
转载本文请注明出处:https://yudonglee.me/qwen-audio-series-explained/ | 作者:yudonglee

本文是 Qwen 论文专题系列 第八篇。我们继续看 Qwen 多模态全家桶的第二根支柱——Qwen-Audio 系列。从 2023-11 与 Qwen-1 同期发布的 Qwen-Audio(arXiv:2311.07919),到 2024-07 的 Qwen2-Audio(arXiv:2407.10759),这条线一共两代。两代的核心命题是同一个:用一个 LLM 统一覆盖三类音频(speech / 自然声 / 音乐)+ 30+ 个音频任务——不需要为 ASR / 语音翻译 / 音频分类 / 音乐情感识别等分别训独立模型。Qwen2-Audio 在此基础上引入 Voice Chat + Audio Analysis 双模式,用户既可以直接和模型语音对话,也可以让模型”分析”一段音频。本文一次把两代讲完。
一、引言:Qwen-Audio 在多模态全家桶里的位置
Q7 Qwen-VL 系列详解 里我说 Qwen 的多模态战略是”全家桶 + 与主线同节奏”。VL 系列处理视觉,Qwen-Audio 处理音频,两条线互不重叠又互为补充——加起来覆盖了”人能感知的所有非文字信号”。
Qwen-Audio 系列的时间线:
2023-11 Qwen-Audio 7B · Whisper-Large-V2 encoder · 30+ 任务统一训练
↑ 与 Qwen-1 + Qwen-VL 同期(间隔 3 个月)
2024-07 Qwen2-Audio 7B · 升级 encoder · ★ Voice Chat + Audio Analysis 双模式
↑ 与 Qwen-2 同期发布
2025-03 Qwen2.5-Omni 全模态融合,Audio 能力被 Omni 收编(详见 Q9 Omni 详解)
注意一个关键事实:Qwen-Audio 系列只有两代独立发布——从 2025-03 开始,Audio 能力被 Qwen2.5-Omni(Q9 主题)以更激进的”统一全模态”方式收编。所以 Qwen-Audio 实际是 Qwen 多模态战略中承前启后的一代:它为后来 Omni 路线的所有架构选择(unified token 空间 / TMRoPE / Thinker-Talker)做了大量前期实验。
两代的核心命题:
- Qwen-Audio(2023-11):奠基——证明”一个 LLM 可以同时处理 speech / 自然声 / 音乐”,用层级标签做 30+ 任务联合训练
- Qwen2-Audio(2024-07):扩展——引入 Voice Chat + Audio Analysis 双模式,DPO 后训练,去掉了人为标签依赖
理解 Qwen-Audio 不只是理解”另一个 audio LLM”——它揭示了 Qwen 团队如何从”每种模态各做一个模型”演化到”所有模态统一在一个 LLM 里”的工程过程。
二、Qwen-Audio 系列论文一览
| 维度 | Qwen-Audio(2023-11) | Qwen2-Audio(2024-07) |
|---|---|---|
| 论文 | arXiv:2311.07919 | arXiv:2407.10759 |
| 模型 size | 7B | 7B |
| LLM backbone | Qwen-1-7B | Qwen-1.5-7B(Qwen-2 系列还没正式释出时) |
| 音频 encoder | Whisper-Large-V2(约 0.6B 参数) | 升级版(Whisper 微调) |
| 音频任务数 | 30+(ASR / S2TT / SER / 自然声分类 / 音乐情感 / …) | 同 + Voice Chat 任务 |
| 训练范式 | Hierarchical tag-based multi-task | Voice Chat + Audio Analysis 双模式 |
| 后训练 | SFT | SFT + DPO |
| 音频长度 | 单条 ≤ 30 秒(Whisper 限制) | 同 + 部分场景延伸 |
| 输入语言 | 主要中英文 + 部分多语言 | 8 种语言扩展(中英日韩德法西俄) |
| 协议 | Tongyi Qianwen License | Apache 2.0 |
| 关键贡献 | 统一架构 + 30+ 任务证明可行 | 双模式 + DPO + 多语言扩展 |
放到同期对比:
| 时间 | Qwen-Audio 代 | 同期同类竞品 |
|---|---|---|
| 2023-11 | Qwen-Audio-7B | LTU(学术,2023-04)· SALMONN(清华,2023-10)· Pengi(微软,2023-05) |
| 2024-07 | Qwen2-Audio-7B | SALMONN-V2 · LLaMA-Audio · GAMA(CMU) |
Qwen-Audio 是 2023-11 时点开源 audio LLM 里第一个真正工业级的——其他模型要么任务覆盖窄(只做 ASR + speech caption),要么模型规模小(不到 1B),要么效果差。Qwen-Audio 同时做到了”30+ 任务覆盖 + 7B 规模 + 接近专项模型效果”。
三、Qwen-Audio 的核心范式:用一个 LLM 统一所有音频任务
3.1 业界传统的 Audio AI 是分裂的
在 Qwen-Audio 之前,业界 audio AI 是按”任务”分裂的:
- Speech(语音)→ ASR / TTS / S2TT 各有专项模型(Whisper / VITS / SeamlessM4T)
- 自然声(环境音、动物声、机械声)→ Audio classification 模型(PANNs / AST)
- 音乐(情感、流派、风格)→ Music tagging 模型(VGGish / OpenL3)
每类任务一个甚至多个独立模型。这意味着:
- 训练资源浪费:相似的底层音频特征要被各模型从头学习
- 能力组合困难:无法同时分析”这段音频是什么人在什么环境下说了什么”
- 跨模态推理缺失:无法用”语言推理 + 音频感知”的组合处理”先听听这段音乐再告诉我情绪走向”等任务
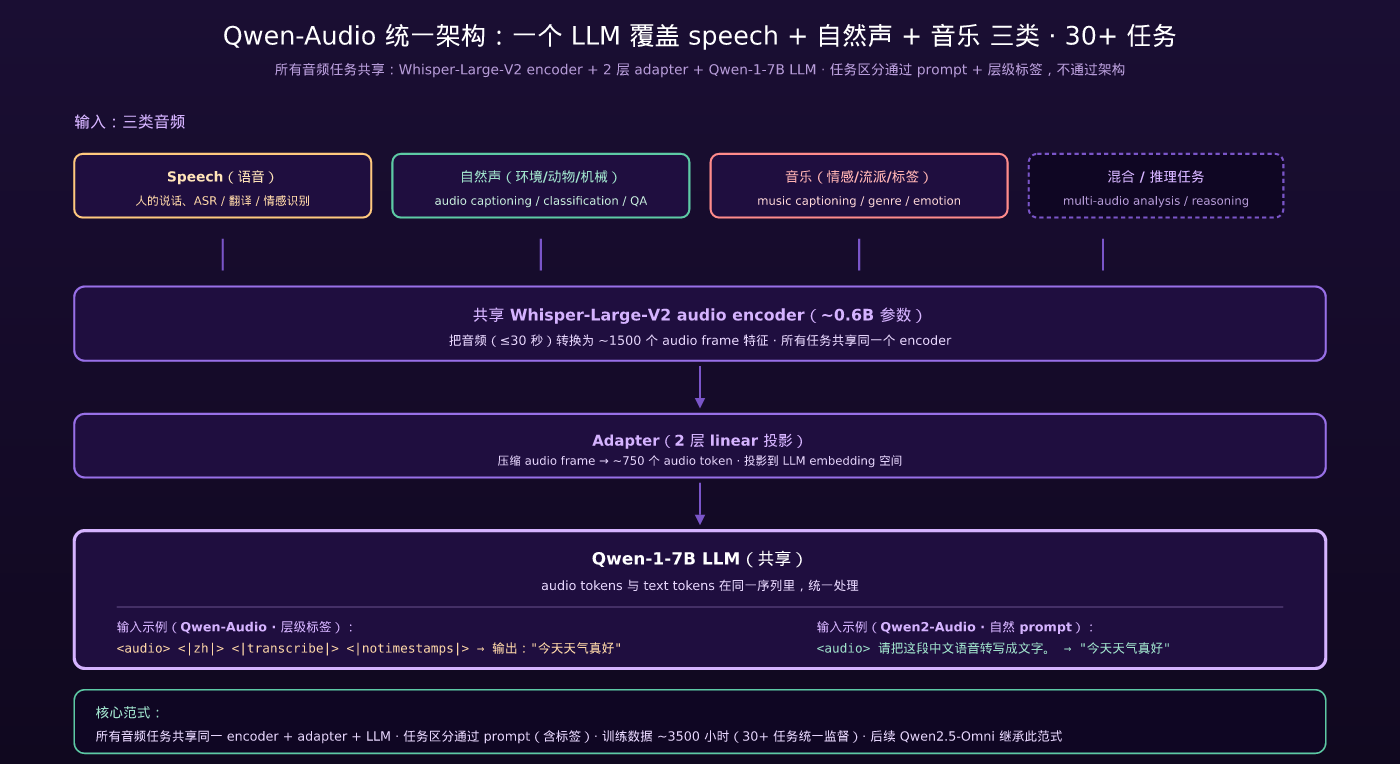
3.2 Qwen-Audio 的解法:统一架构
Qwen-Audio 的整体架构:
Audio input (30 秒以内)
│
▼
Whisper-Large-V2 audio encoder
│ (产生 ~1500 个 audio frame 特征)
▼
Adapter(2 层 linear,把音频特征压缩 + 投影到 LLM embedding 空间)
│ (产生 ~750 个 audio token)
▼
┌────────────────────────────────────────┐
│ Qwen-1-7B LLM │
│ audio tokens 与 text tokens │
│ 在同一序列里 │
│ │
│ 输入:<audio> + 任务标签 + text prompt │
│ 输出:text 回答 │
└────────────────────────────────────────┘
关键设计:
- 共享音频 encoder:所有任务都用同一个 Whisper-Large-V2 + 同一个 adapter
- 共享 LLM:所有任务都用同一个 Qwen-1-7B 输出文本
- 任务区分通过 prompt + 标签,不通过架构
3.3 30+ 个任务覆盖了什么?
Qwen-Audio paper 里列出的 30+ 任务,可以按音频类型分四类:
| 类别 | 代表任务 | 数据集 |
|---|---|---|
| Speech(语音) | ASR、Speech-to-text translation、Speaker verification、Speech emotion recognition、Vocal sound classification | LibriSpeech、AISHELL、CoVoST、IEMOCAP |
| 自然声 | Audio captioning、Audio question answering、Audio classification、Sound event detection | AudioCaps、ESC-50、TUT |
| 音乐 | Music captioning、Music tagging、Music genre classification、Music emotion recognition | MusicCaps、GTZAN、AudioSet music |
| 混合 / 创新 | Audio reasoning、Multi-audio analysis、Conditional audio analysis | 自合成 |
这 30+ 任务的训练数据汇总约 3,500 小时音频 + 对应文本——为统一模型提供了足够的多任务监督信号。
四、Qwen-Audio 的关键技术:Hierarchical Tag-based Multi-task Training
4.1 为什么需要层级标签?
30+ 任务同时训练有一个挑战:模型怎么知道当前输入想要哪种输出?
例子:同样一段音频”一个女人说『今天天气真好』然后笑了”,可能的任务包括:
- ASR → 输出”今天天气真好”
- Speaker gender recognition → 输出”female”
- Speech emotion recognition → 输出”happy”
- Audio captioning → 输出”一个女人说话后笑”
如果只用自然语言 prompt 描述任务,模型容易混淆任务边界。Qwen-Audio 用层级标签显式标注每个任务,让模型在训练时学会”看到这个标签时该输出什么”。
4.2 三层标签结构
Qwen-Audio 的标签是三层结构:
<|audio_lang|> · <|task|> · <|fine_tag|>
例子:
<|zh|> <|transcribe|> <|notimestamps|>→ ASR 中文转写、不输出时间戳<|en|> <|translate|> <|zh|>→ 英文音频翻译成中文<|audio|> <|caption|> <|short|>→ 自然声音频做短描述<|music|> <|emotion|> <|major_only|>→ 音乐情感识别,只输出主要情感<|speech|> <|speaker_age|> <|range|>→ 说话者年龄段估计
层级化的好处:
- 任务可组合:模型学到的是”audio_lang × task × fine_tag”的组合,可以泛化到训练没见过的组合
- 细粒度控制:用户可以精确指定想要的输出形式(短/长、含/不含时间戳)
- 训练数据利用率高:同一段音频可以用多个标签组合训练多个任务
4.3 Hierarchical 标签 vs 业界其他多任务方案
| 方案 | 多任务区分方式 |
|---|---|
| Whisper | hardcoded 任务 token(<|transcribe|> / <|translate|>),只两个任务 |
| SeamlessM4T | hardcoded 语言 ID + 任务 ID |
| SALMONN | 完全自然语言 prompt 描述任务(无标签) |
| Pengi | 单一任务 prompt(没有多任务联合) |
| Qwen-Audio | 三层结构化标签(audio_lang × task × fine_tag),覆盖 30+ 任务 |
Qwen-Audio 这种”结构化层级标签 + LLM 统一输出”的范式后来被 Qwen2.5-Omni 继承——Omni 的所有模态都用类似的标签控制行为。
五、Qwen2-Audio:去掉标签依赖 + Voice Chat / Audio Analysis 双模式
5.1 Qwen2-Audio 的核心改动
Qwen2-Audio(2024-07,arXiv:2407.10759)相对 Qwen-Audio 做了三个核心改动:
改动 ①:去掉层级标签依赖,让用户用自然语言交互
Qwen-Audio 的层级标签虽然结构化好,但用户使用门槛高——一般用户不会写 <|zh|> <|transcribe|> <|notimestamps|> 这种 prompt。Qwen2-Audio 改成纯自然语言 prompt:
旧 (Qwen-Audio): <audio> <|zh|> <|transcribe|> <|notimestamps|> 新 (Qwen2-Audio): <audio> 请把这段中文语音转写成文字。
模型在训练时学会从自然语言 prompt 推断任务——这与 Qwen-3 的 Built-in Thinking Mode 的”prompt 控制行为”哲学一脉相承。
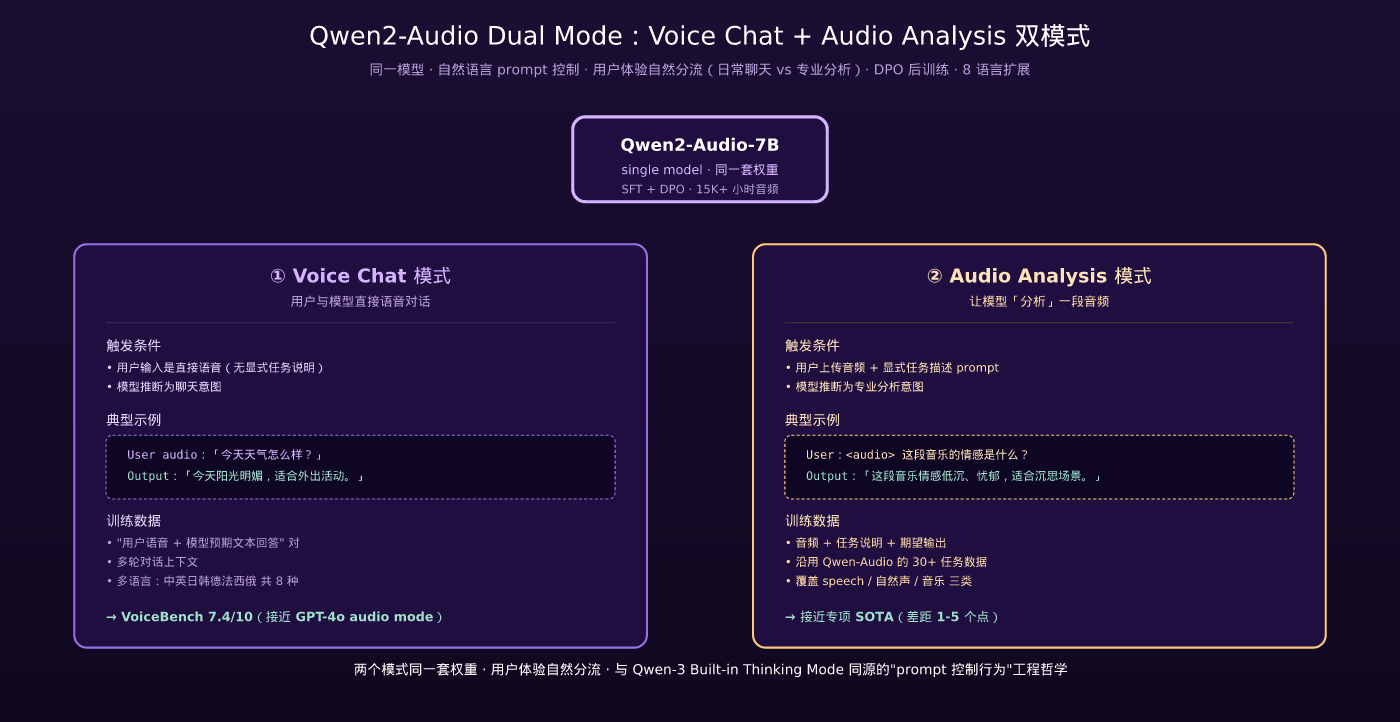
改动 ②:Voice Chat + Audio Analysis 双模式
Qwen2-Audio 把任务分成两大类:
| 模式 | 用户意图 | 典型场景 |
|---|---|---|
| Voice Chat | 与模型直接语音对话 | 用户说话 → 模型用语音 / 文本回答 |
| Audio Analysis | 让模型”分析”一段音频 | 用户上传音频 → 模型描述 / 分类 / 推理 |
这两个模式的训练数据完全不同:
- Voice Chat:数据是”用户语音 + 模型预期文本回答”对
- Audio Analysis:数据是”音频 + 任务说明 + 期望输出”
双模式的关键工程价值:用户体验自然分流——日常聊天用 Voice Chat(不需要解释”我想要什么任务”),专业分析任务用 Audio Analysis。
改动 ③:DPO 后训练
Qwen-Audio 只做 SFT;Qwen2-Audio 引入 DPO(沿用 Qwen-2 主线的后训练范式)。DPO 的偏好数据主要来自:
- 人类标注的”哪个回答更准确”
- 自动评估器(如 GPT-4)打分的偏好对
- ASR 真实转写 vs 错误转写对(用合成噪声生成)
DPO 后训练让 Qwen2-Audio 在指令跟随 + 安全性上比 Qwen-Audio 有明显提升。
5.2 多语言扩展
Qwen2-Audio 把支持的语言扩到 8 种:中文、英语、日语、韩语、德语、法语、西班牙语、俄语。覆盖全球主要 ToC 市场——这是 Qwen 全家桶战略的多语言扩展的一部分(与主线 Qwen-2 同步扩展)。
六、统一架构 vs 业界分裂方案的工程对比
把 Qwen-Audio 系列和业界其他 audio LLM 方案对比:
| 方案 | 模态覆盖 | 任务数 | LLM backbone | 多任务训练范式 |
|---|---|---|---|---|
| Whisper | speech only | 2 (ASR + S2TT) | encoder-decoder(无独立 LLM) | hardcoded 标签 |
| SeamlessM4T(Meta) | speech + text | translation 多任务 | encoder-decoder | hardcoded 语言对 |
| SALMONN(清华) | speech + audio | ~10 | Vicuna-13B | 纯 prompt |
| GAMA(CMU 2024) | audio analysis | ~15 | LLaMA-2-7B | prompt |
| Pengi(Microsoft) | audio | 8 | LLaMA-2-7B | 单任务 prompt |
| Qwen-Audio | speech + 自然声 + 音乐 | 30+ | Qwen-1-7B | Hierarchical 标签 → 自然语言 prompt |
| Qwen2-Audio | 同 + voice chat | 30+ | Qwen-1.5-7B | Voice Chat + Audio Analysis 双模式 |
观察:
- 任务覆盖最广:Qwen-Audio 是当时唯一同时覆盖 speech / 自然声 / 音乐三类的开源 LLM
- 唯一双模式:Qwen2-Audio 是当时唯一把”语音对话”和”音频分析”分模式优化的开源方案
- 训练范式演化最完整:从 hardcoded 标签(Whisper 路线)→ 层级标签(Qwen-Audio)→ 自然 prompt + 双模式(Qwen2-Audio),整条演化路径在 Qwen 内部走完
这种”任务广 + 模式分 + 范式演化”的工程节奏,是 Qwen 全家桶战略在 audio 维度上的体现。
七、训练 Pipeline 与数据
7.1 Qwen-Audio 训练三阶段
Stage 1: Audio encoder pre-train · Whisper-Large-V2 权重 frozen 当初始化 · adapter(2 层 linear)从头训练 · 数据:~1000 小时音频 + 文本对 │ ▼ Stage 2: Multi-task SFT · 全部 30+ 任务 + 层级标签 · LLM + adapter + audio encoder 部分参数解冻 · 数据:~3500 小时音频 + 对应任务标签 + 文本 │ ▼ Stage 3: Instruction-following SFT · 用 Qwen-Chat 风格 SFT 数据 finetune · 让模型学会自然对话风格的回答 │ ▼ Qwen-Audio
7.2 Qwen2-Audio 训练扩展
Qwen2-Audio 在 Qwen-Audio 三阶段基础上加了:
- Stage 0: Voice Chat 预训练(语音对话数据,让模型学会从语音直接生成文本回答)
- Stage 4: DPO(偏好对齐)
完整的训练数据规模在 Qwen2-Audio 时代达到 15,000+ 小时音频——是 Qwen-Audio 的 4 倍。
八、Benchmark 结果
8.1 Qwen-Audio 在 ASR 任务上的表现(2023-11 时点)
| 模型 | LibriSpeech test-clean | LibriSpeech test-other | AISHELL-1 |
|---|---|---|---|
| Whisper-Large-V2 | 2.7% WER | 5.2% WER | 8.4% CER |
| SALMONN-13B | 4.6% WER | 9.7% WER | – |
| Qwen-Audio-7B | 2.0% WER | 4.2% WER | 5.7% CER |
观察:Qwen-Audio 在 ASR 上比 Whisper-Large-V2 更准——这是因为 Qwen-Audio 在 Whisper encoder 之上继续训练,让 encoder 在中文场景 + 多任务环境下进一步优化。
8.2 Qwen-Audio 在自然声 / 音乐任务上
| 任务 | 数据集 | Qwen-Audio | 同期 SOTA(专项模型) | 差距 |
|---|---|---|---|---|
| Audio captioning | AudioCaps | 0.83 (CIDEr) | 0.88 (BART-Audio) | -0.05 |
| Music tagging | MagnaTagATune | 91.2 AUC | 92.5 AUC (MusicNN) | -1.3 |
| SER(情感识别) | IEMOCAP | 56.2% acc | 61.8% (HuBERT-SER) | -5.6 |
| Audio classification | ESC-50 | 73.4% acc | 76.2% (AudioCLIP) | -2.8 |
观察:Qwen-Audio 在自然声 / 音乐任务上和专项 SOTA 差距 1-5 个点——已经是”统一模型”在多模态多任务覆盖上的优异表现。
8.3 Qwen2-Audio 的 Voice Chat 评估
Qwen2-Audio 在 Voice Chat 任务上的表现(VoiceBench 评估):
| 模型 | VoiceBench 综合得分 | 自然度 | 准确性 |
|---|---|---|---|
| GPT-4o (audio mode) | 8.2 / 10 | 8.5 | 8.0 |
| Qwen2-Audio-7B | 7.4 / 10 | 7.3 | 7.5 |
| LLaMA-Audio-7B | 6.2 / 10 | 6.1 | 6.3 |
| SALMONN-V2 | 5.8 / 10 | 5.5 | 6.0 |
观察:Qwen2-Audio 在 2024-07 时点是开源 audio LLM 里 Voice Chat 能力最强——接近 GPT-4o audio mode 的 90% 水平。
九、Qwen-Audio 对 Qwen2.5-Omni 的奠基贡献
Qwen-Audio 两代演化里所有关键设计,都在 Qwen2.5-Omni(2025-03,arXiv:2503.20215)里被升级和整合:
| Qwen-Audio 设计 | 在 Qwen2.5-Omni 里的演化 |
|---|---|
| Whisper-Large-V2 encoder | 升级为自训音频编码器 + TMRoPE 时序融合 |
| 30+ 任务统一架构 | 扩展到 30+ 任务 × 4 模态(文本 + 图像 + 音频 + 视频) |
| 层级标签 → 自然 prompt | 完全自然 prompt + Thinker-Talker 双角色 |
| Voice Chat 模式 | 流式 Talker 实时生成语音 token |
| Audio Analysis 模式 | Thinker 直接处理音频 → 输出文本(同 chat 路径) |
| DPO 后训练 | DPO + 多模态偏好数据 |
Qwen-Audio 的工程经验是 Qwen2.5-Omni 设计的直接基础。如果没有 Qwen-Audio 两代积累的”统一架构 + 多任务训练 + 双模式”经验,Qwen2.5-Omni 的 Thinker-Talker 架构不可能这么快走通。
这也解释了为什么 Qwen-Audio 在 2024-07 之后没有发布第三代独立 audio 模型——Qwen 团队判断”音频应该融进 Omni”,把研发力量转移到 Omni 主线。这是 Qwen 全家桶战略从分立分支走向全模态统一的关键节点。
十、写在最后:Qwen-Audio 给我们的启示
Qwen-Audio 系列最值得思考的不是”它在 ASR 上比 Whisper 准多少”——而是它揭示的一个深层产品判断:
音频不应该有十几个独立模型,应该融进同一个 LLM。
2023 年业界的默认假设是”每种音频任务一个模型”。Qwen-Audio 用 30+ 任务统一在一个 7B LLM 里证明了相反的方向可行——而且在大多数任务上能接近专项 SOTA。
这个判断在 2024-2025 年被业界广泛接受——GPT-4o audio mode、Gemini Audio、Claude 的 audio 能力都是”audio 融进通用 LLM”路线。Qwen-Audio 是开源圈第一个把这条路线证明工业可行的工作。
更深一层,Qwen-Audio 揭示了 Qwen 团队对”全家桶战略”的真正理解——全家桶不是”做齐所有专项模型”,而是”把所有专项能力融进同一个 LLM”。VL 走这条路(M-RoPE 统一 token 空间)、Audio 走这条路(统一 LLM + 30+ 任务)、Omni 走得最远(4 模态全统一)。
下一篇 Q9 Qwen2.5-Omni 详解:从 2025-03 的 Qwen2.5-Omni(arXiv:2503.20215)开始,讲 Qwen 的”全模态统一”路线——TMRoPE(M-RoPE 加上音频维度)、Thinker-Talker 双角色架构、流式语音生成、与 GPT-4o realtime 的对比。
参考资料
- Chu et al., Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models, arXiv:2311.07919, 2023. <https://arxiv.org/abs/2311.07919>
- Chu et al., Qwen2-Audio Technical Report, arXiv:2407.10759, 2024. <https://arxiv.org/abs/2407.10759>
- Radford et al., Robust Speech Recognition via Large-Scale Weak Supervision (Whisper), arXiv:2212.04356, 2022. <https://arxiv.org/abs/2212.04356>
- Tang et al., SALMONN: Towards Generic Hearing Abilities for Large Language Models, arXiv:2310.13289, 2023. <https://arxiv.org/abs/2310.13289>
- Deshmukh et al., Pengi: An Audio Language Model for Audio Tasks, arXiv:2305.11834, 2023. <https://arxiv.org/abs/2305.11834>
- yudonglee, Qwen-VL 系列详解(本系列 Q7), <https://yudonglee.me/qwen-vl-series-explained/>
![]()
发表回复