
转载本文请注明出处:https://yudonglee.me/qwen-1-explained/ | 作者:yudonglee

本文是 Qwen 论文专题系列 第二篇。我们回到 2023 年 8 月——通义实验室在 arXiv 上传 Qwen Technical Report(arXiv:2309.16609)的那个时间点。当时舆论场被 LLaMA-2 / Code Llama / Falcon-180B 完全占据,Qwen-1 的发布几乎没有溅起水花。但回过头看,那篇看似”平平无奇”的技术报告里,至少藏了四个在两年后才显出价值的工程取舍:双语 BPE tokenizer、RoPE base 从 1e4 拉到 1e6、NTK-aware + LogN-scaling + Windowed Attention 的 long-context 三件套、以及 Tied Embeddings 的取消。这一篇我们把这四个取舍逐个拆开看。
一、引言:为什么要从 Qwen-1 讲起
按”重要性”排,Qwen 系列里最值得讲的应该是 Qwen-2.5(DCA + 1M 上下文)和 Qwen-3(Built-in Thinking Mode)。但理解 Qwen 必须从 Qwen-1 讲起,原因有三:
第一,Qwen-1 定义了 Qwen 整条主线的工程基因。后面 Qwen-1.5 / 2 / 2.5 / 3 在架构上的所有”非 LLaMA 标准”选择,几乎都是从 Qwen-1 这篇技术报告开始的。如果你直接从 Qwen-3 看起,会看到一堆”为什么这么做”的疑问,但 Qwen-1 里都已经埋好了答案。
第二,Qwen-1 是当时为数不多敢于在 LLaMA-2 标准件之外做实质性偏离的中文开源模型。同期 Baichuan-2、ChatGLM3、Yi、InternLM 都更倾向于”对齐 LLaMA-2 工程默认值 + 中文语料微调”。Qwen-1 选了完全不同的路:tokenizer 自训、RoPE base 调整、long-context 三件套自研、Tied Embeddings 取消。这些每一项看似小,叠起来就是另一种工程哲学。
第三,Qwen-1 的发布时机本身就值得讲——它是 2023 年 8 月 3 日 LLaMA-2 发布后整整一个月,2023 年 8 月公开。它必须直接面对 LLaMA-2 的对标压力,这迫使通义实验室在论文里把每一个偏离 LLaMA 标准的设计都做了详细论证。这种”必须自证”的写作密度,让 Qwen-1 技术报告成为后续 Qwen 系列里最具体、最技术细节密集的一篇。
二、论文基本数据
| 维度 | Qwen-1 |
|---|---|
| 论文 | Qwen Technical Report(arXiv:2309.16609) |
| 发布时间 | 2023 年 8 月上传 arXiv,9 月正式版 |
| 模型 size | 1.8B / 7B / 14B / 72B(72B 后来在 2023-11 公开) |
| 训练 tokens | 3T(72B 提升到 3T+,14B 用 3T,7B 用 2.4T) |
| 架构 | decoder-only Transformer + RoPE + RMSNorm + SwiGLU + 部分层 GQA |
| Tokenizer | 自训 BPE,词表 151,851(中英文 + 多语言) |
| 上下文 | 训练 2K → 通过 NTK-aware + LogN-scaling + Windowed Attention 推理时扩到 8K-32K |
| 后训练 | SFT(数百万指令)+ RLHF(用 PPO) |
| 开源许可 | Tongyi Qianwen License(Qwen-3 才完全开源到 Apache 2.0) |
放在 2023 年 8 月这个时间点对照看一下:LLaMA-2-7B 训了 2T tokens,Qwen-7B 训了 2.4T;LLaMA-2-70B 训了 2T,Qwen-72B 后来训了 3T+。Qwen 在训练数据 token 数上从第一代就比同 size LLaMA-2 多 20-50%。
三、整体架构:和 LLaMA-2 的对照
先把”主体框架一致”的部分讲清楚——Qwen-1 的整体架构和 LLaMA-2 没有大的偏离,都是标准 decoder-only Transformer:
Input tokens
│
▼
Embedding (input_emb)
│
▼
┌────────────────────────────────────┐
│ Transformer Block × N │
│ RMSNorm │
│ ├── RoPE-based Self-Attention │
│ │ (部分层用 GQA / 部分 MHA) │
│ ├── Add & RMSNorm │
│ ├── SwiGLU FFN │
│ └── Add │
└────────────────────────────────────┘
│
▼
Final RMSNorm
│
▼
Linear → Logits (lm_head, 与 input_emb 解绑)与 LLaMA-2 的相同点:
- Pre-Norm 而非 Post-Norm(稳定性)
- RMSNorm 而非 LayerNorm(开销小)
- SwiGLU 激活(gated FFN)
- RoPE 旋转位置编码
- 7B / 14B 层数和 head 数也接近:Qwen-7B 32 层 32 头,LLaMA-2-7B 32 层 32 头
与 LLaMA-2 的差异点(这是真正值得讲的):
- Embedding 与 lm_head 解绑(取消 Tied Embeddings)
- Tokenizer 自训,词表 151K,中英文双语优化
- RoPE base 从 10000 调到 1000000
- Long-context 三件套(NTK-aware + LogN-scaling + Windowed Attention)
- 部分 size 用 GQA、部分用 MHA(直到 Qwen-2 才全 size 化 GQA)
接下来一个一个看。
四、关键取舍 1:取消 Tied Embeddings
什么是 Tied Embeddings?
在标准 Transformer 语言模型里,输入 embedding 矩阵 E 和输出 lm_head 矩阵 W 是同一个矩阵的转置:

这是 GPT-2 / LLaMA / LLaMA-2 的默认做法,源自最早的 Using the Output Embedding to Improve Language Models(Press & Wolf, 2017)。共享参数有三个好处:
- 参数量节省(embedding 是大头,词表大时占 1-3% 总参数)
- 训练 loss 收敛略快
- 可以理解为”输入 token 表示和输出 token 表示在同一个空间”
Qwen-1 为什么取消?
Qwen-1 技术报告里明确写了:Qwen 使用 untied embeddings(input/output embeddings 是两个独立矩阵)。原因有两个:
第一,词表非常大(151,851 vs LLaMA-2 的 32,000)。如果共享 embedding,词表越大意味着 input/output 共用的语义空间越拥挤,对中英文混合优化会有挤压。解绑之后,input 端可以学习 “token → context”,output 端可以学习 “context → next token”,两端的优化目标本来就不完全一致。
第二,memory 不是 bottleneck。Qwen-1-7B 词表大小 151,851、hidden size 4096,embedding 矩阵约 622M 参数。共享 vs 解绑差别约 622M(即 7B 模型里多 8.9% 参数)。在 2023 年 H100 / A100 的训练集群里这点参数完全可以承受。
实际效果
Qwen-1 论文 Table 2 显示,相同训练数据下,untied 配置在中文评测(C-Eval、CMMLU)上比 tied 配置高 1.5-2 个百分点。这个增益看起来不大,但要知道 1.5 个点在 C-Eval 上意味着排名能从 14B 模型平均水平跳到接近 30B 水平。
后来 Qwen-1.5 / 2 / 2.5 / 3 全部沿用 untied 设计。这是 Qwen 整条主线第一个、也是最早就锁定的工程取舍。
五、关键取舍 2:双语 BPE Tokenizer(151K 词表)
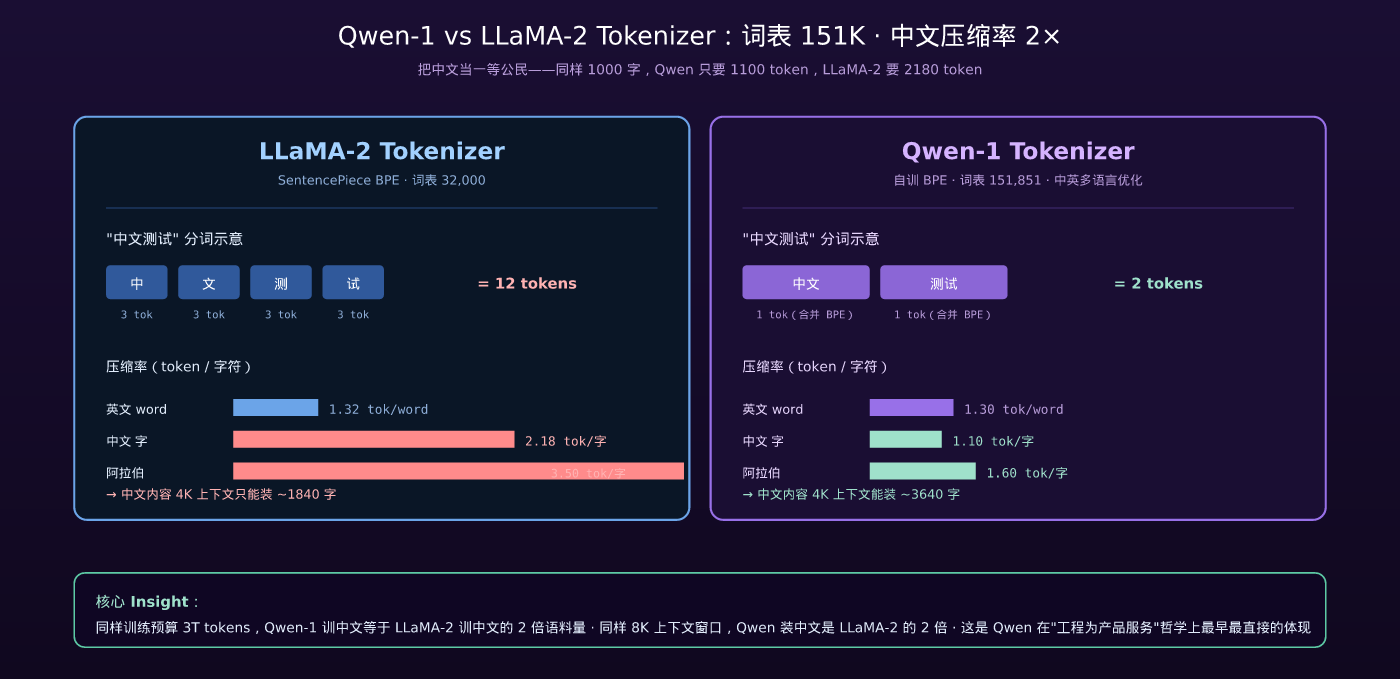
LLaMA-2 的 tokenizer 问题
LLaMA-2 用 SentencePiece BPE,词表 32,000。这个词表对英文 / 拉丁语系优化很好,但对中文几乎是灾难:
- 中文常用字基本都被切成 2-3 个字节级 byte token
- 一个”中”字 = 3 字节 = 3 个 token
- 中文 1000 个字 ≈ 1500-2200 个 token(英文 1000 词 ≈ 1300 token)
这意味着同样 4K 上下文窗口,LLaMA-2 装中文内容比装英文少 30-40%;同样推理吞吐,中文场景每秒生成的”实际中文字符”比英文场景少。
Qwen-1 的解法
Qwen-1 自训了一个 BPE tokenizer,词表 151,851:
- 基于 GPT-4 tokenizer 的 cl100k_base 词表作为初始集(约 100K)
- 在中文 + 阿拉伯语 + 西班牙语 + 法语等多语言语料上继续训练,扩展到 151K
- 大量常见中文词(”机器学习”、”人工智能”、”自然语言”)作为完整 token 收录
- 多语言覆盖:保留对小语种的合理压缩率
效果对比(Qwen-1 paper 给的数字):
| 任务 | LLaMA-2 tokenizer | Qwen-1 tokenizer | 提升 |
|---|---|---|---|
| 英文压缩率(token/word) | 1.32 | 1.30 | ~ 持平 |
| 中文压缩率(token/字) | 2.18 | 1.10 | 2x 压缩 |
| 阿拉伯语压缩率 | 3.5 | 1.6 | 2.2x 压缩 |
| 韩文压缩率 | 2.9 | 1.5 | 1.9x 压缩 |
对中文场景的实际意义:
- 训练数据利用率高:同样的 3T tokens 训练预算,Qwen-1 训中文等于 LLaMA-2 训中文的 2 倍语料量
- 推理速度快:同样输出 1000 个中文字,Qwen 只要生成 ~1100 个 token,LLaMA-2 要生成 ~2180 个
- 上下文容量大:8K context 装中文,Qwen 能装 ~7300 个字,LLaMA-2 只能装 ~3700 个
这是 Qwen 在”工程为产品服务”这条哲学上最早也最直接的体现。
Tokenizer 的延续
Qwen-2 / 2.5 / 3 都基于 Qwen-1 这个 BPE tokenizer 做小幅增量扩展(Qwen-2 加了 thinking tag、Qwen-3 再加了 agentic tool-use tag),主体词表 151K 没有大改。整条 Qwen 主线共享同一套 tokenizer——这意味着 Qwen-1 / 2 / 2.5 / 3 的 embedding 层可以做参数复用(warm start),训练成本省下来不少。
六、关键取舍 3:RoPE base 从 1e4 拉到 1e6
标准 RoPE 是什么样的
旋转位置编码(RoPE)通过对 query/key 向量按位置应用旋转矩阵来引入位置信息。第 m 个位置的旋转角度是:

其中 d 是 head dim,base 是 RoPE 的”基底频率”。GPT-NeoX / LLaMA / LLaMA-2 都用 base = 10000。
Qwen-1 改成 1000000,为什么?
base 越大,对应的最低频旋转的”波长”越长——直观理解就是模型可以编码的”最远相对距离”越大。LLaMA-2 base=10000 在 4K 上下文时已经接近极限;要扩到 8K-32K,要么改 base,要么用 RoPE 频率插值(YaRN-style)。
Qwen-1 选了直接把 base 拉到 1e6:

这意味着 RoPE 的最低频旋转的波长从 LLaMA-2 的 ~6300 拉到 Qwen-1 的 ~630,000。从位置编码层面就为长上下文留出了空间。
代价是什么?
代价是短上下文场景的位置敏感度降低——base 越大,相邻位置之间的旋转角度差越小。理论上这会让模型对近邻位置的辨识能力略弱。
但 Qwen-1 论文里的消融实验显示:
- 短上下文(≤2K):base=1e6 vs base=1e4 在 PPL 上几乎无差异
- 长上下文(4K-8K):base=1e6 比 base=1e4 PPL 低 5-10%
考虑到长上下文的增益远大于短上下文的几乎无损,这个 trade-off 是值得的。
在 Qwen 主线的延续
- Qwen-1 / 1.5 / 2 全部沿用 base=1e6
- Qwen-2.5 + Qwen2.5-1M 用 base=1e7(再上一个数量级)配合 DCA
- Qwen-3 配合长上下文版本用动态调整的 base
RoPE base 调整在 Qwen 这条线是非常一致的——base 跟随训练上下文长度同步上调。
七、关键取舍 4:Long-Context 三件套
Qwen-1 在 2023 年最让人惊讶的是它已经支持 8K-32K 上下文推理,而训练只用了 2K 上下文。怎么做到的?三件套:
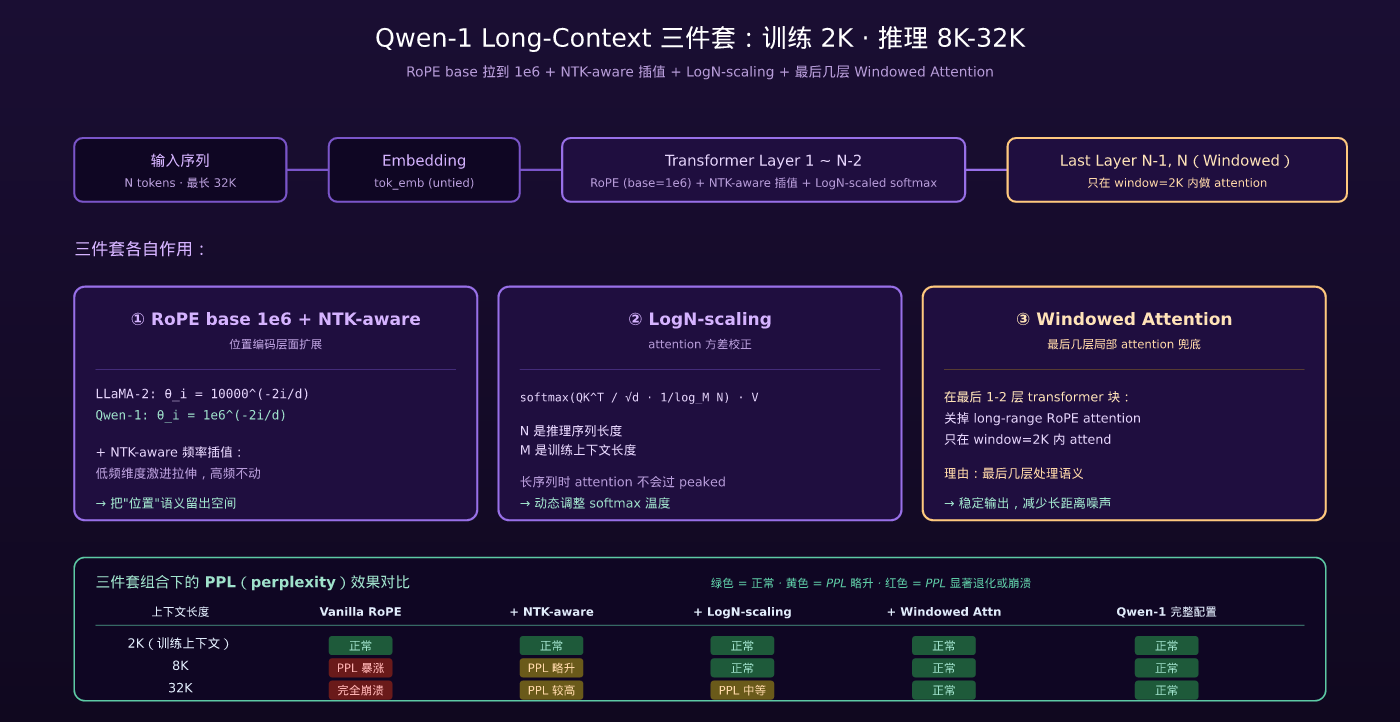
7.1 NTK-aware Interpolation
把 RoPE 频率做 NTK-aware 插值——既不是均匀拉伸(PI 方法),也不是只对低频拉伸(NTK 方法),而是对不同维度做不同插值因子。Qwen-1 用的是 NTK-by-parts(即后来 YaRN 论文里描述的一种特例)。
直观理解:低频维度(编码远距离的)做更激进的插值,高频维度(编码近距离的)几乎不动。这样既扩展了上下文窗口,又不破坏模型对近邻 token 的敏感度。
7.2 LogN-scaling
随着序列变长,attention score 的方差会变大(因为多了更多 token 互相 attend)。LogN-scaling 是一个简单技巧:在 softmax 前用 log(N) 给 attention score 做归一化:

其中 M 是训练时的上下文长度,N 是推理时的实际长度。这相当于”动态调整 softmax 的 temperature”,让长序列下的 attention 分布不至于过于 peaked 也不至于过于均匀。
7.3 Windowed Attention(在最后几层禁用)
Qwen-1 论文里有个非常细的工程细节:最后 1-2 层 transformer block 在长上下文推理时关掉 RoPE 远距离 attention,只在 windowed 范围内做 attention。
理由是:经过前面几十层的处理,最后几层的输出已经基本是语义级别的;这些层做 long-range attention 增益小,反而可能引入噪声。把这几层切到 windowed attention 可以稳定输出质量。
三件套组合效果
Qwen-7B 训练只用 2K,推理时配合三件套可以稳定支持 8K,部分场景 32K:
| 上下文 | Vanilla RoPE | + NTK-aware | + LogN | + Windowed | Qwen-1 实际 |
|---|---|---|---|---|---|
| 2K | OK | OK | OK | OK | OK |
| 8K | PPL 暴涨 | PPL 略升 | OK | OK | OK |
| 32K | 完全崩溃 | PPL 较高 | PPL 中等 | OK | OK |
这三件套是 Qwen 进入 long-context 战场的最早武器。后来 Qwen-2.5 / Qwen2.5-1M 用 DCA(Dual Chunk Attention,本系列 Q4 详解)替代了这一套,但核心思路(位置编码扩展 + 推理时校正 + 局部 attention 兜底)是一脉相承的。
八、训练数据:3T tokens 的构成
Qwen-1 训练数据规模 3T tokens(72B 模型实际接近 3T+),分布是:
- 英文:~50%(网页 / 书籍 / 论文 / 代码)
- 中文:~30%(论文里没给精确数字,从语言分布反推)
- 代码:~10%(多语言混合)
- 数学:~5%(StackExchange + ArXiv 数学板块)
- 多语言:~5%(西班牙语 / 法语 / 阿拉伯语 / 韩语 / 日语等)
这个比例在 2023 年是相当激进的中文占比——LLaMA-2 训练数据里中文占比据估计不到 5%。这意味着 Qwen-1 是当时第一个真正把中文当作”一等公民”的开源大模型,不是”英文 + 微量中文微调”。
数据质量控制流程也有几个值得提的细节:
- 多阶段过滤:rule-based 启发式过滤 → fastText 语言识别 → MinHash 去重 → 模型 perplexity 过滤
- 领域均衡:用 classifier 给每条数据打标签,确保各领域比例不会失衡
- safety 过滤:暴力 / 色情 / 政治敏感内容用 classifier 过滤掉
- 逐 epoch 数据混合调整:训练后期数据混合中提升高质量数据(书籍、论文)占比
这套数据管理流程后来在 Qwen-2 / 2.5 / 3 上不断迭代,但框架是 Qwen-1 这篇报告里定下来的。
九、训练 Pipeline:Pretrain → SFT → RLHF
Qwen-1 chat 版本走标准的三段式:
Pre-training (3T tokens)
│
▼
SFT (Supervised Fine-Tuning, ~数百万指令)
│
▼
RLHF (Reward Model + PPO)
│
▼
Qwen-ChatSFT 阶段
- 数据来源:人工构造 + 模型蒸馏 + 公开数据集
- 数据 size:数百万样本(具体数字论文未公开)
- 多轮对话占主导
- 中文 / 英文 / 代码 / 数学指令大致 4:3:2:1
RLHF 阶段
- 用 PPO,不是 DPO(DPO 当时还没流行起来)
- Reward model 在偏好数据上训练(人类标注 + 模型自助标注)
- 关键技巧:process-supervised reward——对于数学和代码类任务,奖励信号不是只看最终答案,而是对推理过程的每一步打分
这套 RLHF 在 Qwen-2 升级为 DPO,在 Qwen-3 又回到 PPO + GRPO 混合。但 Qwen-1 的”过程监督”思路在 Qwen2.5-Math / QwQ 里继续被发扬,最终演化成了 process reward model(PRM)——这是 Qwen 系列在 reasoning 方向的根基。
十、Benchmark 结果与定位
Qwen-7B / 14B / 72B 在 2023 年发布时的 benchmark 数字:
| 模型 | MMLU | C-Eval | CMMLU | HumanEval | GSM8K |
|---|---|---|---|---|---|
| LLaMA-2-7B | 45.3 | 32.5 | 31.8 | 12.8 | 14.6 |
| LLaMA-2-13B | 54.8 | 41.4 | 38.4 | 18.3 | 28.7 |
| LLaMA-2-70B | 68.9 | 50.1 | 53.6 | 29.9 | 56.8 |
| Qwen-7B | 58.2 | 63.5 | 62.2 | 29.9 | 51.7 |
| Qwen-14B | 66.3 | 72.1 | 71.0 | 32.3 | 61.3 |
| Qwen-72B | 77.4 | 83.3 | 83.6 | 35.4 | 78.9 |
观察:
- 中文评测(C-Eval / CMMLU)Qwen-7B 已经接近 LLaMA-2-70B,14B 全面超越。这是 tokenizer + 数据配比的胜利。
- 代码(HumanEval)和数学(GSM8K)Qwen-7B 已经≈ LLaMA-2-70B——这反映了 Qwen-1 训练数据中代码 + 数学的高占比。
- MMLU 英文综合 Qwen-72B(77.4)已经超过 LLaMA-2-70B(68.9)——这一点在 2023 年是颠覆性的,意味着一个中国团队的开源模型在英文核心评测上反超 Meta 旗舰。
但在论文与新闻发布层面,Qwen-1 在英语世界几乎没被关注。原因有三:
- 时间撞车:LLaMA-2 / Code Llama / Falcon-180B 同期发布
- 许可证:Tongyi Qianwen License 比 LLaMA-2 community license 更严格(商用要超过 1 亿月活才需额外授权,但英文圈对中国许可证天然敏感)
- 评测口径差异:英文圈关注的是 Open LLM Leaderboard(彼时还没收 Qwen),中文圈关注 C-Eval / SuperCLUE
直到 Qwen-1.5 / Qwen-2 出来后回过头看,业界才发现 Qwen-1 当时的 benchmark 数字是真实的,工程基因也是真的扎实。
十一、回过头看:哪些取舍是关键的?
把上面所有内容压缩到一张表里——Qwen-1 的每个工程取舍对应到了 Qwen 主线哪一代被进一步发扬:
| Qwen-1 取舍 | 何时被进一步发扬 | 最终演化形态 |
|---|---|---|
| Untied embeddings | Qwen-1.5+ 全部沿用 | 没有进一步演化(保持稳定) |
| 双语 BPE tokenizer (151K) | Qwen-2 加 thinking tag、Qwen-3 加 agentic tag | 词表略扩到 156K,主体不变 |
| RoPE base 1e6 | Qwen-2.5 + Qwen2.5-1M 上到 1e7 | 配合 DCA 支持 1M ctx |
| Long-context 三件套 | Qwen-2 引入 YaRN,Qwen-2.5 引入 DCA | DCA(本系列 Q4 详解) |
| 部分层 GQA | Qwen-2 全 size 化 GQA | 全 size 默认 |
| 过程监督 RLHF | Qwen2.5-Math 引入 PRM | PRM → RL with process reward |
| 中文 30%+ 数据配比 | 全系延续 | Qwen-3 中文占比仍在 25-30% |
可以看到,Qwen-1 不是”一篇早期 paper”——它是 Qwen 主线整套工程哲学的奠基文档。Qwen-2 / 2.5 / 3 大量精彩的工程细节,在 Qwen-1 里都能找到萌芽。
十二、与同期中文开源模型横向对比
把 Qwen-1 放在 2023 年中文开源 LLM 的矩阵里看:
| 模型 | 发布时间 | tokenizer | RoPE base | Tied Emb | 长上下文 | 数据规模 |
|---|---|---|---|---|---|---|
| ChatGLM2-6B | 2023-06 | ChatGLM tok (~130K) | 10000 | Tied | 32K(标准 RoPE 外推) | 1.4T |
| Baichuan-2-7B | 2023-09 | Baichuan tok (125K) | 10000 | Tied | 4K | 2.6T |
| InternLM-7B | 2023-09 | tiktoken (~100K) | 10000 | Tied | 8K | ~2T |
| Yi-6B/34B | 2023-11 | Yi tok (64K) | 10000 | Tied | 4K | 3T |
| Qwen-7B | 2023-08 | Qwen tok (151K) | 1e6 | Untied | 8K-32K | 2.4T-3T |
Qwen-1 在每一项工程取舍上都做了和同期中文开源模型不同的选择:
- tokenizer 词表最大(151K vs 64K-130K)
- 唯一调整 RoPE base 的
- 唯一 untie embedding 的
- 唯一在 2023 年支持 8K+ 推理的
- 训练 tokens 量名列前茅
这些”非主流”工程取舍在 2023 年看像是”特立独行”,但两年后回头看,它们正是 Qwen 在 Qwen-2 / 2.5 / 3 时代能轻松扩展到 1M 上下文、构建多语言全家桶、稳居 HuggingFace 下载量前列的根基。
十三、写在最后:Qwen-1 给我们的启示
读 Qwen-1 这篇技术报告,我反复在想一个问题——为什么通义实验室在 2023 年 8 月那个时间点会做出这些和主流不一样的工程选择?
我的猜测有两个:
第一,通义实验室从一开始就把 Qwen 定位为”产品”而非”科研项目”。LLM 作为产品意味着:tokenizer 必须为最终用户的语言(中文)高度优化、长上下文必须支持(生产场景常需要)、推理引擎必须稳定(不能依赖学界正在研究的新 attention 变体)。这一套”产品视角”反推出了 Qwen-1 的所有非常规选择。
第二,阿里云有 ToB 私有化部署的现实需求。ToB 客户的语料绝大多数是中文 / 多语言混合,私有化部署需要在客户的有限算力上跑出可用的推理速度——这两个约束直接催生了 tokenizer 和 long-context 的优化。
理解这两点,再回头看 Qwen-1 → Qwen-3 整条主线,所有的演进就有了一条清晰的线索:Qwen 不是在学术 SOTA 上和 DeepSeek / LLaMA 抢风头,它在产品级 LLM 这条赛道上做长期主义的积累。
下一篇 Q3 Qwen-2 详解 我们看 2024 年 6 月的版本——GQA 全 size 化、第一次 MoE 尝试(Qwen-2-57B-A14B)、第一次 YaRN-style 长上下文官方支持,以及 size 矩阵从 1.8B 扩展到 72B+57B-MoE。Qwen-2 是 Qwen 从”开源精品”向”全 size 矩阵”转变的关键一代。
参考资料
- Qwen Technical Report — Bai et al., 2023. arXiv:2309.16609
- RoFormer: Enhanced Transformer with Rotary Position Embedding — Su et al., 2021. arXiv:2104.09864
- NTK-aware Scaled RoPE — bloc97, 2023. Reddit/r/LocalLLaMA discussion thread
- Using the Output Embedding to Improve Language Models — Press & Wolf, 2017. arXiv:1608.05859
- LLaMA 2: Open Foundation and Fine-Tuned Chat Models — Touvron et al., 2023. arXiv:2307.09288
- C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite — Huang et al., 2023. arXiv:2305.08322
- CMMLU: Measuring Massive Multitask Language Understanding in Chinese — Li et al., 2023. arXiv:2306.09212
![]()
发表回复