Tag Qwen
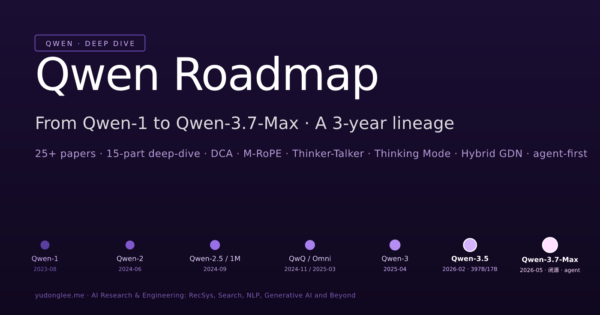
Qwen 论文专题系列序章 —— 把通义实验室 2023-08 → 2026 全部 Qwen 主线 + 6 大专项分支 paper 按「三代主线 + 多模态/Coder/Math/QwQ 分支」梳理成完整脉络,串讲 GQA 全 size 化、Dual Chunk Attention、M-RoPE / TMRoPE、Built-in Thinking Mode、Thinker-Talker 五大核心创新,并对比 Qwen 与 DeepSeek 两条中国开源 LLM 路径。
![]()