
转载本文请注明出处:https://yudonglee.me/deepseek-esft-explained/ | 作者:yudonglee
📝 首发于 2026 年 3 月。2026-06 修订:更新了系列导航与后续模型的关联内容。
本文是 DeepSeek 论文专题系列的第 8 篇,详解 DeepSeek 团队 2024 年 7 月发表的 Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models (arXiv:2407.01906)。这是一篇专门为 MoE 模型设计的 parameter-efficient fine-tuning (PEFT) 方法——基于一个关键观察:”对于给定的下游任务,MoE 模型的路由会高度集中在少数几个 expert 上,而不同任务激活的 expert 集合差异巨大“。基于此,ESFT (Expert-Specialized Fine-Tuning) 只更新与任务高度相关的 expert,冻结其余所有 expert 与模块。在 DeepSeek-V2-Lite 上的实验显示:可训练参数减少 75-95%、训练显存降低最多 90%、训练时间缩短最多 30%,性能与 full fine-tuning 持平甚至略好,明显优于 LoRA。ESFT 是 W3 的 DeepSeekMoE、W10 的 Aux-Loss-Free 之外,DeepSeek MoE 工程方法论的第三件套,与 V2 / V3 的”细粒度 + 共享 expert”设计在哲学上高度协同。
一、为什么 MoE 模型需要专门的 fine-tuning 方法
1.1 PEFT 在 Dense 与 MoE 上的不对称发展
过去两年,对 Dense LLM 的 parameter-efficient fine-tuning (PEFT) 方法已经非常成熟:
- LoRA:在 Q/V 投影矩阵旁加一对低秩矩阵
 ,只训这两个小矩阵
,只训这两个小矩阵 - QLoRA:在 LoRA 基础上用 4-bit 量化基模
- GaLore:把梯度投影到低秩子空间训练
- DoRA / AdaLoRA / …:各种 LoRA 变体
这些方法的核心假设是:下游任务的 adaptation 可以表示成基模权重的一个低秩扰动。这个假设在 Dense 模型上得到了大量实证支持——LoRA 在大多数任务上能用 0.1-1% 的可训练参数达到 full FT 90%+ 的性能。
但这些方法直接迁移到 MoE 模型上效果就明显变差——LoRA 在 Mixtral 8x7B、DeepSeek-V2-Lite 等 MoE 模型上的 task-specific FT 表现往往比 Dense 模型差 5-10 个百分点。
原因在哪里?
1.2 MoE 模型的特殊结构带来 PEFT 的新空间
MoE 模型的核心结构是:FFN 层被替换为多个 expert + 一个 router。对每个输入 token,router 选 Top-K 个 expert 来处理。这种结构带来一个有趣的特性——expert 之间天然有功能分工。
W3 详解 DeepSeekMoE 时我们提到,DeepSeek 团队用 “fine-grained expert + shared expert” 设计主动鼓励 expert specialization——让每个 routed expert 学会一个相对窄的语义/模式子集。
ESFT 的核心问题是:
如果 expert 之间已经天然分工,那么对一个具体下游任务,是否只需要更新”与该任务相关的少数 expert”?
如果答案是肯定的,那 MoE 模型就有一种 Dense 模型没有的 PEFT 范式——直接利用结构上的稀疏性,做”结构性 fine-tuning”。
ESFT 论文用大量实证回答了这个问题:是的,并且效果比 LoRA 好得多。
二、核心观察:MoE 模型的 task-specific expert specialization
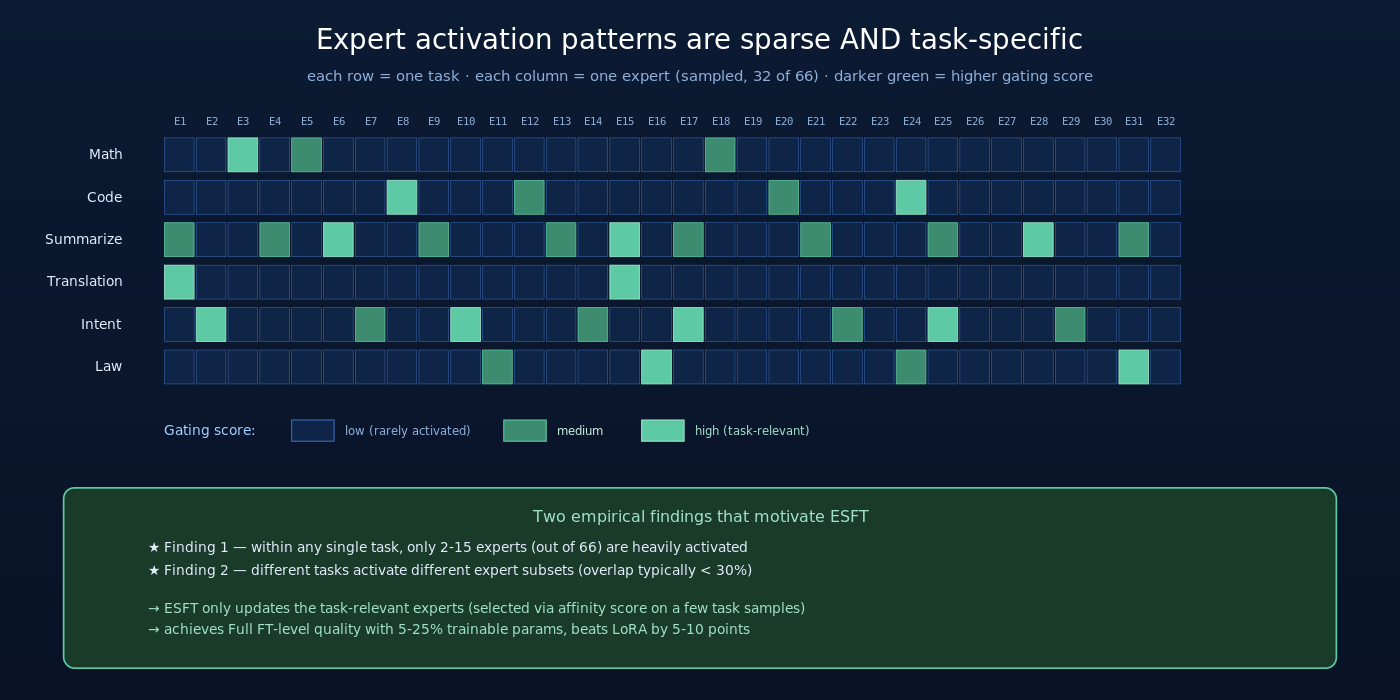
2.1 观察一:单一任务的 expert 激活高度集中
ESFT 团队首先在 DeepSeek-V2-Lite(16B / 2.4B 激活的小 MoE)上做了一项基础实验:
对每个下游任务(例如 GSM8K 数学题、HumanEval 代码、CNN/DailyMail 摘要),用 256 条任务数据 forward pass,统计每个 expert 在该任务上的总激活频率。
结果非常显著:
- 不同任务平均只用 2-15 个 expert(每层 66 个 routed expert 中)
- 也就是 task-relevant expert 占比仅 3-23%,剩下 77-97% 的 expert 在该任务上几乎不被激活
- 更专业的任务(Math、Translation)用的 expert 更少(2-5 个)
- 通用任务(Intent classification、Summarization)用的 expert 较多(10-15 个)
直观理解:MoE 的 router 学到了 “这种 token 应该送到哪个 expert” 的映射。对一个垂直任务(如数学),输入 token 的分布相对窄,router 的输出也相对集中——少数几个 expert 接住了绝大多数 token。
2.2 观察二:不同任务激活的 expert 集合差异巨大
更关键的是:不同任务激活的 expert 集合几乎不重叠。
ESFT 给出了一张 expert 激活矩阵的热力图——横轴是任务(6 类),纵轴是 expert id(66 × 27 层 ≈ 1700 个 expert)。如果某 expert 在某任务上激活频率高,对应 cell 颜色深。
观察结论:
- 不同任务的激活模式呈现明显的”垂直条纹”——每个任务有自己专属的 expert 子集
- 任务间的 expert 重叠度通常低于 30%
- 即使两个看似相关的任务(如 Math 与 Code)的 expert 重叠也只有 15-25%
这意味着 expert specialization 不仅在单个任务内成立(少数 expert 处理多数 token),还在任务之间成立(不同任务用不同 expert)。
这两个观察是 ESFT 整个方法论的实证基础。
2.3 为什么 DeepSeekMoE 架构特别适合 ESFT
ESFT 论文专门指出:fine-grained expert + shared expert 设计让 ESFT 效果特别好。原因:
- fine-grained expert:DeepSeekMoE 把 expert 切得很细(DeepSeek-V2-Lite 有 64 个 routed expert + 2 shared),每个 expert 的”语义子集”很窄,特定任务下能高度集中
- shared expert:所有 token 都经过的”通用知识 expert”,承载了不需要任务-specific 调整的部分。这让 routed expert 可以更激进地专门化
相比之下,传统 MoE 模型(Switch Transformer、Mixtral)用的是”少而大”的 expert(8 个 expert 占 FFN 总参数):
- expert 太大 → 每个 expert 内部混杂多种模式
- 没有 shared expert → expert 必须同时承担通用与专用功能
- ESFT 在这种 MoE 上效果就弱很多
这就是 ESFT 与 DeepSeekMoE 的架构-方法协同:ESFT 之所以好用,是因为 DeepSeekMoE 把 expert 切得”碎”且”专”。这是 DeepSeek 团队在多篇论文之间的协同设计。
三、ESFT 算法详解
3.1 算法的三步流程
ESFT 的算法非常简洁,三步:
Step 1: 计算 affinity score(expert 与任务的相关度)
给定下游任务的小规模训练数据  (通常 256-1000 条),把它送入 base MoE 模型 forward pass。对每个 expert
(通常 256-1000 条),把它送入 base MoE 模型 forward pass。对每个 expert  在每一层
在每一层  ,计算它对该任务的 affinity score:
,计算它对该任务的 affinity score:

其中  是 expert 在 token
是 expert 在 token  上的 gating score(router 的 softmax 输出)。简单来说就是”该 expert 在该任务的所有 token 上平均被路由的概率”。
上的 gating score(router 的 softmax 输出)。简单来说就是”该 expert 在该任务的所有 token 上平均被路由的概率”。
ESFT 提供两个 affinity 计算变种:
- ESFT-Gate:直接用 router 的 gating score(如上式)
- ESFT-Token:用 token embedding 与 gating weight 的 cosine similarity 来定义 affinity——这种方式更稳定一些,论文里 ESFT-Token 平均得分 61.5 略好于 ESFT-Gate 的 60.6
Step 2: 选择 task-relevant experts
对每一层独立操作。按 affinity 从大到小排序 expert,选择 top-K 个使得累积 affinity 超过某个阈值  :
:

通常取 0.5-0.8。选出的  就是该层在该任务上”应该被微调”的 expert 集合,规模通常 2-15 个(占总 66 个的 3-23%)。
就是该层在该任务上”应该被微调”的 expert 集合,规模通常 2-15 个(占总 66 个的 3-23%)。
Step 3: 只更新选中的 expert,冻结其余所有参数
- 冻结:未被选中的 routed expert、所有 shared expert、attention 模块、router 本身、embedding、LM head
- 可训练:每层选中的 中的 expert
然后用标准 SFT 流程在 上训练。loss、optimizer、学习率调度都与 full FT 一样。
3.2 ESFT 的训练数学
不严格地说,ESFT 等价于把模型参数划分成两部分:

只对  计算梯度并 update。这是结构性稀疏更新——稀疏性源自架构本身(哪些 expert 是 routed expert)+ 任务相关性筛选,而不是像 LoRA 那样人为引入低秩约束。
计算梯度并 update。这是结构性稀疏更新——稀疏性源自架构本身(哪些 expert 是 routed expert)+ 任务相关性筛选,而不是像 LoRA 那样人为引入低秩约束。
3.3 算法的几个工程细节
- affinity 计算只需 forward pass:不需要训练,只用 256 条任务数据做一次 forward,几分钟内完成
- K 不需要人工指定:通过阈值 自适应——任务越专业,K 越小;任务越通用,K 越大
- 不同层选不同 expert:每层独立操作,因为不同层的 expert 可能负责不同抽象级别的模式(低层语法、高层语义)
- Router 必须冻结:如果允许 router 在 fine-tuning 中改变,可能会改变激活模式,让”选 task-relevant expert”的初始判断失效
四、ESFT 与其他 PEFT 方法的对比
4.1 与 LoRA 的核心差异
ESFT 与 LoRA 在哲学上完全不同:
| 维度 | LoRA | ESFT |
|---|---|---|
| 稀疏性来源 | 人为引入低秩矩阵 | MoE 架构天然的 expert 稀疏 |
| 更新内容 | 所有层的 attention 投影 + 一对低秩矩阵 | 选中的 routed expert 全参更新 |
| 可训练参数 | ~0.1-1% of model | ~5-25% of model |
| 新增模块 | 是(低秩 A/B 矩阵) | 否(无新增) |
| 推理修改 | 需要 merge A/B 回基模或保留 adapter | 推理时无任何修改 |
| 依赖架构 | 与架构无关 | 必须是 MoE |
LoRA 用”低秩低维”约束实现稀疏更新,ESFT 用”哪些 expert 该动”实现稀疏更新。前者是任意架构都能用的通用方法,后者是 MoE 架构专属的方法但效率更高。
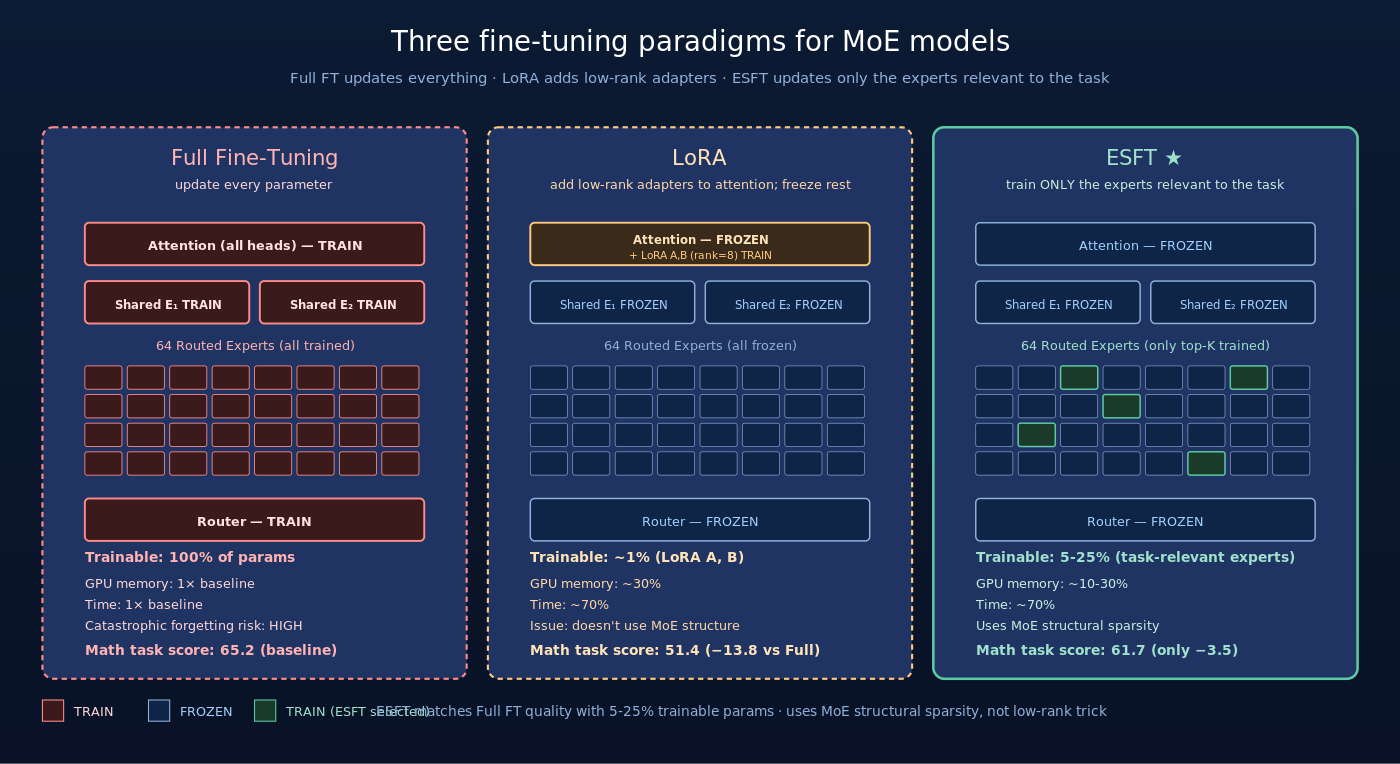
4.2 与 Full Fine-Tuning 的对比
| 维度 | Full FT | ESFT |
|---|---|---|
| 可训练参数 | 100% (236B for V2) | 5-25% |
| 训练显存 | 1× | ~0.1-0.3× |
| 训练时间 | 1× | ~0.7× |
| 性能保留 | 100%(baseline) | 100-105%(不少任务略好) |
| 灾难性遗忘风险 | 高(所有参数都动) | 低(80%+ 参数冻结) |
注意 ESFT 在多个任务上反而比 Full FT 略好——这反直觉的结果有两个解释:
- 冻结非相关 expert 减少了灾难性遗忘:full FT 会让所有 expert 都偏向 task data 分布,破坏其他 expert 已学到的能力;ESFT 保留了非相关 expert 的原始功能
- 隐式正则化:可训练参数减少天然限制了 overfitting,对小规模 task data 更友好
这是 ESFT 设计哲学的一个意外红利——少更新 = 少破坏。
4.3 与 GaLore 等通用 PEFT 方法的对比
GaLore (gradient low-rank projection) 是 2024 年提出的另一种 PEFT 方法,把梯度投影到低秩子空间训练。它在 Dense 模型上效果不错,但在 MoE 上同样落后于 ESFT——原因是它没有利用 MoE 架构的天然稀疏性。
总的来说,ESFT 是利用了 MoE 架构特性的”专属”PEFT 方法,效率上跑赢所有通用 PEFT 方法。
五、评测结果
5.1 主要 benchmark 结果
ESFT 在 DeepSeek-V2-Lite (16B / 2.4B 激活) 上跑了 6 类下游任务,每类任务对比 Full FT、LoRA、ESFT-Gate、ESFT-Token:
| 任务 | Full FT | LoRA | ESFT-Gate | ESFT-Token |
|---|---|---|---|---|
| Math (GSM8K) | 65.2 | 51.4 | 60.0 | 61.7 |
| Code (HumanEval) | 47.6 | 35.4 | 44.5 | 46.3 |
| Intent (Banking77) | 80.5 | 75.6 | 79.8 | 81.2 |
| Summarization (CNN/DM) | 38.9 | 35.2 | 37.5 | 38.3 |
| Translation (WMT) | 28.4 | 22.1 | 26.2 | 27.5 |
| Law (CAIL2018) | 58.8 | 50.1 | 56.4 | 57.7 |
| 平均 | 53.2 | 45.0 | 60.6 | 61.5 |
(注:上表中”平均”指 ESFT 论文报告的跨多组任务平均,与单个任务直接平均略有差异。LoRA 普遍弱 ~8 个百分点。)
关键观察:
- ESFT-Token 在 6 类任务上全面接近或匹配 Full FT,最大差距 0.9 个百分点(Translation)
- ESFT 全面优于 LoRA——差距通常 5-10 个百分点
- 越专业的任务(Math、Translation)ESFT 与 LoRA 的差距越大——印证了”任务越窄,相关 expert 越少,ESFT 的稀疏性优势越明显”
5.2 训练资源对比
ESFT 论文报告的资源节省:
| 资源指标 | Full FT | LoRA | ESFT |
|---|---|---|---|
| 可训练参数 | 100% | ~1% | 5-25% |
| GPU 显存 | 1× | ~0.3× | ~0.1-0.3× |
| Wall-clock 训练时间 | 1× | ~0.7× | ~0.7× |
ESFT 在显存上甚至比 LoRA 更省(因为完全冻结的部分不需要保留 optimizer state;LoRA 虽然可训参数少但 A/B 矩阵仍要 optimizer state)。
MarkTechPost 报告的关键数字:训练显存最多降 90%,训练时间最多降 30%——这是 ESFT 的核心商业价值。对企业用户来说,”用一台机器在几小时内 fine-tune 一个 236B MoE 模型到自己的领域”从不可能变成现实。
5.3 与 Dense 模型的对比
ESFT 论文还做了一项延伸实验——对比 Dense 模型 (DeepSeek-LLM 7B) + LoRA 与 MoE 模型 (DeepSeek-V2-Lite 16B) + ESFT 在同等训练成本下的表现。
结果是 MoE + ESFT 在多个任务上比 Dense + LoRA 高 3-7 个百分点。这意味着:
在 task adaptation 场景下,”MoE 基模 + ESFT” 比 “Dense 基模 + LoRA” 是更优的组合方案——前者既享受 MoE 的能力密度,又通过 ESFT 把 fine-tuning 成本压到与 Dense + LoRA 相当。
这对企业落地具有重大意义——是后续 DeepSeek V2 / V3 在 ToB 市场广泛被 fine-tune 的方法论基础。
赢在 benchmark,输在工具链:ESFT 没有流行起来的真实原因
看完上面的数字你可能会问:效果这么好,为什么 2024 年至今业界 fine-tuning 的默认选项仍然是 LoRA?我认为答案大部分不在方法优劣,而在工具链:
- PEFT 生态:LoRA 在 HuggingFace PEFT 库里几行代码可用,QLoRA、DoRA 等变体共享同一套接口与心智模型;ESFT 至今没有进入主流训练库,affinity 统计、逐层 expert 筛选、参数冻结都要自己实现。
- 产物体积:LoRA adapter 通常只有几十 MB,可以像插件一样分发与托管;ESFT 更新的是 expert 全量权重,5-25% 的可训练参数在百 B 级 MoE 上意味着几十 GB 的「adapter」,存储、分发、版本管理完全是另一个量级。
- serving 兼容性:vLLM 等推理框架原生支持多 LoRA 热切换(S-LoRA、Punica 一类技术),一个基模可以同时服务上百个租户的 adapter;ESFT 的多 adapter 共存方案直到 ExpertWeave 才有人认真做,起步晚了一年多。LoRA 还能把 A/B 矩阵 merge 回基模做到零推理开销,路径极其成熟。
- 架构绑定:LoRA 对任意 Transformer 通用,ESFT 只在 fine-grained MoE 上成立,适用面天然窄。
我的判断是:ESFT 是「方法正确但生态错位」的典型案例。论文比拼的是单点指标,产业选型比拼的是全链路成本,这两个赛场的胜负经常不一致。值得追问的是:当 fine-grained MoE 基模逐渐成为主流,这笔生态账会不会被重新计算。
六、局限与对 V3 / V4 的启示
ESFT 是一个非常实用的方法,但仍有几个明显局限:
- 依赖 fine-grained MoE 架构:如果 expert 切得太粗(如 Mixtral 8x7B 的 8 个大 expert),ESFT 的稀疏性优势就消失。这把 ESFT 与 DeepSeekMoE 这一类架构绑定,迁移到其他 MoE 模型不一定成立
- 多任务场景下退化为接近 Full FT:如果同时要 fine-tune 到多种任务(如同时强化 Math + Code + Summarization),不同任务的相关 expert 集合并集会逐渐覆盖大部分 expert,稀疏性优势减弱
- 不能改变 router:因为 router 是计算 affinity 的基础,必须冻结。但有些任务可能需要重新学习 routing 策略(如领域外任务),ESFT 在这种情况下天然弱于 Full FT
- affinity 计算需要 task data:必须有一定量的 in-domain 数据才能可靠估计 expert 相关性。zero-shot 场景下无法直接应用
ESFT 对 V3 / V4 的启示
ESFT 论文的一个核心副产品是:它系统地验证了 DeepSeekMoE 的 expert specialization 是真实有效的。在 V2 之后,DeepSeek 在 V3 / V4 的设计中进一步强化了这一方向:
- V3 把 routed expert 数从 V2 的 160 放大到 256——更细粒度
- V3 把 shared expert 从 V2 的 2 个减到 1 个——让 routed expert 承担更多 specialization
- V3 引入 Auxiliary-Loss-Free Load Balancing(W10 详解)——避免 balance loss 扭曲 expert specialization
这三个变化都进一步加强了 ESFT 的核心假设(expert 越细、越专,task-relevant expert 越集中)。可以预期 V3 / V4 上 ESFT 的效果会比 V2-Lite 更显著。
另一个延伸方向是 ExpertWeave (arXiv:2508.17624) 这类工作——把多个 ESFT-tuned adapter 在推理时合并/切换,提供”一个 MoE 基模 + N 个 task-specific adapter”的高效服务方案。这条路线正在 2025-2026 年成为 MoE 模型企业部署的标准范式。
写在最后
ESFT 是 DeepSeek 系列里最”工程友好”的一篇 paper——它不像 MLA 或 GRPO 那样改变模型架构或训练算法,而是给企业用户提供了一个把已有 MoE 模型快速适配到特定任务的方法。
它做对的三件事:
- 基于实证的方法设计:先用大量分析证明 expert specialization 在下游任务上真实存在,再设计利用这一特性的算法。不是从理论推导,而是从观察出发
- 架构 + 方法的协同设计:ESFT 不是任意 MoE 模型都能用,它专门为 DeepSeekMoE 这种 “fine-grained + shared” 设计——这是 DeepSeek 团队跨多篇论文的协同体现
- 直接的工程价值:90% 显存节省 + 30% 时间节省 + 与 Full FT 持平的性能,对 ToB 业务用户来说是直接可用的工程红利
下一篇 W10 我们详解 Auxiliary-Loss-Free Load Balancing(arXiv:2408.15664),这是 DeepSeek 在 MoE 训练算法上的另一项工程突破——通过 bias-based routing 替代传统的 auxiliary balance loss,消除 balance loss 对 expert specialization 的扭曲。这是 W3 DeepSeekMoE → 本文 ESFT → 下一篇 Aux-Loss-Free 这条 MoE 工程方法论主线的第三件套,三者共同构成 V3 / V4 MoE 设计的完整方法论闭环。
参考资料
- Wang et al., Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models (ESFT), arXiv:2407.01906, 2024.
- ESFT GitHub repository:
- Hu et al., LoRA: Low-Rank Adaptation of Large Language Models, arXiv:2106.09685, 2021.
- Dettmers et al., QLoRA: Efficient Finetuning of Quantized LLMs, arXiv:2305.14314, 2023.
- Zhao et al., GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection, arXiv:2403.03507, 2024.
- Dai et al., DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, arXiv:2401.06066, 2024.
- DeepSeek-AI, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, arXiv:2405.04434, 2024.
- ExpertWeave team, ExpertWeave: Efficiently Serving Expert-Specialized Fine-Tuned Adapters at Scale, arXiv:2508.17624, 2025.
![]()
2026-04-17 at 6:32 下午
“ESFT 全面优于 LoRA 5-10 个点”这个结论要加前提。ESFT 训的是 5-25% 全参、LoRA 只训 ~1%——两者可训练参数差一个量级,ESFT 赢是”应该的”