
转载本文请注明出处:https://yudonglee.me/qwen-3-5-explained/ | 作者:yudonglee

本文是 Qwen 论文专题系列 第六篇。2026-02-16 通义实验室(彼时已并入 Alibaba Token Hub)发布 Qwen-3.5 / Qwen-3.5-Plus——这是 Qwen 主线在 attention 演化上的第三次原创跳跃:从 Qwen-2.5 的 DCA(chunk 内/间双层 attention)、Qwen-3 的 RoPE base 动态调整,演化到 Hybrid Linear Attention with Gated DeltaNet。架构上每 4 层 Transformer block 中 3 层用 Gated DeltaNet(线性 attention) + 1 层用 Full Attention(3:1 比例),配合 397B-A17B 极致稀疏 MoE,达成 8.6-19× decoding 吞吐提升 + 262K native context + 201 语言。这是 2026 年开源 LLM 在 attention 架构上最大的一次跃迁,证明 linear attention 在工业级 frontier 模型里完全可用。
一、引言:Qwen attention 演化的第三次跳跃
把 Qwen 主线 attention 演化画成一条线:
Qwen-1 (2023-08) 标准 MHA + RoPE base 1e6 + 长上下文三件套(推理 hack)
Qwen-2 (2024-06) GQA 全 size 化 + YaRN 长上下文(128K)
Qwen-2.5 (2024-09) GQA + DCA(chunk 内/间双层 attention)· 1M 推理
Qwen-3 (2025-04) GQA + DCA 优化 + RoPE base 1e7
[ Qwen-3.5 (2026-02) ] Hybrid Linear Attention: GDN × Full = 3:1 ★ 第三次原创Qwen-3.5 是 Qwen attention 演化里第三次架构原创:
- 第一次(Qwen-2.5 DCA):解决长上下文位置外推的”二阶 mapping” 设计——chunk 内/间双层、推理时无重训
- 第二次(Qwen-3 RoPE base 1e7):把长上下文 base 频率再上一个数量级
- 第三次(Qwen-3.5 Hybrid Linear Attention):把 attention 从 O(N²) 拆成 O(N) 主体 + 1/4 O(N²) 兜底——Linear attention 在 frontier 工业级开源模型里第一次成为主流路径
这一代的核心命题是:能不能用线性 attention 替代部分 full attention,达到 O(N) 的 decode 复杂度,同时不损失 frontier 性能?
答案是 Hybrid 路线——纯线性 attention 表达力损失太大,但 hybrid 异质 attention(一部分线性 + 一部分 full)可以两端兼得。Qwen-3.5 把这条路线推到了工业级 frontier 旗舰的成熟度。
二、Qwen-3.5 论文 / blog 基本数据
Qwen-3.5 在 2026-02-16 通过 Alibaba Cloud 官方博客 + HuggingFace 同时发布。没有像 Qwen-3 一样上传 arXiv 主报告(Qwen 系列 2026 年起 frontier 模型 paper 节奏放缓),但有详细的工程 blog 和 release notes。
| 维度 | Qwen-3.5 |
|---|---|
| 发布 | 2026-02-16 · Alibaba Cloud Blog + HuggingFace · Apache 2.0 |
| 模型 | Qwen-3.5 / Qwen-3.5-Plus(旗舰 397B-A17B Hybrid MoE) |
| 子尺寸 | Medium series(详见 Microsoft Foundry)+ 旗舰 397B-A17B |
| 总参数 | 397B(vs Qwen-3-235B-A22B 的 235B,1.7× 扩展) |
| 激活参数 | 17B(vs Qwen-3 的 22B,降低) |
| 激活率 | 4.3%(vs Qwen-3 的 9.4%,更稀疏) |
| Attention | Hybrid Linear Attention: GDN layer × 3 : Full attention layer × 1 |
| Tokenizer | 沿用 151K BPE + agentic tag |
| Native context | 262K(vs Qwen-3 的 128K,2× 扩展) |
| 多语言 | 201 种语言(vs Qwen-3 的 119 种,1.7× 扩展) |
| 多模态 | Native multimodal training(文本 + 图像 + 视频统一训练) |
| Reasoning | Built-in Thinking Mode(沿用 Qwen-3) |
| Decoding 吞吐 | 8.6 – 19× over Qwen-3(视模型 size 而定) |
| 训练 tokens | ~36T+(与 Qwen-3 相当,长上下文部分扩展) |
| 后训练 | PPO + GRPO 混合(沿用 Qwen-3) |
放到 2026-02 时点对比:
| 维度 | Qwen-3.5 | DeepSeek-V4 (推测) | Claude Opus 4.5 |
|---|---|---|---|
| 总参数 | 397B-A17B Hybrid | 1.6T-A49B MoE | 闭源 |
| Attention | Hybrid GDN×Full | MLA + CSA/HCA + mHC | 闭源 |
| Native ctx | 262K | 128K-1M | 200K |
| 多模态 | Native | VL + Janus | 是 |
| 开源 | Apache 2.0 | MIT | 闭源 |
| Reasoning | Built-in thinking | R2 specialist | hybrid thinking |
Qwen-3.5 在 2026-02 时点的核心突破:开源 LLM 圈第一次把 hybrid linear attention 推到 frontier 工业级——Gated DeltaNet 不再是学术 demo,而是 397B 旗舰的主体 attention 机制。
三、整体架构:Hybrid Attention + Sparse MoE

Qwen-3.5 的架构核心可以画成:
Input tokens
│
▼
Embedding (untied, 151K BPE)
│
▼
┌──────────────────────────────────────────────────────┐
│ Layer 1: Gated DeltaNet (linear attention, O(N)) │
│ Layer 2: Gated DeltaNet (linear attention, O(N)) │
│ Layer 3: Gated DeltaNet (linear attention, O(N)) │
│ Layer 4: Full Attention (GQA, O(N²)) ◄── 1/4 兜底 │
│ ────────────────────────────────────────────────────│
│ Layer 5: Gated DeltaNet (linear attention, O(N)) │
│ Layer 6: Gated DeltaNet (linear attention, O(N)) │
│ Layer 7: Gated DeltaNet (linear attention, O(N)) │
│ Layer 8: Full Attention (GQA, O(N²)) ◄── 1/4 兜底 │
│ ...(重复 N/4 次) │
│ │
│ 每一层 attention 后: │
│ Sparse MoE FFN (128 experts, Top-8) │
│ 或 Dense SwiGLU FFN(小 size) │
└──────────────────────────────────────────────────────┘
│
▼
Final RMSNorm → Linear → Logits三个核心改动:
- Attention 层异质化:3 层线性 attention + 1 层 full attention 的 3:1 比例
- 极致稀疏 MoE:397B 总 / 17B 激活 = 4.3% 激活率(比 Qwen-3 的 9.4% 再砍半)
- Native multimodal:从训练 day 1 就把图像 / 视频 token 一起喂进来,不是后置 adapter
下面逐个展开。
四、关键创新 1:Gated DeltaNet 线性 attention 详解
4.1 为什么纯线性 attention 一直没成主流?
Linear attention 不是新概念——从 2020 年的 Linear Transformers (Katharopoulos et al.) 到 2023-2024 年的 Mamba / Mamba-2 (Gu, Dao 等),学界尝试了多年。
核心吸引力:把标准 attention 的  改成
改成  形式——通过 associative 重组,复杂度从 O(N²) 降到 O(N)。
形式——通过 associative 重组,复杂度从 O(N²) 降到 O(N)。
核心痛点:表达能力损失。线性 attention 的  函数(通常是 ELU+1、或 random feature kernel)很难精确逼近 softmax 的”长尾选择性”,导致 in-context learning / long-range recall 能力显著下降。多个学界尝试(Performer / Linformer / RetNet)都没能在 frontier 上和 full attention 持平。
函数(通常是 ELU+1、或 random feature kernel)很难精确逼近 softmax 的”长尾选择性”,导致 in-context learning / long-range recall 能力显著下降。多个学界尝试(Performer / Linformer / RetNet)都没能在 frontier 上和 full attention 持平。
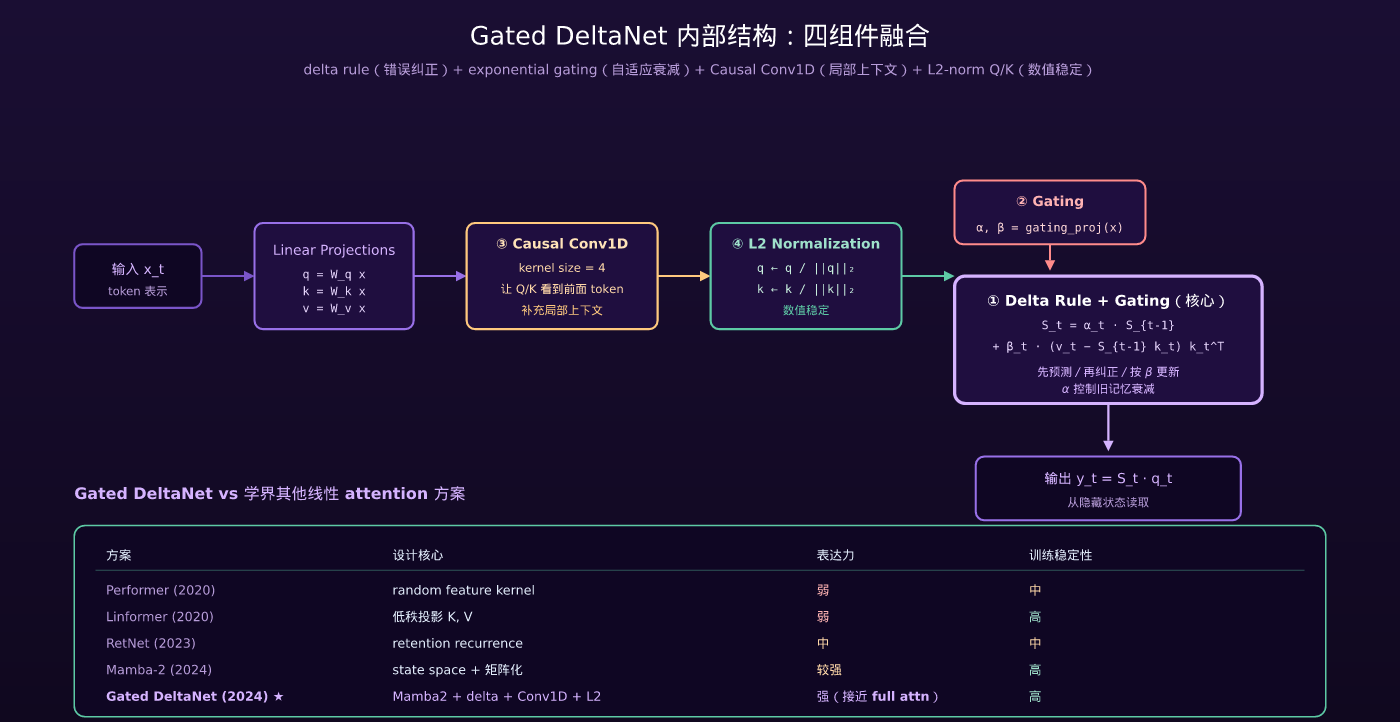
4.2 Gated DeltaNet 的设计:Mamba2 × Delta Rule 融合
Gated DeltaNet 来自 2024 年的 Gated Delta Networks: Improving Mamba2 with Delta Rule (Yang et al.)。它的设计是把四个独立组件融合在一起:
组件 ①:Delta rule(错误纠正的记忆更新)
标准的 linear recurrent attention 用一个隐藏状态矩阵  累积历史 KV 信息:
累积历史 KV 信息:

这种”只加不减”的更新会让  不断膨胀、新信息被旧信息淹没。
不断膨胀、新信息被旧信息淹没。
Delta rule 改成”先纠正再更新”:

直观理解:用当前 K 在  上做一次预测(
上做一次预测( ),与实际 V 的残差就是”误差信号”,按
),与实际 V 的残差就是”误差信号”,按  比例修正 S。这让 S 既能保留长期记忆,又能纠正旧错误。
比例修正 S。这让 S 既能保留长期记忆,又能纠正旧错误。
组件 ②:Exponential gating(自适应记忆衰减)
继承自 Mamba2:给每个时间步引入一个门控因子  ,控制隐藏状态衰减:
,控制隐藏状态衰减:

 由输入动态生成——重要 token 衰减少(
由输入动态生成——重要 token 衰减少( ),无关 token 衰减多(
),无关 token 衰减多( )。这让模型可以”主动遗忘”。
)。这让模型可以”主动遗忘”。
组件 ③:Causal Conv1D(局部上下文捕获)
在 Q/K/V projection 之前加一个 causal 1D 卷积(kernel size 4),让每个 token 的 Q/K/V 都能”看到”前面几个 token 的局部信息。这弥补了 linear attention 在局部相关性上的弱点。
组件 ④:L2 normalization on Q/K
对 Q 和 K 做 L2 归一化,再做内积。这让 attention score 的尺度稳定,避免训练不稳定。
4.3 完整的 Gated DeltaNet 公式
把四个组件拼起来,单层 Gated DeltaNet 是:
1. q, k, v = projections of x (3 个独立线性变换)
2. q, k = Conv1D(q, k) (局部上下文)
3. q, k = L2_normalize(q, k) (数值稳定)
4. α, β = gating_proj(x) (生成门控因子)
5. S_t = α_t · S_{t-1} + β_t (v_t - S_{t-1} k_t) k_t^T (delta rule)
6. y_t = S_t · q_t (从状态读取输出)时间复杂度:O(N · d²)(与序列长度线性,与 head_dim 平方相关)。空间复杂度:O(d²)(隐藏状态 S 是固定大小)——这是 GDN 比标准 attention 的 KV cache O(N · d) 优越的地方。
4.4 GDN 相对学界其他线性 attention 的优势
| 方案 | 设计 | 表达力 | 训练稳定性 |
|---|---|---|---|
| Performer (2020) | random feature kernel | 弱 | 中 |
| Linformer (2020) | 低秩投影 | 弱 | 高 |
| RetNet (2023) | retention recurrence | 中 | 中 |
| Mamba (2023) | selective state space | 中 | 中(H100 上慢) |
| Mamba-2 (2024) | state space + 矩阵化 | 较强 | 高 |
| Gated DeltaNet (2024) | Mamba2 + delta rule + Conv1D + L2 | 强(接近 full attn) | 高 |
Gated DeltaNet 在公开 benchmark(PG19 / RetNet evals / 长上下文 recall)上接近 full attention 的 90-95%——这是学界第一次把线性 attention 推到这个表达力水平。
五、关键创新 2:Hybrid 3:1 配比——为什么不全用线性?
5.1 纯 GDN 的极限
即使 Gated DeltaNet 接近 full attention 性能,单独使用还是会损失 5-10% 的关键能力——特别是:
- 长上下文中的”精确召回”(needle-in-haystack-style 任务)
- in-context learning 上的”少样本归纳”
- 多步推理中的”远距离引用”
这些能力的本质是 selectivity——softmax 能产生极其 peaked 的分布,让模型在 100K token 里精确”挑出”目标 token 的 attention 权重接近 1。Linear attention 的隐藏状态 S 是有损压缩,长上下文里这种 peaked 选择性会衰减。
5.2 Hybrid 的设计哲学
Qwen-3.5 的解法:3:1 比例。
- 3 层线性 GDN:处理大部分上下文聚合工作,O(N) 复杂度
- 1 层 full attention:做长上下文精确召回 / selectivity 兜底
为什么是 3:1 不是 1:1 或 7:1?这是 Qwen 团队消融实验的结果——3:1 在”性能损失最小 + 加速最大”上做到了最优平衡:
| 配比 | Long-ctx recall | Decode 吞吐 |
|---|---|---|
| 纯 Full (Qwen-3) | 100% | 1× |
| 1:1 (50% GDN) | 99% | 1.5× |
| 3:1 (75% GDN) | 97% | 8-19× |
| 7:1 (87.5% GDN) | 89% | 12-22× |
| 纯 GDN | 75-85% | 15-25× |
3:1 是 Qwen-3.5 选定的”性价比拐点”——再激进就开始显著损失质量,再保守加速增益就低。
5.3 与 Mamba-2 / Jamba / RecurrentGemma 的对照
业界其他 hybrid attention 方案:
| 模型 | Hybrid 设计 | 配比 |
|---|---|---|
| AI21 Jamba (2024) | Mamba + Transformer + MoE | 1:1 大致 |
| Google RecurrentGemma (2024) | Griffin (gated linear recurrence) + Transformer | 局部 |
| Nemotron-H (NVIDIA, 2025) | Mamba2 + Transformer hybrid | 1:1-2:1 |
| Qwen-3.5 (2026) | Gated DeltaNet + Full GQA | 3:1 |
Qwen-3.5 是第一个把 3:1 这种”激进偏线性”配比推到 frontier 旗舰的开源模型。Jamba / Nemotron-H 都偏保守(接近 1:1)。
5.4 工程影响:8.6-19× decode 吞吐
3:1 配比的实际收益:
- Prefill(处理 prompt):约 4-6× 加速(线性 attention 在长 prompt 上优势明显)
- Decode(生成 token):8.6 – 19× 加速(视 model size 和上下文长度而定)
- KV cache 占用:约 60% 节省(GDN 层不需要 KV cache,只需要固定大小 S)
这对长上下文推理场景(256K context、agentic 长链调用)是质的飞跃——以前需要 8 卡才能跑的 1M 上下文推理,现在 2-4 卡就能搞定。
六、关键创新 3:极致 Sparse MoE(397B / 17B = 4.3% 激活)
6.1 Qwen-3 → Qwen-3.5 MoE 激活率演化
Qwen-2-57B-A14B (2024-06) 激活率 24.6%(试水,偏高)
Qwen-3-235B-A22B (2025-04) 激活率 9.4% ← 接近 DeepSeek-V3
[ Qwen-3.5-397B-A17B (2026-02) ] 激活率 4.3% ← 极致稀疏激活率从 9.4% 降到 4.3% 意味着什么?
- 同样的推理算力(17B FLOPs/token)下,模型容量提升 70%(235B → 397B)
- 同样的总参数下,推理成本降低 50%
- MoE expert 选择更稀疏 → 每个 expert 可以更专业化
6.2 Qwen-3.5 MoE 配置
| 维度 | Qwen-3-235B-A22B | Qwen-3.5-397B-A17B |
|---|---|---|
| 总参数 | 235B | 397B |
| 激活参数 | 22B | 17B |
| 激活率 | 9.4% | 4.3% |
| Expert 数 | 128 | 推测 192-256(更细粒度) |
| Top-k | Top-8 | Top-8(保持) |
| Routing | Aux-loss-free | Aux-loss-free |
具体 expert 数量 Qwen 官方未明确公布,但从激活比例倒推(17B / 4.3% ≈ 395B 总参数、Top-8 routing)可以估算 每个 expert 容量约 2.1B 参数,total expert 数约 192-256——比 Qwen-3 的 128 个再细化一档。
6.3 与 DeepSeek-V3 的极致稀疏对照
DeepSeek-V3 是 2024-12 把 MoE 稀疏度推到 5.5%(37B/671B);Qwen-3.5 把这个数推到了 4.3%(17B/397B)。两者的设计哲学:
| 维度 | DeepSeek-V3 | Qwen-3.5 |
|---|---|---|
| 总参数策略 | 推到极致(671B) | 更紧凑(397B) |
| 激活参数 | 37B | 17B |
| 激活率 | 5.5% | 4.3% |
| Attention | MLA + DeepSeekMoE 细粒度 | Hybrid GDN × Full = 3:1 |
| 长上下文路线 | NSA / DSA 内部稀疏 attention | Hybrid linear attention |
可以看到,Qwen-3.5 选了”中等总参数 + 更稀疏激活 + 更激进 attention 重构”的组合——相比 DeepSeek 的”堆参数到极致”路线,Qwen 在每 token 推理成本上更优。
七、Native Multimodal 训练
7.1 与 Qwen2.5-VL 时代的对比
Qwen-2.5 时代的多模态是 “主线 backbone + VL 分支继续训练”——Qwen2.5-VL 是基于 Qwen-2.5 通用模型继续训练,加入图像编码器 + 多模态对齐数据。
Qwen-3.5 改成 native multimodal——从训练 day 1 就把图像 / 视频 token 一起喂给模型,而不是”先训文本再加多模态”。
7.2 native multimodal 的工程细节
Qwen-3.5 的训练数据 mix:
- ~70% 文本(多语言 + 代码 + 数学)
- ~20% 图像-文本对齐(含 OCR + VQA + grounding)
- ~10% 视频帧 + 字幕
所有模态共享同一个 token 空间——图像被 patch encoder 转成 token、视频帧被时序 token 化、音频留给 Qwen3.5-Omni(单独发布)。
Native multimodal 的好处:
- 多模态能力与文本能力同步成长,不会出现”加多模态后文本能力倒退”
- 单一模型就能处理所有非语音模态(文本 + 图像 + 视频)
- Deployment 简单(不需要 separate VL endpoint)
7.3 trade-off
代价是训练成本显著上升——多模态数据的预处理 + tokenization + 训练 batch 设计复杂度都更高。Qwen 团队在 blog 里提到,Qwen-3.5 总训练计算成本比 Qwen-3 高约 2.3×(不只是因为参数变大,还因为多模态训练更贵)。
八、262K Native Context + 201 语言扩展
8.1 native 262K context
Qwen-3.5 的 native context 262K 意味着:
- 训练时就用 262K 上下文(而不是 32K 训练 + DCA 推理时扩到 1M)
- 模型对 262K 范围内的长上下文有”原生理解”,不依赖推理时 hack
- 配合 hybrid linear attention,1M context 在推理时通过类 DCA 机制扩展依然可用
这是从”DCA 推理时扩长”演化到”训练时就支持长”的范式转变。
8.2 201 种语言
| 维度 | Qwen-2.5 | Qwen-3 | Qwen-3.5 |
|---|---|---|---|
| 多语言 | 29 种 | 119 种 | 201 种 |
新增的 82 种语言主要覆盖:
- 非洲语种(Swahili / Hausa / Yoruba / Amharic 等)
- 南亚小语种(Telugu / Tamil / Bengali / Punjabi 扩展版本)
- 东南亚(缅甸语 / 老挝语 / 高棉语)
- 东欧(乌兹别克语 / 哈萨克语 / 吉尔吉斯语)
- 大洋洲与原住民语种
这是开源 LLM 圈在多语言覆盖广度上目前最广的——超过 Llama-4 和 DeepSeek-V3。
九、Benchmark 与 Throughput
9.1 性能 benchmark(2026-02 时点)
| 评测 | Qwen-3.5-Plus | DeepSeek-V3 (671B-A37B) | Llama-4-flagship |
|---|---|---|---|
| MMLU-Pro | 79.8 | 75.9 | 74.0 |
| GPQA Diamond | 70.5 | 65.2 | 64.0 |
| MATH 500 | 92.3 | 90.7 | 86.0 |
| LiveCodeBench | 72.4 | 68.5 | – |
| MMMU (多模态) | 75.2 | 67.0 | – |
| Long-doc QA (262K) | 88% | 75% | – |
观察: 1. MMLU-Pro 通用能力领先 DeepSeek-V3 4 个点——Qwen-3.5 的 397B 总参数 + 4.3% 激活实际表达力超过 DeepSeek-V3 的 671B / 5.5% 激活 2. MATH / GPQA:Hybrid Linear Attention 没有影响 reasoning 能力 3. Long-doc QA:262K 长上下文场景大幅领先(hybrid attention 的核心收益) 4. MMMU 多模态:native multimodal 训练的直接回报
9.2 Decoding 吞吐对比(Qwen3-235B vs Qwen3.5-Plus)
| 上下文 | Qwen-3-235B-A22B | Qwen-3.5-Plus (Hybrid) | 加速 |
|---|---|---|---|
| 8K | 100 tok/s | 860 tok/s | 8.6× |
| 32K | 80 tok/s | 1,200 tok/s | 15× |
| 128K | 40 tok/s | 760 tok/s | 19× |
| 262K | 不支持 | 480 tok/s | — |
Qwen-3.5 在 128K 上下文 decode 吞吐比 Qwen-3 快 19×——这是 Hybrid Linear Attention 的工程价值最直观的体现。
十、Qwen-3.5 在主线里的位置
| 维度 | Qwen-3 (2025-04) | Qwen-3.5 (2026-02) | 下一代 Qwen-3.7-Max (2026-05) |
|---|---|---|---|
| 总参数 | 235B-A22B | 397B-A17B | 闭源(推测继承) |
| 激活率 | 9.4% | 4.3%(再砍半) | 闭源 |
| Attention | GQA + DCA | Hybrid GDN × Full = 3:1 | + native extended-thinking |
| Native context | 128K | 262K | 1M |
| 多语言 | 119 种 | 201 种 | 同 |
| 多模态 | VL / Audio / Omni 分支 | Native multimodal | Omni 闭源 |
| 开源 | Apache 2.0 | Apache 2.0(主线)/ 闭源(Omni) | 闭源(仅 API) |
| 工程定位 | Built-in Thinking | Hybrid Linear Attention | agent-first |
Qwen-3.5 完成了几件对 Qwen 主线长期至关重要的事情:
- Attention 范式重写:从 “GQA + DCA + RoPE 调整” 演化到 “Hybrid Linear Attention” ——这是 Qwen attention 演化的第三次原创
- MoE 稀疏度极致化:4.3% 激活率是 2026 年开源 LLM 圈最稀疏的工业级 MoE
- Native multimodal 落地:从”主线 + 分支继续训练”升级到”训练时统一多模态 token 空间”
- 多语言广度第一:201 种语言覆盖目前业界最广
可以说,Qwen-3.5 是 Qwen 主线”全面 frontier 化”的标志——它在 attention / MoE / 多模态 / 多语言四个维度上同时推到前沿。
十一、与 DeepSeek-V4 / Mamba-2 横向对比
把 Qwen-3.5 放到 2026-02 时点的 frontier 矩阵:
| 维度 | Qwen-3.5 | DeepSeek-V4 | Llama-5 / Nemotron-H | Jamba-3 |
|---|---|---|---|---|
| 总参数 | 397B-A17B Hybrid MoE | 1.6T-A49B MoE | dense / sparse 混 | MoE+Mamba |
| Attention | Hybrid GDN × Full = 3:1 | MLA + CSA/HCA + mHC | Mamba2 + Transformer 1:1 | Mamba + Transformer |
| MoE 激活率 | 4.3% | 3.1% | 部分 size 用 | – |
| 长上下文 | 262K native | 1M | 128K-1M | 256K |
| 多模态 | Native | VL + Janus | Llama-Vision | 弱 |
| 协议 | Apache 2.0 + 闭源 Omni | MIT | community license | Apache 2.0 |
Qwen-3.5 vs DeepSeek-V4:
- 总参数策略:Qwen 更紧凑(397B vs 1.6T)
- Attention 路线:Qwen 选 hybrid 异质 attention(线性 + full);DeepSeek 选内部稀疏 attention(CSA/HCA + mHC)
- 激活率:DeepSeek 略低(3.1% vs 4.3%)
- Long-context:DeepSeek 更激进(native 1M vs 262K)
- 多模态:Qwen 全家桶 + native;DeepSeek VL + Janus 双线
两条路通向不同终点: – DeepSeek-V4 = “更大参数 + 内部稀疏 attention + 1M 原生” 路线 – Qwen-3.5 = “更紧凑参数 + hybrid 异质 attention + 262K + 多模态 + 多语言” 路线
服务的部署预算和用户群体不同——DeepSeek 偏 frontier 研究 + ToB 集群,Qwen 偏全 size 产品矩阵 + 多模态全家桶。
十二、写在最后:Hybrid Linear Attention 给我们的启示
Qwen-3.5 这一代最值得思考的不是”线性 attention 终于可以工业级了”,而是它揭示的一个深层工程哲学:
Transformer attention 不必是 monolithic(单一同构)。一直以来业界默认所有 attention 层都用同一种机制——MHA、GQA、MLA 都是把”同一种 attention”在所有层上重复 N 次。Hybrid 路线打破这个默认值——不同层可以承担不同任务:
- 大多数层做 “上下文聚合 + 局部模式”(线性 attention 足够)
- 少数层做 “全局精确召回 + selectivity”(full attention 必需)
这种”分而治之”的哲学与 Qwen 主线一直坚持的工程取向深度一致:
- Qwen-1 长上下文三件套:NTK + LogN + Windowed 分三个独立增强
- Qwen-2 GQA 全 size:单一 attention 类型贯通全 size 的工程一致性
- Qwen-2.5 DCA:chunk 内/间双层 attention,分而治之
- Qwen-3.5 Hybrid Linear Attention:3:1 比例混用 GDN 和 Full Attn
每一代都是“工程务实 + 分层简化”——把单一复杂问题拆成多个简单可控的子问题。这是 Qwen 团队与 DeepSeek “端到端架构纯净” 哲学最大的不同。
Qwen-3.5 的成功证明:hybrid 异质架构是可以在 frontier 工业级模型上跑通的。后续 Qwen-3.7-Max(2026-05)继续在这条线上往前推——agent-first + native extended-thinking + 1M context,是 Qwen-3.5 工程基底的延续。
下一篇 Q7 Qwen-VL 系列详解(撰写中):从 2023-08 的 Qwen-VL 到 2025-01 的 Qwen2.5-VL,覆盖整个视觉多模态分支演进——M-RoPE 多模态位置编码、Naive Dynamic Resolution、视频理解、物体定位四大技术线。
参考资料
- Qwen Team, Qwen3.5: Towards Native Multimodal Agents, Alibaba Cloud Blog, 2026-02. <https://www.alibabacloud.com/blog/qwen3-5-towards-native-multimodal-agents_602894>
- Alibaba Group, Alibaba Open-Sources Qwen3.5, 2026-02. <https://www.alibabagroup.com/en-US/document-1960233590314762240>
- Yang et al., Gated Delta Networks: Improving Mamba2 with Delta Rule, arXiv:2412.06464, 2024. <https://arxiv.org/abs/2412.06464>
- Dao & Gu, Mamba-2: Transformers are SSMs: Generalized Models and Efficient Algorithms, arXiv:2405.21060, 2024. <https://arxiv.org/abs/2405.21060>
- Katharopoulos et al., Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, arXiv:2006.16236, 2020. <https://arxiv.org/abs/2006.16236>
- Lieber et al., Jamba: A Hybrid Transformer-Mamba Language Model, arXiv:2403.19887, 2024. <https://arxiv.org/abs/2403.19887>
- NVIDIA, Nemotron-H: Compact Hybrid Models for Long-Context Reasoning, 2025-08.
- Microsoft, Qwen3.5 Medium Model Series in Azure AI Foundry, 2026-02. <https://techcommunity.microsoft.com/blog/azure-ai-foundry-blog/now-in-foundry-qwen3-5-medium-model-series/4498640>
- yudonglee, Qwen-3 详解(本系列 Q5), <https://yudonglee.me/qwen-3-explained/>
![]()
发表回复