转载本文请注明出处:https://yudonglee.me/ctc-explained-part2/ 作者:yudonglee
本文总共分为两部分来全面阐述CTC算法(本篇为Part 2):
Part 1:Training the Network(训练算法篇),介绍CTC理论原理,包括问题定义、公式推导、算法过程等。Part 1链接。
Part 2:Decoding the Network(解码算法篇),介绍CTC Decoding的几种常用算法。Part 2链接。
在上一篇文章中,我们详细介绍了 CTC 的问题背景以及模型训练的算法与原理。本篇是系列的第二部分,重点介绍 CTC 的模型推理阶段——解码算法。
在一般的分类问题中,训练好模型后,推理过程非常简单——加载模型、前向传播即可得到分类结果。然而,在序列学习问题中,模型的推理过程本质上是一个搜索问题:给定输入序列 x,需要在所有可能的标签序列空间中,找到条件概率 p(z|x) 最大的输出序列 z*。这一搜索过程通常称为解码(decoding)。由于搜索空间随序列长度呈指数级增长,如何在有限时间内找到最优解(或高质量的近似解)是一个极具挑战性的问题。
CTC 解码的目标是找到使条件概率最大的标签序列,形式化地定义为:

如上图所示,将 CTC 网络的输出按时间步展开,可以形成一个栅格网络(lattice),解码过程就是在这个栅格中搜索最优路径。
最直观的策略有两种:
策略一:穷举搜索。 遍历所有可能的路径,对映射到同一标签的路径概率求和,选择概率最大的标签序列。这能保证找到最优解,但时间复杂度为  (其中 |L’| 为扩展字符集大小,T 为时间步数),是指数级的,显然不可行。
(其中 |L’| 为扩展字符集大小,T 为时间步数),是指数级的,显然不可行。
策略二:贪心解码(Greedy Decoding / Best Path Decoding)。在每一个时间步独立地选择概率最大的输出符号,将整条路径通过映射函数 B 得到最终标签。这种方法时间复杂度仅为 O(T),非常高效。如上图的例子中,贪心解码得到的输出序列 l = blank。
然而,贪心解码存在一个根本性的缺陷:最优路径 ≠ 最优标签。回顾 Part 1 的核心概念,CTC 中一个最终标签对应搜索空间中多条路径,最终标签的概率是所有这些路径概率之和。因此,单条概率最高的路径所对应的标签,其总概率未必最高。如上图的例子,虽然概率最大的单条路径对应 l = blank,但将所有映射到 l = b 的路径概率相加后,p(l=b) > p(l=blank),所以真正的最优解是 l = b。
这一现象说明,CTC 解码不能简单地取每步最优,而需要更精巧的搜索策略。
本篇介绍两种常用的 CTC 解码算法:
| 算法 | 核心思想 | 最优解保证 | 时间复杂度 |
| CTC Prefix Search Decoding | 基于前缀概率的贪心搜索 | 能保证找到最优解 | 最坏情况为指数级 |
| CTC Beam Search Decoding | 固定宽度的束搜索 | 不保证最优,但近似效果好 |  ,可控 ,可控 |
两者的核心区别在于:Prefix Search 追求精确最优但可能耗时过长,Beam Search 牺牲一定最优性换取可预测的计算开销。在实际工程中,Beam Search 因其效率优势而被更广泛地采用。
1. CTC Prefix Search Decoding
CTC Prefix Search Decoding 最早由 Graves 在其 2006 年的 CTC 原始论文中提出。它的核心思想是:不去枚举完整的输出序列,而是逐步构建序列的前缀(prefix),每一步选择当前前缀概率最大的分支进行扩展,直到构建出完整的标签序列,关键步骤是利用动态规划算法计算“前缀概率”。下面先通过一个简单的例子来介绍CTC Prefix Search Decoding的大致过程,如下图:
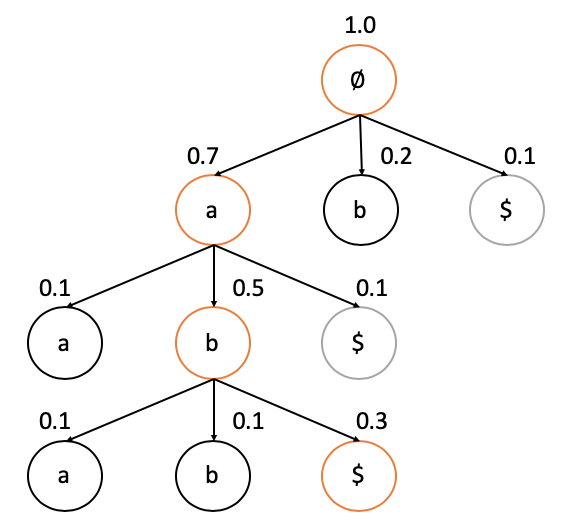
 为结束节点(表示不可往下扩展子节点),最终搜索过程会在结束节点上停止,并输出最终的解码label与概率值。
为结束节点(表示不可往下扩展子节点),最终搜索过程会在结束节点上停止,并输出最终的解码label与概率值。如上图例子,CTC Prefix Search搜索过程:
1. 初始化最佳序列 为空集,最佳序列的概率
为空集,最佳序列的概率 。把根节点放入到扩展集合中,初始化它的前缀概率为1.0,初始化
。把根节点放入到扩展集合中,初始化它的前缀概率为1.0,初始化 。
。
2. 从扩展集合中选取前缀概率最大的节点扩展,扩展子节点a和b,计算a和b的前缀概率(上图中第一层节点a和b的前缀概率分别为0.7和0.2),如果前缀概率大于则将其加入到扩展集合。同时,计算结束节点 的概率(上图中第一层节点$的概率为0.1),如果结束节点的概率大于,则将其对应的label设置为最佳序列l*,同时更新。
的概率(上图中第一层节点$的概率为0.1),如果结束节点的概率大于,则将其对应的label设置为最佳序列l*,同时更新。
3. 继续搜索,重复步骤2,直到扩展集合为空,即搜索结束,输出最终解码的l*和概率p(l*)。(上图中最终 ,
, )
)
从上面的例子中可以看出,CTC Prefix Search的搜索过程非常简单,核心问题是如何计算前缀概率和每个结束节点对应的概率,它们的计算方式跟上一篇介绍前向概率和后向概率的动态规划算法类似,下面来正式介绍它们的定义与计算方式。
定义t时刻前缀为 的概率为
的概率为 :即在t时刻网络输出序列对应的label为
:即在t时刻网络输出序列对应的label为 的概率。将划分为两种情况:a)
的概率。将划分为两种情况:a) 定义为t时刻网络输出blank空字符的概率,b)
定义为t时刻网络输出blank空字符的概率,b) 定义为t时刻网络输出非空字符的概率,则 = + 。更加正式的定义如下:
定义为t时刻网络输出非空字符的概率,则 = + 。更加正式的定义如下:
定义 为建模单元的字符集(如上图例子中的{a, b}),
为建模单元的字符集(如上图例子中的{a, b}), 为加入blank空字符后的扩展字符集(如上图例子中的{a, b, -}),
为加入blank空字符后的扩展字符集(如上图例子中的{a, b, -}), 是网络输出路径
是网络输出路径 到输出序列
到输出序列 的映射函数:
的映射函数: ,路径集合
,路径集合 ,t时刻的前缀的概率
,t时刻的前缀的概率 ,
, ,
, ,最终序列
,最终序列 (假定输入序列长度为T)的概率
(假定输入序列长度为T)的概率 ,
, 。
。

在给定足够时间的条件下CTC Prefix Search Decoding总能搜索到最大概率值,但随着输入序列长度的增加,搜索过程扩展的前缀可能呈指数级增加。所以在实际应用中为了能够在限定时间的条件下找到近似解,需要增加一些启发式的搜索剪枝策略,比如,分而解之的思路:将搜索空间按照空字符blank来划分为更小的子空间,再针对每个子空间进行CTC Prefix Search。
另外,在语音识别等实际应用中,解码过程往往还要加上一些条件约束,即满足: ,其中G可以是语言模型或语法等约束[4],取决于具体应用的条件设定。
,其中G可以是语言模型或语法等约束[4],取决于具体应用的条件设定。 ,假定
,假定 概率同等,则解码的目标是:
概率同等,则解码的目标是: 。所以,实际应用中可以在解码过程加上限定约束条件,比如,在语音识别中
。所以,实际应用中可以在解码过程加上限定约束条件,比如,在语音识别中 可以对应为语言模型或发音模型的概率。
可以对应为语言模型或发音模型的概率。
2. CTC Beam Search Decoding
CTC Beam Search Decoding 算法原理简洁,但在实际工程中应用最为广泛。其核心思想是:在每一个时间步,只保留概率最高的 W 条候选路径(W 称为 Beam Width,束宽),对这 W 条路径分别扩展,再从扩展结果中保留新的 top-W 路径,依次递推直到序列结束。
Beam Search 的关键在于如何正确计算每一步扩展后的路径概率——在 CTC 中这比标准 Beam Search 更复杂,因为需要处理 blank 符号和多对一映射的问题。
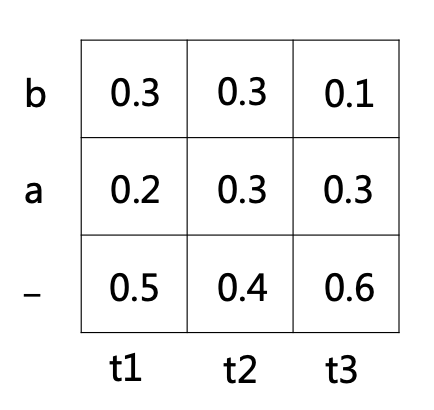
为了帮助理解,我们先从一个简单例子出发。设 T = 3(3 个时间步),字符集为 {a, b}(加上 blank 共 3 个符号),其每个时间步的输出概率如下图的时间栅格表所示:
首先,如果对搜索空间进行穷举——即每一步都对所有可能的符号进行扩展——则搜索树如下图所示。每个叶子节点代表一条完整路径,将其通过映射函数 B 转换为最终标签后,对同一标签的路径概率求和即可得到每个标签的总概率:
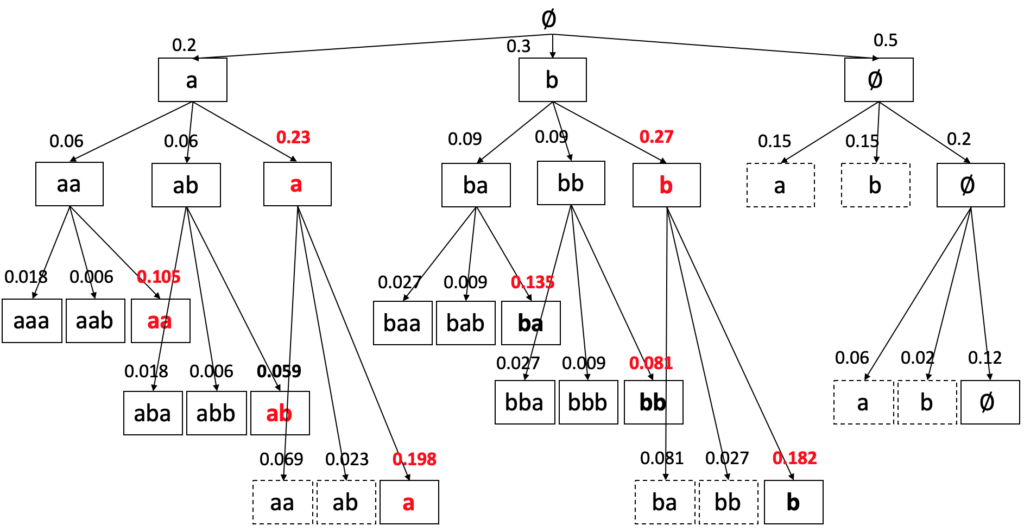
从上图可以看出,穷举搜索在 T=3、|L’|=3 的小例子中就已经有 27 条路径,最优解为 l* = b,p(l*) = 0.164。当 T 和字符集增大时,路径数呈指数级增长,穷举显然不可行。
Beam Search 的解决方案很直接:每一步只保留概率最大的 W 个候选进行扩展,其余全部剪掉。如下图所示(W = 2):
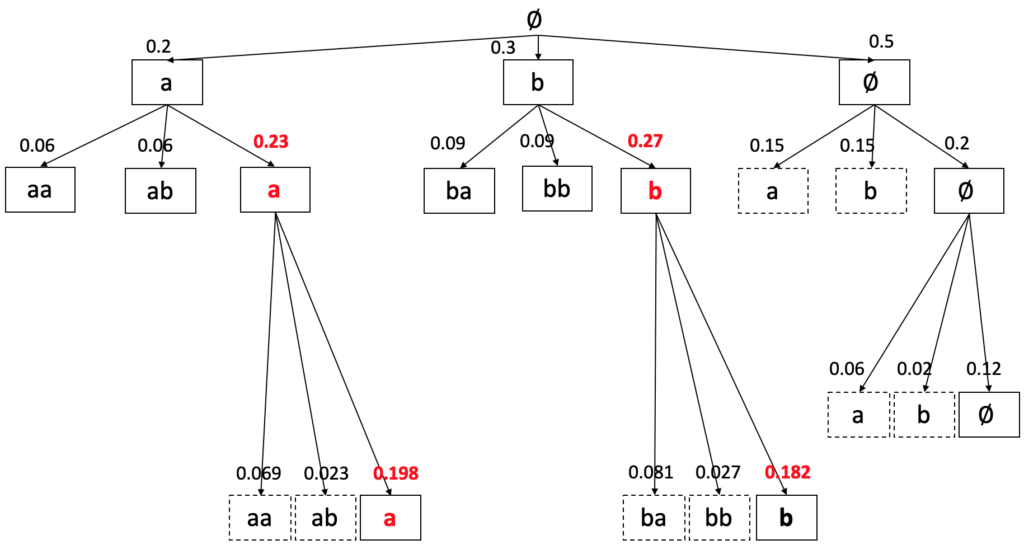
由此可见,Beam Search 实际上是对搜索**树**进行了宽度限制的剪枝:每一步最多保留 W 个节点,总的时间复杂度从穷举的 降至 O(T · W · |L’|),在实际应用中完全可控。W 越大,搜索越充分,解的质量越高,但计算开销也越大。典型的 W 取值在 5–100 之间,具体取决于任务和实时性要求。
接下来介绍 CTC Beam Search 中最核心的步骤——计算节点扩展概率:。
与 Prefix Search 类似,我们需要定义前缀概率。设 为某个候选前缀,定义 为时刻 t 前缀 的概率,即在前 t 个时间步内,所有映射到以 为前缀的路径的概率之和。
下面我们再介绍CTC Beam Search中最核心的一步,计算节点扩展概率:。跟上一节一样,定义t时刻前缀为的概率为:即在t时刻网络输出序列对应的label为的概率。
先引入几个符号定义:
– 前继前缀  :去掉前缀 最后一个字符后得到的前缀。例如
:去掉前缀 最后一个字符后得到的前缀。例如  ,则
,则  。
。
– 末尾字符  : 的最后一个字符。例如
: 的最后一个字符。例如  ,则
,则  。
。
– 末尾字符  :的最后一个字符。例如
:的最后一个字符。例如  ,则
,则  。
。
将 拆分为两部分:
– :时刻 t 网络输出 blank 时,前缀为 l 的概率。
– :时刻 t 网络输出非 blank 字符时,前缀为 l 的概率。
则 = + 。
和 可以通过以下递推关系从 t-1 推导到 t(注意需要特殊处理”扩展字符与末尾字符相同”的情况,以避免重复计数):
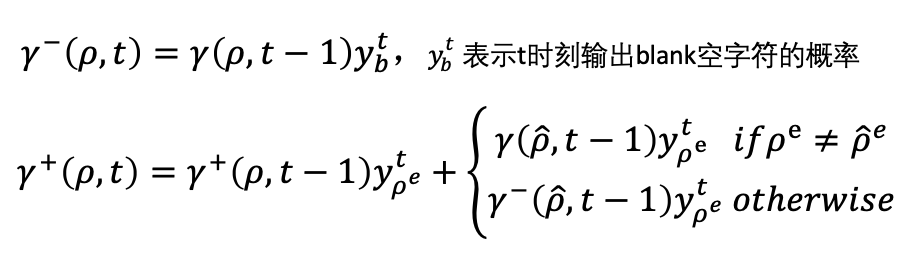
至此,CTC Beam Search的求解过程就基本介绍完了,如上一节所述,在实际应用中往往需要加上一些条件约束,比如语言模型或语法约束等,我们对扩展字符的过程加上约束,修改和的递归求解如下:
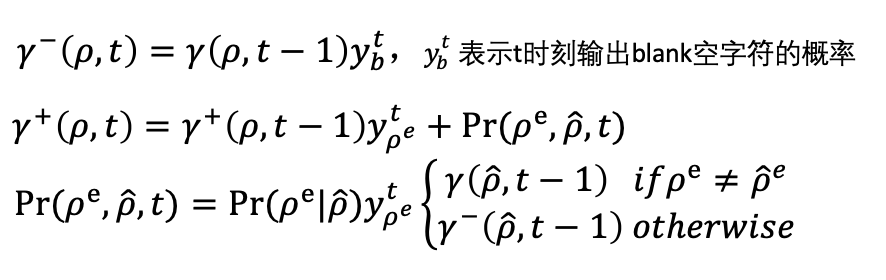
 表示从到的扩展概率
表示从到的扩展概率综上所述,CTC Beam Search的算法过程如下:

3. 两种算法的对比与实践建议
在实际应用中选择解码算法时,可以参考以下对比:
| 维度 | Prefix Search Decoding | Beam Search Decoding |
| 最优解保证 | 能找到全局最优解 | 近似解,不保证最优 |
| 时间复杂度 | 最坏指数级 | O(T·W·\|L’\|),可控 |
| 实现复杂度 | 较高 | 较低 |
| 融合外部约束 | 支持 | 支持,且更灵活 |
| 实际应用 | 常作为评估基准 | 工程中主流选择 |
| 适用场景 | 字符集较小、序列较短 | 通用,尤其大词汇量任务 |
实践建议:
1. Beam Width 的选择:W 通常取 10–100。过小(如 W=1,退化为贪心)会明显损失质量;过大则收益递减,计算浪费。建议从 W=20 开始调节。
2. 语言模型权重:α 是最重要的超参数之一,通常通过在开发集上搜索最优值来确定,典型范围在 0.5–2.0 之间。
3. 长度奖励:CTC 模型由于 blank 的存在,天然倾向于生成较短的序列。适当的 length bonus(β > 0)可以缓解这一问题。
4. 实时性要求:如果是流式(streaming)场景,Beam Search 可以与流式解码策略结合,分块进行解码。
总结
本篇详细介绍了 CTC 模型的两种主要解码算法。
CTC Prefix Search Decoding 基于最优优先搜索策略,每次选取前缀概率最大的节点进行扩展,利用动态规划递推计算前缀概率。在给定足够时间的前提下,它能保证找到全局最优解,因此常被用作评估其他解码算法的基准。但其最坏情况下的搜索空间随序列长度指数级增长,实际应用中需要结合剪枝策略控制计算开销。
CTC Beam Search Decoding 采用固定束宽的搜索策略,每一步只保留概率最高的 W 条路径进行扩展,在搜索效率和解码质量之间取得了良好的平衡。虽然不能保证最优,但凭借实现简单、计算开销可预测的优势,成为实际工程中使用最广泛的 CTC 解码方法。
两种算法都可以方便地融合语言模型、发音词典等外部知识来提升解码效果,这在语音识别等实际场景中至关重要。
总的来说,CTC 的解码问题本质上是一个搜索问题——如何在指数级的路径空间中高效找到概率最大的输出序列。理解这两种算法的原理与各自的适用场景,对于在实际项目中合理选择和优化解码策略具有重要的指导意义。
值得一提的是,近年来 CTC 解码领域也有不少新的进展。例如,将 CTC 与 Attention 机制结合的混合解码方法(CTC/Attention Joint Decoding)能够同时利用 CTC 的单调对齐优势和 Attention 的上下文建模能力;基于 WFST(Weighted Finite-State Transducer)的解码框架可以高效地将词典、语言模型等多种约束统一编码,在大词汇量连续语音识别中广泛应用。感兴趣的读者可以进一步参阅相关文献 [5][6]。
References
- Graves et al., Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with RNNs. In ICML, 2006. (Graves提出CTC算法的原始论文)
- Graves et al., A Novel Connectionist System for Unconstrained Handwriting Recognition. In IEEE Transactions on PAML, 2009.(CTC算法在手写字识别中的应用)
- Graves et al., Towards End-to-End Recognition with RNNs. In JMLR, 2014.(CTC算法在端到端声学模型中的应用)
- Alex Graves, Supervised Sequence Labelling with Recurrent Neural Networks. In Studies in Computational Intelligence, Springer, 2012.( Graves 的博士论文,关于sequence learning的研究,主要是CTC)
- Watanabe et al., Hybrid CTC/Attention Architecture for End-to-End Speech Recognition. IEEE Journal of Selected Topics in Signal Processing, 2017.(CTC/Attention 联合解码的代表性工作)
- Miao et al., EESEN: End-to-End Speech Recognition using Deep RNN Models and WFST-Based Decoding. In ASRU, 2015.(基于 WFST 的 CTC 解码框架)
- TensorFlow CTC API 文档:https://www.tensorflow.org/api_docs/python/tf/nn/ctc_loss
- Librosa 文档:https://librosa.org/doc/latest/index.html
![]()
2019-04-01 at 12:53 am
非常謝謝大牛的分享,此外,我在搜索一些資料的時候,有看到prefix beam search的內容,大概是關於在不同的path構建中,遇到blank_token就加入當前path,如果遇到非blank_token就提前做一個去重複,去除blank_token的操作(目的是為了讓當前能夠生成相同label的path做一個合併動作),只是問題在於,我不清楚這個操作,是在beam_search 選取top n的path後做的,還是先有這個操作,再排名並選取top n 這樣?
2019-04-01 at 1:05 am
抱歉,還有一個小小的問題想請教一下,如果說我們現在就是在top n中進行這種操作,那麼比如說,當前能夠生成相同label的path,他們會捨棄掉概率最小的一條?還是說兩者都保留?另外這兩條path的概率分數該如何處理哈?
2019-04-01 at 5:49 pm
1. 第一个问题,你可以参考文中CTC Beam Search的伪代码(第12~13行),每次遇到blank都会进行合并,然后再扩展子节点
2. 第二个问题,遇到相同的label则进行合并,他们概率会相加,合并后只保留一个节点,代码也同样参考CTC Beam Search的伪代码(第12~13行)
2019-04-16 at 2:32 pm
gamma- 和 gamma+ 的含义是不是写反了?
2019-04-30 at 10:22 am
谢谢指正,笔误,已经修正~
2019-04-29 at 6:08 pm
t时刻的前缀的概率,那边的伽马+,伽马-写错了吧,作者仔细看看哈
2019-04-30 at 10:22 am
谢谢指正,笔误,已经修正~
2019-05-07 at 6:52 pm
作者您好,CTC Beam Search伪代码中第十一行能详细解释下吗,这一步没有看懂。t时刻的网络输出的序列对应的label为p,那t-1时刻网络输出的序列对应的label不应该是p^吗?
2019-06-04 at 2:14 pm
可以仔细看下gamma+(p,t)的定义,这行代码对应的就是它定义的实现。你可能看漏的细节是:从“ab”扩展到“abb”对应的最后label是“ab”,而从“ab_”扩展到“ab_b”对应的最后label才是“abb”
2019-05-30 at 3:10 pm
Beam Search Decoding里面穷举搜索的时候最后b是表示b__、_b_、__b么?如果是最后的概率是0.3*0.4*0.6+0.5*0.3*0.6+0.5*0.4*0.1=0.182,是我哪里理解有问题吗?
2019-06-04 at 11:31 am
你的理解是对的,图中0.164算错了,应该是0.182,已经修正更新,谢谢
2019-06-02 at 12:13 am
请问大佬使用什么软件画上面的概率路径图形?
2019-06-04 at 11:15 am
ppt
2019-08-06 at 2:25 pm
作者您好,我认为原论文中,prefix search decoding 算法24行有问题,应该是 probRemaining -= p(p | x), 将已经不能再扩展的节点概率减去, 您觉得呢?
2019-08-30 at 9:58 am
请问一下,Beam Search Decode T2时刻是a的概率为什么是0.23,如果t1时刻选择了a,那么要使t2时刻输出a则t2时刻只能选择a或者blank即(aa, a-)概率为0.14,而你的0.23很明显是(-a,a-)的概率,如果是总的概率(-a,aa,a-)0.29. 为何结果是0.23,不是合并了重复的路径吗?还有,上面最终输出的结果是a的概率为0.198不是比b的0.182概率更大。
2019-10-08 at 4:05 pm
beam search算法第十二行应该是B不是B^吧,因为保证值计算过就好了,没必要非要在最大的M个里面吧
2019-11-08 at 4:52 pm
我也有这个疑问,麻烦博主解答下
2020-03-05 at 10:29 pm
同问这个问题
2020-03-12 at 12:20 pm
同问
2019-09-26 at 4:05 pm
请问P(p…|x)表示什么?
2020-05-10 at 9:37 am
你好,请问实战部分链接是失效了吗?想参考一下,谢谢!
2020-08-17 at 2:06 am
part3能看吗?
2021-01-06 at 9:54 pm
为什么a到a的概率是0.23?
2021-01-08 at 3:19 pm
part3什么时候能看挺期待
2021-05-12 at 10:49 am
Part3 什么时候更啊,博主
2022-01-08 at 11:55 am
大佬,期待第三部分