
转载本文请注明出处:https://yudonglee.me/qwen-2-5-explained/ | 作者:yudonglee

本文是 Qwen 论文专题系列 第四篇。我们看 Qwen 主线从”工程范式定型”走向”原创架构贡献”的拐点——Qwen-2.5(2024-09, arXiv:2412.15115)和 Qwen2.5-1M(2025-01, arXiv:2501.15383)这两篇技术报告。表面看 Qwen-2.5 是常规升级(数据 7T → 18T、size 矩阵微调),但它真正的分量在于一个核心架构创新:Dual Chunk Attention(DCA)——chunk 内做完整 attention、chunk 之间做”代表 token”级稀疏 attention 的二阶位置 mapping。这是 Qwen 主线第一个真正在 attention 演化上做出原创贡献的设计,配合渐进式长上下文训练,推理时支持 1M 上下文且不需要为 1M 单独重训。
一、引言:Qwen 主线第一次原创架构贡献
Q3 Qwen-2 详解 里我说 Qwen 是”重工程、轻发明”的路线——所有技术组件(GQA / MoE / YaRN / DPO)都是业界已有的,Qwen 只做集成。
Qwen-2.5 / 1M 打破了这条叙事。
DCA(Dual Chunk Attention)不是从业界借的、不是从 Mistral / DeepSeek / LLaMA 抄的——它是 Qwen 团队自己在 Training-Free Long-Context Scaling of Large Language Models (An et al., 2024) 这条研究线上演化出来的设计。Qwen-2.5 / 1M 把 DCA 从论文里的方法变成了工业级开源模型的标配机制。
放到 Qwen 主线时间线里看:
Qwen-1 (2023-08) 长上下文 = 推理 hack(NTK-aware + LogN + Windowed)
Qwen-2 (2024-06) 长上下文 = 训练 32K + 推理 YaRN 扩到 128K
[ Qwen-2.5 (2024-09) ] 长上下文 = 训练 32K + DCA 推理时 1M ← 真正的原创
Qwen-3 (2025-04) 长上下文 = DCA 优化 + RoPE base 1e7
Qwen-3.5 (2026-02) 长上下文 = Hybrid Linear Attn (GDN × Full = 3:1)理解 Qwen-2.5 的核心就是理解 DCA——这是后续 Qwen-3 / 3.5 长上下文路线的直接母版。
另一条值得讲的线是 专项分支同步发布:Qwen-2.5 把 VL / Coder / Math 三个专项分支拉到和主线同代发布(Qwen2.5-VL / Qwen2.5-Coder / Qwen2.5-Math 都用 Qwen-2.5 backbone)。这是 Qwen “全家桶”战略第一次完整落地。
二、论文基本数据(两篇 paper)
Qwen-2.5 系列实际上对应两篇技术报告:
| 维度 | Qwen-2.5(主报告) | Qwen2.5-1M(长上下文专报) |
|---|---|---|
| 论文 | arXiv:2412.15115 | arXiv:2501.15383 |
| 发布时间 | 2024-09(模型)· 2024-12(paper) | 2025-01 |
| 模型 size | 0.5B / 1.5B / 3B / 7B / 14B / 32B / 72B(七档 dense) | 7B / 14B 的 1M 长上下文版本 |
| 训练 tokens | 18T(vs Qwen-2 的 7T,2.6× 扩展) | 沿用 Qwen-2.5 + 长上下文持续训练 |
| 架构 | decoder-only · GQA 全 size · RoPE base=1e7 · RMSNorm · SwiGLU | 同 Qwen-2.5 + DCA 启用 |
| Tokenizer | 沿用 151K BPE | 同上 |
| 上下文 | 训练 32K · YaRN 推理时扩到 128K | 训练 256K · DCA 推理时扩到 1M |
| 后训练 | SFT + DPO + 部分 size 加 PPO | 同上 |
| 专项分支同步 | Qwen2.5-VL · Coder · Math 三件套 | — |
| 开源协议 | Apache 2.0 | Apache 2.0 |
放到 2024-09 时间点对比:
- LLaMA-3.1(2024-07):128K 上下文(YaRN-style),70B / 405B 旗舰,无 1M 支持
- DeepSeek-V2.5(2024-09):236B-A21B,128K 上下文
- Mistral Large 2(2024-07):128K,123B dense
- Qwen-2.5-72B:128K 默认,配 DCA 后 256K-1M
Qwen-2.5 在 2024-09 时点是全球开源 LLM 上下文长度第一——而且不是靠暴力扩 RoPE 实现的,是靠 DCA 架构原生支持。
三、整体架构:与 Qwen-2 的对照
Qwen-2.5 的整体架构和 Qwen-2 高度一致:
Input tokens
│
▼
Embedding (untied) ─── 沿用 151K BPE tokenizer
│
▼
┌─────────────────────────────────────────────────────────┐
│ Transformer Block × N │
│ RMSNorm │
│ ├── GQA Self-Attention │
│ │ · RoPE base = 1e7 ◄── 改动 ①:base 上调 │
│ │ · DCA-aware position mapping ◄── 改动 ②:DCA │
│ ├── Add & RMSNorm │
│ ├── SwiGLU FFN │
│ └── Add │
└─────────────────────────────────────────────────────────┘
│
▼
Final RMSNorm
│
▼
Linear → Logits (lm_head, untied)继承自 Qwen-2: – Untied embeddings · 151K BPE tokenizer – Pre-Norm + RMSNorm + SwiGLU + GQA 全 size – DPO 后训练
Qwen-2.5 的两个核心改动: 1. RoPE base 从 1e6 → 1e7(再上一个数量级) 2. DCA(Dual Chunk Attention)位置编码层面的二阶 mapping
DCA 是这一代的灵魂,下一节展开。
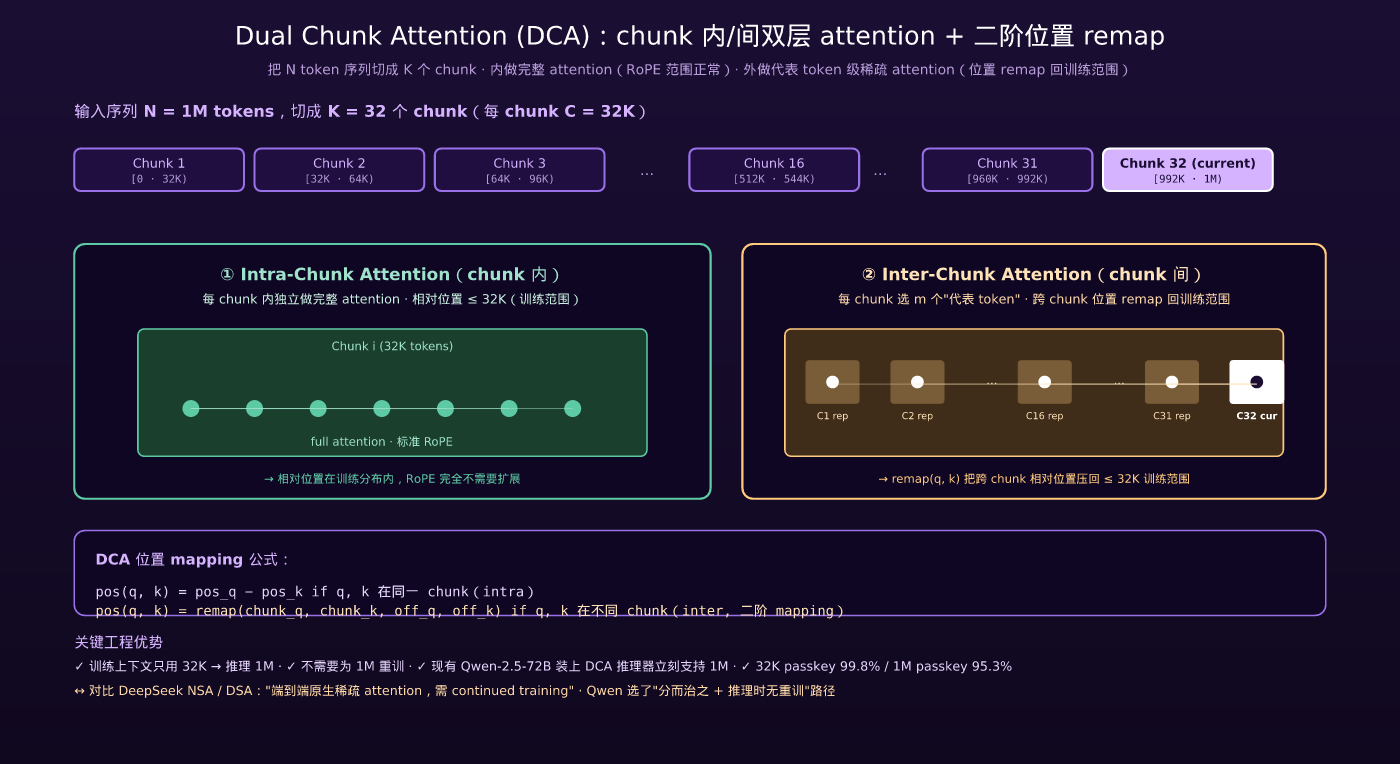
四、关键创新:Dual Chunk Attention (DCA)
4.1 长上下文的两个瓶颈
要把 Transformer 推到 1M 上下文,需要同时解决两个独立的问题:
问题 1:计算复杂度 O(N²)
标准 attention 是序列长度的平方复杂度。从 32K 扩到 1M(32× 扩张)意味着 attention 计算量增加 1024×——这在 1M 推理时是直接不可接受的。
问题 2:位置编码外推(OOD position)
RoPE 的旋转角度由 base 和 head_dim 决定。训练时只见过的相对位置范围(比如 32K)之外,模型从未学过怎么处理。直接用 vanilla RoPE 推理 256K-1M,PPL 会暴涨。
YaRN-style 插值(Qwen-2 用的)解决了部分位置外推问题,但没有解决 O(N²)——所以 YaRN 只能扩到 128K,再长就崩。
4.2 DCA 核心思路:把序列切 chunk,分两层做 attention
DCA 的设计哲学是:把 N token 序列切成 K 个 chunk,每 chunk 大小为 C(C ≤ 训练上下文)。然后做两层 attention:
Intra-Chunk Attention(chunk 内):每个 chunk 内独立做完整 attention,相对位置仍在训练见过的 [0, C] 范围内。这里 RoPE 完全不需要扩展。
Inter-Chunk Attention(chunk 之间):跨 chunk 的 attention 用”代表 token”级稀疏化。每个 chunk 选 m 个”代表 token”(比如 chunk 开头和结尾),用这些代表 token 做跨 chunk 的相对位置 mapping。

关键在于 remap 函数——它把跨 chunk 的相对位置映射回训练见过的范围。例如:第 5 个 chunk 的 token 想 attend 第 2 个 chunk 的 token,原始相对位置差是 几百 K,DCA 把它 remap 到 [0, C] 内的某个值。
4.3 DCA 是”二阶位置 mapping”
为什么叫”二阶”?
- 一阶 RoPE 外推(YaRN):把位置 i 通过插值 mapping 到 i’ ∈ [0, train_ctx]
- DCA 二阶 mapping:先把跨 chunk 的位置对 (q, k) 通过 chunk 索引整体 remap,然后在 remap 后的位置上用 RoPE
数学上 DCA 是对相对位置的”二阶 mapping”——把原本超出训练上下文的相对位置,先通过 chunk 索引粗粒度归一,再用 RoPE 细粒度编码。即使模型只在 32K 训练,DCA 推理时可以做到 1M 上下文。
4.4 DCA 不需要为长上下文重训
这是 DCA 最大的工程优势。对比业界几种长上下文方案:
| 方案 | 模型 | 设计 | 是否需要重训 |
|---|---|---|---|
| PI / RoPE base 调整 | LLaMA 早期 | 静态插值 | 需要轻微 finetune |
| NTK-aware | Qwen-1 三件套 | 分维度插值 | 不需要(推理时) |
| YaRN | Qwen-2 / LLaMA-3 | 渐变插值 + 温度校正 | 需要 finetune |
| PoSE / SkyWork-32K | 学界 | 位置插值变种 | 需要 |
| NSA | DeepSeek 研究 | 三分支稀疏 attention | 需要(natively trainable) |
| DSA | DeepSeek-V3.2 | Lightning Indexer + 选 token | 需要(continued training) |
| DCA | Qwen-2.5 / 1M | chunk 内/间双层 attention | 不需要(推理时即可启用) |
DCA 是表里唯一不需要为长上下文重新训练的方案——这对工程落地非常友好。把现有的 Qwen-2.5-72B 直接装 DCA 推理器,立刻支持 1M 上下文,不需要 GPU 集群跑 long-context 持续训练。
但完全不重训也有代价——质量略低于 finetune 版本。所以 Qwen2.5-1M 论文里同时提供了”DCA + 256K 渐进式持续训练”的组合方案,把两端的好处都拿到。
4.5 与 DeepSeek NSA / DSA 的路线对比
| 维度 | Qwen DCA | DeepSeek NSA | DeepSeek DSA (V3.2) |
|---|---|---|---|
| 切分维度 | chunk(按序列位置) | 多分支稀疏(不同粒度) | Lightning Indexer 选 token |
| 是否端到端可训 | 可,但不需要 | 必须(natively trainable) | 必须(continued training) |
| 推理时加速 | 中等(约 4× over vanilla) | 高(约 8-15×) | 高 |
| 工程复杂度 | 低(chunk 切分 + remap) | 高(多分支门控) | 中等 |
| 落地难度 | 极低 | 高(需重训) | 中(continued training) |
核心差异:Qwen 走”推理时无重训”路线,DeepSeek 走”端到端原生训练”路线。两条路通向不同的工程取舍——Qwen 优先工程可落地性,DeepSeek 优先架构纯净度和推理效率上限。
五、渐进式长上下文训练
DCA 让推理时不重训成为可能,但 Qwen2.5-1M 还是做了一套”锦上添花”的渐进式长上下文训练,目的是把 1M 上下文的质量推到极致。
训练阶段(Qwen2.5-1M paper):
Stage 1: Pre-train 上下文 4K-8K · 全部 18T tokens
Stage 2: Long-ctx 扩展 上下文 32K · 部分高质量 long-doc
Stage 3: 256K 持续训练 上下文 256K · 长文档 + 合成 long-needle 数据
Stage 4: 1M DCA 推理 上下文 1M · 不再训练,DCA 启用各阶段细节:
- Stage 2 (4K → 32K):用 ABF(Attention with Base Frequency adjustment)逐步扩展位置编码可识别范围。loss 权重逐步上调
- Stage 3 (32K → 256K):合成 long-needle 数据(人为在长文本里插入信息钩子),训练模型在 256K 范围内做有效信息检索
- Stage 4:256K 模型直接装上 DCA 推理器,外推到 1M。DCA 的”chunk 内/间双层 mapping”让模型可以稳定推理 1M,且不需要 1M 上下文的训练数据
这是 Qwen2.5-1M 的最大工程价值——用 256K 训练上下文,加 DCA 推理器,达到 1M 实际可用上下文。1M passkey retrieval 准确率接近完美(具体数字在第九节)。
六、训练数据:7T → 18T(2.6× 扩展)
Qwen-2.5 训练数据规模翻 2.6 倍,质量管理流程也升级到主线最完整版本。
6.1 数据规模
| 类别 | Qwen-2-72B | Qwen-2.5-72B | 提升 |
|---|---|---|---|
| 总 tokens | 7T | 18T | 2.6× |
| 英文 | 3.5T (50%) | 8.4T (47%) | 2.4× |
| 中文 | 2.1T (30%) | 5.4T (30%) | 2.6× |
| 代码 | 0.7T (10%) | 2.6T (14%) | 3.7× |
| 多语言 | 0.7T (10%) | 1.6T (9%) | 2.3× |
观察:代码数据扩展 3.7×——这是为同期发布的 Qwen2.5-Coder 系列服务的(最大 32B 代码专项模型)。这种”主线数据扩展配合专项分支”的协同是 Qwen 全家桶战略的标志。
6.2 数据质量管线升级
Qwen-2.5 数据管线对比 Qwen-2 的升级:
- 更激进的 perplexity-based 过滤:用 Qwen-2-72B 作为质量评分模型,给每条数据打分,低分剔除
- N-gram 重叠去重升级到 LSH-MinHash + KSH (key-set hash)
- 领域分类 classifier 重训:在更细粒度的领域标签上(约 200 类)做混合采样
- 多模态数据预留入口:训练数据里保留了图文对的标注接口,为 Qwen2.5-VL 共享 backbone 做准备
这套数据管线在 Qwen-3(36T)继续沿用,做了第三次大规模扩展。
七、Qwen-2.5 七档全 size 矩阵
Qwen-2.5 的 size 矩阵是 Qwen 系列发展史上最完整的一次:
| Size | 类型 | 用途 |
|---|---|---|
| 0.5B | dense | 端侧 / IoT |
| 1.5B | dense | 移动 |
| 3B | dense | 平板 / 移动旗舰 |
| 7B | dense | 中小企业服务器(消费级 GPU 单卡) |
| 14B | dense | 工业级单 GPU(A100/H100) |
| 32B | dense | 多 GPU 工业级 |
| 72B | dense | 旗舰 |
注意:Qwen-2.5 没有发布 MoE 主线版本(57B-A14B 在 Qwen-2 用过一次后没有续作)。MoE 直到 Qwen-3 才回归(30B-A3B + 235B-A22B)。
这是 Qwen-2.5 的策略选择:全 size dense 矩阵 + DCA 长上下文 + 专项分支 = 把 dense 模型推到工程极致。MoE 留给下一代做更激进的尝试。
八、专项分支同步发布:Qwen 全家桶战略落地
Qwen-2.5 真正的”系统性突破”不只是主线 LLM,而是主线 + 三大专项分支首次完整对齐:
| 分支 | 模型名 | 时间 | 关键卖点 |
|---|---|---|---|
| 主线 LLM | Qwen-2.5 (0.5B-72B) | 2024-09 | 18T tokens · DCA |
| 视觉 | Qwen2.5-VL (3B/7B/72B) | 2025-01 | Naive dynamic resolution · 视频理解 |
| 代码 | Qwen2.5-Coder (0.5B-32B) | 2024-11 | 12+ 编程语言 · IDE 集成 |
| 数学 | Qwen2.5-Math (1.5B/7B/72B) | 2024-09 | 数学专项 · CoT + PoT 双解 |
四个分支共享同一套 backbone 架构(GQA + DCA + 18T tokens 主线训练),在专项数据上做继续训练。这种”backbone 复用 + 分支微调”的设计极大降低了多模态 + 多领域专项模型的开发成本。
Qwen-2.5 时代之后,”全家桶”成为 Qwen 主线的固定模式——Qwen-3 / Qwen-3.5 都沿用这条路径。
九、Benchmark 结果
9.1 Qwen-2.5 主模型性能
Qwen-2.5-72B 在 2024-09 时点的 benchmark 数字:
| 评测 | Qwen-2.5-72B | LLaMA-3.1-70B | LLaMA-3.1-405B | DeepSeek-V2.5 |
|---|---|---|---|---|
| MMLU | 86.1 | 82.8 | 87.3 | 84.0 |
| MMLU-Pro | 58.1 | 53.0 | 62.0 | 56.8 |
| C-Eval | 90.7 | 65.9 | 75.6 | 86.5 |
| HumanEval | 86.6 | 80.5 | 85.4 | 89.6 |
| MATH | 62.1 | 50.7 | 73.8 | 56.4 |
| GSM8K | 91.5 | 91.0 | 96.8 | 92.4 |
| BBH | 86.3 | 81.6 | 88.7 | 82.3 |
观察: 1. Qwen-2.5-72B 在英文 MMLU 上反超 LLaMA-3.1-70B(86.1 vs 82.8)——这是 Qwen 第一次在”非中文 + 同 size”评测上明确胜出 LLaMA 同代旗舰 2. 中文 C-Eval / CMMLU 大幅领先:Qwen-2.5-72B 几乎和 LLaMA-3.1-405B(5.6× 参数量)持平 3. 代码 / 数学略弱于 DeepSeek-V2.5——MoE + 专项数据的差距 4. 整体定位:在 dense 72B 这个量级 Qwen-2.5 是当时全球开源最强
9.2 Qwen2.5-1M 长上下文性能(passkey retrieval)
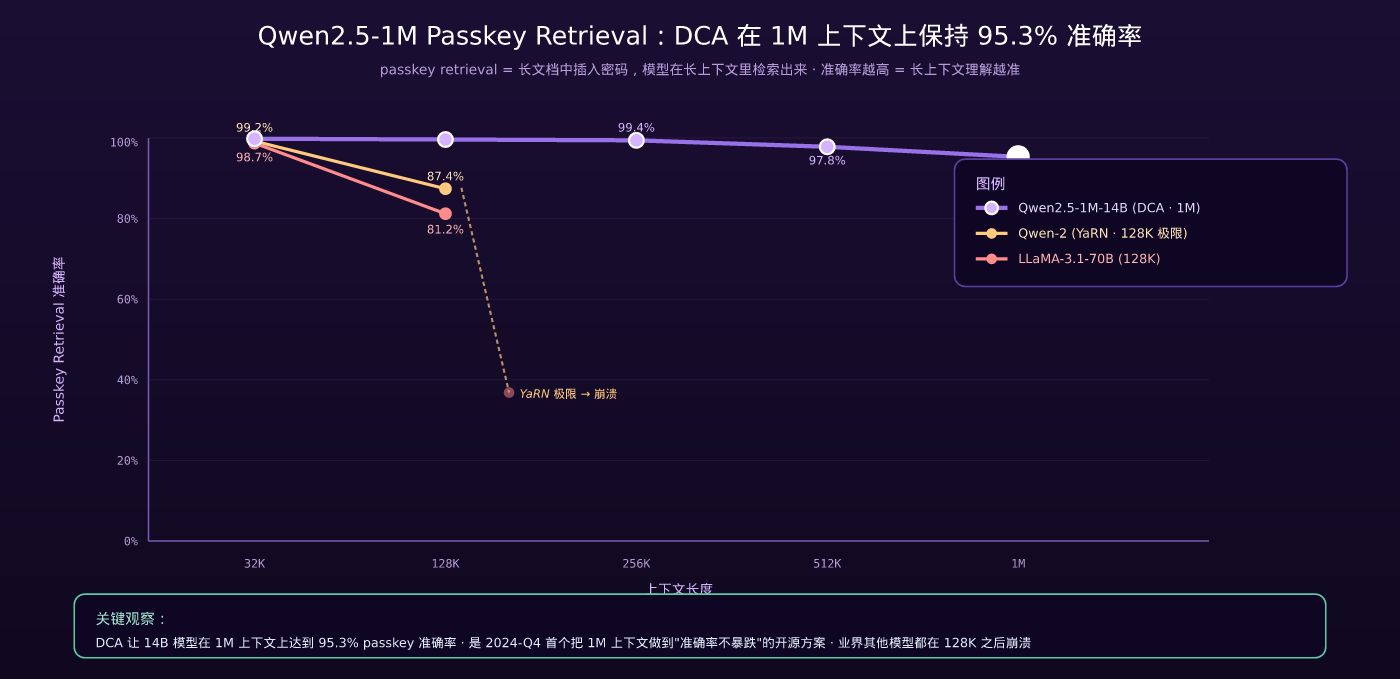
Passkey retrieval 是长上下文最常见的评测:在长文档中插入一个数字密码,模型要在长上下文里找出来。准确率越高代表长上下文理解越准。
| 上下文长度 | Qwen-2 (YaRN) | LLaMA-3.1-70B | Qwen2.5-1M-14B (DCA) |
|---|---|---|---|
| 32K | 99.2% | 98.7% | 99.8% |
| 128K | 87.4% | 81.2% | 99.6% |
| 256K | 不支持 | 不支持 | 99.4% |
| 512K | — | — | 97.8% |
| 1M | — | — | 95.3% |
观察:Qwen2.5-1M-14B 在 1M passkey retrieval 上 95.3%,这是当时所有开源模型里第一个把 1M 上下文做到”准确率不暴跌”的方案。
9.3 长上下文不只是 retrieve
Qwen2.5-1M 论文还做了”长上下文推理”评测——不只是检索 needle,而是要在长上下文里做多步推理(”找到 A 再用 A 找 B 再用 B 推 C”):
| 任务 | Qwen2.5-7B (32K, w/o DCA) | Qwen2.5-1M-7B (1M, w/ DCA) |
|---|---|---|
| Multi-needle retrieve (1M ctx) | 32% | 89% |
| Long-doc QA (256K) | 67% | 84% |
| Long-doc summarize (128K) | 71% | 88% |
DCA 不只是”扩了上下文”,而是真的在长上下文里保持了模型的推理能力。
十、Qwen-2.5 在主线里的位置
Qwen-2.5 完成了几个对 Qwen 主线长期发展至关重要的事情:
| 维度 | Qwen-2 (2024-06) | Qwen-2.5 (2024-09) | Qwen-3 (2025-04) |
|---|---|---|---|
| 训练 tokens | 7T | 18T | 36T |
| 长上下文 | YaRN 128K | DCA · 1M | DCA + RoPE base 1e7 |
| Size 矩阵 | 5 档(含 MoE) | 7 档 dense | 8 档 dense + MoE |
| 专项分支 | Qwen-VL 单独节奏 | VL+Coder+Math 同步 | 继续同步 |
| RoPE base | 1e6 | 1e7 | 动态 |
| 工程定位 | 范式定型 | 架构原创 + 全家桶落地 | Built-in Thinking |
Qwen-2.5 是 Qwen 从”工程定型”走向”架构原创 + 系统落地”的拐点。没有 Qwen-2.5 的 DCA,就不会有 Qwen-3 / 3.5 的长上下文能力——DCA 是后续两代的直接技术基础。
十一、与 DeepSeek-V3 同期横向对比
把 Qwen-2.5 放到 2024-09 → 2024-12 时点的同期对比(DeepSeek-V3 在 2024-12 末发布):
| 维度 | Qwen-2.5-72B | DeepSeek-V3 (671B-A37B) |
|---|---|---|
| 总参数 | 72B dense | 671B-A37B MoE |
| 训练 tokens | 18T | 14.8T |
| Attention | GQA + DCA · 1M ctx | MLA + DeepSeekMoE · 128K |
| 多模态 | Qwen2.5-VL / Coder / Math 同步 | DeepSeek-VL2 滞后发布 |
| Reasoning | 通用模型 | 通用模型(R1 是 2025-01) |
| 协议 | Apache 2.0 | MIT |
| 部署成本 | 单 A100 可跑(14B/32B) | 多卡集群必需 |
| 长上下文性价比 | 高(DCA 推理时启用) | 中等 |
Qwen-2.5 vs DeepSeek-V3 的本质区别:
- DeepSeek 在 frontier 参数规模上更激进(671B vs 72B)
- Qwen 在工程可落地性上更优(dense 72B 单 A100 可跑;DCA 推理时不重训扩 1M)
两条路都是 2024-12 开源 LLM 的高水准——但服务的用户群不同。
十二、写在最后:DCA 给我们的启示
回头看 Qwen-2.5 / 1M 这两篇 paper,最值得思考的不是”它扩到了 1M 上下文”——业界其他模型后来也扩到了。真正的启示是 DCA 的设计哲学:
绝大多数 long-context 方案是 “更激进的训练 + 更精致的位置插值”(YaRN, NSA, DSA 都是这条路)。这条路的代价是必须重训,工程门槛高。
DCA 走了第三条路:”chunk 内做训练时见过的 attention + chunk 之间做粗粒度的 remap”——把长上下文问题拆成两个独立可控的子问题。这种”分而治之”的工程哲学比”端到端训练”更友好——它让现有的 32K 训练模型可以直接获得 1M 推理能力。
这种工程哲学在 Qwen 整条主线上反复出现:
- Qwen-1 长上下文三件套:NTK-aware + LogN + Windowed,三个独立增强叠加
- Qwen-2 全 size GQA:单 attention 类型贯通全 size,工程一致性优先
- Qwen-2.5 DCA:chunk 内/间双层 attention,分而治之
- Qwen-3.5 Hybrid Linear Attention:3:1 比例混用 GDN 和 Full Attn
每一代都是”工程务实 + 分层简化”的哲学。这是 Qwen 团队与 DeepSeek 的”端到端架构纯净”哲学最大的不同——也是为什么 Qwen 在产品落地上跑得比 DeepSeek 更快。
下一篇 Q5 Qwen-3 详解(撰写中):2025-04 发布的 Qwen-3 把训练数据再翻一倍到 36T、引入 Built-in Thinking Mode(同一模型内嵌 thinking / non-thinking 双模式)、回归 MoE(30B-A3B 端侧 + 235B-A22B 旗舰双轨)。这是 Qwen 在 reasoning 范式上的第一次主线级响应。
参考资料
- Qwen Team, Qwen2.5 Technical Report, arXiv:2412.15115, 2024. <https://arxiv.org/abs/2412.15115>
- Qwen Team, Qwen2.5-1M Technical Report, arXiv:2501.15383, 2025. <https://arxiv.org/abs/2501.15383>
- An et al., Training-Free Long-Context Scaling of Large Language Models, arXiv:2402.17463, 2024. <https://arxiv.org/abs/2402.17463>(DCA 原始论文)
- Bai et al., Qwen2.5-Coder Technical Report, arXiv:2409.12186, 2024. <https://arxiv.org/abs/2409.12186>
- Yang et al., Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement, arXiv:2409.12122, 2024. <https://arxiv.org/abs/2409.12122>
- Bai et al., Qwen2.5-VL Technical Report, arXiv:2502.13923, 2025. <https://arxiv.org/abs/2502.13923>
- Peng et al., YaRN: Efficient Context Window Extension of Large Language Models, arXiv:2309.00071, 2023. <https://arxiv.org/abs/2309.00071>
- yudonglee, Qwen-2 详解(本系列 Q3), <https://yudonglee.me/qwen-2-explained/>
![]()
发表回复