-3.3-70B 性能的 80-90%,但推理算力只要 1/23。这是端侧 MoE 的工程胜利。
十、Qwen-3 在主线里的位置
| 维度 | Qwen-2.5 (2024-09) | Qwen-3 (2025-04) | Qwen-3.5 (2026-02) |
|---|---|---|---|
| 训练 tokens | 18T | 36T | 36T+ |
| 长上下文 | DCA 1M | DCA 优化 + base 1e7 | Hybrid Linear Attn |
| Size 矩阵 | 7 档 dense | 6 档 dense + 2 档 MoE | 同 |
| MoE | 无(57B-A14B 已弃用) | 30B-A3B + 235B-A22B | 397B-A17B Hybrid |
| Reasoning | 无主线 | Built-in Thinking Mode | 同 + 优化 |
| 后训练 | DPO 主路 | PPO + GRPO 混合 | 同 |
| 多语言 | 29 种 | 119 种 | 201 种 |
| 工程定位 | 架构原创(DCA) | Built-in Thinking + 高稀疏 MoE | Hybrid Linear Attn |
Qwen-3 完成了几个对 Qwen 主线长期至关重要的事情:
- 建立 dense + MoE 双轨:Qwen-2.5 时代纯 dense 路线在 Qwen-3 上扩展为”dense 端侧矩阵 + MoE 旗舰双轨”。这条双轨在 Qwen-3.5 / 3.7 全部沿用
- 确立 Built-in Thinking 路线:与 DeepSeek-R1 specialist 路线明确分叉。后续 Claude 3.7 / GPT-5 hybrid reasoning 都是同一条路径
- MoE 配置工业级化:从 Qwen-2 试水到 Qwen-3 全面成熟,为 Qwen-3.5 的 397B-A17B Hybrid MoE 做铺垫
- 后训练范式重组:DPO → PPO + GRPO 混合,与 reasoning 范式对齐
可以说,Qwen-3 是 Qwen 主线”架构成熟”的标志——从 Qwen-3 开始,所有后续 Qwen 模型(3.5 / 3.6 / 3.7)都是在 Qwen-3 这套基础架构上做更激进的延伸(hybrid linear attention、agent-first、闭源 frontier)。
十一、与同期 frontier 开源模型横向对比
把 Qwen-3 放到 2025-04 时点的全球 frontier 开源 LLM 矩阵:
| 维度 | Qwen-3-235B-A22B | DeepSeek-V3 + R1 | Llama-4 | Mistral Large 2 |
|---|---|---|---|---|
| 发布时间 | 2025-04 | 2024-12 / 2025-01 | 2025-04 | 2024-07 |
| 总参数 | 235B-A22B MoE | 671B-A37B | 400B+ dense | 123B dense |
| 训练 tokens | 36T | 14.8T | ~15T | 闭源 |
| Attention | GQA + DCA | MLA + DeepSeekMoE | GQA | GQA |
| MoE | 128 experts · Top-8 | DeepSeekMoE fine-grained | 部分 size | 8x22B |
| Reasoning | 内嵌 thinking 双模式 | R1 独立 specialist | 较弱 | 较弱 |
| 多模态 | VL / Audio / Omni 同步 | VL + Janus | Llama-Vision | 单独 |
| Size 矩阵 | 8 档(含端侧 MoE) | 三档 | 三档 | 三档 |
| 协议 | Apache 2.0 | MIT | community license | Apache 2.0 / 闭源 |
Qwen-3 的差异化定位:
- vs DeepSeek:Qwen 提供 hybrid reasoning + 端侧 MoE;DeepSeek 提供更激进的总参数 + reasoning specialist
- vs LLaMA-4:Qwen 的中文 + 多语言碾压;reasoning 能力远胜
- vs Mistral:全面胜出(参数规模、上下文、reasoning、多模态)
Qwen-3 在 2025-04 时点是开源 LLM 圈”全面均衡”的领导者——没有任何单点是绝对最强,但在每个维度都进入第一梯队,且部署矩阵最完整。
十二、写在最后:Qwen-3 给我们的启示
Qwen-3 这一代最值得思考的不是某个具体技术——而是 Qwen 团队对”reasoning 范式”的工程判断。
2024-11 OpenAI 发布 o1 后,开源圈面临一个战略选择:
- 跟 DeepSeek 走 specialist 路线?训练一个独立 reasoning specialist,把通用模型和 reasoning 模型分开。
- 走 hybrid 路线?通用模型内嵌 thinking 能力,单一 endpoint。
Qwen 团队选了第二条路。这个选择从产品视角是激进的——它要求把两种截然不同的行为(detailed CoT vs 直答)压进同一个模型,训练复杂度显著上升。但从长期工程价值看,hybrid 路线赢在三点:
- deployment 简单:单副本权重 + 单 endpoint
- 用户体验顺滑:不需要切换模型
- 能力可组合:thinking 行为可以与多模态 / agentic / 工具调用等其他能力自由组合
事后看,Claude 3.7(2025-02 发布)也走了 hybrid 路线,GPT-5(2025 下半年)也走了类似设计。Qwen-3 是第一个把 hybrid reasoning 推到开源主线的模型家族——这是 Qwen 主线第一次在工程哲学上引领业界。
下一篇 Q6 Qwen-3.5 详解(撰写中):2026-02 的 Qwen-3.5 把 attention 架构推到 hybrid linear(3:1 GDN + Full)· 397B-A17B 总参数 / 17B 激活、262K native context、201 语言、8.6-19× decoding 吞吐。这是 Qwen 在 attention 演化上的第三次原创——从 Qwen-2.5 DCA 到 Qwen-3.5 Hybrid Linear,覆盖完整的”长上下文 + 低复杂度推理”路线。
参考资料
- Qwen Team, Qwen3 Technical Report, arXiv:2505.09388, 2025. <https://arxiv.org/abs/2505.09388>
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, arXiv:2501.12948, 2025. <https://arxiv.org/abs/2501.12948>
- Anthropic, Claude 3.7 Sonnet: Hybrid Reasoning Model, 2025-02. <https://www.anthropic.com/news/claude-3-7-sonnet>
- DeepSeek-AI, DeepSeek-V3 Technical Report, arXiv:2412.19437, 2024. <https://arxiv.org/abs/2412.19437>
- DeepSeek-AI, Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, arXiv:2408.15664, 2024. <https://arxiv.org/abs/2408.15664>
- yudonglee, DeepSeekMath 详解(GRPO), <https://yudonglee.me/deepseekmath-explained/>
- yudonglee, Qwen-2.5 / 1M 详解(本系列 Q4), <https://yudonglee.me/qwen-2-5-explained/>
![]()
发表回复